-
【深度长文】学好并发编程不一定需要了解的MESI和内存屏障
学好并发编程不一定需要了解的MESI和内存屏障
一个从腾讯毕业的孩子,将自己的文章搬运出来
开篇
并发编程一直围绕着3个要素展开,分别是原子性、有序性、可见性。
对于使用者来说,可以通过学习使用一些并发工具类来保证三要素。
例如Java:
synchronize保证了原子性、可见性。(如果撇开DCL问题的话,所有变量都在同步代码块内处理的话,甚至也可以说保证了不同同步代码块之间的有序性)
ReentrantLock等保证原子性、可见性、有序性
volatile保证了可见性、有序性又例如Golang:
sync.Mutex sync.RWMutex 保证了原子性、可见性
channel技术可以用于保证可见性、有序性那么本篇文章,主要围绕的是可见性和有序性。语言给定了规则,我们只要遵守相应的规则,使用相应的工具类开发,就能保证并发安全。那么它的底层究竟是怎么工作的,今天的文章希望能给大家带来帮助,同时因为偏底层,如果有错误的地方,欢迎指正~
在进入主题之前,首先我们来看两段经典的伪代码
// cpu0和cpu1方法分别模拟2个CPU正在并行 public class Demo { int value = 0; boolean done = false; void cpu0() { value = 10; done = true; } void cpu1() { while (!done) { } System.out.println(value == 10); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
package main var value = 0 var done = false func setup() { value = 10 done = true } func main() { go setup() for !done { } println(value == 10) }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
看完上述的代码,它的输出结果是什么吗?以及为什么?
答案是不确定,要分很多种情况讨论。
第一段Java代码中,造成输出结果不确定的原因有
- while (!done) 这段代码很危险,如果done没有用volatile修饰,那么极大可能会出现,编译器将它优化为 while (1) 或者每次都直接从寄存器里取值,就导致原本我们希望通过变量done来控制循环结束,但编译器把它变成一个死循环。而这段代码我在生活中也实验过,如果while (!done) 循环体里面没有任何代码,就极大可能出现死循环。而如果任意插入一段代码,就能破除这个问题。(具体原理还没深究)
- cpu0 中的数据不存在依赖性,因此允许重排序。因此done=true时,并不能保证value=10 已经执行
- 尽管在cpu0 中没有进行重排序,但是由于不存在happends-before的保证,因此cpu0 和 cpu1不存在可见性的保证
第二段go代码中,造成输出结构不确定的原因有
- for !done 同样有可能会被编译器优化成死循环
- setup里面value同样不能保证在done前执行
- setup里面的value即是在done前执行,也不能保证对主routine可见
那么有什么方式能够保证最终输出结果为true呢?它的底层原理是什么?
那么接下来,我们带着这些疑问,一起走进今天的主题来一探究竟。
一、不同CPU设计的区别
单核CPU

只有一个CPU,读写都直接操作主存。优点:
设计简单、实现简单
不存在数据一致性问题
缺点缺点:
cpu和内存的IO性能差了100倍(cpu是1ns级,而内存是100ns级),频繁的与主存交互数据会影响cpu的性能单核+高速缓存
