实时数据仓库(总结)
1. 开源实时数仓和离线数仓的区别
-
API计算引擎
离线数据仓库主要使用hive sql 和spark sql进行开发
实时数据仓库主要是使用flink sql开发
-
数据存储
离线数据仓库保存在hdfs上
实时数据仓库的流表的数据保存在kafka中,维表的数据保存在hbase。或者mysql中
-
数据仓库分层
离线数据仓库和实时数据仓库分层的规则基本一致,离线数据仓库在构建模型时,会尽量构建公共表,减少重复计算ODS,DWD,DWS,ADS
实时数据仓库在做模型开发的时候会尽量减少使用中间层,可以降低数据的延迟,
-
数据延时
离线一般采用T+1模式,第二天计算前一天的数据,在项目中一般到第二天早上6点左右才能将前一天的数据处理完
实时的延时一般在秒级别或者在分钟级别
-
架构
离线:hive,hadoop,spark,调度,离线涉及的组件比较少,不容易问题,出现问题容易解决
实时:hive,kadoop,kafka,zookeeper,flink,hbase,mysql,监控,出现问题不好定位,为什么用到这么多组件:目前还没有一个成熟的开源的实时数据仓库的解决方案
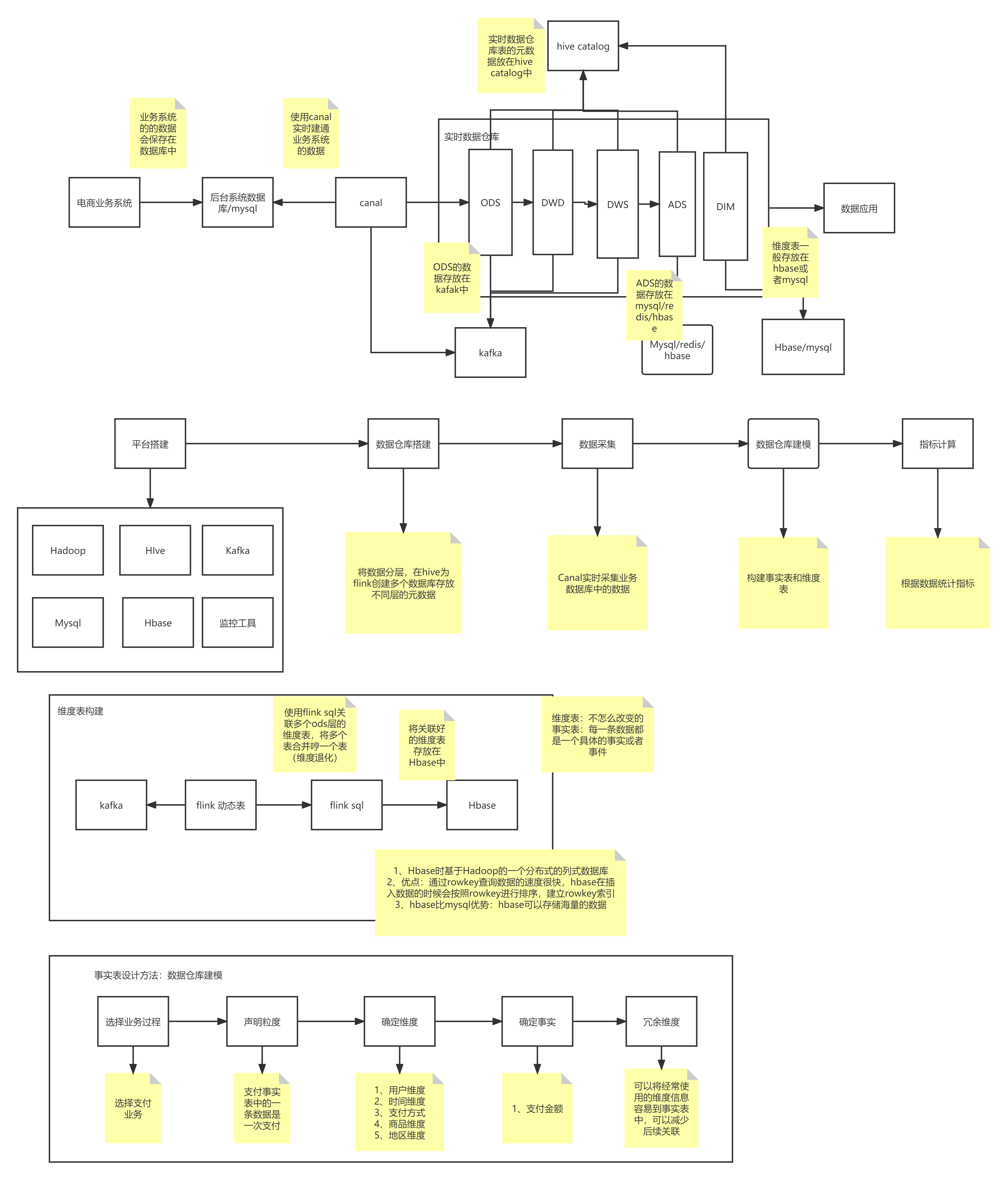
2. 项目架构
-
数据源:电商的业务会产生数据,数据保存在数据库中,数据库汇总的数据会不断的插入和更新
-
数据采集:使用canal实时监控mysql binlog 日志,将数据实时写到kafka中,数据写入的格式为 canal-json
-
数据存储
-
ODS,DWD,DWS的数据保存在kafka中
-
DIM和ADS数据保存在mysql或者hbase中
-
kafka中的数据默认保存7天,但是我们在项目中一般设置为3天
同时每个分区默认设置两个副本。mysql中的数据量最好不要超过500万条
-
-
数据处理:使用flink sql处理,注意流表和维表关联的问题
-
数据应用 BI api:需要使用spring boot 代码对应一个表
3. 功能模块
-
ODS:
使用canal采集数据,在flink sql中建表,一个topic对应一个表
-
DWD:
- 在dwd主要涉及到建模
- 数据仓库建模使用的是星形建模
- 事实表建模流程:
- 选择业务过程,选择公司的业务线创建表
- 声明粒度:确定每一行数据的函数,是每次还是每天,每月
- 确定维度:维度是后面进行指标计算的分组条件,比如时间维度,地区维度,用户维度,商品维度
- 确定实时:金额,数量
- 冗余维度:为了减少关联可以在事实表中将维度表中的信息冗余进来,比如将用户的年龄,籍贯等信息融入到事实表中
- 支付事实表
- 订单事实表
-
DIM:维度建模
- 维度退化:将多个维度退化成一个维度表
- 确定主维度
- 确定维度信息
-
ADS:
- 基于dwd层或者dws层的事实表统计指标
- 将统计好的指标统计到mysql中
- 供上层应用使用
- 支付类指标
- 订单类