-
《机器学习》李宏毅P1-2
机器学习引入
类比于生物的本能,我们可以为机器设置本能——即设定规则,这些规则通常称hand-crafted rules,叫做人设定的规则。
假设设计可以帮我们开关音乐的一个机器人,以这种做法就是:设立一条规则(写程序)。如果输入的句子里面看到“turn off”这个词汇,那chat-bot要做的事情就是把音乐关掉。
使用时,只要对chat-bot说,Please turn off the music 或can you turn off the music, Smart? 它就会把音乐关掉。看起来好像很聪明。但如果说please don‘t turn off the music,他还是会把音乐关掉。这里就出现了错误。这其实不是真正的人工智能。 使用hand-crafted rules时,由于没办法考虑到所有的可能性,因此非常的僵化,故而有以上所述缺点。
使用hand-crafted rules时,由于没办法考虑到所有的可能性,因此非常的僵化,故而有以上所述缺点。永远没有办法超过它的创造者人类:人类想不到,就没办法写规则,没有写规则,机器就不知道要怎么办。所以如果一个机器,它只能够按照人类所设定好的hand-crafted rules,它整个行为都是被规定好的,没有办法freestyle。如果是这样的话,它就没有办法超越创造他的人类。
希望创造的机器尽可能的智慧:对于大企业来说可以派以成千上万的工程师,用血汗的方式来建出数以万计的规则,然后让他的机器看起来好像很聪明。但是对于中小企业来说,这样建规则的方式反而是不利的。而机器学习发展,对比较小规模企业反而是更有利的。不需要非常大量的人来帮你想各式各样的规则,只要有data,就可以让机器来帮你做这件事情。
机器学习介绍
机器学习顾名思义,从名字就可以被猜出,就是让机器具有学习的能力。
人工智能是我们想要达成的目标,而机器学习是想要达成目标的手段,希望机器通过学习方式,使得他跟人一样聪明。
深度学习就是机器学习的其中一种方法。让机器他有自己学习的能力:讲的比较拟人化一点,就是写段程序,然后让机器人变得了很聪明,他就能够有学习的能力。接下来,你就像教一个婴儿、教一个小孩一样的教他,你并不是写程序让他做到这件事,你是写程序让它具有学习的能力。然后接下来,你就可以用像教小孩的方式告诉它。
- 假设你要叫他学会做语音辨识,你就告诉它这段声音是“Hi”,这段声音就是“How are you”,这段声音是“Good bye”。希望接下来它就学会了,你给它一个新的声音,它就可以帮你产生语音辨识的结果。
- 如果你希望他学会怎么做影像辨识,你可能不太需要改太多的程序。因为他本身就有这种学习的能力,你只是需要交换下告诉它:看到这张图片,你要说这是猴子;看到这张图片,然后说是猫;看到这张图片,可以说是狗。它具有影像辨识的能力,接下来看到它之前没有看过的猫,希望它可以认识。
如果讲的更务实一点的话,machine learning所做的事情,就是在寻找一个function,要让机器具有一个能力,这种能力是根据你提供给他的资料,它去寻找出我们要寻找的function。还有很多关键问题都可以想成是我们就是需要一个function。
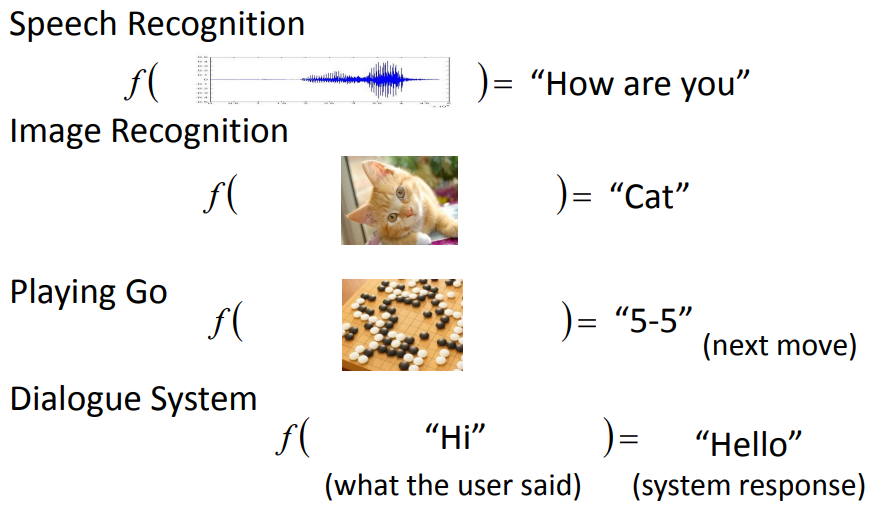
在语音辨识问题里面的function:输入是声音讯号,输出是语音辨识的文字。这个function非常非常的复杂,制定规则的方式60年代就有人做,但到现在都还没有做出来。不是人类所可以写出来,这是可以想象的。因此需要凭借的机器的力量找出这个function。
影像辨识问题中的function:输入一张图片,输出图片里面有什么样的东西。
Alpha GO的内在function:机器已知在十九×十九的棋盘上,哪些位置有黑子,哪些位置有白子。机器通过内在function告诉你,接下来下一步应该落子在哪。
一个聊天机器人内在function:输入就是使用者的input,它的输出就是机器的回应如何寻找function
以影像辨识为例,我们找个function输入一张图片,它告诉我们这个图片里面有什么样的东西。- 首先要准备一个function set(集合),这个function里面有成千上万的function。举例来说,这个function在里面,有一个f1,你给它看一只猫,它就告诉你输出猫,看一只狗就输出狗。有一个function f2它很怪,你给它看猫,它说是猴子;你给他看狗,它说是蛇。你要准备一个function set,这个function set里面有成千上万的function。这个function set就叫做model(模型)。

