-
Zookeeper实战、选举原理、分布式锁原理
Zookeeper实战
基于springboot对操作zookeeper,加深学习印象
Zookeeper Java客户端
- 第一步当然是导入依赖
<dependency> <groupId>org.apache.zookeepergroupId> <artifactId>zookeeperartifactId> <version>3.8.0version> dependency>- 1
- 2
- 3
- 4
- 5
- 创建客户端连接zk
编写测试类:
@Slf4j public class ZookeeperTest { private static final String ZK_ADDRESS="192.168.109.200:2181"; private static final int SESSION_TIMEOUT = 5000; private static ZooKeeper zooKeeper; private static final String ZK_NODE="/zk‐node"; @Before public void init() throws IOException, InterruptedException { final CountDownLatch countDownLatch = new CountDownLatch(1); zooKeeper = new ZooKeeper(ZK_ADDRESS, SESSION_TIMEOUT, new Watcher() { public void process(WatchedEvent watchedEvent) { if (watchedEvent.getState() == Event.KeeperState.SyncConnected && watchedEvent.getType() == Event.EventType.None){ countDownLatch.countDown(); log.info("连接成功"); } } }); log.info("连接中"); countDownLatch.await(); } @Test public void createTest() throws KeeperException, InterruptedException { String path = zooKeeper.create(ZK_NODE, "测试数据".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL); log.info("path{}",path); } @Test public void createAsynTest() throws KeeperException, InterruptedException { zooKeeper.create(ZK_NODE, "测试数据".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT,(rc, path, ctx, name) -> log.info("rc {},path {},ctx {},name {}",rc,path,ctx,name),"context"); //log.info("path{}",path); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
Apache Curator 开源客户端
什么是 Curator
Curator 是一套由netflix 公司开源的,Java 语言编程的 ZooKeeper 客户端框架,Curator项目 是现在ZooKeeper 客户端中使用最多,对ZooKeeper 版本支持最好的第三方客户端,并推荐使 用,Curator 把我们平时常用的很多ZooKeeper 服务开发功能做了封装,例如 Leader 选举、 分布式计数器、分布式锁。这就减少了技术人员在使用 ZooKeeper 时的大部分底层细节开发工 作。在会话重新连接、Watch 反复注册、多种异常处理等使用场景中,用原生的 ZooKeeper 处理比较复杂。而在使用 Curator 时,由于其对这些功能都做了高度的封装,使用起来更加简 单,不但减少了开发时间,而且增强了程序的可靠性。
Curator 实战
这里我们以 Maven 工程为例,首先要引入Curator 框架相关的开发包,这里为了方便测试引入 了junit ,lombok,由于Zookeeper本身以来了 log4j 日志框架,所以这里可以创建对应的 log4j配置文件后直接使用。 如下面的代码所示,我们通过将 Curator 相关的引用包配置到 Maven 工程的 pom 文件中,将 Curaotr 框架引用到工程项目里,在配置文件中分别引用了两 个 Curator 相关的包,第一个是 curator-framework 包,该包是对 ZooKeeper 底层 API 的一 些封装。另一个是 curator-recipes 包,该包封装了一些 ZooKeeper 服务的高级特性,如: Cache 事件监听、选举、分布式锁、分布式 Barrier。
pom
<dependency> <groupId>org.apache.curatorgroupId> <artifactId>curator-recipesartifactId> <exclusions> <exclusion> <groupId>org.apache.zookeepergroupId> <artifactId>zookeeperartifactId> exclusion> exclusions> <version>5.2.1version> dependency>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
测试