为了演示方便,多级高速缓存统一抽象为一级Cache
为了解决单核时代,cpu和内存间读写速度差距过大的问题,在两者之间引入了多级高速缓存

工作方式
cpu从主存中读取数据时,会将数据写入一份数据副本到高速缓存中(在高速缓存中以缓存行的形式保存,一个缓存行是64字节,读取一个数据如果小于64直接,则会把数据附近连续的内存数据一起保存下来以填充满一个缓存行。因此这里衍生出一个知识点,伪共享问题,本篇内容不对伪共享展开讨论)
之后cpu如果重复读写这个数据,就不需要再访问主存,而是直接访问高速缓存中对应的缓存行上的数据。这样就能频繁避免读写内存所带来的开销(CPU和高速缓存间的速度差距比CPU和主存之间小的多得多)
优点:提升了cpu读写数据的速度
缺点:单核CPU瓶颈明显。一台机器的性能取决于cpu在一个时钟周期内可执行的单元数量。
cpu、高速缓存、memory的速度差异

多核CPU + 高速缓存
为了解决上一个时代,单核cpu的性能瓶颈。超频并不是一个很好的解决方案,因为超频不仅会带来硬件寿命的急剧下降,发热问题也会导致cpu性能下降。并且一味的通过超频来提升cpu性能,它的研发成本和收益并不可观。因此,增加核心数是当下更好的方式。

由于增加了核心数,每个核心又拥有它自己的高速缓存。因此对于同一份主存数据,出现了数据不一致性的问题。
为了解决数据一致性问题,第一阶段采用的是总线锁的问题。总线是cpu连接内存的桥梁,多个cpu和内存之间的交互可以被总线进行管理。因此可以通过在总线上加锁的方式,来控制同一时间内,只有一个CPU能访问内存数据。
#Lock 信号会把总线上的并行化操作变成了串行,使得某个处理器能够独占内存。因此这是一个锁粒度和开销都很大的操作

优点:多核CPU并行工作提升了计算机的处理速度
缺点:
- 带来了缓存一致性问题
- 总线锁的方式开销太大
二、缓存一致性协议(MESI)
由于通过总线锁的方式来保证一致性所带来的性能开销太大,因为MESI协议的目的就是以一种更优的方式来管理数据一致性,同时保证CPU的高性能。它的思想是通过降低锁的粒度以及减少使用总线锁的频率来提高并行度从而达到性能优化。

缓存行的状态
它将高速缓存中每个缓存行(Cache Line)赋予了一个状态属性,分别是
- Modified
- Exclusive
- Shared
- Invalid
Exclusive
- 本地缓存独占
- 缓存行有效
- 与 主存 数据一致
当某个数据,只有一个CPU需要使用这个数据时。并且它从主存读到缓存行后,没有进行任何修改操作。那么此时,这份数据的状态就是Exclusive
Modified
- 本地缓存独占
- 缓存行有效
- 缓存行 和 主存 的数据不一致
当某个数据,只有一个CPU需要使用这个数据时。那么这个CPU对当前数据的读写,就不需要马上同步到主存中(因为没有其他CPU需要,不存在数据一致性问题)。cpu直接与cache进行交互,不需要和主存进行交互,从而提升了读写速度
Shared
- 多个CPU缓存共享
- 缓存行有效
- 与 主存 数据一致
当某个数据存在于多个CPU的缓存行时。数据没有被任意一个CPU修改,因此每一个CPU缓存中所维护的数据副本,都与主存完全一致,数据是有效的
Invalid
- 多个CPU缓存共享
- 缓存行无效(既当前数据和主存的不一致,不能直接读缓存行,否则会读到脏数据)
- 与 主存 数据不一致
当某个数据存在于多个CPU的缓存行时。其他CPU对数据进行了修改,从而使得当前CPU维护的数据副本失效。位于Invalid状态的数据,CPU在进行读操作时,需要从主存中读取最新的有效数据
事件
而引起缓存行状态的变化,由以下4类事件触发:
本地写
本地处理器进行数据写入
本地读
本地处理器进行数据读取
远程写
其他处理器对数据进行写入
远程读
其他处理器对数据进行读取
而CPU是如何感知到其他CPU对共享内存数据进行读写呢?
