-
11、Semantic-NeRF
简介
Semantic-NeRF原论文名为《In-Place Scene Labelling and Understanding with Implicit Scene Representation》,首次提出将语义信息加入NeRF,实现了纹理、几何与语义信息的联合隐表征。论文的核心出发点在于证明了三维隐表征自身具备的连续性和多视角一致性使得Semantic-NeRF仅依靠稀疏/带噪声的语义标签,便能获得准确的室内语义标注和理解。论文方法并不复杂,就是在MLP网络上加了一路语义的输出,然后仿照颜色的积分方式对Semantic进行积分,如下图所示
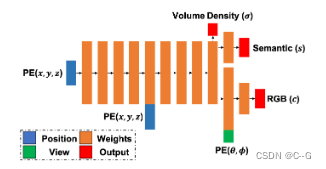
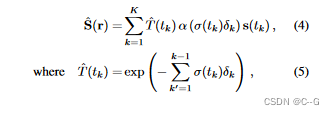
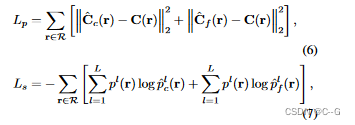
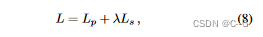
λ是语义损失的权重,设置为0.04以平衡两种损失的量级。在实际应用中,我们发现实际性能对λ值不敏感,而将λ设为1可以得到类似的性能。由于语义信息具有多视角一致性和不变性,因此,类似于几何信息,语义信息也仅和3D空间有关。2D空间的语义标签可以通过体素渲染获得。网络的损失函数由光度损失函数(MSE损失)和语义损失函数(交叉熵损失)共同构成,整个网络由Adam优化器端到端进行优化。
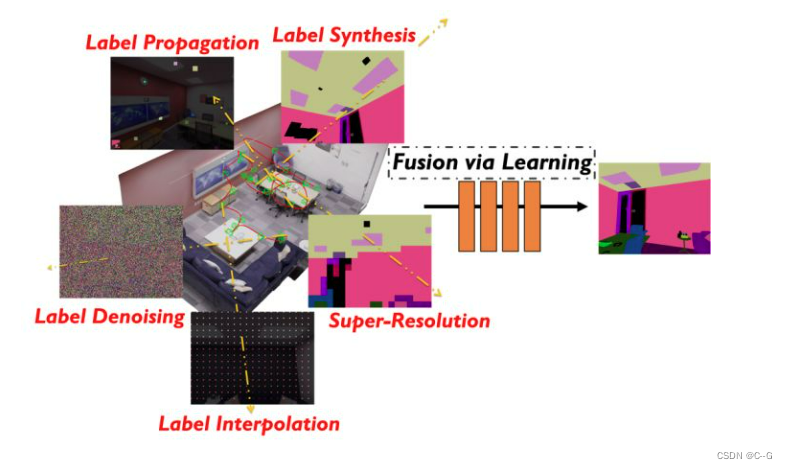
论文的一个核心发现是NeRF训练过程的核心动机来自于多视角观测下彩色图片和语义图片的一致性,而多视角语义一致性又是语义SLAM中非常核心的概念,使得我们可以融合多个视角的语义观测,获得一个更加准确的语义地图或表征。因此,Semantic-NeRF的训练过程本身就是一个多视角语义标签融合(multi-view semantic label fusion)过程。配合场景中语义信息的冗余性以及隐表征的连续性,我们可以仅利用稀疏、甚至带噪音的语义标签进行训练,在场景表征Semantic-NeRF的训练过程中进行融合,从而获得干净、准确的2D语义标签。
-
相关阅读:
【无标题】
【JavaWeb】Servlet过滤器
使用 ESP32 CAM 和 OpenCV 的运动检测
深度学习 机器视觉 车位识别车道线检测 - python opencv 计算机竞赛
【李沐深度学习笔记】线性回归的简洁实现
项目管理软件dhtmlxGantt配置教程(五):如何对列进行排序
Maven
DSU ON TREE
【java刷算法】牛客—剑指offer4DFS与BFS两种思路的碰撞,一起来练习吧
linux常用命令
- 原文地址:https://blog.csdn.net/weixin_50973728/article/details/126285463