-
数据结构——图
图
一、图基本介绍
1、为什么要有图
- 线性表局限于一个直接前驱和一个直接后继的关系
- 树也只能有一个直接前驱也就是父节点
- 当我们需要表示多对多的关系时, 这里我们就用到了图
2、图的举例说明
图是一种数据结构,其中结点可以具有零个或多个相邻元素。两个结点之间的连接称为边。 结点也可以称为顶点。如图:

二、图的常用概念
- 顶点(vertex)
- 边(edge)
- 路径
- 无向图(下图)

无向图: 顶点之间的连接没有方向,比如A-B,
即可以是 A-> B 也可以 B->A .路径: 比如从 D -> C 的路径有
1) D->B->C
2) D->A->B->C- 有向图
顶点之间的连接有方向,比如A-B,只能是 A-> B 不能是 B->A .

6. 带权图
这种边带权值的图也叫网.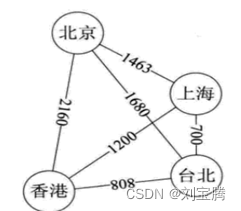
三、图的表示方式
图的表示方式有两种:二维数组表示(邻接矩阵);链表表示(邻接表)。
1、邻接矩阵
邻接矩阵是表示图形中顶点之间相邻关系的矩阵,对于n个顶点的图而言,矩阵是的row和col表示的是1…n个点。

2、邻接表
-
邻接矩阵需要为每个顶点都分配n个边的空间,其实有很多边都是不存在,会造成空间的一定损失.
-
邻接表的实现只关心存在的边,不关心不存在的边。因此没有空间浪费,邻接表由数组+链表组成
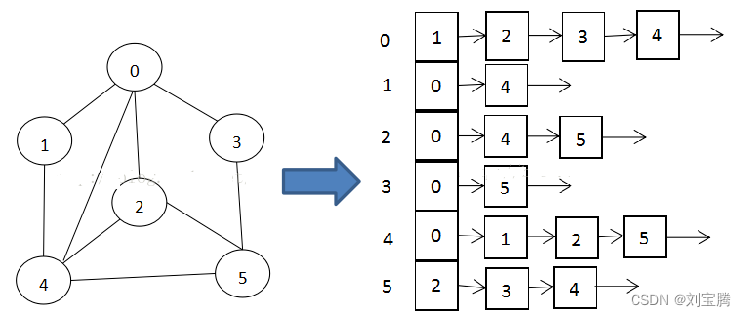
说明: -
标号为0的结点的相关联的结点为 1 2 3 4
-
标号为1的结点的相关联结点为0 4,
-
标号为2的结点相关联的结点为 0 4 5
-
…
四、图的深度优先遍历介绍
1、图遍历介绍
所谓图的遍历,即是对结点的访问。一个图有那么多个结点,如何遍历这些结点,需要特定策略,一般有两种访问策略:
- 深度优先遍历
- 广度优先遍历
2、深度优先遍历基本思想
图的深度优先搜索(Depth First Search) 。
- 深度优先遍历,从初始访问结点出发,初始访问结点可能有多个邻接结点,深度优先遍历的策略就是首先访问第一个邻接结点,然后再以这个被访问的邻接结点作为初始结点,访问它的第一个邻接结点, 可以这样理解:每次都在访问完当前结点后首先访问当前结点的第一个邻接结点。
- 我们可以看到,这样的访问策略是优先往纵向挖掘深入,而不是对一个结点的所有邻接结点进行横向访问。
- 显然,深度优先搜索是一个递归的过程
3、深度优先遍历算法步骤
- 访问初始结点v,并标记结点v为已访问。
- 查找结点v的第一个邻接结点w。
- 若w存在,则继续执行4,如果w不存在,则回到第1步,将从v的下一个结点继续。
- 若w未被访问,对w进行深度优先遍历递归(即把w当做另一个v,然后进行步骤123)。
- 查找结点v的w邻接结点的下一个邻接结点,转到步骤3。
五、图的广度优先遍历
1、广度优先遍历基本思想
图的广度优先搜索(Broad First Search) 。
类似于一个分层搜索的过程,广度优先遍历需要使用一个队列以保持访问过的结点的顺序,以便按这个顺序来访问这些结点的邻接结点2、广度优先遍历算法步骤
- 访问初始结点v并标记结点v为已访问。
- 结点v入队列
- 当队列非空时,继续执行,否则算法结束。
- 出队列,取得队头结点u。
- 查找结点u的第一个邻接结点w。
- 若结点u的邻接结点w不存在,则转到步骤3;否则循环执行以下三个步骤:
6.1 若结点w尚未被访问,则访问结点w并标记为已访问。
6.2 结点w入队列
6.3 查找结点u的继w邻接结点后的下一个邻接结点w,转到步骤6。
六、图的深度优先VS 广度优先
1、应用实例