它是通过总线嗅探机制
总线嗅探机制:CPU对一个缓存行的读写,最终会被其他CPU知道
缓存行状态和事件的关系

处于Exclusive状态
当内存中某个数据第一次被CPU使用时,CPU将数据从内存中拷贝一份副本到高速缓存中,状态为 E
本地读 (E -> E)
本地CPU直接从本地缓存中读取数据,状态不发生改变
本地写(E -> M)
由于没有其他CPU共享数据,为了减少和内存的交互。cpu直接跟高速缓存进行写入操作。
由于此时,本地缓存的数据和主存的数据不一致,因此状态会变更为 M
M 表示本地缓存行数据是真实有效的,还没同步至主存中
远程读 (E -> S)
当发生远程读时,说明此时这个数据已经不是当前CPU独占了,存在多CPU共享内存数据的情况。在这种情况下,会由E转变为S。由于远程没有对数据做修改,因此每个CPU维护的数据副本跟主存一致。
远程写(E -> I)
当发生远程写时,说明此时数据已经不是当前CPU独占,存在多CPU共享内存数据的情况。
在这种情况下,由于远程将数据做了修改操作,因此本地维护的数据副本数据已经失效,如果本地CPU要在此使用数据,需要从主存中同步最新的数据。因此状态由E变为I,告知CPU缓存行这条数据已经失效了,如果要再次使用,请到主存中拉取。
处于Modified状态
当内存中的某个数据仅存在于当前CPU缓存中时,并且CPU对数据进行了修改导致缓存与主存数据不一致,此时缓存行的状态为M
本地读(M -> M)
CPU直接从缓存中把数据读取使用,状态不需要发生变化
本地写(M -> M)
CPU直接修改缓存中的数据,状态不需要发生变化
远程读(M -> S)
由于数据此时不再独占,并且当前CPU维护的数据是真实有效的,因此需要先将数据同步到主存中。然后修改状态为 S
远程写(M -> I)
由于数据此时不再独占,并且其他CPU要对数据进行写入操作。首先当前CPU会把自己缓存中的数据同步到主存中,然后将自己状态变更为 I (等待下一次使用数据时,强制从主存中获取,保证最新)
处于Shared状态
多个CPU同时对同一份内存数据进行缓存
本地读(S -> S)
本地写(S -> M)
CPU首先会把数据写入自己的缓存,然后通知其他CPU将对应的缓存行变更为 I 。
在这之后,由于缓存数据和主存数据不一致,因此变更为M
远程读(S -> S)
远程写(S -> I)
其他CPU对数据进行修改,会通知当前CPU将缓存行变更为 I 状态。以便下一次使用数据时,强制从主存中获取最新数据
处于Invalid状态
CPU从未使用过内存中某个数据 或 由于其他CPU的修改导致当前CPU失效。都会处于这个状态
本地读(I -> E/S)
分情况讨论
-
其他CPU缓存行没有对当前内存数据,存在E S M状态任意一种时。cpu直接从内存中读取数据到缓存中,然后状态变更为 E(表示独占)
-
其他CPU缓存行存在当前内存数据时,根据情况变更为 E 或者 S
- 其他CPU是E、S状态,则自己从主存中获取最新数据,然后 I -> S
- 其他CPU是M状态(根据前面的特性,可知有且只有1个),此时会通过本地读(对其他CPU来说是远程读事件),让对方CPU把数据从缓存同步到内存中。此时当前CPU再从主存中读取最新数据,然后状态修改为S。(远程CPU从M -> S)
本地写(I -> M)
分情况讨论
-
其他CPU不存在对应缓存数据时,当前CPU从主存中读取数据后直接对缓存进行修改,并状态从I -> M
-
其他CPU存在对应缓存行数据
- 其他CPU是E或S状态,此时当前CPU从主存读取数据后直接对缓存进行修改,并通过事件触发远程CPU状态变为I。当前CPU由I -> M
- 其他CPU是M(有且只有1个),通过事件先让远程CPU把最新值同步到内存中。然后当前CPU从内存中读取最新的值,然后对缓存数据进行修改后。自身状态由I -> M
远程读(I -> I)
与我无关
远程写(I -> I)
与我无关
MESI小结
相比原来多CPU通过总线锁的方式保证数据一致性,MESI提供更细粒度的控制。能够有效的减少使用总线锁的频率,同时也减少cpu和内存直接交互的频率。
但是此时的MESI还是不够高效,作为一个超底层的技术,它应该关注于优化极致的性能。因此我们来分析一下,此时的MESI还存在哪些性能问题?
