-
网络协议常用面试题汇总(二)
HTTP相关
URI和URL的区别
URI,是uniform resource identifier,统一资源标识符,用来唯一的标识一个资源。
Web上可用的每种资源如HTML文档、图像、视频片段、程序等都是用URI来定位的;
URI一般由三部分组成:
1.访问资源的命名机制;
2.存放资源的主机名;
3.资源自身的名称,由路径表示,着重强调于资源。URL是uniform resource locator,统一资源定位器,它是一种具体的URI,即URL可以用来标识一个资源,而且还指明了如何定位这个资源;
URL是intent上用来描述信息资源的字符串,主要用在各种www客户程序和服务器程序上;
采用URL可以用一种统一的格式来描述各个信息资源,包括文件、服务器的地址和目录等;
URL一般由三部分组成:
1.协议(或称为服务方式)
2.存在该资源的主机IP地址(有时也包括端口号)
3.主机资源的具体地址。如目录和文件等区别:URI是一种抽象的,高层次概念定义统一资源标识,而URL则是具体的资源标识的方式。
URL是一种URI。笼统的说,每个URL都是URI,但不一定每一个URI都是URL。在Java的URI中,一个URI实例可以代表绝对的,也可以是相对的,只要它符合URI的语法规则。而URL类则不仅符合语义,还包含了定位该资源的信息,因此它不能是相对的。
在Java类库中,URI类不包含任何访问资源的方法,它唯一的作用就是解析,相反的是,URL类可以打开一个到达资源的流。
TCP粘包/拆包的原因及解决方法?
TCP是以流的方式来处理数据,一个完整的包可能会被TCP拆分成多个包进行发送,也可能把小的封装成一个大的数据包发送。
TCP粘包/分包的原因:
应用程序写入的字节大小大于套接字发送缓冲区的大小,会发生拆包现象,而应用程序写入数据大小小于套接字缓冲区大小,网卡将应用多次写入的数据发送到网络上,这将会发生粘包现象;
进行MSS大小的TCP分段,当TCP报文长度-TCP头部长度>MSS的时候将发生拆包;
以太网帧的payload(净荷)大于MTU(1500字节)进行ip分片;解决方案
1.消息定长:FixedLengthFrameDecoder类;
2.包尾增加特殊字符分割:行分隔符类:LineBaseFrameDecoder或自定义分隔符类:DelimiterBaseFrameDecoder;
3.将消息分为消息头和消息体:LengthFieldBaseFrameDecoder类。分为有头部的拆包和粘包、长度字段在前且有头部的拆包与粘包、多扩展头部的拆包与粘包;JVM层面相关性能优化
当客户端的并发连接数达到数十万或者数百万时,系统一个较小的抖动就会导致很严重的后果,例如服务器的GC,导致应用暂停(STW)的GC持续几秒,就会导致海量的客户端设备掉线或者消息积压,一旦系统恢复,会有海量的设备接入或者海量的数据发送很可能瞬间就把服务器冲垮。
JVM层面的调优主要涉及GC参数优化,GC参数设置不当会导致频繁GC,甚至OOM异常,对服务端的稳定运行产生重大影响。- 确定GC优化目标
GC(垃圾收集)有三个主要指标。
1.吞吐量:是评价GC能力的重要指标,在不考虑GC引起的停顿时间或内存消耗时,吞吐量是GC能支撑应用程序大大的最高性能指标;
2.延迟:GC能力的最重要指标之一,是由于GC引起的停顿时间,优化目标是缩短延迟时间或完全消除停顿(STW),避免应用程序在运行过程中发生抖动。
3.内存占用:GC正常时占用的内存量。JVM GC调优的三个基本原则如下:
1.Minor go回收原则:每次新生代GC回收尽可能多的内存,减少应用程序发生Full gc的频率。
2.GC内存最大化原则:垃圾收集器能够使用的内存越大,垃圾收集器效率越高,应用程序运行也越流畅。但是过大的内存一次Full go耗时可能较长,如果能够有效避免Full GC,就需要做精细化调优。
3.3选2原则:吞吐量、延迟和内存占用不能兼得,无法同时做到吞吐量和暂停时间都最优,需要根据业务场景做选择。对于大多数应用,吞吐量优先,其次是延迟。当然对于时延敏感型的业务,需要调整次序。-
确定服务端内存占用
在优化GC之前,需要确定应用程序的内存占用大小,以便为应用程序设置合适的内存,提升GC效率。内存占用与活跃数据有关,活跃数据指的是应用程序稳定运行时长时间存活的Java对象、活跃数据的计算方式:通过GC日志采集GC数据,获取应用程序稳定时老年代占用的Java堆大小,以及永久代【元数据区】占用的Java堆大小,两者之和就是活跃数据的内存占用大小。 -
GC优化过程
1.GC数据的采集和研读;
2.设置合适的JVM堆的大小;
3.选择合适的垃圾回收器和回收策略;
Epoll相关
select、poll、epoll的区别?