- 深度优先遍历顺序为 1->2->4->8->5->3->6->7
- 广度优先算法的遍历顺序为:1->2->3->4->5->6->7->8
2、源码
public class Graph { private ArrayList<String> vertexList; //存储顶点集合 private int[][] edges; //存储图对应的邻结矩阵 private int numOfEdges; //表示边的数目 //定义给数组boolean[], 记录某个结点是否被访问 private boolean[] isVisited; public static void main(String[] args) { //测试一把图是否创建ok int n = 9; //结点的个数 String Vertexs[] = {"A", "B", "C", "D", "E","F","G","H","I"}; // String Vertexs[] = {"1", "2", "3", "4", "5", "6", "7", "8"}; //创建图对象 Graph graph = new Graph(n); //循环的添加顶点 for(String vertex: Vertexs) { graph.insertVertex(vertex); } //添加边 //A-B A-C B-C B-D B-E // graph.insertEdge(0, 1, 1); // A-B // graph.insertEdge(0, 2, 1); // // graph.insertEdge(1, 2, 1); // // graph.insertEdge(1, 3, 1); // // graph.insertEdge(1, 4, 1); // graph.insertEdge(0, 1, 1); graph.insertEdge(0, 3, 1); graph.insertEdge(0, 4, 1); graph.insertEdge(1, 2, 1); graph.insertEdge(1, 0, 1); graph.insertEdge(1, 4, 1); graph.insertEdge(2, 1, 1); graph.insertEdge(2, 5, 1); graph.insertEdge(2, 4, 1); graph.insertEdge(3, 0, 1); graph.insertEdge(3, 6, 1); graph.insertEdge(4, 0, 1); graph.insertEdge(4, 1, 1); graph.insertEdge(4, 6, 1); graph.insertEdge(5, 2, 1); graph.insertEdge(6, 3, 1); graph.insertEdge(6, 4, 1); graph.insertEdge(6, 7, 1); graph.insertEdge(7, 6, 1); graph.insertEdge(7, 8, 1); graph.insertEdge(8, 7, 1); //更新边的关系 // graph.insertEdge(0, 1, 1); // graph.insertEdge(0, 2, 1); // graph.insertEdge(1, 3, 1); // graph.insertEdge(1, 4, 1); // graph.insertEdge(3, 7, 1); // graph.insertEdge(4, 7, 1); // graph.insertEdge(2, 5, 1); // graph.insertEdge(2, 6, 1); // graph.insertEdge(5, 6, 1); //显示一把邻结矩阵 graph.showGraph(); //测试一把,我们的dfs遍历是否ok System.out.println("深度遍历"); graph.dfs(); // A->B->C->D->E [1->2->4->8->5->3->6->7] // System.out.println(); System.out.println("广度优先!"); graph.bfs(); // A->B->C->D-E [1->2->3->4->5->6->7->8] } //构造器 public Graph(int n) { //初始化矩阵和vertexList edges = new int[n][n]; vertexList = new ArrayList<String>(n); numOfEdges = 0; } //得到第一个邻接结点的下标 w /** * * @param index * @return 如果存在就返回对应的下标,否则返回-1 */ public int getFirstNeighbor(int index) { for(int j = 0; j < vertexList.size(); j++) { if(edges[index][j] > 0) { return j; } } return -1; } //根据前一个邻接结点的下标来获取下一个邻接结点 public int getNextNeighbor(int v1, int v2) { for(int j = v2 + 1; j < vertexList.size(); j++) { if(edges[v1][j] > 0) { return j; } } return -1; } //深度优先遍历算法 //i 第一次就是 0 private