如何优化MESI的性能
还记得上节中提到,当发生本地写时,需要通知其他相关的CPU缓存行状态变为失效。而在这个过程中,完整的描述是这样的
本地写:本地CPU发起本地写事件,并等待其他相关的所有CPU进行失效ACK响应后,自己才会继续工作。因为只有这样,才能保证自己写入的数据,能被其他CPU感知到。
远程写:CPU通过嗅探机制,收到失效请求。处理器需要将对应的缓存行置为失效,然后响应失效ACK。

由此可知,无论是CPU本地写等待失效ACK,还是CPU要处理远程写的失效请求。都会因为保证数据强一致性而带来的延迟。
为此,针对上面的2个场景,CPU再做优化。
优化手段一:存储缓存
优化对象:触发本地写的CPU
优化切入点:CPU等待其他CPU的失效ACK所造成的阻塞
具体做法
引入存储缓存,当发生本地写事件时,不再等待远程ACK响应。而是会将新值写入存储缓存中,然后CPU继续去处理其他事情。当全部失效ACK都响应完成时,才会将存储缓存中的数据同步到Cache中,并将状态变为 M
此时会有一个问题,就是当数据在存储缓存中,还在等待失效ACK时,这条数据的最新值是不位于缓存中的,此时CPU要对这个数据进行读取的话。CPU会先去存储缓存判断是否存在这条数据,存在的话直接读存储缓存的值。这一机制被称为Store Fowarding
存储缓存容量不大,因此当存储缓存已经堆积满时。此时有新的本地写事件,会阻塞CPU。直到存储缓存中有事务完成。
优化手段
通过将同步操作保证强一致性,变为异步操作保证最终一致性。从而达到优化本地CPU的处理效率。
优化手段二:失效队列
优化对象:触发远程写的CPU
优化切入点:CPU收到远程写事件对应,需要进行失效处理后响应失效ACK所造成的延迟
具体做法
引入失效队列,当收到失效处理请求时。CPU先不处理对应缓存行,而是将失效请求放入失效队列,同时马上响应失效ACK回去。而对于失效队列,会在空闲时逐个进行处理。
优化手段
将耗时的同步操作保证强一致性。改为异步保证最终一致性
“MESI + 存储缓存 + 失效队列”,用最终一致性 换 性能
经过上面的一系列发展,最终基于这种最终一致性保证的MESI协议下,CPU的处理效率得到很大的提升。但这也意味着,它会带来数据不一致的问题。
我们回到最初的代码,这里引起最终value == 10可能为false的原因。有重排序带来的问题,也有存储缓存带来的问题。cpu0中并不能保证value=10已经成功写入缓存or主存。因此cpu1见到done=true时,并不能保证value一定等于10 。同时这里也牵涉一个概念,叫做数据依赖性。value和done并不存在任何数据依赖,假设他们存在数据依赖。那么当done=true时,value一定等于10是可以保证的。
public class Demo { int value = 0; boolean done = false; void cpu0() { value = 10; done = true; } void cpu1() { while (!done) { } System.out.println(value == 10); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
三、内存屏障
在实际工作中,存在很多场景是需要保证同步、保证数据强一致性的。
所以CPU设计者提供了能够保证一致性的手段,它将这些手段的使用权交给用户去考虑。
内存屏障解决的问题
- 可见性
- 重排序
内存屏障的分类
从功能类型上划分,内存屏障主要分为三种:
写屏障
保证写事务的强一致性。
当CPU遇到写屏障时,必须强制等待存储缓存中的写事务全部处理完毕后,cpu才能继续工作。
其目的是保证当前CPU的写操作,能够通知到其他CPU并响应失效ACK注意,虽然保证了能等待所有其他CPU响应失效ACK后,才继续工作。但这并不意味着,其他CPU一定会对当前变更后的最新值可见。原因是其他CPU还存在失效队列。写屏障并不能保证,其他CPU将失效请求已经处理完,仅仅只是保证他们都响应了ACK
读屏障
保证读事务的强一致性
当CPU遇到读屏障时,必须强制处理完当前失效队列的所有无效事务。
其目的是保证,读屏障之后的读指令,能够读到最新的值。全能屏障
同时包含写、读屏障的功能
硬件层面实现
而具体的实现,如在X86架构中,C语言定义的内存屏障命令有
- lfence (读屏障)
- sfence(写屏障)
- mfence(全能屏障)
// 编译器屏障,只针对编译器生效(GCC 编译器的话,可以使用 __sync_synchronize)
#define barrier() asm volatile(“”:::“memory”)// cpu 内存屏障
#define lfence() asm volatile(“lfence”: : :“memory”)
#define sfence() asm volatile(“sfence”: : :“memory”)
#define mfence() asm volatile(“mfence”: : :“memory”)
我们来看一下,如果使用内存屏障的话,如何来解决我们之前的代码问题,保证输出true ?
