-
self-supervised text erasing with controllable image synthesis
从文字擦除的角度上,一般输入有原图,去除了文字的gt图和包含了文字位置的mask图,至于为什么有些带有原始文字位置mask作为额外的监督信息是不是会更好帮助网络定位文字,作为辅助信息,本文也为了这个维度信息。思路上有两种方案,一种是端到端网络,将文字定位和文字擦除当成一个整体来做,第二种是分两步来做,将文字定位和文字擦除当成上下游任务,先解决定位文字,再将得到的文字位置信息作为先验知识和图片一起输入到图像修复中,这种想法非常普遍,ocr的文字检测和识别,去水印等都是这个思路。SynthText,SCUT-EnsText是gt和mask的,EnsNetset是只有原图和gt,没有mask。其实文字擦除本质还是生成任务,现如今,这个思路上主要是图像修复,包括超分之类的,不一定要通过生成式的GAN去做,扩散也可以做,前期的思路,通过ae或者encoder-decoder架构,用l1损失就可以很好的建模,只不过伴随着gan的发展可控,gan思路就多起来。
1.Introduction
自监督在文字擦除或者图像修复或者去水印上的应用是广泛的,以Synthesis为例,输入原图之后,在原图上添加水印或者其他的东西,以这张图为输入,原图为gt,通过数据合成,来达到去除的目的,这中做法是非常普遍的,作者说不够好,提出了下面的对比:
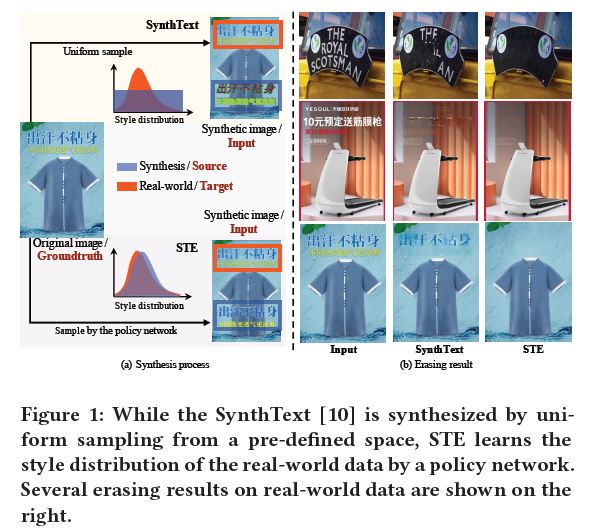
上面这张图的尚不就是synthText的方式,从均匀分布中采样,一般就是random.randit的这种方式,而本文提出的STE在style分布上采样更贴合原始数据,效果更好,本质上讲,生成数据和原始数据是同分布的,模型拟合这种分布学到的是更本质的知识。
提出了self-supervised Text Erasing(STE) framework。包括了两部分,image synthesis和text erasing。在图像合成中,除了之前的生成方法,还利用了mser提取区域近似真实图,考虑到合成文本和真实文本之间文本风格差距,构建了policy network,reward是根据所选风格的现实性和难度来计算。在擦除模块,是一个从粗到细的生成模型来擦除文本并用适当的纹理填充缺失的像素,并提出了对比学习的一个三元组损失。
2.self-supervised text erasing
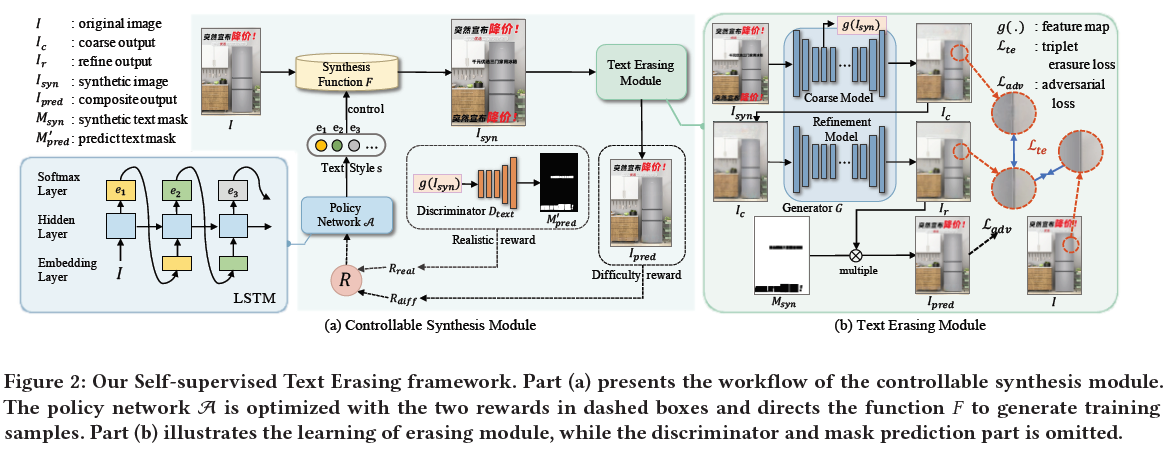