- 有了这个function set,接下来机器要做的事情是:通过一些训练资料告诉机器说一个好的function,它的输入输出应该是什么样子的,有什么样关系。如资料告诉机器在影像辨识问题中,如果看到这个猴子图要输出猴子,看到这个猫的图也要输出猫,看到这个狗的图,就要输出狗。根据这些训练资料,机器就可以判断某个function是好的还是不好的。
举例来说:在这个例子里面显然f1,他比较符合training data的叙述,比较符合我们的知识。所以f1看起来是比较好的。f2看起来是一个荒谬的function。如上所述的这个task叫做supervised learning(已知input和output去寻找合适的function)

上述学习过程如图所示

虽然机器有办法决定一个function的好坏,但光能够决定一个function的好坏是不够的,因为在function set里面,可能有成千上万的function,所以我们需要一个有效率的演算法,从function的set里面挑出最好的function——f*
找到f*之后,我们希望用它应用到一些场景中,比如:影像辨识,输入一张在机器没有看过的猫,然后希望输出也是猫——即机器具有举一反三的能力machine learning framework

左边这个部分叫training,学习过程;右边这个部分叫做testing,学好以后可以拿它做应用。
 整个machine learning framework整个过程分成了三个步骤
整个machine learning framework整个过程分成了三个步骤- 第一个步骤就是找一个function
- 第二个步骤让machine可以衡量一个function是好还是不好
- 第三个步骤是让machine有一个自动的方法,有一个好的演算法可以挑出最好的function。
机器学习相关的技术