public class Demo { int value = 0; boolean done = false; void cpu0() { value = 10; // 插入写屏障,保证value的新值能写入主存, 写屏障(); done = true; } void cpu1() { while (!done) { } // 插入读屏障,保证在读取value前,处理完所有失效请求,保证value的值从主存中获取 读屏障(); System.out.println(value == 10); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
JVM级内存屏障 (JSR-133)
上面提到的硬件级指令,会随着CPU的不同而不同。
如果Java需要程序员自行去编写代码使用内存屏障(如上面代码插入的2个内存屏障),那么我们就需要识别不同的处理器来使用不同的指令,写出来的代码可能如下:
// 伪代码 if (cpu is X86) { cpuX86.mfence(); } else if (cpu is M1) { cpuM1.storeLoadBarrier(); } else { // ... }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
这样的编码会给开发人员带来很大的不便,不仅如此需要开发人员具备更深入的知识能力并且存在一定的危险性(如官方不推荐开发人员使用Unsafe这种能够操作最底层的工具类)
为了屏蔽不同CPU的内存屏障指令差异的细节。JMM 把内存屏障定义为四类(而每一类JMM内存屏障具体的底层实现,Java开发者不需要关注)LoadLoad
Load1; LoadLoad; Load2 保证Load1先于Load2执行 确保Load1数据的装载先于Load2及所有后续装载指令
StoreStore
Store1; StoreStore; Store2 保证Store1先于Store2指令执行 确保Store1数据对其他处理器可见(刷新到内存),先于Store2及所有后续存储指令
LoadStore
Load1; LoadStore; Store2 确保Load1数据装载先于Store2及所有后续存储指令刷新到内存
StoreLoad(全能屏障,开销最大)
Store1; StoreLoad; Load1
确保Store1数据对其他处理器可见(刷入内存),先于Load2及所有后续装载指令。
StoreLoad指令保证屏障之前所有的内存访问指令(装载和存储)完成之后,才执行屏障后续的内存访问指令 (因此StoreLoad又被称为 全能指令,能同时具备上述3种指令的效果)
上面聊了内存屏障,下面再回到CPU硬件级,再简单介绍2条常见的指令
#Lock 指令
除了内存屏障外,还有一些指令如#Lock,它虽然不是内存屏障但能达到内存屏障相似的效果。同时它也为原子性提供了有力的支持
#Lock的作用
当CPU遇到#Lock信号时,会做如下处理
- 锁总线。其它CPU对内存的读写请求都会被阻塞,直到锁释放,不过实际后来的处理器都采用锁缓存行替代锁总线,因为锁总线的开销比较大,锁总线期间其他CPU没法访问内存
- 将当前存储缓存的写事务全部处理完毕。将最新值同步到内存,并且保证其他处理器相关的缓存行状态更新为失效(以保证之后这些处理器能从主存中获取最新的值)
- 阻止屏障两边的指令重排序
CMPXCHG 指令
我们Java中用到的Unsafe类CAS操作(或是AtomicXXX类),它的底层是通过CMPXCHG指令实现比较和交换操作。为了保证CAS的硬件级原子性,它会依靠#Lock指令来实现。
// Unsafe compareAndSet()方法,往下挖到HotSpot源码关于x86的实现如下 // cmpxchg本身不具备原子性,只是一个单纯的比较和交换。所以需要依赖lock指令来保证多CPU并行时CAS操作的原子性 __asm__ volatile ("lock cmpxchgl %1,(%3)" : "=a" (exchange_value) : "r" (exchange_value), "a" (compare_value), "r" (dest) : "cc", "memory");- 1
- 2
- 3
- 4
- 5
- 6
四、happends-before
引言
我们再一次回到这一段代码
public class Demo { int value = 0; boolean done = false; void cpu0() { value = 10; // or StoreStoreBarrier() 写屏障(); done = true; } void cpu1() { while (!done) { } // or LoadLoadBarrier() 读屏障(); System.out.println(value == 10); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
虽然 JMM 为我们屏蔽了硬件层面内存屏障指令的细节,提供了LoadLoad,LoadStore,StoreStore,StoreLoad四种内存屏障的封装。但是我们平时开发中,很少会直接跟内存屏障直接打交道。当然还是因为内存屏障的学习使用成本很高。
因此,无论是Java还是Go语言,都为我们再一次屏蔽内存屏障的细节,以至于程序员在进行开发时,可能干到退休都不知道内存屏障的概念。程序员只需要关注,如何编码保证原子性、可见性、有序性即可。
至此,语言级解决可见性、重排序问题的主角登场了happends-before
概念:
happends-before 定义了一系列跟语言有关的规则,来保证操作之间的可见性 如 A happends-before B 则保证了 A操作的结果 对 B操作可见happends-before的出现,不再需要程序员去关注如何使用内存屏障,程序员只要清楚了解happends-before有哪些规则,在开发过程中注意即可保证可见性,有序性。
