-
目标检测之概述-笔记整理
什么是目标检测
- 目标检测(Object Detection)的任务是找出图像中所有感兴趣的目标(物体),确定它们的类别和位置。
例子:确定某张给定图像中是否存在给定类别(比如人、车、自行车、狗和猫)的目标实例;如果存在,就返回每个目标实例的空间位置和覆盖范围。作为图像理解和计算机视觉的基石,目标检测是解决分割、场景理解、目标追踪、图像描述、事件检测和活动识别等更复杂更高层次的视觉任务的基础。
目标检测的应用场景
目标检测具有巨大的实用价值和应用前景。
-
应用领域包括人脸检测、行人检测、车辆检测、卫星图像中道路的检测、车载摄像机图像中的障碍物检测、医学影像在的病灶检测等。
-
应用场景包括长/视频领域、医学场景、安防领域、自动驾驶等等众多领域
行人车辆检测

多人脸的检测:

目标检测的实用价值
这里我们举一些使用的场景
- 在视频中去进行检测明星人物,检测出某明星的视频只看他的视频。类似在爱奇艺中的只看他功能快速筛选仅有明星出现的片段。
目标检测算法介绍

算法分类
- 两步走的目标检测:先进行区域推荐,而后进行目标分类
包含一个用于区域提议的预处理步骤,使得整体流程是两级式的。代表:R-CNN、SPP-Net、Fast R-CNN、Faster R-CNN和R-FCN等
- 端到端的目标检测:直接在网络中提取特征来预测物体分类和位置
即无区域提议的框架,这是一种单独提出的方法,不会将检测提议分开,使得整个流程是单级式的。代表:OverFeat、YOLOv1、YOLOv2、YOLOv3、SSD和RetinaNet等

几种类别结构xmind形式如下:

目标检测的任务
- 分类:
- N个类别
- 输入:图片
- 输出:类别标签
- 评估指标:Accuracy

- 定位:
- N个类别
- 输入:图片
- 输出:物体的位置坐标
- 主要评估指标:IOU

其中我们得出来的(x,y,w,h)有一个专业的名词,叫做bounding box(bbox).
- 物体位置:
- x, y, w,h:x,y物体的中心点位置,以及中心点距离物体两边的长宽
- xmin, ymin, xmax, ymax:物体位置的左上角、右下角坐标
目标定位的简单实现思路
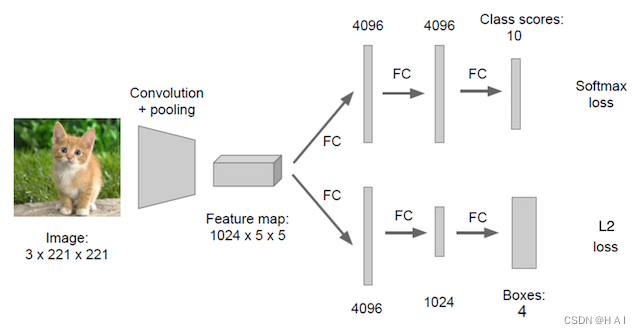
在分类的时候我们直接输出各个类别的概率,如果再加上定位的话,我们可以考虑在网络的最后输出加上位置信息。下面我们考虑图中只有一个物体的检测时候,我们可以有以下方法去进行训练我们的模型
回归位置
增加一个全连接层,即为FC1、FC2
-
FC1:作为类别的输出
-
FC2:作为这个物体位置数值的输出

假设有10个类别,输出[p1,p2,p3,...,p10],然后输出这一个对象的四个位置信息[x,y,w,h]。同理知道要网络输出什么,如果衡量整个网络的损失
- 对于分类的概率,还是使用交叉熵损失
- 位置信息具体的数值,可使用MSE均方误差损失(L2损失)
两种Bounding box名称
在目标检测当中,对bbox主要由两种类别。
- Ground-truth bounding box:图片当中真实标记的框
- Predicted bounding box:预测的时候标记的框

一般在目标检测当中,我们预测的框有可能很多个,真实框GT也有很多个。
目标检测在很多领域都有应用需求,包括人脸检测,行人检测,车辆检测以及遥感影像中的重要地物检测等。
-
相关阅读:
Nodejs系列之模块成员导出与导入
Alexa染料标记RNA核糖核酸|RNA-Alexa 514|RNA-Alexa 488|RNA-Alexa 430
ASM字节码插桩解决国内隐私问题
代码随想录刷题 Day14
Leetcode.2591 将钱分给最多的儿童
LangChain与WebSocket:实时通信的新纪元
痞子衡嵌入式:恩智浦i.MX RTxxx系列MCU启动那些事(7)- 从SD/eMMC启动
【golang】调度系列之m
第四章 文件管理 九、文件系统的层次结构
音视频封装格式:AAC音频基础和ADTS打包方案详解
- 原文地址:https://blog.csdn.net/weixin_44199723/article/details/126340326