void dfs(boolean[] isVisited, int i) { //首先我们访问该结点,输出 System.out.print(getValueByIndex(i) + "->"); //将结点设置为已经访问 isVisited[i] = true; //查找结点i的第一个邻接结点w int w = getFirstNeighbor(i); while(w != -1) {//说明有 if(!isVisited[w]) { dfs(isVisited, w); } //如果w结点已经被访问过 w = getNextNeighbor(i, w); } } //对dfs 进行一个重载, 遍历我们所有的结点,并进行 dfs public void dfs() { isVisited = new boolean[vertexList.size()]; //遍历所有的结点,进行dfs[回溯] for(int i = 0; i < getNumOfVertex(); i++) { if(!isVisited[i]) { dfs(isVisited, i); } } } //对一个结点进行广度优先遍历的方法 private void bfs(boolean[] isVisited, int i) { int u ; // 表示队列的头结点对应下标 int w ; // 邻接结点w //队列,记录结点访问的顺序 LinkedList queue = new LinkedList(); //访问结点,输出结点信息 System.out.print(getValueByIndex(i) + "=>"); //标记为已访问 isVisited[i] = true; //将结点加入队列 queue.addLast(i); while( !queue.isEmpty()) { //取出队列的头结点下标 u = (Integer)queue.removeFirst(); //得到第一个邻接结点的下标 w w = getFirstNeighbor(u); while(w != -1) {//找到 //是否访问过 if(!isVisited[w]) { System.out.print(getValueByIndex(w) + "=>"); //标记已经访问 isVisited[w] = true; //入队 queue.addLast(w); } //以u为前驱点,找w后面的下一个邻结点 w = getNextNeighbor(u, w); //体现出我们的广度优先 } } } //遍历所有的结点,都进行广度优先搜索 public void bfs() { isVisited = new boolean[vertexList.size()]; for(int i = 0; i < getNumOfVertex(); i++) { if(!isVisited[i]) { bfs(isVisited, i); } } } //图中常用的方法 //返回结点的个数 public int getNumOfVertex() { return vertexList.size(); } //显示图对应的矩阵 public void showGraph() { for(int[] link : edges) { System.err.println(Arrays.toString(link)); } } //得到边的数目 public int getNumOfEdges() { return numOfEdges; } //返回结点i(下标)对应的数据 0->"A" 1->"B" 2->"C" public String getValueByIndex(int i) { return vertexList.get(i); } //返回v1和v2的权值 public int getWeight(int v1, int v2) { return edges[v1][v2]; } //插入结点 public void insertVertex(String vertex) { vertexList.add(vertex); } //添加边 /** * * @param v1 表示点的下标即使第几个顶点 "A"-"B" "A"->0 "B"->1 * @param v2 第二个顶点对应的下标 * @param weight 表示 */ public void insertEdge(int v1, int v2, int weight) { edges[v1][v2] = weight; edges[v2][v1] = weight; numOfEdges++; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
-
相关阅读:
网络安全新架构:零信任安全
Day2--使用ESP32双核、U8G2 OLED任务、任务以绝对频率运行、任务内存优化
使用CSS实现《声生不息》节目Logo
LeetCode-190. 颠倒二进制位(java)
顺丰小哥派件装载问题——典型的01背包问题
LeetCode17电话号码的字母组合
10种有用的Linux Bash_Completion 命令示例
软考正高级职称评审条件
什么是美颜SDK?为什么开发者应该考虑集成直播美颜SDK?
电商API接口:数据分析,代购商城建站,erp系统商品数据选品,价格监控,品牌维权,商家搬货,店铺铺货
- 原文地址:https://blog.csdn.net/rookie_lbt/article/details/126282125