happends-before for JAVA
规则
- 程序次序规则:一个线程内,按照代码顺序,书写在前面的操作先行发生于书写在后面的操作;
- 锁定规则:一个unLock操作先行发生于后面对同一个锁额lock操作;
- volatile变量规则:对一个变量的写操作先行发生于后面对这个变量的读操作;
- 传递规则:如果操作A先行发生于操作B,而操作B又先行发生于操作C,则可以得出操作A先行发生于操作C;
- 线程启动规则:Thread对象的start()方法先行发生于此线程的每个一个动作;
- 线程中断规则:对线程interrupt()方法的调用先行发生于被中断线程的代码检测到中断事件的发生;
- 线程终结规则:线程中所有的操作都先行发生于线程的终止检测,我们可以通过Thread.join()方法结束、Thread.isAlive()的返回值手段检测到线程已经终止执行;
- 对象终结规则:一个对象的初始化完成先行发生于他的finalize()方法的开始
例子
挑其中几条规则,做一点讲解来理解(1) 如volatile规则
volatile int a = 0; 1 a = 10; 2 print(a == 10); // true- 1
- 2
- 3
- 4
基于这条规则,它保证无论是单线程,还是多线程。只要代码1 先行于 代码2 。a = 10就一定可见
(2) volatile + 传递规则
int a = 0; volatile boolean done = false; public void cpu0() { this.a = 10; // (1) this.done = true; // (2) } public void cpu1() { while (true) { if (done) { // (3) print(x == 10); // (4) true break; } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
首先是基于程序次序规则、volatile规则得出:
(1) happends-before (2)(3) happends-before (4)
(2) happends-before (3)
得出三面3个公式后,我们再根据传递性可得
(1) happends-before (4)
这也就意味着,
(4)的x一定是10,它对(1)的操作可见
(3) 线程启动规则
在父线程中启动子线程,子线程启动前的父线程操作对它可见
// 正例 int a = 0; a = 10; new Thread(() -> { print(a == 10); // true }).start(); // 反例,不满足线程启动规则 int a = 0; new Thread(() -> { a = 10; }).start(); print(a == 10); // true or false 都有可能。不能保证- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
(4) synchronize
Object lock = new Object(); int a = 0; public void cpu0() { synchronized (lock) { // cpu0先进入 this.a = 10; } } public void cpu1() { synchronized (lock) { // cpu1后进 print(a == 10); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
能够保证cpu1读到的a为10。
以上通过一些简单的例子,来告诉大家只要遵守happends-before规则,就能保证可见。那么它的底层原理是怎么实现的呢?
volatile的happends-before实现原理
内存语义:
- volatile写:会把工作内存的值刷入主存
- volatile读:在读之前,会把对应工作内存置为无效。然后从主存中获取最新的值
为了实现上述的内存语义,编译器在生成字节码的时候。会对volatile变量进行如下处理
volatile写(前面):StoreStoreBarrier
volatile写(后面):StoreLoadBarrier
volatile读(后面):LoadLoadBarrier
volatile读(后面):LoadStoreBarrier
synchronized的happends-before实现原理
内存语义
- 获取锁,进入synchronized:JMM将工作内存置为无效,使得数据的使用必须从主存中获取最新的
- 释放锁,退出synchronized:JMM将工作内存的共享变量刷新到主存中
happends-before for Golang
规则
-
Initialization:先import的包的init(),一定可见于后import的包
-
Goroutine Creation:该规则说的是 goroutine 创建的场景,创建函数本身先于 goroutine 内的第一行代码执行
-
Goroutine Destruction:该规则说的是 goroutine 销毁的场景,这条规则说的是,goroutine 的 exit 事件并不保证先于所有的程序内的其他事件,或者说某个 goroutine exit 的结果并不保证对其他人可见
-
Channel communiaction:
-
1、A send on a channel happens before the corresponding receive from that channel completes.
-
2、The closing of a channel happens before a receive that returns a zero value because the channel is closed.