这篇论文的核心在看懂这张图,首先STE是一个自监督的框架,它的输入只有一张图,没有gt,整体是一个GAN的架构,输入I,生成器架构包括了合成函数F和一个Text Erasing Module,在经过了合成函数F之后产生了合成图和text mask,此处的text mask是合成时添加到I上的,即Isyn,此图输入Text Erasing Module,输出的是Ipred,Ipred在形式上应当与I相同,事实上输出的Ipred即为fake_img,和real_img构成了判别器的输入。Text Erasing Module是一个文字擦除模块EraseNet,这个是之前就有的模型,如果有原图及其对应的gt图,取消了文字的图,可以直接用来训练,STE取了巧,把它包进了GAN这个框架里,用它做生成器,输入合成图,输出是没有文字的图,这个过程有一个coarse model和一个refine model组成,这里是一个生成架构,但是通过什么信号来监督呢?refine model输出图和F添加上的text mask做乘积得到输出图fake_img,fake_img是包括原始的text的,refine model还输出了一个预测的text mask,这个预测的text mask将来会在判别器里起作用,就是说整个GAN是监督原始图生成的真不真,通过F函数是添加了text上去的,这个text的去除是在生成器中完成,并且生成器其实是祛除了所有的text的,我们在构造loss的时候给重新加回来了,Erasenet就是去text用,真实场景前向推理时只用这个模块。
2.1 Overview
在STE中,I和Isyn是一对数据,利用合成数据Isyn来训练生成模型G。为了将合成文本与原始文本对齐,使用策略网络A为F选择合适的样式s,通过反馈进行优化,包括文字难度Rdiff和风格现实奖励Rreal,Msyn表示合成区域的二进制掩码,损失计算的结果Ipred,由Ir和Isyn以Msyn为条件合成。
2.2 style-aware synthesis function
customization mechanism:文本样式被分解为多个单独的单元,通过选择每个单元中的操作,确定样式参数。
replication mechanism:它旨在通过复制目标分布中的原始文本来合成样本。
2.3 controllable synthesis module
2.3.1 search space
合成函数F提供了多种样式,所有这些构成了策略网络的搜索空间。
2.3.2 style optimization via reindorce.