select,poll,epoll都是操作系统实现IO多路复用的机制。我们知道,I/O多路复用就通过一种机制,可以监视多个描述符,一旦某个描述符就绪(一般是读就绪或者写就绪),能够通知程序进行相应的读写操作。那么就这三种机制有什么区别呢。
1.支持一个进程所能打开的最大连接数
select 单个进程所能打开的最大连接数有FD_SETSIZE宏定义,其大小是32个整数的大小(在32位的机器上,大小就是3232,同理64位机器人上FD_SETSIZE为3264) poll poll本质上和select没有区别,但是它没有最大连接数的限制,原因是它是基于链表来存储的 epoll 连接数基本上只受限于机器的内存大小 2.FD剧增后带来的IO效率问题
select 因为每次调用时都会对连接进行线性遍历,所以随着FD的增加会造成遍历速度慢的“线性下降性能问题”。 poll 同上 epoll 因为epoll内核中实现是根据每个fd上的callback函数来实现的,只有活跃的socket才会主动调用callback,所以在活跃socket较少的情况下,使用epoll没有前面两者的线性下降的性能问题,但是所有socket都很活跃的情况下,可能会有性能问题。 3.消息传递方式
select 内核需要将消息传递到用户空间,都需要内核拷贝动作 poll 同上 epoll epoll通过内核和用户空间共享一块内存来实现的 总结:
综上,在选择select、poll、epoll时要根据具体的使用场合以及这三种方式的自身特点。
1.表面上看epoll的性能最好,但是在连接数少并且都十分活跃的情况下,select和poll的性能可能比epoll好,毕竟epoll的通知机制需要很多函数回调;
2.select低效是因为每次它都需要轮询。但低效也是相对的,视情况而定,也可通过良好的设计改善。什么是水平触发(LT)和边缘触发(ET)?
Level_Triggered(水平触发):当被监控的文件描述符上有可读写事件发生时,epoll_wait()会通知处理程序去读写。如果这样没有把数据一次性全部读写完(如读写缓冲区太小),那么下次调用epoll_wait()时,它还会通知你在上次没读写完的文件描述符上继续读写,当然如果你一直不去读写,它会一直通知你!如果系统中有大量你不需要读写的就绪文件描述符,而它们每次都会返回,这样会大大降低处理程序检索自己的就绪文件描述符的效率!Edge_Triggered(边缘触发):当被监控的文件描述符上有可读写事件发生时,epoll_wait()会通知处理程序去读写。如果这次没有把数据全部读写完(如读写缓冲区太小),那么下次调用epoll_wait()时,它不会通知你,也就是它只会通知你一次,直到该文件描述符上出现第二次可读写事件才会通知你!这种模式比水平触发效率高,系统不会充斥大量你不关心的就绪文件描述符!select(),poll()模型都是水平触发模式,信号驱动IO是边缘触发模式,epoll()模型既支持水平触发,也支持边缘触发,默认是水平触发;
