-
C/C++常见的易模糊知识点(结构体、指针、STL)
语法
结构体对齐
三条规则
- 结构体中元素是按照定义顺序一个一个放到内存中去的,但
并不是紧密排列的。从结构体存储的首地址开始,每一个元素放置到内存中时,它都会认为内存是以它自己的大小来划分,因此元素放置的位置一定会在自己宽度的整数倍上开始(以结构体变量首地址为0计算)。 - 在经过第一原则分析后,检查计算出的存储单元是否为所有元素中
最宽的元素的长度的整数倍,是,则结束;若不是,则补齐为它的整数倍。 - 结构体成员为结构体对象时需要着重理解
分别举例
1. 自己的大小来划分
2. 宽的元素的长度的整数倍#includeusing namespace std; struct X { char a; int b; double c; }s1; struct Y { char a; double b; int c; }s2; void print1() { cout << sizeof(s1) << " "; cout << sizeof(s1.a) << " "; cout << sizeof(s1.b) << " "; cout << sizeof(s1.c) << endl; } void print2() { cout << sizeof(s2) << " "; cout << sizeof(s2.a) << " "; cout << sizeof(s2.b) << " "; cout << sizeof(s2.c) << endl; } int main() { cout << "顺序char int double " << endl; print1(); cout << "顺序char double int " << endl; print2(); // 1+(补7)+8+4 =20; 根据规则二不是 double(8) 的整数倍加4 return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
代码结果: 顺序char int double 16 1 4 8 # 规则一:1+(补3)+4+8=16 顺序char double int 24 1 8 4 #分析 1+(补7)+8+4 =20; 根据规则二不是 double(8) 的整数倍,需20+4=24- 1
- 2
- 3
- 4
- 5
图例


