pandas学习(四) apply
- .apply() Pandas 的 apply() 方法是用来调用一个函数(Python method),让此函数对数据对象进行批量处理。
- .to_datatime 将给定的数据按照指定格式转换成日期格式
- .resample,重新采样,是对原样本重新处理的一个方法,是一个对常规时间序列数据重新采样和频率转换的便捷的方法。
- dataframe.idxmax(),函数返回在请求的轴上第一次出现最大值的索引
1.数据集1
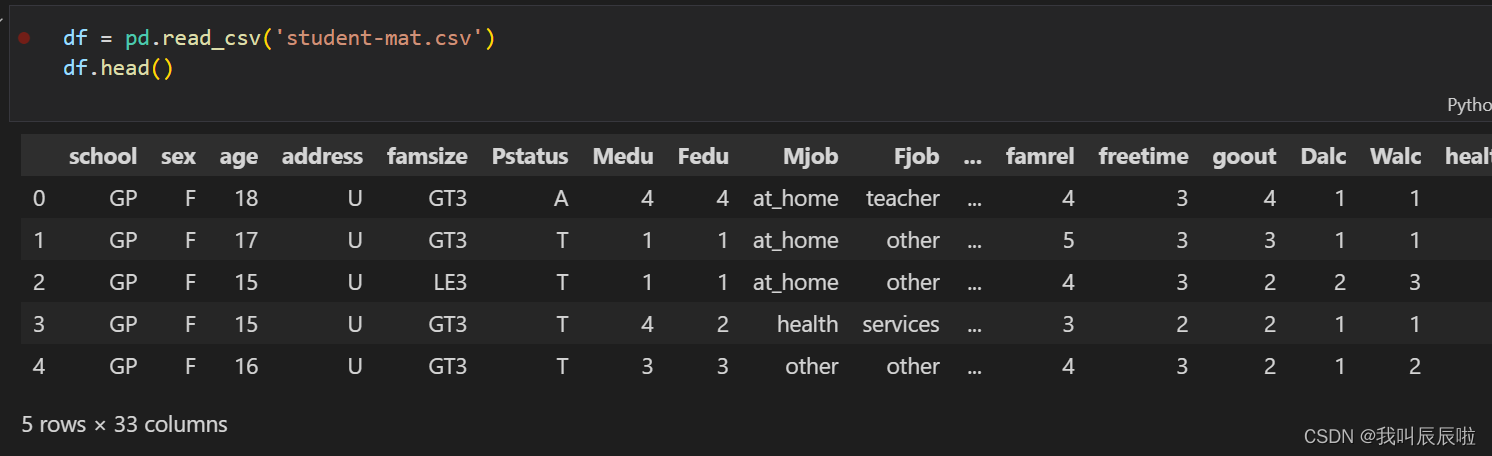
1.1将数据从“学校”切片到“监护人”列
stud_alcoh = df.loc[: , "school":"guardian"]
stud_alcoh.head()
1.2 写一个lambda函数可以使得首字母大写
capitalizer = lambda x: x.capitalize()
stud_alcoh['Mjob'].apply(capitalizer)
stud_alcoh['Fjob'].apply(capitalizer)
1.3 需要赋值才能使得原数据集值更改
stud_alcoh['Mjob'] = stud_alcoh['Mjob'].apply(capitalizer)
stud_alcoh['Fjob'] = stud_alcoh['Fjob'].apply(capitalizer)
stud_alcoh.tail()
1.4 创建一个名为“majority”的函数,该函数将布尔值返回到名为 legal_drinker 的新列
def majority(x):
if x > 17:
return True
else:
return False
stud_alcoh['legal_drinker'] = stud_alcoh['age'].apply(majority)
stud_alcoh.head()
1.5 数据集的值乘以10
def times10(x):
if type(x) is int:
return 10 * x
return x
stud_alcoh.applymap(times10).head(10)
2.数据集2

是否注意到年份的类型是 int64。但是pandas有一种不同的类型来使用时间序列
2.1 将 Year 转换为 datetime64
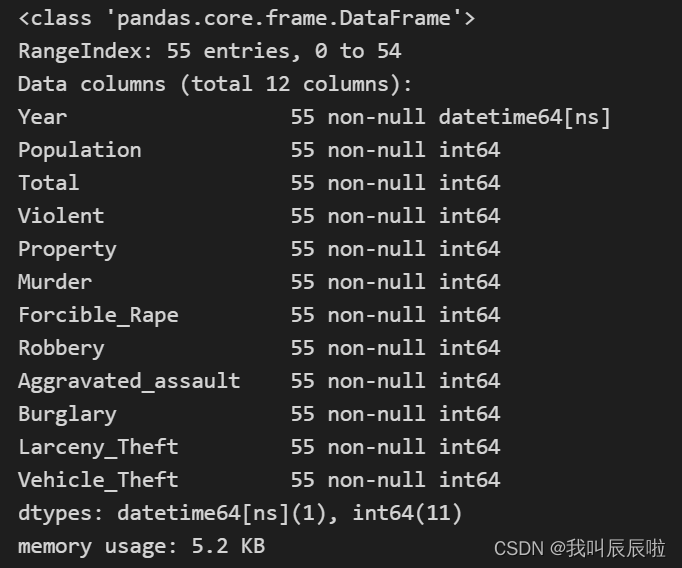
crime.Year = pd.to_datetime(crime.Year, format='%Y')
crime.info()
2.2 设置Year作为dataframe的index
crime = crime.set_index('Year', drop = True)
crime.head()

2.3 按十年对年份进行分组并对值求和
crimes = crime.resample('10AS').sum()
population = crime['Population'].resample('10AS').max()
crimes['Population'] = population
crimes

2.4 在美国生活最危险的十年是什么?
crime.idxmax(0)