策略网络的目标是在大搜索空间中为每个图像找到合适的合成样式。
2.3.3 reward setting
style realistic reward:为了捕获目标分布,实现了一个文本鉴别器Dtext来指导数据合成,具体来说,构建Dtext是为了预测合成图像Isyn中文本区域,该模块将生成器G的特征图g(Isyn)作为输入。
text difficult reward:
2.4 erasing module with triplet erasure loss
计算损失,只关注合成文本区域。
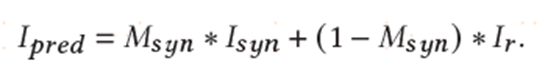
损失函数:

基础版本:没有对比学习,风格控制和强化学习模块,整体是一个GAN,GAN的判别器的真假样本是输入图,就是带有原始的text的图,只不过在做判别器时融合了text_mask信息。
dataset,dataset_size=init_dataset->CreateDataLoader->CustomDatasetDataLoader.initialize()->data_loader=CreateDataset->dataset=ItemsDataset()->dataset.initialize()->imageFiles/infos->dataloader=torch.utils.data.DataLoader(dataset)->dataset=data_loader.load()(dataloader)->train/valid/test->create_model()(pix2pix/disc/gateconv/erase)->model=EraseModel->model.initialize()->BaseModel.initialize->set_param->self.adaptive_feature_norm=AdaptiveFeatureNorm(0.1)->netG=STRnet2(3)->netD=Discriminator_STE(3)->LossWithGAN_STE(vggfeatureextractor,netD)->dis=torch.nn.L1loss->self.optimizer_G=torch.optim.Adam(netG.parameters())->netG.train()切换mode->model.setup->Visualizer->model.update_learning_rate()->ItemsDataset.__getitem__->load_item()->gt/info->gen_config=random_gen_config->space_config是一个配置区间->img=generate_img_with_config(gt,info,gen_config)->generate_img(image,info,config)其实这就是synthesis function F->raw_mask=gen_raw_mask text的mask->mask=get_mask()->transformers_param=get_params()获得一些数据预处理的参数->trans=get_transform->img=trans(img):512,768/mask=trans(mask)/gt=trans(gt)/raw_mask=trans(raw_mask)->img/gt/mask/raw_mask=input_transform(img/gt/mask/raw_mask):3,768,512->data=next(dataset_iter):gt/img/mask/raw_mask:2,3,768,512->model.set_input(data)->model.optimize_parameters()->STRnet2.forward(img:2,3,768,512)->x_o0:2,512,24,16 x_o1:2,64,192,128,x_o2:2,32,384,256,x_o3:2,3,768,512,fake_B:2,3,768,512,gen_mask:2,3,768,512,x_mask:2,256,48,32->comp_B=fake_B*(1-mask)+real_A*mask:2,3,768,512->mask_sigmoid->comp_G=self.fake_B*(1-mask)+real_A*mask->comp_all=fake_B*(1-mask)+real_A*mask*raw_mask+fake_B*(1-raw_mask)->lossWithGAN_STE.forward(real_A输入图,mask/mask_gt:后续加上的mask,fake_B/output输出的假图,这个假图是什么文字也没有的图,gen_mask/mm:这个是预测的加上去的text mask图,gt:和输入图一样的,raw_mask:原始的text mask的图)->D_real=discriminator(gt:2,3,768,512,masks:2,3,768,512)->Discriminator_STE.forward()->concat_feat:2,512,12,8->D_real:2,45->D_fake=discriminator(output,mask)->gan_mode:vanilla->D_loss=D_real+D_fake->D_optimizer.zero_grad()->D_loss.backward()->D_optimizer.step()->G_fake=discriminator(output,mask)->output_comp=mask*input+(1-mask)*output->holeLoss=10*l1((1-mask)*output,(1-mask)*gt)->mask_loss=dice_loss(mm,1-mask_gt*raw_mask,mask_sigmoid)->validAreaLoss->mask:2,3,768,512;masks_a:2,3,192,128;masks_b:2,3,384,256;gt:2,3,768,512;imgs1:2,3,192,128;imgs2:2,3,384,256;raw_mask:2,3,768,512;raw_masks_a:2,3,192,128;raw_masks_b:2,3,384,192->msr_loss->extractor:VGG16FeatureExtractor->feat_output_comp=extractor(output_comp)[2,64,384,256;2,128,192,128;2,256,96,64]->feat_output=extractor(output)->feat_gt=extractor(gt)->prcLoss=0.01*l1(feat_output,feat_gt)->styleLoss=120*l1(gram_matrix(feat_output),gram_matrix(feat_gt))->GLoss=msrloss+holeLoss+validAreaLoss+prcLoss+styleLoss+G_fake+1*mask_loss->optimizer_G.zero_grad()->G_loss.backward()->optimizer_G.step()
EraseModel->STRnet(2):
- STRnet2(
- (conv1): ConvWithActivation(
- (conv2d): Conv2d(3, 32, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1))
- (activation): LeakyReLU(negative_slope=0.2, inplace=True)
- )
- (conva): ConvWithActivation(
- (conv2d): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
- (activation): LeakyReLU(negative_slope=0.2, inplace=True)
- )
- (convb): ConvWithActivation(
- (conv2d): Conv2d(32, 64, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1))
- (activation): LeakyReLU(negative_slope=0.2, inplace=True)
- )
- (res1): Residual(
- (conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