3.结构体成员为结构体对象时#includeusing namespace std; struct X { char a; int b; double c; }; struct Y { X b; char a; }; void print() { cout << "X 的内存大小为:" << sizeof(X) << endl; cout << "Y 的内存大小为:" << sizeof(Y) << endl; } int main () { print(); return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
代码结果: X 的内存大小为:16 # 1+(补3)+4+8=16 Y 的内存大小为:24 # b 前 a 后 :16+1+(补7,补至8的倍数) = 24 # 若 a 前 b 后:1+(补7,补至8的倍数)+16=24- 1
- 2
- 3
- 4
分析:
计算Y的存储长度时,在存放第二个元素b时的初始位置是在double型的长度8的整数倍处,而非16的整数倍处,即系统为b所分配的存储空间是第8~23个字节。
如果将Y的两个元素char型的a和X型的b调换定义顺序(b 前a 后),则系统为b分配的存储位置是第0~15个字节,为a分配的是第16个字节,加起来一共17个字节,不是最长基本类型double所占宽度8的整数倍,因此要补齐到8的整数倍,即24。修改默认对齐数
预处理指令: #pragma
#includeusing namespace std; struct s1 { double a; char b; int c; }; #pragma pack(4) //数据成员对齐数 = min( 修改后的默认对齐数(4) ,该数据类型大小 ) struct s2 { char a; struct s1 s11; double b; }; #pragma pack() int main() { printf("s1的大小:%d\n", sizeof(s1)); printf("s2的大小:%d\n", sizeof(s2)); return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
代码结果: s1的大小:16 s2的大小:28 # 1+(补3,补至4的倍数)+16+8=28- 1
- 2
- 3
分析:
- char a; // 地址从0开始,第一个字节存的是char
- struct s1 s11; // min( 4 ,max(double,char,int)) = 4 ,此时下标是1,1不是4的整数倍,补3个空字节,再存入s11(16个字节)
- double b; // min(4,8) = 4 ,此时下标是20,20是4的整数倍,再存入double
- 共存了1+3+16+8=28个字节,整体对齐数 = min(4,max( char, struct s1, double )) = 4,28是4的整数倍,不用补空字节。
int a[ ]中 a 与 &a区别
a 作为右值时与&a[0] 意义相同,代表数组首元素地址;
&a是取数组 a 的首地址,&a+1是 &a + 5*sizeof(int);
a 是首元素首地址,即&a[0];&a 是数组首地址,虽然数值上相同,但是意义不相同。#includeusing namespace std; int main() { int a[5] = {1,2,3,4,5}; int* ptr = (int* )(&a + 1); printf("%d,%d", *(a + 1), *(ptr - 1)); //2, 5 return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
捋清楚这个代码的结果
#includeusing namespace std; struct Test { int a; char* b; short c; char d[2]; short e[4]; }*p; int main() { cout << "sizrof(short) = " << sizeof(short) << endl; cout << "sizeof(struct Test) = " << sizeof(struct Test) << endl; cout << "sizeof(*p) = " << sizeof(*p) << endl; cout << "p = " << p << " p + 0x1 = " << p + 0x1 << endl; cout << "(unsigned long)p = " << p << " unsigned long)p + 0x1 = " << p + 0x1; return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
确定系统大小端
什么是大小端?
大端模式(Big.endian):字数据的高字节存储在低地址中,而字数据的低字节则存放在高地址中。
小端模式(Little_endian):字数据的高字节存储在高地址中,而字数据的低字节则存放在低地址中。图例
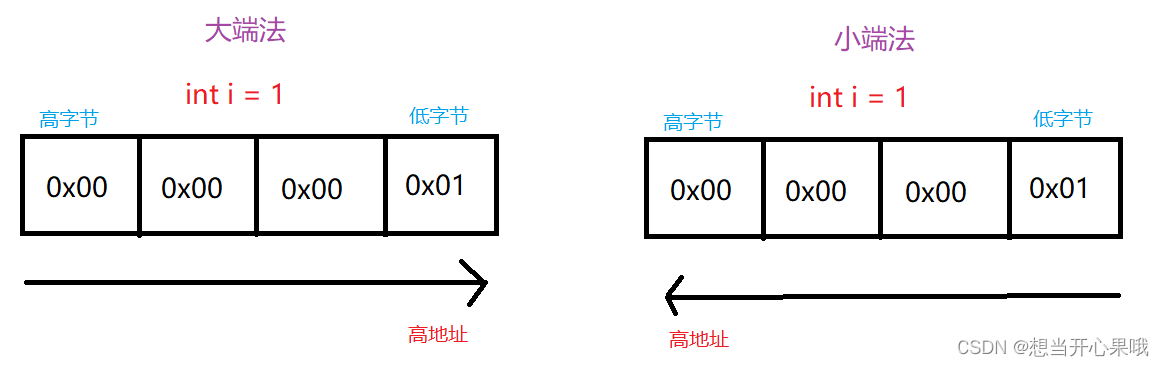
确定系统大小端代码#includeusing namespace std; int checkSystem() { union check{ int i; char ch; }c; c.i = 1; return (c.ch == 1); } int main () { int a = checkSystem(); cout << a; //输出为1 则为小端模式,0 则为大端模式 return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
一道考验题
在
大端模式与小端模式下的输出结果分别是什么?#includeusing namespace std; void print() { union check{ int i; char a[2]; }*p, u; p = &u; p->a[0] = 0x39; p->a[1] = 0x38; cout << "p->i = " << p->i; } int main() { print(); return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
小端模式下代码运行结果: p->i = 14393- 1
- 2
结果分析
3889(h) = 14393(d)