监督学习
Regression(回归)
Regression是一种machine learning的task,当我们说:我们要做regression时的意思是,machine找到的function,它的输出是一个scalar(数值),这个叫做regression。
举例来说,比如说预测明天上午的PM2.5 ,也就是说找一个function,这个function的输出是未来某一个时间PM2.5的一个数值,这个是一个regression的问题。
机器要判断function明天上午的PM2.5输出,你要提供给它一些资讯,它才能够猜出明天上午的PM2.5。你给他资讯可能是今天上的PM2.5、昨天上午的PM2.5等等。这是一个function,它吃我们给它过去PM2.5的资料,它输出的是预测未来的PM2.5。Classification(分类)
Regression和Classification的差别就是我们要机器输出的类型不一样。在Regression中机器输出的是一个数值,在Classification里面机器输出的是类别。
假设Classification问题分成两种- 一种叫做二分类输出的是 : 是或否;
- 另一类叫做多分类(Multi-class),在Multi-class中是让机器做一个选择题,等于是给他数个选项,每个选项都是一个类别,让他从数个类别里选择正确的类别。
举例来说,二分类可以鉴别垃圾邮件将其放到垃圾箱。通过大量Data学习一个function,使其输入是一个邮件,输出为邮件是否为垃圾邮件。
多分类例子——文章分类,机器自动帮大量新闻按照其内容类型做分类。同样通过大量Data学习一个function,使其输入是一则新闻,输出是新闻属于哪个类别。若要训练这种机器就要准备很多训练资料(Training Data),然后给它新的文章,机器能给你正确的结果。deep learning
刚才讲的都是让machine去解的任务,接下来要讲的是在解任务的过程中第一步就是要选择function set,选不同的function set就是选不同的model。
Model有很多种,最简单的就是线性模型,但我们会花很多时间在非线性的模型上。在非线性的模型中最耳熟能详的就是Deep learning。
在做Deep learning时,它的function是特别复杂的,所以可以做特别复杂的事情。比如它可以做影像辨识,这个复杂的function可以描述pixel和class之间的关系
例如下围棋问题:

除了deep learning 以外还有很多machine learning的model也是非线性的模型。
半监督学习
监督学习的问题是需要大量的training data。training data告诉我们要找的function的input和output之间的关系。如果我们在监督学习下进行学习,我们需要告诉机器function的input和output是什么。这个output往往没有办法用很自然的方式取得,需要人工的力量把它标注出来,这些function的output叫做label。
为了减少label的量,减少人工工作量,引入半监督学习。
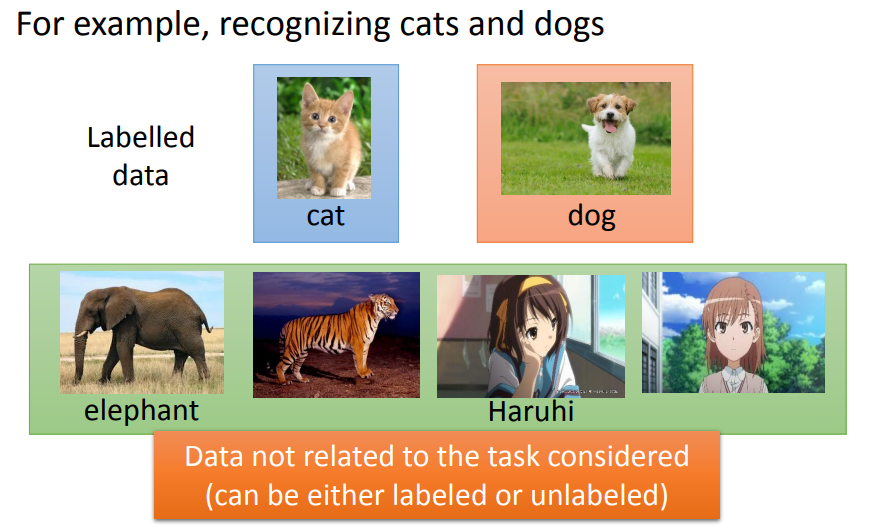
假设你先想让机器鉴别猫狗的不同。你想做一个分类器让它告诉你,图片上是猫还是狗。你有少量的猫和狗的labelled data,但是同时你又有大量的Unlabeled data,但是你没有力气去告诉机器说哪些是猫哪些是狗。在半监督学习的技术中,这些没有label的data,他可能也是对学习有帮助。
迁移学习
另外一个减少data用量的方向是迁移学习。
迁移学习的意思是:假设我们要做猫和狗的分类问题,只有少量的有label的data。但是我们现在有大量的data,这些大量的data中可能有label也可能没有label。但是他跟我们现在要考虑的问题是没有什么特别的关系的,我们要分辨的是猫和狗的不同,但是这边有一大堆其他动物的图片还是动画图片,你有这一大堆不相干的图片,它到底可以带来什么帮助。这个就是迁移学习要讲的问题。
无监督学习
更加进阶的就是无监督学习,我们希望机器可以学到无师自通。
如果在完全没有任何label的情况下,到底机器可以学到什么样的事情。举例来说,如果我们给机器看大量的文章(在去网络上收集站文章很容易,网络上随便爬就可以)让机器看过大量的文章以后,它到底可以学到什么事情。它能不能够学会每一个词汇的意思,要让机器学会每一个词汇的意思,即输入词汇,输出词义or向量表示or else
监督学习中的结构化学习
structured learning 中让机器输出的是要有结构性的
举例来说:在语音辨识里面,机器输入是声音讯号,输出是一个句子。句子是要很多词汇拼凑完成。它是一个有结构性的object。
或者是说在机器翻译里面你说一句话,你输入中文希望机器翻成英文,它的输出也是有结构性的。
或者人脸辨识,来给机器看张图片,它会知道说最左边是长门,中间是凉宫春日,右边是宝玖瑠。然后机器要把这些东西标出来,这也是一个structure learning问题。

