-
论文详解 GLENet 增强型3D目标检测网络
 图 1:(a) 给定一个不完整 LiDAR 观测的对象,可能存在多个具有不同大小和形状的潜在合理的真实边界框。 (b) 当注释来自 2D 图像和部分点时,标签过程中的模糊和不准确是不可避免的。在给定的情况下,只有后部的汽车类别的类似点云可以用不同长度的不同真实值框进行注释,长度Length有非常明显的变化。
图 1:(a) 给定一个不完整 LiDAR 观测的对象,可能存在多个具有不同大小和形状的潜在合理的真实边界框。 (b) 当注释来自 2D 图像和部分点时,标签过程中的模糊和不准确是不可避免的。在给定的情况下,只有后部的汽车类别的类似点云可以用不同长度的不同真实值框进行注释,长度Length有非常明显的变化。在上述现象的推动下,还存在另一类概率检测器,它们明确考虑了标签模糊性的潜在影响。最后,这些方法可以分为两种范式,如图 2 所示,(b)范式倾向于输出边界框的概率分布,而不是直接以确定的方式回归确定的框坐标。例如,在高斯分布的假设下,检测头据此预测分布的均值和方差。为了监督这种概率模型,这些工作只是将真实边界框视为Dirac增量分布,然后在估计分布和真实值之间应用 KL 散度。
注:KL散度的概念来源于概率论和信息论中。KL散度又被称为:相对熵、互熵、鉴别信息。在机器学习、深度学习领域中,KL散度被广泛运用于变分自编码器中、EM算法、GAN网络中。在统计学意义上来说,KL散度可以用来衡量两个分布之间的差异程度。若两者差异越小,KL散度越小,反之亦反。当两分布一致时,其KL散度为0。正是因为其可以衡量两个分布之间的差异,所以在VAE、EM、GAN中均有使用到KL散度。
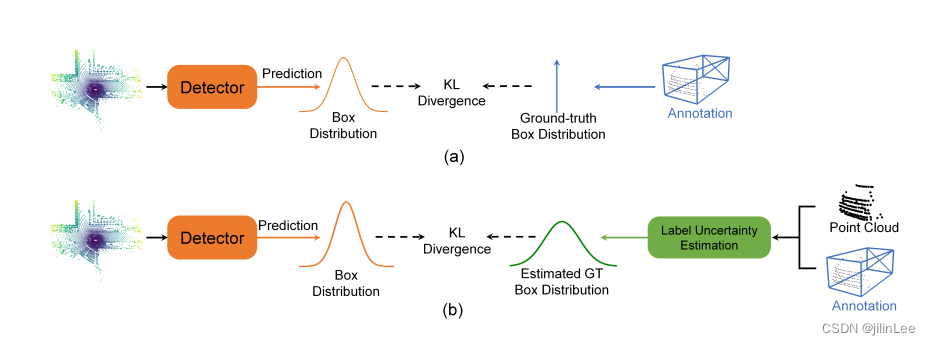 图 2:概
图 2:概 -
相关阅读:
基于nodejs+vue市民健身中心网上平台mysql
几种常见的分布式唯一ID生成方案简析
Flutter绘制拖尾效果
mysql大数据量 分页查询优化
基于C语言的操作系统(银行家算法、处理机管理、可变式分区管理、分页存储管理、进程同步模拟、生产消费者问题、哲学家就餐)
Redis -- Nosql
useGetState自定义hooks解决useState 异步回调获取不到最新值
月薪 3万人民币是一种怎样的体验?做自媒体可以达到这种水平吗
代理模式——设计模式
面试突击65:为什么要用HTTPS?它有什么优点?
- 原文地址:https://blog.csdn.net/puiopp63/article/details/126346787