再来一道网络难题
计算一下输出结果!
#includeusing namespace std; int main() { int a[4] = {1,2,3,4}; int* ptr1 = (int* )(&a + 1); int* ptr2 = (int* )((long)a + 1); printf("%x, %x", ptr1[-1], *ptr2); return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
代码运行结果: 4, 2000000 # 在小端模式下 4, 100 # 在大端模式下- 1
- 2
- 3
分析

ptr1:将&a+1的值强制转换成int*类型,赋值给int*类型的变量 ptr,ptrl 肯定指到数组a的下一个int类型数据了。ptr1[-1]被解析成* (ptr1-1),即ptrl往后退4字节,所以其值为0x4。
ptr2:按照上面的讲解,(int)a+1的值是元素a[0]的第2个字节的地址,然后把这个地址强制转换成int*类型的值赋给ptr2,也就是说*ptr2的值应该为元素a[0]的第2个字节开始的连续4字节的内容。小端模式下

大端模式下

参考文章链接
二维数组
内存相当于尺子,最小单位为字节;二维数组也是存在尺子当中的。
看成这样很重要

来一道题
#includeusing namespace std; int main() { int a[3][2] = {(0,1), (2,3), (4,5)}; int* p = a[0]; /*for (int i = 0; i < 3; i++) { for (int j = 0; j < 2; j ++) cout << a[i][j] << " "; cout << endl; }*/ printf("%d", p[0]); //1 return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
分析
花括号里面嵌套的是小括号,而不是花括号!这里是花括号里面嵌套了逗号表达式, 其实这个赋值就相当于int a[3][2]={1, 3, 5}。- 1
- 2
再来一道号称很难做对的题 &p[4][2] - &a[4][2]
#includeint main() { int a[5][5]; int (*p)[4]; p = a; printf("a_ptr = %#p, p_ptr = %#p\n", &a[4][2], &p[4][2]); printf("%p, %d\n", &p[4][2] - &a[4][2], &p[4][2] - &a[4][2]); return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
代码运行结果: a_ptr = 0x7fff23bcfdc8, p_ptr = 0x7fff23bcfdb8 0xfffffffffffffffc, -4- 1
- 2
- 3
分析理解
- 首先明确数组名 a 作为右值时,代表数组首元素地址,即 a 代表 a[0]地址。
&a[4][2]表示的是&a[0][0]+4*5*sizeof(int)+ 2 * sizeof(int)。- p 是指向四个元素的数组指针,也就是说 p+1 表示指针 p 向后移动“包含4个int类型元素的数组”。
- 由于p被初始化为
&a[0],所以&p[4][2]表示的是&a[0][0]+4 *4sizeof(int)+2*sizeof(int)