其实多数人可能都听过regression,也听过classification,你可能不见得听过structure learning。很多教科书都直接说,machine learning是两大类的问题,regression,和classification。
真正世界还应该包括structure learning,这里面还有很多问题是没有探究的.reinforcement learning
若将强化学习和监督学习进行比较时
监督学习的训练方式:告诉机器正确答案,让他直接学习答案。
加强学习的训练方式:机器通过评分得知学习结果的好坏,自己进行改进。一个聊天机器人的训练示例:
用监督学习的方法来训练一个聊天机器人:告诉机器,当使用者说hello时说hi,当使用者说byebye时说good bye。。。
用reinforcement learning方法来训练一个聊天机器人:让机器直接和人类对话,如果人类不满意,机器就知道刚才做错了,但不知道是哪里错了,因此它就要回去反省检讨哪一步做的不好。机器要在reinforcement learning的情况下学习,机器是非常intelligence的。 reinforcement learning也是比较符合我们人类真正的学习的情景,这是你在学校里面的学习老师会告诉你答案,但在真实社会中没人回告诉你正确答案。你只知道你做得好还是做得不好.
以Alpha Go为例:
supervised learning就是根据棋谱数据告诉机器:看到这个盘式你就下“5-5”,看到这个盘式你就下“3-3”等等
reinforcement learning的意思是:机器跟对手互下,机器会不断的下棋,最后赢了,机器就会知道下的不错,但是究竟是哪里可以使它赢,它其实是不知道的。
Alpha Go其实是用监督学习加上reinforcement learning去学习的。先用棋谱做监督学习,然后在做reinforcement learning,但是reinforcement learning需要一个对手,如果使用人当对手就会很让费时间,所以机器的对手是另外一个机器。总结

同样的颜色不同的方块是同一个类型的,这边的蓝色的方块,指的是学习的情景,通常学习的情景是你没有办法控制的。比如,因为我们没有data做监督学习,所以我们才做reinforcement learning。现在因为Alpha Go比较火,所以Alpha Go中用到的reinforcement learning会被认为比较潮。reinforcement learning就是我们没有办法做监督学习的时候,我们才做reinforcement learning。
红色的是指你的task,你要解的问题,你要解的这个问题随着你用的方程的不同,有regression、有classification、有structured。所以在不同的情境下,都有可能要解这个task。
在这些不同task里面有不同的model,用绿色的方块表示。 -
相关阅读:
我的256天创作纪念日
【MyBatis】初识这一优秀的持久层框架
STCH8高级PWM定时器输入捕获功能脉宽测量
npm run build 打包报错 - 添加 parallel: false, 解决
DO280管理和监控OpenShift平台--资源限制
MILP(混合整数线性规划)
【活动通知】2023 Elastic Meetup 北京站将于12月2日下午1点30在北京召开
【Unity程序技巧】2D音乐中心管理器
电机开源驱动器基本操作与实现
【构建ML驱动的应用程序】第 11 章 :监控和更新模型
- 原文地址:https://blog.csdn.net/qq_39848541/article/details/126346358