-
6.2 网络钓鱼攻击
目录
一、了解网络钓鱼
网络钓鱼(phishing)由钓鱼(fishing)一词演变而来。在网络钓鱼过程中,攻击者使用诱饵(如电子邮件、手机短信、QQ链接等)将攻击代码发送给大量用户,期待少数安全意识弱的用户“上钩”,进而达到“钓鱼”(如窃取用户的隐私信息)的目的。
网络钓鱼的具体实施过程为:不法分子利用各种手段,仿冒真实网站的URL地址及页面内容,或者利用真实网站服务器程序上的漏洞,在站点的某些网页中插入危险的HTML代码,以此来骗取用户银行卡或信用卡账号、密码等私人资料。
国际反网络钓鱼工作组( Anti-Phishing Working Group, APWG)给网络钓鱼的定义是:网络钓鱼是一种利用社会工程学和技术手段窃取用户个人身份数据和财务账户凭证的网络攻击方式。采用社会工程学手段的网络钓鱼攻击往往是向用户发送冒充合法企业或机构的欺骗性电子邮件、手机短信等,引诱用户回复个人敏感信息或单击其中的链接访问伪造的网站,进而泄露凭证信息(如用户名、密码、账号ID、PIN码或信用卡详细信息等)或下载恶意软件。而技术手段的攻击则是直接在个人计算机上移植恶意代码,采用某些技术手段直接窃取凭证信息,如使用专门开发的软件拦截用户的用户名和密码、误导用户访问伪造的网站等。
网页挂马和钓鱼网站是恶意网址的两个主要形式。但是单纯的钓鱼网站由于本身不包含恶意代码,因此很难被传统的安全技术方法所识别。另外,绝大多数钓鱼网站设在境外,因此很难通过法律手段进行有效的打击。二、实验环境
网络钓鱼攻击实验清单 类型 序号 软硬件要求 规格 攻击机 1 数量 1台 2 操作系统版本 kali 3 软件版本 social-engineer-toolkit 三、实验步骤
!!!说多了都是泪,kali要联网,要联网!!!
1、登录到kali,在kali的工具包里找到social-engineer-toolkit,并打开,第一次打开会显示如下界面,且“同意服务条款”:

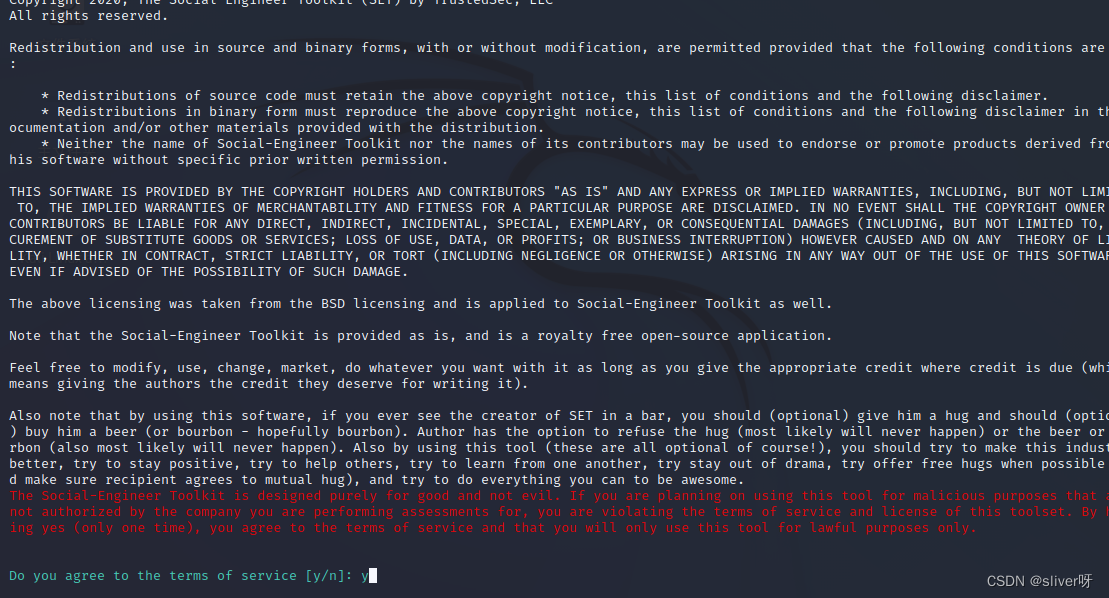
2、在出现的界面中,选择1)Social-Engineering Attacks选项,即社会工程学攻击方式。