-
3、A receive from an unbuffered channel happens before the send on that channel completes.
-
4、The kth receive on a channel with capacity C happens before the k+Cth send from that channel completes.
-
-
Lock:
-
1、For any sync.Mutex or sync.RWMutex variable l and n
-
2、For any call to l.RLock on a sync.RWMutex variable l, there is an n such that the l.RLock happens (returns) after call n to l.Unlock and the matching l.RUnlock happens before call n+1 to l.Lock.
-
-
Once:
例子
(1) Goroutine Creationvar value = 0 func main() { value = 10; go func() { // 规则保证了可见性 println(10 == value) } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
(2) channel
package main var value = 0 var done = false var ch = make(chan struct{}) func setup() { value = 10 done = true <- ch } func main() { go setup() ch <- struct{}{} for !done { } println(value == 10) }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
五、总结内存屏障

上图中jvm实现的内存屏障指向c语言实现内存屏障,并不是指LoadLoad、LoadStore等JMM内存屏障是通过调用lfence、sfence、mfence实现。对硬件级内存屏障感兴趣的,可以看看c语言、或者open-jdk里面关于orderAccess相关源码。看看都用了什么指令,这些指令有什么作用为什么能达到内存屏障的效果。
六、再聊一点 JMM工作内存 和 CPU MESI之间的关系
JMM 简述
首先相信这张图,对于一个Java工程师来说再也熟悉不过了。这是 Java虚拟机对CPU、Cache、主内存的一种抽象设计,它被称作 JMM(Java Memory Model)

CPU-Cache- Memory 和 JMM 之间的逻辑映射关系
CPU-高速缓存 抽象为 线程-工作内存(存放于JVM栈中)
主内存 抽象为 主内存(存放于JVM堆中)对于CPU-高速缓存-主存来说,都是在物理意义上完全独立的硬件设备。
而对于JMM,实际上在物理硬件上,他们都位于主存(物理硬件设备)。而 JVM对物理主存又划分了5个逻辑区域,分别是堆、栈、方法区、本地方法区、程序计数器。(它只是一种对物理内存上进行逻辑划分的设计)
因此,CPU-Cache-Memory 和 线程-工作内存-堆-主存(堆) 看似相似,但实际并不影响CPU MESI。同样的,JMM这样设计之初,也是尽可能的让线程和工作内存位于CPU对应的寄存器和高速缓存中。两者可以说是相似的,可以从宏观上进行对等理解。两者的关系如图