@Slf4j public class CuratorTest { @Test public void test(){ //重试策略,当客户端异常退出或者与服务端失去连接的时候,可以通过设置客户端 重新连接 ZooKeeper 服务端。而 Curator 提供了 一次重试、多次重试等不同种类的实现方 式。在 Curator 内部, // 可以通过判断服务器返回的 keeperException 的状态代码来判断是否进 行重试处理,如果返回的是 OK 表示一切操作都没有问题,而 SYSTEMERROR 表示系统或服务 端错误 RetryPolicy retryPolicy = new ExponentialBackoffRetry(1000, 3); //connectString 服务端地址,可以多个,用,隔开;host1:port1,host2:port2,host3;port3 CuratorFramework client = CuratorFrameworkFactory.newClient("ddf0",retryPolicy); client.start(); } @Test public void test1(){ //流式方式 RetryPolicy retryPolicy = new ExponentialBackoffRetry(1000, 3); CuratorFramework client1 = CuratorFrameworkFactory.builder() .connectString("ip") .sessionTimeoutMs(5000) .connectionTimeoutMs(500) .retryPolicy(retryPolicy) .namespace("base") .build(); client1.start(); //创建结点 client1.create().forPath("/test"); //指定结点类型 client1.create().withMode(CreateMode.CONTAINER).forPath("/t"); //一次性创建多个结点 String pathWithParent = "/testt/chien"; client1.create().creatingParentsIfNeeded().forPath(pathWithParent); //获取数据 byte[] bytes = client1.getData().forPath(pathWithParent); log.info("{}",new String(bytes)); //删除结点, client1.delete().guaranteed().deletingChildrenIfNeeded().forPath(pathWithParent); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
异步接口;
Curator 引入了BackgroundCallback 接口,用来处理服务器端返回来的信息,这个处理过程是 在异步线程中调用,默认在 EventThread 中调用,也可以自定义线程池。
//异步 client1.getData().inBackground((item1, item2)->{ log.info("ddd"); }).forPath("/path"); ExecutorService executorService = Executors.newSingleThreadExecutor(); //指定线程池 client1.getData().inBackground((item1, item2)->{ log.info("ddd"); }, executorService).forPath("/path"); //监听器 client1.getData().inBackground().withUnhandledErrorListener((item1, item2)->{}).forPath("/path"); //Curator 引入了 Cache 来实现对 Zookeeper 服务端事件监听,Cache 事件监听可以理解为一 // 个本地缓存视图与远程 Zookeeper 视图的对比过程。Cache 提供了反复注册的功能。 // Cache 分 为两类注册类型:节点监听和子节点监听。 //1、Node Cache client1.create().creatingParentsIfNeeded().forPath("/path"); CuratorCache.build(client1, "/path") .listenable().addListener((type, oldData, data) -> log.info("{} path nodeChanged: new data{}","/path",data));- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
Zookeeper集群
ZK 有三种角色:
Leader: 处理所有的事务请求(写请求),可以处理读请求,集群中只能有一个Leader
Follower:只能处理读请求,同时作为 Leader的候选节点,即如果Leader宕机,Follower节点
要参与到新的Leader选举中,有可能成为新的Leader节点。
Observer:只能处理读请求。不能参与选举

说到这里,就不得不聊聊CAP了;根据这三种角色;能不能推出ZK 是什么原则呢?
首先:既然主从了,那必然会有数据持久化同步,zk是怎么做的呢?超过半数以上的follow节点持久化成功才会返回成功响应;这就推出---------------》C :一致性;虽然不是强一致性,但是必然保证了最终一致性!
有了C,然后再从A、P 之中选一个;Zk是怎么选的呢?
zk在集群如果遇到leader节点挂点的话;会触发选举操作;在这期间是不会对外提供服务的,也就是说:并不高可用;没有A,所以:zk采用的原则是CP原则;一致性和分区容忍性;
如果其中一台机器突发情况挂掉了的话,整个系统并不会受到太大的影响,也就保证了P!
Leader选举原理

总结:
当发现集群中leader挂了之后,各节点开始进行选举;首先将投票信息组成一个二元祖,将自己投出去,
当收到别的节点发来的投票时,进行比较;优先选择zxid大的(事务数据较多);如果一样大的话就比较myid!投myid比较大的选票;
判断选票数量是否超过半数,超过半数选举结束!

Zookeeper经典应用场景
分布式锁
zookeeper中的锁分为两种;公平锁和非公平锁
- 非公平锁:
流程:判断锁节点是否存在;不存在说明可以创建该节点,存在的话只能监听该节点,等该节点触发删除时间后再去竞争锁;
不存在就创建锁,当然这一过程可能有多个线程同时去创建,所以还要判断是否创建成功;没创建成功则继续监听该节点,等待其被删除释放;
创建成功;说明获取锁成功,进行接下来的业务,业务执行完毕之后删除节点,唤醒正在监听的线程去竞争锁资源!
