-
一文速学-时间序列分析算法之加权移动平均法详解+Python代码实现
目录
前言
时间序列法并不属于机器学习而是统计分析法,供预测用的历史数据资料有的变化表现出比较强的规律性,由于它过去的变动趋势将会连续到未来,这样就可以直接利用过去的变动趋势预测未来。但多数的历史数据由于受偶然性因素的影响,其变化不太规则。利用这些资料时,要消除偶然性因素的影响,把时间序列作为随机变量序列,采用算术平均、加权平均和指数平均等来减少偶然因素,提高预测的准确性。

在上篇文章已经具体介绍了一次移动平均法和二次移动平均法详解+实例代码
一文速学-时间序列分析算法之一次移动平均法和二次移动平均法详解+实例代码
接下来也是紧接着平滑法的第三中算法,加权移动平均法。
一、加权移动平均法
在简单移动平均公式中,每期数据在求平均时的作用是等同的。但是,每期数据所包含的信息量不一样,近期数据包含着更多关于未来情况的信心。因此,把各期数据等同看待是不尽合理的,应考虑各期数据的重要性,对近期数据给予较大的权重,这就 是加权移动平均法的基本思想。
根据我的上篇文章我们明白移动平均法基本上是在平均值的基础上进行预测。一般来说若经济变量在某一值上下波动情况以及升降缓慢预测效果比较好,反之误差比较大。
1.计算公式
设时间序列为
 加权移动平均公式为:
加权移动平均公式为: ,
,
公式中
 为t期加权移动平均数:
为t期加权移动平均数: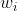 为
为 的权数,它体现了相应的
的权数,它体现了相应的 在加权平均数的重要性。
在加权平均数的重要性。利用加权移动平均数来做预测,其预测公式为:

即以第t期加权平均数作为t+1期的预测值
那么我们以实际案例来使用运算:
2.示例运用
以在某化学反应里,测得生成物浓度y(%)与时间t(min)的数据为例子:

我们取时间窗口为5,则权重我们设置为
 .按照预测公式为:
.按照预测公式为:代码:
- #输入x为预测集、n为时间窗口、w为设置权重,m为预测时间
- def weighting_shift(x,n,w,m):
- num=0
- sum=0
- for i in range(n):
- num=w[i]+num
- sum=w[i]*x[m-i-2]+sum
- y=sum/num
- return y
输入预测下一个值,也就是
 为:8.17。这个预测值偏低但是我们可以使用相对误差进行修正:
为:8.17。这个预测值偏低但是我们可以使用相对误差进行修正:例如:我们要预测

- #输入x为预测集、n为时间窗口、w为设置权重,m为预测时间
- def weighting_shift(x,n,w,m):
- num=0
- sum=0
- for i in range(n):
- num=w[i]+num
- sum=w[i]*x[m-i-2]+sum
- y=sum/num
- return y
- w=[5,4,3,2,1]
- weighting_shift(y,5,w,16)

3.误差修正
的相对误差为:
我们将所有的误差放到一张表上面:
- #输入时间窗口
- def get_error(x,n,w):
- y_error=[]
- for i in range(x.size-n):
- y=weighting_shift(x,n,w,n+i+1)
- y_error.append((x[n+i]-y)/x[n-1+i])
- return y_error

那么我们再计算总的平均相对误差:

- list_y=[]
- #输入x为预测集、n为时间窗口、w为设置权重,m为预测时间
- def weighting_shifts(x,n,w,m):
- num=0
- sum=0
- for i in range(n):
- num=w[i]+num
- sum=w[i]*x[m-i-2]+sum
- y=sum/num
- return y
- for i in range(6,16):
- list_y.append(weighting_shifts(y,5,w,i))
- y=y[5:15]
- def mean_shift(list_y,y):
- sum1=0
- sum2=0
- y=list(y)
- for i in range(len(list_y)):
- sum1=sum1+list_y[i]
- sum2=sum2+y[i]
- error_mean=(1-sum1/sum2)
- return error_mean
- mean_shift(list_y,y)
之后将我们求得的 :

 ,还是得按照趋势来加权,否则就像这样就算平滑相对误差也得不到相对准确的值。
,还是得按照趋势来加权,否则就像这样就算平滑相对误差也得不到相对准确的值。在加权移动平均法中,
 的选择,同样具有一定的经验性。一般的原则是:近期数据的权数大,远期数据的权数小。至于大到什么程度和小到什么程度,则需要按照预 测者对序列的了解和分析来确定。
的选择,同样具有一定的经验性。一般的原则是:近期数据的权数大,远期数据的权数小。至于大到什么程度和小到什么程度,则需要按照预 测者对序列的了解和分析来确定。
点关注,防走丢,如有纰漏之处,请留言指教,非常感谢
以上就是本期全部内容。我是fanstuck ,有问题大家随时留言讨论 ,我们下期见。
-
相关阅读:
SDK 资源
红黑树(RBT)
AttributeError: ‘bytes‘ object has no attribute ‘encode‘异常解决方案
高压电气系统验证
PCB元件创建
力扣名企直通车-学习计划-网易-刷题记录
Next.js(React应用开发框架)实战——路由(一)
【Prometheus】Prometheus的k8s部署
OSPF基础(二):OSPF区域、router-ID、度量值、修改度量值的方法、OSPF协议报文类型、OSPF邻接关系建立过程
高端制造企业生产设备文件管理,怎样保证好用不丢失文件?
- 原文地址:https://blog.csdn.net/master_hunter/article/details/126341845