直接内存深入辨析
在所有的网络通信和应用程序中,每个TCP的Socket的内核中都有一个发送缓冲区(SO_SNDBUF)和一个接收缓冲区(SO_RECVBUF),可以使用套接字选项来更改该缓冲区大小。
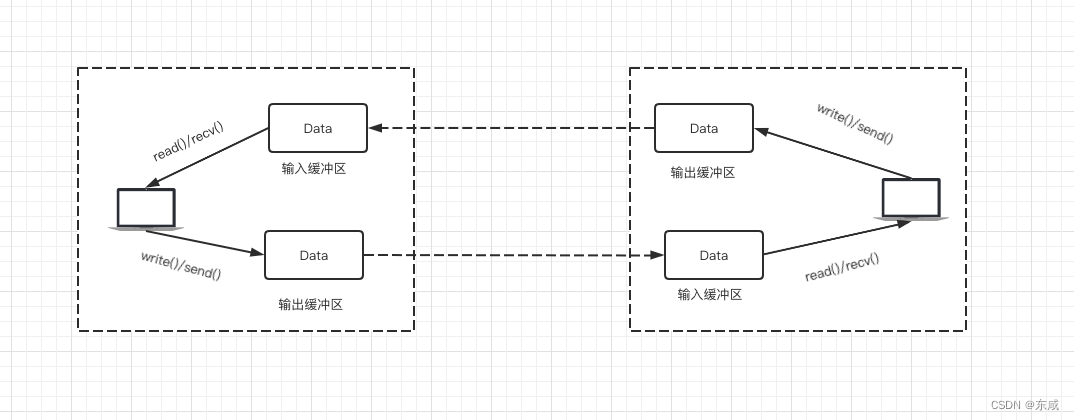
当某个应用进程调用write时,内核从该应用进程的缓冲区复制所有数据到所写套接字的发送缓冲区。如果该套接字的发送缓冲区容不下该应用进程的所有数据(或是应用进程的缓冲区大于套接字的发送缓冲区,或是套接字的发送缓冲区中已有其他数据),假设该套接字是阻塞的,则该应用进程将被投入睡眠。内核将不从write系统调用返回,直到应用进程缓冲区中的所有数据都复制到套接字发送缓冲区。因此,从写一个TCP套接字的write调用成功返回仅仅表示我们可以重新使用原来的应用进程缓冲区,并不表明对端的TCP或应用进程已接收到数据。

Java程序自然也要遵守上述的规则。但在Java中存在着堆、垃圾回收等待性,所以在实际的IO中,在JVM内部的存在着这样一种机制:
在IO读写上,如果是使用堆内存,JDK会先创建一个DirectBuffer,再去执行真正的写操作。这是因为,当我们把一个地址通过JNI传递给底层的C库的时候,有一个基本的要求,就是这个地址上的内容不能失效。然后,在GC管理下的对象是会在Java堆中移动的。也就是说,有可能我把一个地址传给底层的write,但是这段内存却因为GC整理内存而失效了。所以必须要把待发送的数据放在一个GC管不到的地方。这就是调用native方法之前,数据一定要在堆外内存的原因。可见,DirectBuffer并没有节省什么内存拷贝,只是因为HeapBuffer必须多做一次拷贝,使用DirectBuffer就会少一次内存拷贝。相比没有使用堆外内存的Java程序,使用直接内存的Java程序当然更快一点。
从垃圾回收的角度看,直接内存不受GC(新生代的Minor GC)影响,只有当执行老年代的Full GC时候才会顺便回收直接内存,整理内存的压力也比数据放到HeapBuffer要小。
堆外内存的优点和缺点
堆外内存相比于堆内存有几个优势:
1.减少了垃圾回收的工作,因为垃圾回收会暂停其他的工作(可能使用多线程或者时间片的方式,根本感觉不到)
2.加快了复制的速度。因为堆内在flush到远程时,会先复制到直接内存(非堆内存),然后在发送;而堆外内存相当于省略了这个工作;不好的一面:
1.堆外内存难以控制,如果内存泄漏,很难排查;
2.堆外内存相对来说,不适合存储很复杂的对象。一般简单的对象或者扁平化的比较合适。零拷贝
什么是零拷贝?