- (conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
- (batch_norm2d): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
- )
- (res2): Residual(
- (conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
- (conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
- (batch_norm2d): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
- )
- (res3): Residual(
- (conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
- (conv2): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
- (conv3): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2))
- (batch_norm2d): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
- )
- (res4): Residual(
- (conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
- (conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
- (batch_norm2d): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
- )
- (res5): Residual(
- (conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
- (conv2): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
- (conv3): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2))
- (batch_norm2d): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
- )
- (res6): Residual(
- (conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
- (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
- (batch_norm2d): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
- )
- (res7): Residual(
- (conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
- (conv2): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
- (conv3): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2))
- (batch_norm2d): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
- )
- (res8): Residual(
- (conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
- (conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
- (batch_norm2d): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
- )
- (conv2): ConvWithActivation(
- (conv2d): Conv2d(512, 512, kernel_size=(1, 1), stride=(1, 1))
- (activation): LeakyReLU(negative_slope=0.2, inplace=True)
- )
- (deconv1): DeConvWithActivation(
- (conv2d): ConvTranspose2d(512, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), output_padding=(1, 1))
- (activation): LeakyReLU(negative_slope=0.2, inplace=True)
- )
- (deconv2): DeConvWithActivation(
- (conv2d): ConvTranspose2d(512, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), output_padding=(1, 1))
- (activation): LeakyReLU(negative_slope=0.2, inplace=True)
- )
- (deconv3): DeConvWithActivation(
- (conv2d): ConvTranspose2d(256, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), output_padding=(1, 1))
- (activation): LeakyReLU(negative_slope=0.2, inplace=True)
- )
- (deconv4): DeConvWithActivation(
- (conv2d): ConvTranspose2d(128, 32, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), output_padding=(1, 1))
- (activation): LeakyReLU(negative_slope=0.2, inplace=True)
- )
- (deconv5): DeConvWithActivation(
- (conv2d): ConvTranspose2d(64, 3, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), output_padding=(1, 1))
- (activation): LeakyReLU(negative_slope=0.2, inplace=True)
- )
- (lateral_connection1): Sequential(
- (0): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1))
- (1): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
- (2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
- (3): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1))
- )
- (lateral_connection2): Sequential(
- (0): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1))
- (1): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
- (2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
- (3): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1))
- )
- (lateral_connection3): Sequential(
- (0): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1))
- (1): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
- (2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
