-
Java常见的几种设计模式
单例设计模式:一个类只允许创建一个对象(或者实例),那这个类就是一个单例类,这种设计模式就叫做单例设计模式
1.如何实现一个单例
构造函数需要是 private 访问权限的,这样才能避免外部通过 new 创建实例;
考虑对象创建时的线程安全问题;
考虑是否支持延迟加载;
考虑 getInstance() 性能是否高(是否加锁)
2.常见的几种单例模式:
饿汉式:饿汉式的实现方式比较简单。在类加载的时候,instance 静态实例就已经创建并初始化好了,所以,instance 实例的创建过程是线程安全的。不过,这样的实现方式不支持延迟加载(在真正用到 的时候,再创建实例)。

有人觉得这种实现方式不好,因为不支持延迟加载,如果实例占用资源多(比如占用内存多)或初始化耗时长(比如需要加载各种配置文件),提前初始化实例是一种浪费资源的行为。最好的方法应该在用到的时候再去初始化。不过,我个人并不认同这样的观点。如果初始化耗时长,那我们最好不要等到真正要用它的时候,才去执行这个耗时长的初始化过程,这会影响到系统的性能(比如,在响应客户端接口请求的时候,做这个初始化操作,会导致此请求的响应时间变长,甚至超时)。采用饿汉式实现方式,将耗时的初始化操作,提前到程序启动的时候完成,这样就能避免在程序运行的时候,再去初始化导致的性能问题。如果实例占用资源多,按照 fail-fast 的设计原则(有问题及早暴露),那我们也希望在程序启动时就将这个实例初始化好。如果资源不够,就会在程序启动的时候触发报错(比如 Java 中的 PermGen Space OOM),我们可以立即去修复。这样也能避免在程序运行一段时间后,突然因为初始化这个实例占用资源过多,导致系统崩溃,影响系统的可用性。
懒汉式: 有饿汉式,对应的,就有懒汉式。懒汉式相对于饿汉式的优势是支持延迟加载。
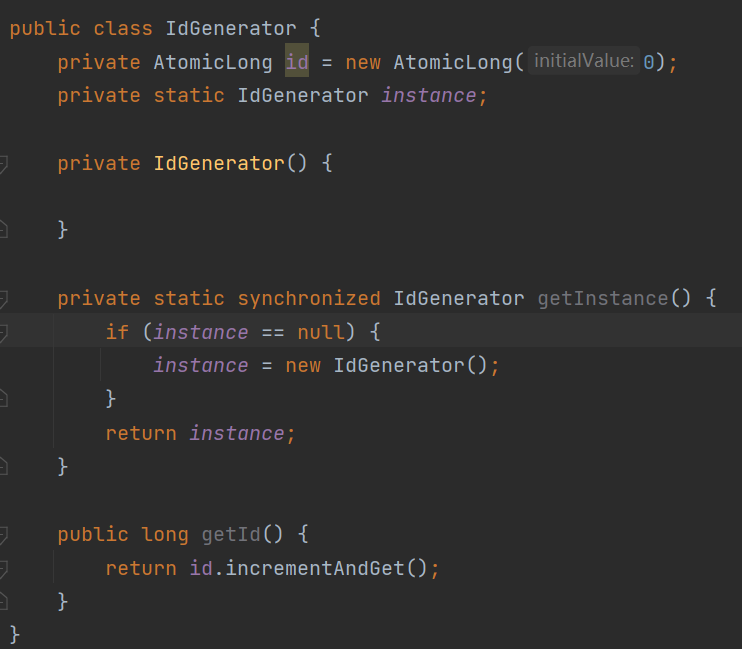
不过懒汉式的缺点也很明显,我们给 getInstance() 这个方法加了一把大锁(synchronzed),导致这个函数的并发度很低。量化一下的话,并发度是 1,也就相当于串行操作了。而这个函数是在单例使用期间,一直会被调用。如果这个单例类偶尔会被用到,那这种实现方式还可以接受。但是,如果频繁地用到,那频繁加锁、释放锁及并发度低等问题,会导致性能瓶颈,这种实现方式就不可取了。
双重检测: 饿汉式不支持延迟加载,懒汉式有性能问题,不支持高并发。那我们再来看一种既支持延迟加载、又支持高并发的单例实现方式,也就是双重检测实现方式。
在这种实现方式中,只要 instance 被创建之后,即便再调用 getInstance() 函数也不会再进入到加锁逻辑中了。所以,这种实现方式解决了懒汉式并发度低的问题。

网上有人说,这种实现方式有些问题。因为指令重排序,可能会导致 IdGenerator 对象被 new 出来,并且赋值给 instance 之后,还没来得及初始化(执行构造函数中的代码逻辑),就被另一个线程使用了。要解决这个问题,我们需要给 instance 成员变量加上 volatile 关键字,禁止指令重排序才行。实际上,只有很低版本的 Java 才会有这个问题。我们现在用的高版本的 Java 已经在 JDK 内部实现中解决了这个问题(解决的方法很简单,只要把对象 new 操作和初始化操作设计为原子操作,就自然能禁止重排序)。
静态内部类:

SingletonHolder 是一个静态内部类,当外部类 IdGenerator 被加载的时候,并不会创建 SingletonHolder 实例对象。只有当调用 getInstance() 方法时,SingletonHolder 才会被加载,这个时候才会创建 instance。instance 的唯一性、创建过程的线程安全性,都由 JVM 来保证。所以,这种实现方法既保证了线程安全,又能做到延迟加载。
枚举:
最后,我们介绍一种最简单的实现方式,基于枚举类型的单例实现。这种实现方式通过 Java 枚举类型本身的特性,保证了实例创建的线程安全性和实例的唯一性

工厂模式分为三种更加细分的类型:简单工厂、工厂方法和抽象工厂
1.工厂模式: 定义一个用于创建对象的接口,让子类决定实例化哪一个类。使一个类的实例化延迟到其子类
适用:当一个类不知道它所必须创建的对象的类的时候
- public interface IRuleConfigParserFactory {
- IRuleConfigParser createParser();
- }
- public class JsonRuleConfigParserFactory implements IRuleConfigParserFactory {
- @Override
- public IRuleConfigParser createParser() {
- return new JsonRuleConfigParser();
- }
- }
- public class XmlRuleConfigParserFactory implements IRuleConfigParserFactory {