可以发现:这种模式的锁有一个很大的问题:会导致同时一刻有一堆线程去争抢锁资源,有的运气不好可能永远都拿不到锁;会导致一种羊群效应;

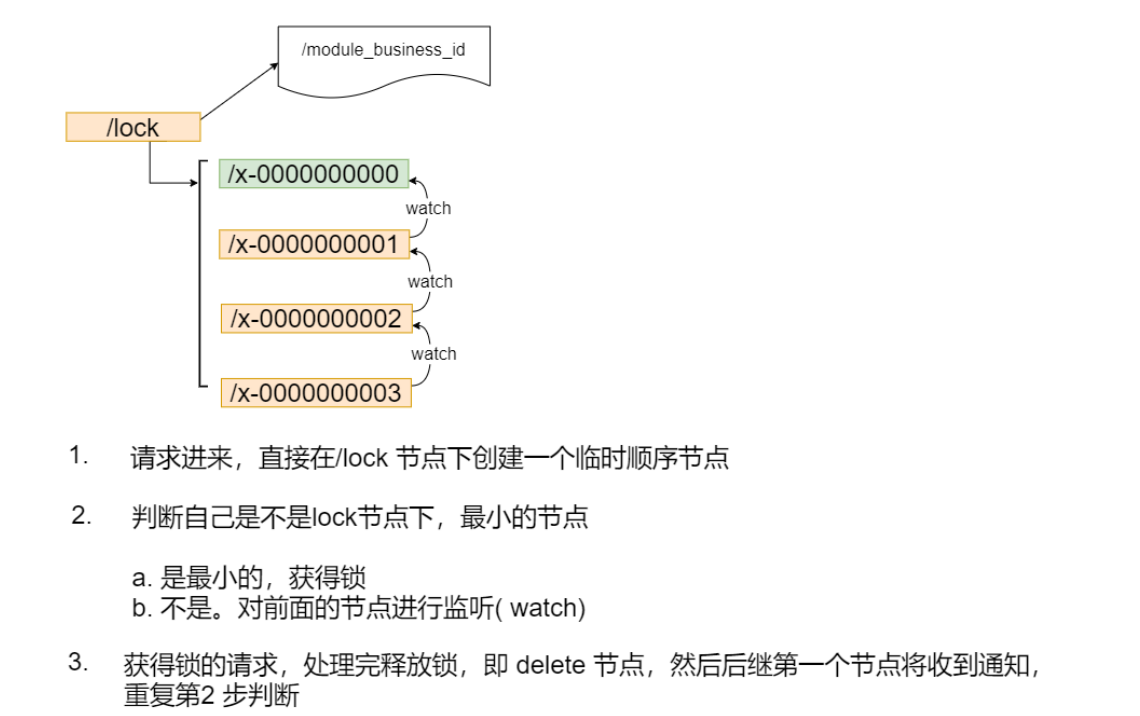
- 公平锁
还记得zk的顺序节点吗?公平锁的实现就是靠顺序结点来实现的!
流程:
首先线程创建临时的顺序节点,判断自己是不是第一个节点,如果是说明获取锁成功;
如果不是的话,则监听它的上一个节点,当上一个节点被删除之后自己便成为了第一个节点,也就是获取锁成功
注册中心
将自己服务信息放到zokeeper中,其他客户端就能获取结点信息,包括ip和端口信息!获取信息之后即可进行远程调用啦!
-
相关阅读:
谈谈游戏中如何防外挂和防破解
谈谈数字化转型成功的10个启示
麦芽糖-阿奇霉素 maltose-Azithromycin 阿奇霉素-PEG-麦芽糖
ArduPilot开源飞控之AP_InertialNav
【FLY】Android IO性能优化
springcloud16:总结配置中心+消息中心总结篇
撸了一个简易的配置中心,顺带整合到了SpringCloud
2.mysql--备份恢复
php算法面试题及答案
Java设计模式
- 原文地址:https://blog.csdn.net/m0_52255061/article/details/126329963