零拷贝技术指计算机执行操作时,CPU不需要先将数据从某处内存复制到另一个特定区域。这种技术通常用于通过网络传输文件时节省CPU周期和内存带宽。
零拷贝技术可以减少数据拷贝和共享总线操作的次数,消除传输数据在存储器之间不必要的中间拷贝次数,从而有效地提高数据传输效率。
零拷贝技术减少了用户进程地址空间和内核地址空间之间因为上下文切换而带来的开销。
可以看出没有说不需要拷贝,而是说减少不必要的拷贝;
下面这些组件,框架中均使用了零拷贝技术:kafka、netty、rocketmq、nginx、apache。
Linux的I/O机制与DMA
在早期计算机中,用户进程需要读取磁盘数据,需要CPU中断和CPU参与,因此效率比较低,发起IO请求,每次的IO中断,都带来CPU的上下文切换。因此出现了 – DMA。
DMA(Direct Memory Access,直接内存存取)是所有现代电脑的重要特色,它允许不同速度的硬件装置来沟通,而不需要依赖于CPU的大量中断负载。
DMA控制器,接管了数据读写请求,减少CPU的负担。这样一来,CPU能高效工作了。现代硬盘基本都支持DMA。
因此IO读取,涉及两个过程:
1.DMA等待数据准备好,把磁盘数据读取到操作系统内核缓冲区;
2.用户进程,将内核缓冲区的数据copy到用户空间;
这两个过程,都是阻塞的。传统数据传送机制
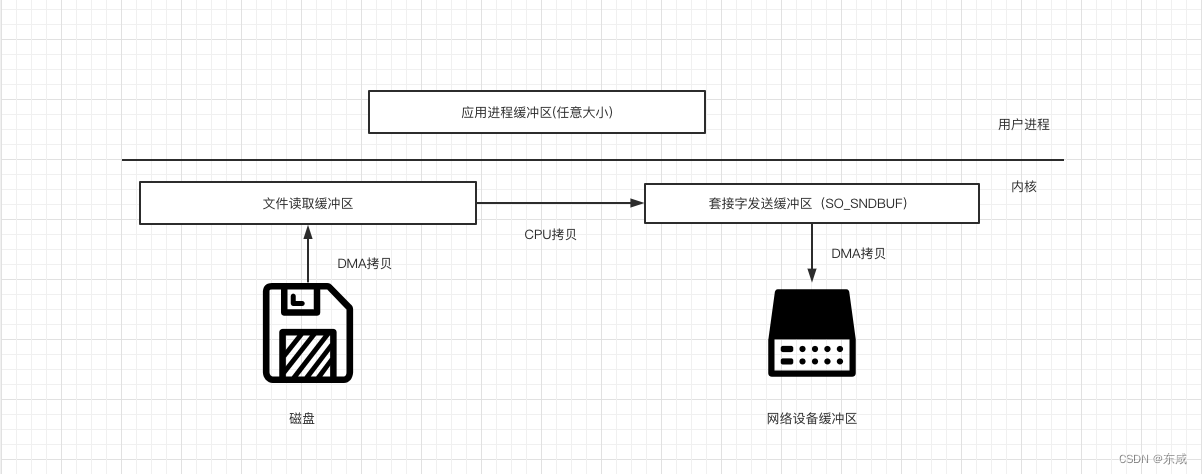
比如:读取文件,再用Socket发送出去,实际经过四次copy。
伪代码实现如下:
buffer = File.read()
Socket.send(buffer)1.第一次,将磁盘文件,读取到操作系统内核缓冲区;
2.第二次,将内核缓冲区的数据,copy到应用程序的buffer;
3.第三步,将应用程序buffer中的数据,copy到socket网络发送缓冲区(属于操作系统内核的缓冲区);
4.第四次,将socket buffer的数据,copy到网卡,由网卡进行网络传输;

分析上述的过程,虽然引入DMA来接管CPU的中断请求,但四次copy是存在“不必要的拷贝的”。实际上并不需要第二个和第三个数据副本。应用程序除了缓存数据并将其传输回套接字缓冲区之外什么都不做。相反,数据可以直接从读缓冲区传输到套接字缓冲区。显然,第二次和第三次数据copy其实在这种场景下没有什么帮助反而带来开销,这也正是零拷贝出现的背景和意义。