- @Override
- public IRuleConfigParser createParser() {
- return new XmlRuleConfigParser();
- }
- }
- public class YamlRuleConfigParserFactory implements IRuleConfigParserFactory {
- @Override
- public IRuleConfigParser createParser() {
- return new YamlRuleConfigParser();
- }
- }
- public class PropertiesRuleConfigParserFactory implements IRuleConfigParserFactory {
- @Override
- public IRuleConfigParser createParser() {
- return new PropertiesRuleConfigParser();
- }
- }
从上面的工厂方法的实现来看,一切都很完美,但是实际上存在挺大的问题。问题存在于这些工厂类的使用上。接下来,我们看一下,如何用这些工厂类来实现 RuleConfigSource 的 load() 函数。具体的代码如下所示:
- public class RuleConfigSource {
- public RuleConfig load(String ruleConfigFilePath) {
- String ruleConfigFileExtension = getFileExtension(ruleConfigFilePath);
- IRuleConfigParserFactory parserFactory = RuleConfigParserFactoryMap.getParserFactory(ruleConfigFileExtension);
- if (parserFactory == null) {
- throw new InvalidRuleConfigException("Rule config file format is not supported: " + ruleConfigFilePath);
- }
- IRuleConfigParser parser = parserFactory.createParser();
- String configText = "";
- //从ruleConfigFilePath文件中读取配置文本到configText中
- RuleConfig ruleConfig = parser.parse(configText);
- return ruleConfig;
- }
- private String getFileExtension(String filePath) {
- //...解析文件名获取扩展名,比如rule.json,返回json
- return "json";
- }
- }
- //因为工厂类只包含方法,不包含成员变量,完全可以复用,
- //不需要每次都创建新的工厂类对象,所以,简单工厂模式的第二种实现思路更加合适。
- public class RuleConfigParserFactoryMap { //工厂的工厂
- private static final Map
- static {
- cachedFactories.put("json", new JsonRuleConfigParserFactory());
- cachedFactories.put("xml", new XmlRuleConfigParserFactory());
- cachedFactories.put("yaml", new YamlRuleConfigParserFactory());
- cachedFactories.put("properties", new PropertiesRuleConfigParserFactory());
- }
- public static IRuleConfigParserFactory getParserFactory(String type) {
- if (type == null || type.isEmpty()) {
- return null;
- }
- IRuleConfigParserFactory parserFactory = cachedFactories.get(type.toLowerCase());
- return parserFactory;
- }
- }
当我们需要添加新的规则配置解析器的时候,我们只需要创建新的 parser 类和 parser factory 类,并且在 RuleConfigParserFactoryMap 类中,将新的 parser factory 对象添加到 cachedFactories 中即可。代码的改动非常少,基本上符合开闭原则。实际上,对于规则配置文件解析这个应用场景来说,工厂模式需要额外创建诸多 Factory 类,也会增加代码的复杂性,而且,每个 Factory 类只是做简单的 new 操作,功能非常单薄(只有一行代码),也没必要设计成独立的类,所以,在这个应用场景下,简单工厂模式简单好用,比工厂方法模式更加合适。