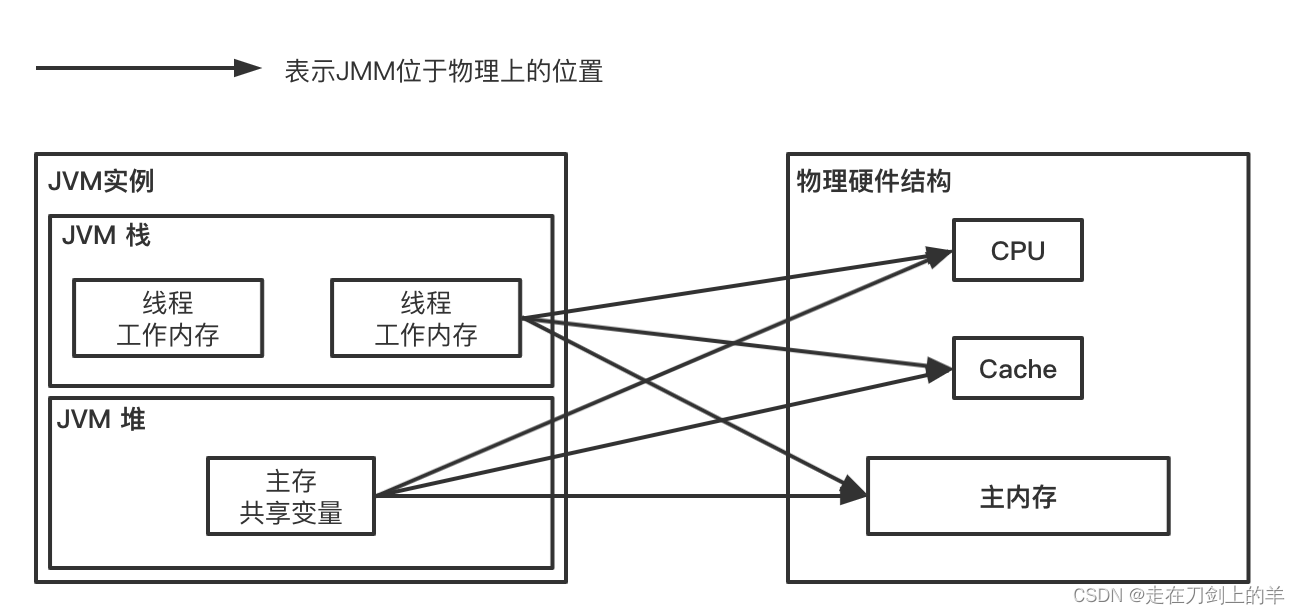
- JVM 是对物理内存的逻辑划分,划分为5个区域。JVM 所有内存都位于物理内存上
- JMM 只是Java对CPU-Cache-主存的一种抽象,其中线程-工作内存 位于 JVM栈中、而共享变量使用的“主存” 位于 JVM堆中。而JVM堆、栈都位于物理内存中。理解上可以 线程-工作内存-主存 等价于 CPU-Cache-主存。但实际上是不能划等号。
- 上图的箭头,主要是揭示了JMM每一个逻辑块(线程、工作内存、主存)对应可能会存放在的物理位置(CPU寄存器、Cache Line、物理内存)。
JMM 的工作方式
首先回忆CPU-Cache-主存的工作方式,
CPU会从主存中复制一份数据副本到自己的高速缓存,之后的读写操作会基于工作内存。MESI协议用于保证数据一致性,基于这份协议可以对高速缓存的数据何时同步到主存做一个控制。
JMM的工作方式也类似:
线程会从主存(JVM堆)中复制一份数据副本到自己的工作内存,之后的读写操作会基于工作内存。而JMM也有一套机制,用于解决工作内存何时将数据同步到主存(JVM堆)中。

Lock:作用于主存;把一个变量标识为线程独占状态
Unlock:作用于主存;把一个变量从线程独占状态恢复释放
Read:作用于主存;把一个变量传输到工作内存,以便后续的Load操作
Load:作用于工作内存;将Read传输过来的变量数据,放入工作内存的变量副本中 (Read和Load一定是顺序、成对出现的)
Use:作用于工作内存;将工作内存的变量副本的值传输给线程(执行引擎)使用;当执行变量的读操作时会触发Use
Assign:作用于工作内存;将从执行引擎获取的新值赋值给工作内存的变量副本中
Store:作用于工作内存;将工作内存的变量副本的值,传输给主存,以便后续的Write操作
Write:作用于主存;将Store传输过来的值,写入到主存的变量中(Store和Write一定是顺序,成对出现的)最后要声明一些东西
- MESI,存储缓存,失效队列。不同的CPU架构采用的实现是不一样的,如x86没有失效队列,只有存储队列。因此对它来说,一个写屏障就能解决可见性问题。因此不同CPU架构拥有不同的MESI实现,具体的细节要与时共进,大家自己去找对应的资料
- 文章中提到的JSR,happends-before,大家也要与时共进。不同的java版本,不同语言的happends-before都会有些区别
- 最后希望这篇文章能够让你对不同层面如何解决可见性、重排序有一个全局的了解。能区分CPU、语言级内存屏障、语言级happends-before的关系以及为什么要分这么多层
学好MESI、内存屏障可能不能帮助你写好Java、Golang。
像Java的话,了解底层或许能帮助你对synchronize、volatile、JUC包、AQS有个更好的理解。用好JUC的话其实是能够帮助你在并发编程上用的更加游刃有余。
完。
-
相关阅读:
MEM 英语备考第一篇
leetcode做题笔记128. 最长连续序列
小程序无感刷新
vue3Blog首页基础布局样式规划
Python7-使用pickle模块将Python对象序列化
腾讯联手警方重拳出击,平阳警方斩断特大外挂黑色产业链
LabVIEW开发FPGA的高速并行视觉检测系统
PyTorch ConvTranspose2d 的定义与计算过程
MUTISIM仿真 译码电路设计
java178-终篇?静态代理?动态代理?
- 原文地址:https://blog.csdn.net/qq_29765371/article/details/126279560