同时,read和send都属于系统调用,每次调用都牵涉到两次上下文切换;
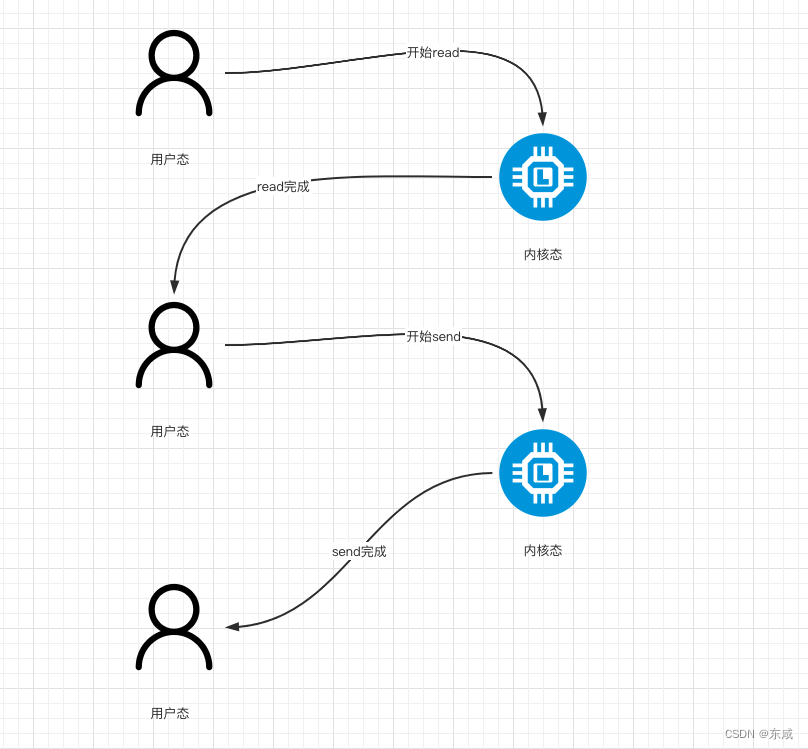
总结下,传统的数据传输所消耗的成本:4次拷贝,4次上下文切换;
4次拷贝,其中两次是DMA copy,两次是CPU copy。Linux支持的零拷贝
目的:减少IO流程中不必要的拷贝,当然零拷贝需要OS支持,也就是需要kernel暴露api。
mmap内存映射
硬盘上文件的位置和应用程序缓冲区进行映射(建立一种一一对应关系),由于mmap()将文件直接映射到用户空间,所以实际文件读取时根据这个映射关系,直接将文件从硬盘拷贝到用户空间,只进行了一次数据拷贝,不再有文件内容从硬盘拷贝到内核空间的一个缓冲区。
mmap内存映射将会经历:3次拷贝:1次cpu copy,2次DMA copy;以及4次上下文切换

sendfile
linux2.1支持sendfile,当调用sendfile()时,DMA将磁盘数据复制到kernel buffer,然后将内核中的kernel buffer直接拷贝到socket buffer。在硬件支持的情况下,甚至数据都并不需要被真正复制到socket关联的缓冲区内。取而代之的是,只有记录数据位置和长度的描述符被加入到socket缓冲区中,DMA模块将数据直接从内核缓冲区传递给协议引擎,从而消除了遗留的最后一次复制。
一旦数据全都拷贝到socket buffer,sendfile()系统调用将会return,代表数据转化的完成。socket buffer里的数据就能在网络传输了。
sendfile会经历:3次拷贝,1次CPU copy,2次DMA copy;硬件支持的情况下,则是2次拷贝,0次CPU copy,2次 DMA copy以及2次上下文切换;
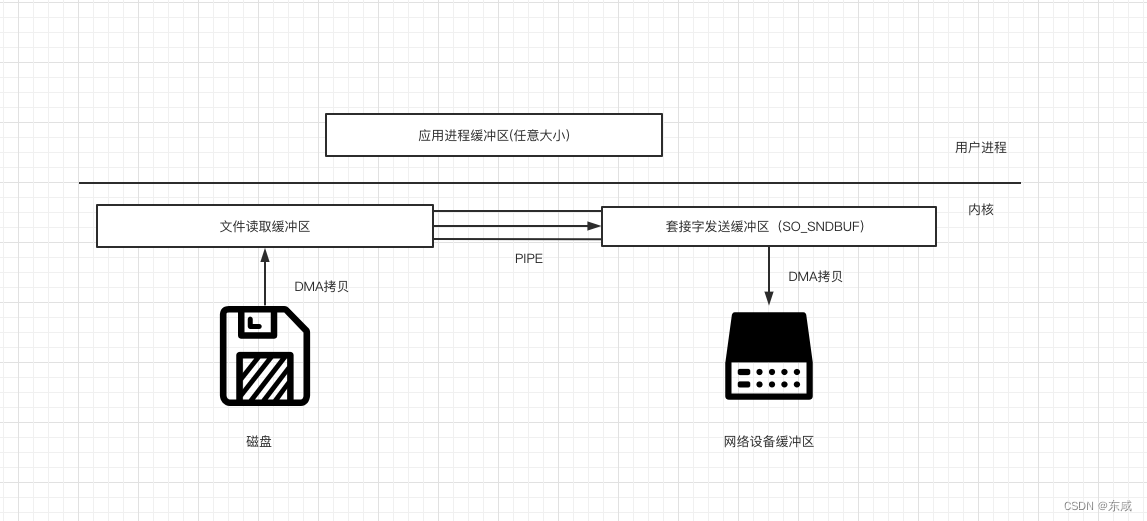
splice
linux从2.6.17支持splice
数据从磁盘读取到OS内核缓冲区后,在内核缓冲区直接可将其转成内核空间其他数据buffer,而不需要拷贝到用户空间。如下图所示,从磁盘读取到内核buffer后,在内核空间直接与socket buffer简历pipe管道;
和sendfile()不同的是,splice()不需要硬件支持。