- (3): Conv2d(128, 64, kernel_size=(1, 1), stride=(1, 1))
- )
- (lateral_connection4): Sequential(
- (0): Conv2d(32, 32, kernel_size=(1, 1), stride=(1, 1))
- (1): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
- (2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
- (3): Conv2d(64, 32, kernel_size=(1, 1), stride=(1, 1))
- )
- (conv_o1): Conv2d(64, 3, kernel_size=(1, 1), stride=(1, 1))
- (conv_o2): Conv2d(32, 3, kernel_size=(1, 1), stride=(1, 1))
- (mask_deconv_a): DeConvWithActivation(
- (conv2d): ConvTranspose2d(512, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), output_padding=(1, 1))
- (activation): LeakyReLU(negative_slope=0.2, inplace=True)
- )
- (mask_conv_a): ConvWithActivation(
- (conv2d): Conv2d(256, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
- (activation): LeakyReLU(negative_slope=0.2, inplace=True)
- )
- (mask_deconv_b): DeConvWithActivation(
- (conv2d): ConvTranspose2d(256, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), output_padding=(1, 1))
- (activation): LeakyReLU(negative_slope=0.2, inplace=True)
- )
- (mask_conv_b): ConvWithActivation(
- (conv2d): Conv2d(128, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
- (activation): LeakyReLU(negative_slope=0.2, inplace=True)
- )
- (mask_deconv_c): DeConvWithActivation(
- (conv2d): ConvTranspose2d(128, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), output_padding=(1, 1))
- (activation): LeakyReLU(negative_slope=0.2, inplace=True)
- )
- (mask_conv_c): ConvWithActivation(
- (conv2d): Conv2d(64, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
- (activation): LeakyReLU(negative_slope=0.2, inplace=True)
- )
- (mask_deconv_d): DeConvWithActivation(
- (conv2d): ConvTranspose2d(64, 32, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), output_padding=(1, 1))
- (activation): LeakyReLU(negative_slope=0.2, inplace=True)
- )
- (mask_conv_d): Conv2d(32, 3, kernel_size=(1, 1), stride=(1, 1))
- (coarse_conva): ConvWithActivation(
- (conv2d): Conv2d(3, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
- (activation): LeakyReLU(negative_slope=0.2, inplace=True)
- )
- (coarse_convb): ConvWithActivation(
- (conv2d): Conv2d(32, 64, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1))
- (activation): LeakyReLU(negative_slope=0.2, inplace=True)
- )
- (coarse_convc): ConvWithActivation(
- (conv2d): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
- (activation): LeakyReLU(negative_slope=0.2, inplace=True)
- )
- (coarse_convd): ConvWithActivation(
- (conv2d): Conv2d(64, 128, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1))
- (activation): LeakyReLU(negative_slope=0.2, inplace=True)
- )
- (coarse_conve): ConvWithActivation(
- (conv2d): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
- (activation): LeakyReLU(negative_slope=0.2, inplace=True)
- )
- (coarse_convf): ConvWithActivation(
- (conv2d): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
- (activation): LeakyReLU(negative_slope=0.2, inplace=True)
- )
- (astrous_net): Sequential(
- (0): ConvWithActivation(
- (conv2d): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(2, 2), dilation=(2, 2))
- (activation): LeakyReLU(negative_slope=0.2, inplace=True)
- )
- (1): ConvWithActivation(
- (conv2d): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(4, 4), dilation=(4, 4))
- (activation): LeakyReLU(negative_slope=0.2, inplace=True)
- )
- (2): ConvWithActivation(
- (conv2d): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(8, 8), dilation=(8, 8))
- (activation): LeakyReLU(negative_slope=0.2, inplace=True)
- )
- (3): ConvWithActivation(
- (conv2d): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(16, 16), dilation=(16, 16))
- (activation): LeakyReLU(negative_slope=0.2, inplace=True)
- )
- )
- (coarse_convk): ConvWithActivation(
- (conv2d): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
- (activation): LeakyReLU(negative_slope=0.2, inplace=True)