2. 抽象工厂模式: 定义一个用于创建对象的接口,让子类决定实例化哪一个类。使一个类的实例化延迟到其子类
适用:一个系统要独立于它的产品的创建、组合和表示时
- // 产品1interface IProduct1{}
- class Product1A implements IProduct1{}
- // 扩展产品1 B系列
- class Product1B implements IProduct1{}
- // 产品2
- interface IProduct2{}
- class Product2A implements IProduct2{}
- // 扩展产品2 B系列
- class Product2B implements IProduct2{}
- // 工厂
- interface IFactory{
- public IProduct1 getProduct1();
- public IProduct2 getProduct2();
- };
- // 工厂 A ,生产A系列产品
- class FactoryA implements IFactory{
- public IProduct1 getProduct1(){
- return new Product1A();
- };
- public IProduct2 getProduct2(){
- return new Product2A();
- };
- }
- // 工厂 B ,生产B系列产品
- class FactoryB implements IFactory{
- public IProduct1 getProduct1(){
- return new Product1B();
- };
- public IProduct2 getProduct2(){
- return new Product2B();
- };
- }
- public class testAbstractFactory {
- public void test(){
- IFactory factory = new FactoryA();
- IProduct1 product1A = (IProduct1)factory.getProduct1();
- IProduct2 product2A = (IProduct2)factory.getProduct2();
- // 如果扩展产品系列B时,添加 FactoryB、ProductB即可,不需要修改原来代码
- factory = new FactoryB();
- IProduct1 product1B = (IProduct1)factory.getProduct1();
- IProduct2 product2B = (IProduct2)factory.getProduct2();
- }
- }
当我们需要添加新的规则配置解析器的时候,我们只需要创建新的 parser 类和 parser factory 类,并且在 RuleConfigParserFactoryMap 类中,将新的 parser factory 对象添加到 cachedFactories 中即可。代码的改动非常少,基本上符合开闭原则。实际上,对于规则配置文件解析这个应用场景来说,工厂模式需要额外创建诸多 Factory 类,也会增加代码的复杂性,而且,每个 Factory 类只是做简单的 new 操作,功能非常单薄(只有一行代码),也没必要设计成独立的类,所以,在这个应用场景下,简单工厂模式简单好用,比工厂方法模式更加合适。
判断是否用工厂模式的标准:
封装变化:创建逻辑有可能变化,封装成工厂类之后,创建逻辑的变更对调用者透明。
代码复用:创建代码抽离到独立的工厂类之后可以复用。
隔离复杂性:封装复杂的创建逻辑,调用者无需了解如何创建对象。
控制复杂度:将创建代码抽离出来,让原本的函数或类职责更单一,代码更简洁。
构造者模式: 将一个复杂对象的构建与它的表示分离,使得同样的构建过程可以创建不同的表示
适用:当创建复杂对象的算法应该独立于该对象的组成部分以及它们的装配方式时
- public class ResourcePoolConfig {
- private String name;
- private int maxTotal;
- private int maxIdle;
- private int minIdle;
- private ResourcePoolConfig(Builder builder) {
- this.name = builder.name;
- this.maxTotal = builder.maxTotal;
- this.maxIdle = builder.maxIdle;
- this.minIdle = builder.minIdle;
- }
- //...省略getter方法...