注意splice和sendfile的不同,sendfile是将磁盘数据加载到kernel buffer后,需要一次CPU copy,拷贝到socket buffer。而splice是更进一步,连这个CPU copy也不需要了,直接将两个内核空间的buffer进行pipe。
splice会经历2次拷贝;0次cpu copy;2次DMA copy;以及2次上下文切换;
Linux提供的零拷贝技术Java并不是全支持,支持2种(内存映射mmap、sendfile)NIO提供的内存映射 MappedByteBuffer
NIO中的FileChannel.map()方法其实就是采用了操作系统中的内存映射方式,底层就是调用Linux mmap实现的。
将内核缓冲区的内存和用户缓冲区的内存做了一个地址映射。这种方式适合读取大文件,同时也能对文件内容进行更改,但是如果其后要通过SocketChannel发送,还是需要CPU进行数据的拷贝。NIO提供的sendfile
Java NIO中提供的FileChannel拥有transferTo和transferFrom两个方法,可直接把FileChannel中的数据拷贝到另一个Channel,或者直接把另外一个Channel中的数据拷贝到FileChannel。该接口常被用于高效的网络/文件的数据传输和大文件拷贝。在操作系统支持的情况下,通过该方法传输数据并不需要将源数据从内核态拷贝到用户态,再从用户态拷贝到目标通道的内核态,同时也避免了两次用户态和内核态间的上下文切换,也即使用了”零拷贝“,所以其性能一般高于Java IO中提供的方法。
-
相关阅读:
基于偏二叉树SVM多分类算法的应用层DDoS检测方法
参数估计——《概率论及其数理统计》第七章学习报告(点估计)
由国内知名企业开源人工智能项目想到的
【python】Numpy统计函数总结
数据通信网络基础
《MySQL高级篇》七、性能分析工具的使用(慢查询日志 | EXPLAIN | SHOW PROFILING | 视图分析 )
《机器学习核心算法》分类算法 - 朴素贝叶斯 MultinomialNB
Python的PyQt框架的使用-构建环境篇
微服务线上问题排查困难?不知道问题出在哪一环?那是你还不会分布式链路追踪
rv1126-rv1109-驱动方法
- 原文地址:https://blog.csdn.net/a734474820/article/details/126259632