- )
- (coarse_convl): ConvWithActivation(
- (conv2d): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
- (activation): LeakyReLU(negative_slope=0.2, inplace=True)
- )
- (coarse_deconva): DeConvWithActivation(
- (conv2d): ConvTranspose2d(384, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), output_padding=(1, 1))
- (activation): LeakyReLU(negative_slope=0.2, inplace=True)
- )
- (coarse_convm): ConvWithActivation(
- (conv2d): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
- (activation): LeakyReLU(negative_slope=0.2, inplace=True)
- )
- (coarse_deconvb): DeConvWithActivation(
- (conv2d): ConvTranspose2d(192, 32, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), output_padding=(1, 1))
- (activation): LeakyReLU(negative_slope=0.2, inplace=True)
- )
- (coarse_convn): Sequential(
- (0): ConvWithActivation(
- (conv2d): Conv2d(32, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
- (activation): LeakyReLU(negative_slope=0.2, inplace=True)
- )
- (1): ConvWithActivation(
- (conv2d): Conv2d(16, 3, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
- )
- )
- (c1): Conv2d(32, 64, kernel_size=(1, 1), stride=(1, 1))
- (c2): Conv2d(64, 128, kernel_size=(1, 1), stride=(1, 1))
- )
EraseModel:Discriminator_STE
- Discriminator_STE(
- (globalDis): Sequential(
- (0): ConvWithActivation(
- (conv2d): Conv2d(3, 64, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1))
- (activation): LeakyReLU(negative_slope=0.2, inplace=True)
- )
- (1): ConvWithActivation(
- (conv2d): Conv2d(64, 128, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1))
- (activation): LeakyReLU(negative_slope=0.2, inplace=True)
- )
- (2): ConvWithActivation(
- (conv2d): Conv2d(128, 256, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1))
- (activation): LeakyReLU(negative_slope=0.2, inplace=True)
- )
- (3): ConvWithActivation(
- (conv2d): Conv2d(256, 256, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1))
- (activation): LeakyReLU(negative_slope=0.2, inplace=True)
- )
- (4): ConvWithActivation(
- (conv2d): Conv2d(256, 256, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1))
- (activation): LeakyReLU(negative_slope=0.2, inplace=True)
- )
- (5): ConvWithActivation(
- (conv2d): Conv2d(256, 256, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1))
- (activation): LeakyReLU(negative_slope=0.2, inplace=True)
- )
- )
- (localDis): Sequential(
- (0): ConvWithActivation(
- (conv2d): Conv2d(3, 64, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1))
- (activation): LeakyReLU(negative_slope=0.2, inplace=True)
- )
- (1): ConvWithActivation(
- (conv2d): Conv2d(64, 128, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1))
- (activation): LeakyReLU(negative_slope=0.2, inplace=True)
- )
- (2): ConvWithActivation(
- (conv2d): Conv2d(128, 256, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1))
- (activation): LeakyReLU(negative_slope=0.2, inplace=True)
- )
- (3): ConvWithActivation(
- (conv2d): Conv2d(256, 256, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1))
- (activation): LeakyReLU(negative_slope=0.2, inplace=True)
- )
- (4): ConvWithActivation(
- (conv2d): Conv2d(256, 256, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1))
- (activation): LeakyReLU(negative_slope=0.2, inplace=True)
- )
- (5): ConvWithActivation(
- (conv2d): Conv2d(256, 256, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1))
- (activation): LeakyReLU(negative_slope=0.2, inplace=True)
- )
- )
- (fusion): Sequential(
- (0): Conv2d(512, 1, kernel_size=(4, 4), stride=(1, 1))
- )
- )
-
相关阅读:
《计算机图形学编程(使用OpenGL和C++)》笔记(1)-前言
表的增删改查
Pyton conway生存游戏--代码参考
Python ————浅拷贝与深拷贝
Apollo学习笔记(29)粒子滤波
【机器学习12】集成学习
为什么建议主键整型自增?
解决圆形进度条ProgressBar的几个问题
3D数字孪生:从3D数据采集到3D内容分析
嵌入式基础-电路
- 原文地址:https://blog.csdn.net/u012193416/article/details/126288661
 https://zhuanlan.zhihu.com/p/441303427
https://zhuanlan.zhihu.com/p/441303427