-
集群模式执行Spark程序(第七弹)
#添加打包插件
在pom.xml文件中添加所需插件
插入内容如下:
src/main/scala src/test/scala net.alchim31.maven scala-maven-plugin 3.2.2 compile testCompile -dependencyfile ${project.build.directory}/.scala_dependencies org.apache.maven.plugins maven-shade-plugin 2.4.3 package shade *:* META-INF/*.SF META-INF/*.DSA META-INF/*.RSA - "org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
等待加载

步骤1 将鼠标点在WordCount ,ctrl+c后ctrl+v复制,重新命名为WordCount_Online

步骤2 修改代码
# 3.读取数据文件,RDD可以简单的理解为是一个集合,集合中存放的元素是String类型
val data : RDD[String] = sparkContext.textFile(args(0))
# 7.把结果数据保存到HDFS上
result.saveAsTextFile(args(1))
# 修改以上这2行代码

步骤3 点击右边【maven projects】—>双击【lifecycle】下的package,自动将项目打包成Jar包
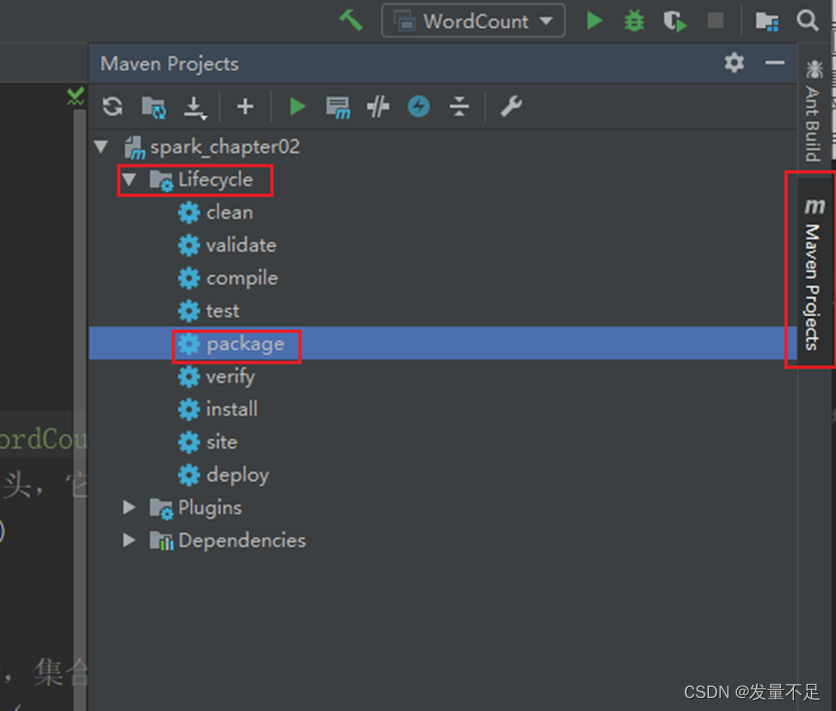
打包成功标志: 显示BUILD SUCCESS,可以看到target目录下的2个jar包

步骤4 启动Hadoop集群才能访问web页面
$ start-all.sh

步骤5 访问192.168.196.101(master):50070 点击【utilities】—>【browse the file system】

步骤6 点击【spark】—>【test】,可以看到words.txt



步骤7 将words.txt删除
$ hadoop fs -rm /spark/test/words.txt

步骤8 刷新下页面。可以看到/spark/test路径下没有words.txt

步骤9 Alt+p,切到/opt/software,把含有第3方jar的spark_chapter02-1.0-SNAPSHOT.jar包拉进
#先将解压的两个jar包复制出来

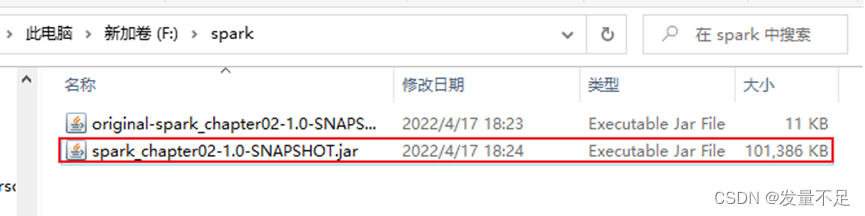


步骤10 也把F盘/word/words.txt直接拉进/opt/software

步骤11 查看有没有words.txt和spark_chapter02-1.0-SNAPSHOT.jar

步骤12 执行提交命令
$ bin/spark-submit \
--master spark://master:7077 \
--executor-memory 1g \
--total-executor-cores 1 \
/opt/software/spark_chapter02-1.0-SNAPSHOT.jar \
/spark/test/words.txt \
/spark/test/out
-
相关阅读:
漏洞复现-Apache Druid 任意文件读取 _(CVE-2021-36749)
小米汽车上市进入倒计时,已开启内部试驾
[wp]NewStarCTF 2023 WEEK5|WEB
VulnHub--mrrobot
C#中的for和foreach的探究与学习
Web 应用程序中的数据流
获取Linux内核源码
FPGA中乘除法运算实现途径
从 iOS 设备恢复数据的 20 个iOS 数据恢复工具
fastjson 1.2.24 反序列化导致任意命令执行漏洞
- 原文地址:https://blog.csdn.net/m0_57781407/article/details/126294896