- //我们将Builder类设计成了ResourcePoolConfig的内部类。
- //我们也可以将Builder类设计成独立的非内部类ResourcePoolConfigBuilder。
- public static class Builder {
- private static final int DEFAULT_MAX_TOTAL = 8;
- private static final int DEFAULT_MAX_IDLE = 8;
- private static final int DEFAULT_MIN_IDLE = 0;
- private String name;
- private int maxTotal = DEFAULT_MAX_TOTAL;
- private int maxIdle = DEFAULT_MAX_IDLE;
- private int minIdle = DEFAULT_MIN_IDLE;
- public ResourcePoolConfig build() {
- // 校验逻辑放到这里来做,包括必填项校验、依赖关系校验、约束条件校验等
- if (StringUtils.isBlank(name)) {
- throw new IllegalArgumentException("...");
- }
- if (maxIdle > maxTotal) {
- throw new IllegalArgumentException("...");
- }
- if (minIdle > maxTotal || minIdle > maxIdle) {
- throw new IllegalArgumentException("...");
- }
- return new ResourcePoolConfig(this);
- }
- public Builder setName(String name) {
- if (StringUtils.isBlank(name)) {
- throw new IllegalArgumentException("...");
- }
- this.name = name;
- return this;
- }
- public Builder setMaxTotal(int maxTotal) {
- if (maxTotal <= 0) {
- throw new IllegalArgumentException("...");
- }
- this.maxTotal = maxTotal;
- return this;
- }
- public Builder setMaxIdle(int maxIdle) {
- if (maxIdle < 0) {
- throw new IllegalArgumentException("...");
- }
- this.maxIdle = maxIdle;
- return this;
- }
- public Builder setMinIdle(int minIdle) {
- if (minIdle < 0) {
- throw new IllegalArgumentException("...");
- }
- this.minIdle = minIdle;
- return this;
- }
- }
- }
- // 这段代码会抛出IllegalArgumentException,因为minIdle>maxIdle
- ResourcePoolConfig config = new ResourcePoolConfig.Builder()
- .setName("dbconnectionpool")
- .setMaxTotal(16)
- .setMaxIdle(10)
- .setMinIdle(12)
- .build();
如果一个类中有很多属性,为了避免构造函数的参数列表过长,影响代码的可读性和易用性,我们可以通过构造函数配合 set() 方法来解决。但是,如果存在下面情况中的任意一种,我们就要考虑使用建造者模式了。
我们把类的必填属性放到构造函数中,强制创建对象的时候就设置。如果必填的属性有很多,把这些必填属性都放到构造函数中设置,那构造函数就又会出现参数列表很长的问题。如果我们把必填属性通过 set() 方法设置,那校验这些必填属性是否已经填写的逻辑就无处安放了。
如果类的属性之间有一定的依赖关系或者约束条件,我们继续使用构造函数配合 set() 方法的设计思路,那这些依赖关系或约束条件的校验逻辑就无处安放了。
如果我们希望创建不可变对象,也就是说,对象在创建好之后,就不能再修改内部的属性值,要实现这个功能,我们就不能在类中暴露 set() 方法。构造函数配合 set() 方法来设置属性值的方式就不适用了。
原型模式:用原型实例指定创建对象的种类,并且通过拷贝这些原型创建新的对象
适用:当要实例化的类是在运行时刻指定时;或者需要创建多个对象并且这些对象内部状态相差不大