二维数组与二维指针
二维数组参数与二维指针参数关系

函数指针
简单看下函数指针用法
#include#include char* fun(char* p1, char* p2) { int i = 0; i = strcmp(p1, p2); if (i == 0) return p1; else return p2; } int main() { char * (*pf)(char* p1, char* p2); pf = &fun; (*pf)("aa", "bb"); return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
理解
* (int* )&p = (int)Function做了什么#includevoid Function() { printf("call Function"); } int main() { void (*p)(); * (int* )&p = (int)Function; (*p)(); return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
分析
(int*)&p表示将地址强制转换成指向int类型数据的指针。(int)Function表示将函数的人口地址强制转换成int类型的数据。“* (int* ) &p= (int) Function;"表示将函数的人口地址赋值给指针变量p。
再来一个
(*(void(*)())0)()的理解分析:第1步:void( * ) (),可以明白这是-一个函数指针类型。这个函数没有参数,没有返回值;第2步:(void( * ) ())0,这是将0强制转换为函数指针类型,0是一个地址,也就是说一个函数保存在首地址为0的一段区域内;第3步:(*(void(*)())0),这是取0地址开始的一段内存里面的内容,其内容就是保存在首地址为0的一段区域内的函数;
-第4步:( * (void( * ) ())0)(),这是函数调用。
函数指针数组与函数指针数组指针
函数指针数组
char* (*pf)(char* p)不难理解!char* (*pf[3])(char* p)就是函数指针数组。
pf并非指针,而是一个数组名,数组存储了3个指向函数的指针
函数指针数组指针
char* (*(*pf)[3])(char* p)就是函数指针数组指针!!!
pf 是实实在在的指针,这个指针指向一个包含了3个元素的数组;这个数组里面存的是指向函数的指针
//指针函数数组指针的应用 #include#include char* func1(char* p) { printf("%s\n", p); return p; } char* func2(char* p) { printf("%s\n", p); return p; } char* func3(char* p) { printf("%s\n", p); return p; } int main() { char* (*a[3])(char* p); char* (*(*pf)[3])(char* p); pf = &a; a[0] = &func1; a[1] = &func2; a[2] = &func3; pf[0][0]("func1"); //等价(*pf)[0]("func1") pf[0][1]("func2"); pf[0][2]("func3"); return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
typedef
与回调函数相关的应用:C/C++ typedef 用法
STL标准库
List底层实现原理
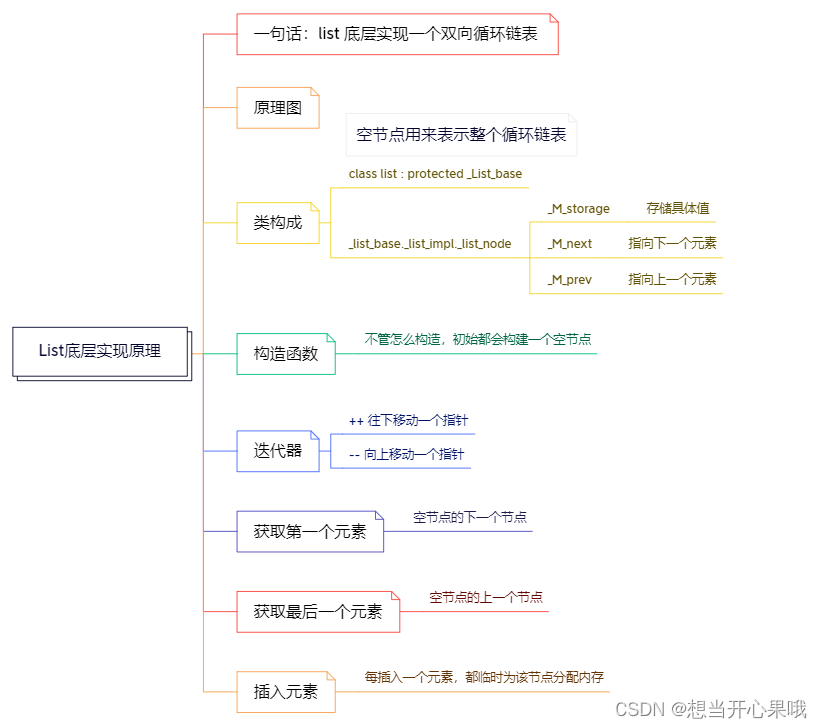
原理图

deque 底层原理

priority_queue 底层原理(容器适配器)

充电站
推荐一个零声学院免费公开课程,个人觉得老师讲得不错,分享给大家:Linux,Nginx,ZeroMQ,MySQL,Redis,fastdfs,MongoDB,ZK,流媒体,CDN,P2P,K8S,Docker,TCP/IP,协程,DPDK等技术内容,立即学习 - 结构体中元素是按照定义顺序一个一个放到内存中去的,但
-
相关阅读:
【TS】object类型
期货的含义及交易特点
【黑马头条】-day11热点文章实时计算-kafka-kafkaStream-Redis
【Linux】操作系统中的文件系统管理:磁盘结构、逻辑存储与文件访问机制
如何搭建一个好看的github主页
实现自动化获取1688商品详情数据接口经验分享
PMP备考大全:经典题库(敏捷管理第1期)
剑指offer-数组总结
基于PyQt5和GUI编程实现的实时图像获取及处理的人脸识别系统
Web Components详解-Shadow DOM样式控制
- 原文地址:https://blog.csdn.net/weixin_53492721/article/details/126302753