3、接着选择2)Website Attack Vectors选项,即以网站为载体攻击的方式。

4、接着选择5)Web jacking Attack Method选项,即网站劫持方式。

5、接着选择2)Site Cloner,即网址克隆方式。

6、接着输入本机的IP地址。

7、在Enter the url to clone:后面输入需要进行克隆的网站URL,以便针对访问网站进行钓鱼操作。本实验采用https://secure.login.gov。出现以下界面说明克隆网站成功,一旦有数据通过克隆网站发送出去,就会被监听到。

8、接着打开kali的浏览器,在url栏中输入“192.168.92.129/index2.html”,会显示出克隆网站,跟真的一样。
在该网站上输入邮件地址和密码。

9、返回控制台界面,可以看到刚刚尝试登陆的信息会被kali记录,并显示在控制台上。

10、另外,在浏览器输入完邮件地址和密码后,页面会跳一下,并不会显示登录成功,而是重定向到正确的网址下。

至此,钓鱼实验基本上完成。
总结:用setoolkit进行钓鱼攻击,kali是根据要克隆的网址将网站保存在某个文件夹下,并且添加一些其他的信息,主要是将受害者输入的信息截获下来,并保存到有一个文本文件中,还有截获完之后,使浏览器跳转到正常页面。
四、实验过程中出现的一些问题
1、如果要克隆的网站页面有中文,不管是你用python开启web服务,还是用apache,登录“<攻击机IP地址>/index2.html”,页面都会出现乱码情况。

解决方式:目前没找到好的解决方法,我是用的英文网站代替之。
2、在输入克隆网站后,出现“Error,Unable to clone this specific site”:

2021.3版的kali自带的setoolkit,默认用python开启的web服务,一般情况是不会出现这种情况,我出现此种情况,是将占据80端口的pathon3删了,导致这种情况的。

解决方法:这情况下,重启kali可以解决。
另外,一种方法就是:用apache开启web服务。先修改setoolkit的配置文件“/etc/setoolkit/set.config”中的apache_server,将“OFF”改为“ON”:

紧接着开启apache2服务,在此打开setoolkit基本上可以用了,这种方式克隆网页放在“/var/www”下,克隆的网页就是www目录下的index.html;txt文件中存放的是kali截获的数据。
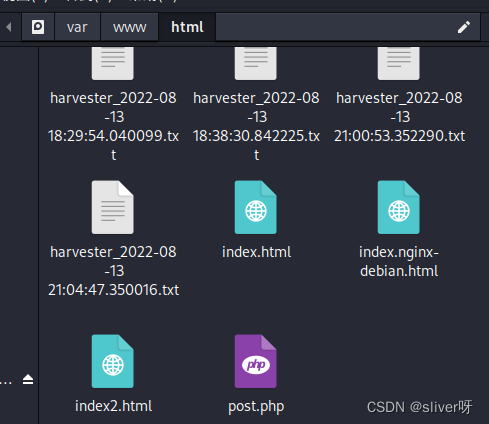
3、与用python开启的web服务的setoolkit相比,用apache开启web服务的setoolkit会稍微有点不同:
(1)输入完克隆网址后,控制台的数据就不一样。

apache版setoolkit
python版setoolkit
(2)显示截获数据的方式也不一样;
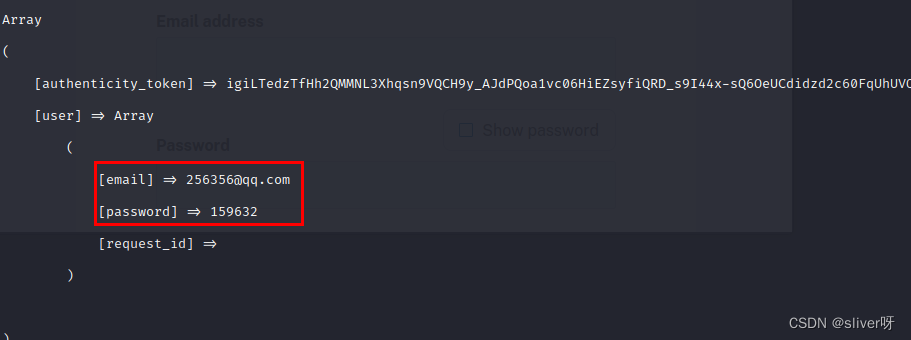
apache版setoolkit
python版setoolkit
-
相关阅读:
计算机毕业设计ssm+vue基本微信小程序的拼车自助服务小程序-网约车拼车系统
Linux网路服务之DNS域名解析
基于PHP+MySQL美食分享网站的设计与实现(含论文)
ElasticSearch 、Kibana安装
Python生成随机数字/字符
【学习笔记】尚未用过的图论知识
第四章 路由基础
Bigder:34/100 面试感觉挺好的,没有收到录取
版本控制 | 一文了解什么是组件化开发,以及如何从单体架构转向组件化开发
笔记:Qt开发之定制化qDebug()函数
- 原文地址:https://blog.csdn.net/qq_55202378/article/details/126324493