原型模式有两种实现方法,深拷贝和浅拷贝。浅拷贝只会复制对象中基本数据类型数据和引用对象的内存地址,不会递归地复制引用对象,以及引用对象的引用对象……而深拷贝得到的是一份完完全全独立的对象。所以,深拷贝比起浅拷贝来说,更加耗时,更加耗内存空间。如果要拷贝的对象是不可变对象,浅拷贝共享不可变对象是没问题的,但对于可变对象来说,浅拷贝得到的对象和原始对象会共享部分数据,就有可能出现数据被修改的风险,也就变得复杂多了。
- class Car implements Cloneable{
- private int id;
- public int getId() {return id;}
- public void setId(int id) {this.id = id;}
- public Car clone(){
- try {
- return (Car)super.clone();
- }catch (CloneNotSupportedException e) {
- e.printStackTrace();
- return null;
- }
- }
- }
- class Prototype implements Cloneable{
- private int id;
- private Car car;
- public Car getCar() {return car;}
- public void setCar(Car car) {this.car = car;}
- public int getId() {return id;}
- public void setId(int id) {this.id = id;}
- public Object clone(){
- try {
- boolean deep = true;
- if (deep){
- /**
- * 深复制,复制出了两辆车
- * */
- Prototype prototype = (Prototype)super.clone();
- prototype.setCar((Car)this.car.clone());
- // 继续复制其他引用对象
- return prototype;
- }else{
- /**
- * 浅复制 ,是同一辆车
- * */
- return super.clone();
- }
- } catch (CloneNotSupportedException e) {
- e.printStackTrace();
- return null;
- }
- }
- }
- public class TestPrototype {
- public void test(){
- Prototype p1 = new Prototype();
- p1.setCar(new Car());
- p1.setId(1);
- // 复制
- Prototype p2 = (Prototype)p1.clone();
- p2.setId(2);
- }
- }
代理模式:代理是一种常用的设计模式,代理模式可以对原有的类进行扩展,即通过代理对象的模式来访问目标类。
1.静态代理:静态代理需要代理类与目标类有一样的继承父类和实现接口
接口:
- public interface UserDao {
- public void addUser();
- public void deleteUser();
- }
目标类
- public class DbUser implements UserDao {
- @Override
- public void addUser() {
- System.out.println("添加用户操作");
- }
- @Override
- public void deleteUser() {
- System.out.println("删除用户操作");
- }
- }
静态代理类:
- public class StaticProxyUser implements UserDao {
- private DbUser target;
- public StaticProxyUser(DbUser dbUser) {
- target = dbUser;
- }
- @Override
- public void addUser() {
- System.out.println("添加前的操作");
- target.addUser();
- System.out.println("添加后的操作");
- }
- @Override
- public void deleteUser() {
- System.out.println("删除前的操作");
- target.deleteUser();
- System.out.println("删除后的操作");
- }
- }
测试:
- public class MyTest {
- @Test
- public void demo() {
- StaticProxyUser staticProxyUser = new StaticProxyUser(new DbUser());
- staticProxyUser.addUser();
- staticProxyUser.deleteUser();
- }
- }
静态代理总结:
1.可以做到在不修改目标对象的功能前提下,对目标功能扩展.
