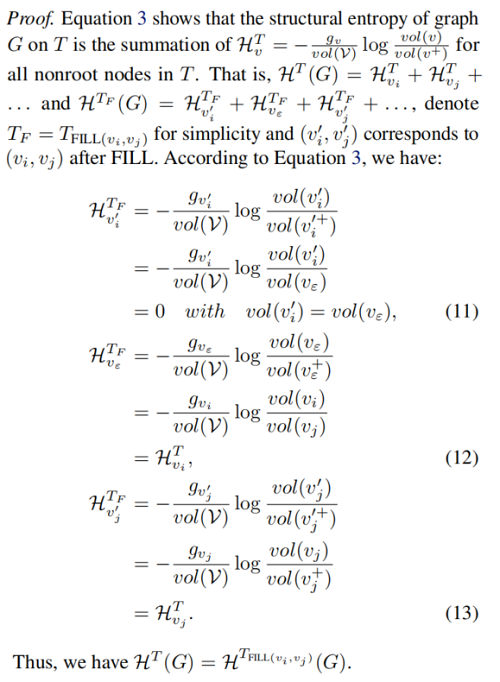Definition 3.1. Let T be any coding tree for graph G=(V,E)" role="presentation">G=(V,E), vr" role="presentation">vr is the root node of T" role="presentation">T and V" role="presentation">V are the leaf nodes of T" role="presentation">T . Given any two nodes (vi,vj)" role="presentation">(vi,vj) in T" role="presentation">T , in which vi∈vr" role="presentation">vi∈vr.children and vj∈vr" role="presentation">vj∈vr.children.
Define a function MERGET(vi,vj)" role="presentation">MERGET(vi,vj) for T" role="presentation">T to insert a new node vε" role="presentation">vε between vr" role="presentation">vr and (vi,vj)" role="presentation">(vi,vj) :
vε⋅ children ←vi(5)vε⋅ children ←vj(6)vr. children ←vε(7)" role="presentation">vε⋅ children ←vi(5)vε⋅ children ←vj(6)vr. children ←vε(7)
Definition 3.2. Following the setting in Definition 3.1, given any two nodes (vi,vj)" role="presentation">(vi,vj) , in which vi∈vj.children" role="presentation">vi∈vj.children.
Define a function REMOVET(vi)" role="presentation">REMOVET(vi) for T" role="presentation">T to remove vi" role="presentation">vi from T" role="presentation">T and merge vi.children" role="presentation">vi.children to vj.chileren" role="presentation">vj.chileren:
Definition 3.3. Following the setting in Definition 3.1, given any two nodes (vi,vj)" role="presentation">(vi,vj) , in which vi∈vj.children" role="presentation">vi∈vj.children and ∣Heigth(vj)−Height(vi)∣>1" role="presentation">∣Heigth(vj)−Height(vi)∣>1 .
Define a function FILL(vi,vj)" role="presentation">FILL(vi,vj) for T" role="presentation">T to insert a new node vε" role="presentation">vε between vi" role="presentation">vi and vj" role="presentation">vj :
Proposition 3.4. Let T be a coding tree after the second stage of Algorithm 1, and given two adjacent nodes (vi,vj)inT" role="presentation">(vi,vj)inT , in which vi∈vj.children" role="presentation">vi∈vj.children and ∣Heigth(vj)−Height(vi)∣>1" role="presentation">∣Heigth(vj)−Height(vi)∣>1 . Then, HT(G)=HTFILL(vi,vj)(G)" role="presentation">HT(G)=HTFILL(vi,vj)(G).
Proposition 3.5. Given a permutation matrix P∈{0,1}n×n" role="presentation">P∈{0,1}n×n , then SEP(A,H)=SEP(PAP⊤,PH)" role="presentation">SEP(A,H)=SEP(PAP⊤,PH) (i.e., SEP is permutation invariant).