2.缺点:
因为代理对象需要与目标对象实现一样的接口,所以会有很多代理类,类太多.同时,一旦接口增加方法,目标对象与代理对象都要维护.
2动态代理(JDK代理)
动态代理不用实现目标类的接口,不会出现大量代理类的现象,一般情况下创建一个代理类就可以了。
动态代理对象的生成,是利用JDK的API,动态的在内存中构建代理对象(需要我们指定创建代理对象/目标对象实现的接口的类型)
动态代理也叫做:JDK代理,接口代理
动态代理需要使用newProxyInstance方法,该方法结构为static Object newProxyInstance(ClassLoader loader, Class<问号>] interfaces,InvocationHandler h ),可以看到该方法需要三个参数
参数1:ClassLoader 需要一个类加载器,Java中常用的类加载器有三种类型
启动类加载器(Bootstrap ClassLoader):这个类加载器负责将\lib目录下的类库加载到虚拟机内存中,用来加载java的核心库,此类加载器并不继承于java.lang.ClassLoader,不能被java程序直接调用,代码是使用C++编写的.是虚拟机自身的一部分.
扩展类加载器(Extendsion ClassLoader):
这个类加载器负责加载\lib\ext目录下的类库,用来加载java的扩展库,开发者可以直接使用这个类加载器.应用程序类加载器(Application ClassLoader):
这个类加载器负责加载用户类路径(CLASSPATH)下的类库,一般我们编写的java类都是由这个类加载器加载,这个类加载器是CLassLoader中的getSystemClassLoader()方法的返回值,所以也称为系统类加载器.一般情况下这就是系统默认的类加载器.
除此之外,我们还可以加入自己定义的类加载器,以满足特殊的需求,需要继承java.lang.ClassLoader类.
参数2:Class <问好>[] interfaces,:目标对象实现的接口的类型,使用泛型方式确认类型
参数3:InvocationHandler h:事件处理,执行目标对象的方法时,会触发事件处理器的方法,会把当前执行目标对象的方法作为参数传入接口:
- public interface UserService {
- void addUser();
- void updateUser();
- void delUser();
- }
目标类:
- public class UserServiceImpl implements UserService {
- @Override
- public void addUser() {
- System.out.println("添加用户");
- }
- @Override
- public void updateUser() {
- System.out.println("更新用户");
- }
- @Override
- public void delUser() {
- System.out.println("删除用户");
- }
- }
代理类:
- public class ProxyFactory {
- //维护一个目标对象
- private Object target;
- public ProxyFactory(Object target) {
- this.target = target;
- }
- public Object getProxyInstance() {
- return Proxy.newProxyInstance(target.getClass().getClassLoader(),
- target.getClass().getInterfaces(), new InvocationHandler() {
- @Override
- public Object invoke(Object o, Method method, Object[] args) throws Throwable {
- System.out.println("开始事务2");
- //执行目标对象
- Object invoke = method.invoke(target, args);
- System.out.println("提交事务2");
- return invoke;
- }
- });
- }
- }
测试:
- @Test
- public void testUserService() {
- //目标对象
- UserService target = new UserServiceImpl();
- UserService proxy = (UserService) new ProxyFactory(target).getProxyInstance();
- proxy.addUser();
- }
3CGLIB代理
上面的静态代理和动态代理模式都是要求目标对象是实现一个接口的目标对象,但是有时候目标对象只是一个单独的对象,并没有实现任何的接口,这个时候就可以使用以目标对象子类的方式类实现代理,这种方法就叫做:Cglib代理Cglib代理,也叫作子类代理,它是在内存中构建一个子类对象从而实现对目标对象功能的扩展.
JDK的动态代理有一个限制,就是使用动态代理的对象必须实现一个或多个接口,如果想代理没有实现接口的类,就可以使用Cglib实现.
Cglib是一个强大的高性能的代码生成包,它可以在运行期扩展java类与实现java接口.它广泛的被许多AOP的框架使用,例如Spring AOP和synaop,为他们提供方法的interception(拦截)
Cglib包的底层是通过使用一个小而块的字节码处理框架ASM来转换字节码并生成新的类.不鼓励直接使用ASM,因为它要求你必须对JVM内部结构包括class文件的格式和指令集都很熟悉.
Cglib子类代理实现方法:
1.需要引入cglib的jar文件,但是Spring的核心包中已经包括了Cglib功能,所以直接引入pring-core-3.2.5.jar即可.
2.引入功能包后,就可以在内存中动态构建子类
3.代理的类不能为final,否则报错
4.目标对象的方法如果为final/static,那么就不会被拦截,即不会执行目标对象额外的业务方法.
接口和目标类同上代理类:
- public class MyBeanFactory {
- //cglib代理
- public static UserService createUserService() {
- //目标类
- final UserService userService = new UserServiceImpl();
- /**
- * 代理类
- * 回掉函数中的intercept同jdk动态代理的invoke方法
- * 4个参数,前三个同jdk动态代理的参数
- * 第四个参数:methodProxy是目标类的方法的代理
- *
- */
- //1.1核心类
- Enhancer enhancer = new Enhancer();
- //1.2确定父类
- enhancer.setSuperclass(UserService.class);
- //1.3设置回掉函数
- enhancer.setCallback(new MethodInterceptor() {
- @Override
- public Object intercept(Object proxy, Method method, Object[] args, MethodProxy methodProxy) throws Throwable {
- System.out.println("执行前");
- Object invoke = method.invoke(userService, args);
- System.out.println("执行后");
- return invoke;
- }
- });
- //1.4创建代理对象
- UserService proxyUserService = (UserService) enhancer.create();
- return proxyUserService;
- }
- }
测试:
- public class test {
- @Test
- public void demo() {
- UserService userService = MyBeanFactory.createUserService();
- userService.addUser();
- userService.updateUser();
- userService.deleteUser();
- }
- }
使用时如果目标对象没有实现接口可以采用cglib代理,目标类实现了接口采用jdk动态代理,静态代理一般不建议使用。
桥接模式:将抽象部分与它的实现部分分离,使它可以独立的变更
角色:抽象层接口(Abstraction)、具体抽象层、实现者接口、具体实现者
什么时候用:1.不想在抽象与实现之间形成固定的绑定关系(这样就能在运行时切换实现)。2.抽象与实现都应可以通过子类化独立进行扩展。
3.对抽象的实现进行修改不应影响客户端代码。4.如果每个实现需要额外的子类以细化抽象,则说明有必要把它们分成两个部分。5.想在带有不同抽象接口的多个对象之间共享一个实现。桥接模式有两种理解方式。第一种理解方式是“将抽象和实现解耦,让它们能独立开发”。这种理解方式比较特别,应用场景也不多。另一种理解方式更加简单,类似“组合优于继承”设计原则
- interface ILeader{
- public void doSomething();
- }
- class LeaderA implements ILeader{
- @Override
- public void doSomething() {}
- }
- class LeaderB implements ILeader{
- @Override
- public void doSomething() {}
- }
- class Boss {
- ILeader leader;
- public void setLeader(ILeader leader) {
- this.leader = leader;
- }
- public void doSomething(){
- this.leader.doSomething();
- }
- }
- public class TestBirdge {
- public void test(){
- Boss boss = new Boss();
- LeaderA leaderA = new LeaderA();
- boss.setLeader(leaderA);
- boss.doSomething();
- // 当某个经理离职的时候,老板可以再找一个有经验的经理来做事,
- LeaderB leaderB = new LeaderB();
- boss.setLeader(leaderB);
- boss.doSomething();
- }
- }
装饰器模式:动态的给对象添加一些额外的责任,就增加功能来说,装饰比生成子类更为灵活
角色:组件接口(Component)、具体的组件、继承至Component的修饰接口(Decorator)、具体的修饰
理解:修饰接口Decorator继承Component,并持有Component的一个引用,所以起到了复用Component并增加新的功能。
什么时候用:1.想要在不影响其他对象的情况下,以动态、透明的方式给单个对象添加职责。2.想要扩展一个类的行为,却做不到。类定义可能被隐藏,无法进行子类化;或者对类的每个行为的扩展,哦支持每种功能组合,将产生大量的子类。
- interface ICar{
- public void run();
- }
- class Car implements ICar{
- @Override
- public void run() {
- }
- }
- // 现在想给汽车添加 氮气加速
- // 下面用子类化方式实现
- class SubClassCar extends Car{
- @Override
- public void run() {
- this.addNitrogen();
- super.run();
- }
- public void addNitrogen(){}
- }
- // 下面用装饰模式实现
- class DecoratorCar implements ICar{
- private Car car;
- @Override
- public void run() {
- this.addNitrogen();
- car.run();
- }
- public void addNitrogen(){}
- }
- public class TestDecorator {
- public void test(){
- }
- }
适配器模式:用来做适配的,它将不兼容的接口转换为可兼容的接口,让原本由于接口不兼容而不能一起工作的类可以一起工作
适配器模式有两种实现方式:类适配器和对象适配器。其中,类适配器使用继承关系来实现,对象适配器使用组合关系来实现
- // 类适配器: 基于继承
- public interface ITarget {
- void f1();
- void f2();
- void fc();
- }
- public class Adaptee {
- public void fa() { //... }
- public void fb() { //... }
- public void fc() { //... }
- }
- public class Adaptor extends Adaptee implements ITarget {
- public void f1() {
- super.fa();
- }
- public void f2() {
- //...重新实现f2()...
- }
- // 这里fc()不需要实现,直接继承自Adaptee,这是跟对象适配器最大的不同点
- }
- // 对象适配器:基于组合
- public interface ITarget {
- void f1();
- void f2();
- void fc();
- }
- public class Adaptee {
- public void fa() { //... }
- public void fb() { //... }
- public void fc() { //... }
- }
- public class Adaptor implements ITarget {
- private Adaptee adaptee;
- public Adaptor(Adaptee adaptee) {
- this.adaptee = adaptee;
- }
- public void f1() {
- adaptee.fa(); //委托给Adaptee
- }
- public void f2() {
- //...重新实现f2()...
- }
- public void fc() {
- adaptee.fc();
- }
- }
针对这两种实现方式,在实际的开发中,到底该如何选择使用哪一种呢?判断的标准主要有两个,一个是 Adaptee 接口的个数,另一个是 Adaptee 和 ITarget 的契合程度。
如果 Adaptee 接口并不多,那两种实现方式都可以。
如果 Adaptee 接口很多,而且 Adaptee 和 ITarget 接口定义大部分都相同,那我们推荐使用类适配器,因为 Adaptor 复用父类 Adaptee 的接口,比起对象适配器的实现方式,Adaptor 的代码量要少一些。
如果 Adaptee 接口很多,而且 Adaptee 和 ITarget 接口定义大部分都不相同,那我们推荐使用对象适配器,因为组合结构相对于继承更加灵活。
-
相关阅读:
2022-08-18 第六小组 瞒春 学习笔记
【计算机组成与设计】-第五章 memory hierarchy(二)
【stm32】hal库学习笔记-UART/USART串口通信(超详细!)
CatchAdmin实战教程(四)Table组件之自定义基础页面
day34 文件上传&黑白盒审计&逻辑&中间件&外部引用
lv6 嵌入式开发-Flappy bird项目
最后一个单词的长度[简单]
ChatGPT多模态升级,支持图片和语音,体验如何?
golang 中 sync.Mutex 的实现
【Leetcode刷题Python】199. 二叉树的右视图
- 原文地址:https://blog.csdn.net/guanshengg/article/details/126282151
