-
spark学习笔记(十)——sparkSQL核心编程-自定义函数UDF、UDAF/读取保存数据/五大数据类型
目录
用到的全部依赖
- <dependencies>
- <dependency>
- <groupId>org.apache.sparkgroupId>
- <artifactId>spark-core_2.12artifactId>
- <version>3.0.0version>
- dependency>
- <dependency>
- <groupId>org.apache.sparkgroupId>
- <artifactId>spark-sql_2.12artifactId>
- <version>3.0.0version>
- dependency>
- <dependency>
- <groupId>mysqlgroupId>
- <artifactId>mysql-connector-javaartifactId>
- <version>5.1.27version>
- dependency>
- <dependency>
- <groupId>org.apache.sparkgroupId>
- <artifactId>spark-hive_2.12artifactId>
- <version>3.0.0version>
- dependency>
- <dependency>
- <groupId>org.apache.hivegroupId>
- <artifactId>hive-execartifactId>
- <version>1.2.1version>
- dependency>
- dependencies>
- <build>
- <plugins>
- <plugin>
- <groupId>net.alchim31.mavengroupId>
- <artifactId>scala-maven-pluginartifactId>
- <version>3.2.2version>
- <executions>
- <execution>
- <goals>
- <goal>testCompilegoal>
- goals>
- execution>
- executions>
- plugin>
- <plugin>
- <groupId>org.apache.maven.pluginsgroupId>
- <artifactId>maven-assembly-pluginartifactId>
- <version>3.1.0version>
- <configuration>
- <descriptorRefs>
- <descriptorRef>jar-with-dependenciesdescriptorRef>
- descriptorRefs>
- configuration>
- <executions>
- <execution>
- <id>make-assemblyid>
- <phase>packagephase>
- <goals>
- <goal>singlegoal>
- goals>
- execution>
- executions>
- plugin>
- plugins>
- build>
用户自定义函数
用户可以通过spark.udf功能添加自定义函数,实现自定义功能。
UDF
(1)创建DataFrame
在spark的bin目录下创建input文件夹,在input里创建user.json文件,user.json内容如下:
{"username":"zj","age":20}
{"username":"xx","age":21}
{"username":"yy","age":22}val df = spark.read.json("input/user.json")(2)注册UDF
spark.udf.register("addName",(x:String)=> "Name:"+x)(3)创建临时表
df.createOrReplaceTempView("people")(4)应用UDF
spark.sql("Select addName(username),age from people").show()
UDAF
强类型的Dataset和弱类型的DataFrame都提供了相关的聚合函数max(),min(),count(),avg()等等。
用户可以设定自定义聚合函数,通过继承UserDefinedAggregateFunction来实现用户自定义弱类型聚合函数。Spark3.0版本推荐使用强类型聚合函数Aggregator。
在datas目录下新建user.json文件,内容为:
{"username": "zj","age": 25} {"username": "qq","age": 32} {"username": "ww","age": 43}
弱类型
- import org.apache.spark.SparkConf
- import org.apache.spark.sql.expressions.{MutableAggregationBuffer, UserDefinedAggregateFunction}
- import org.apache.spark.sql.types.{DataType, LongType, StructField, StructType}
- import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession, types}
- object sparkSQL_UDAF {
- def main(args: Array[String]): Unit = {
- //TODO 创建sparkSQL运行环境
- val sparkConf = new SparkConf().setMaster("local[*]").setAppName("sparkSQL")
- val spark = SparkSession.builder().config(sparkConf).getOrCreate()
- //TODO 执行逻辑操作 计算平均年龄
- //创建DataFrame
- val df = spark.read.json("datas/user.json")
- //创建临时表
- df.createOrReplaceTempView("user")
- //自定义
- spark.udf.register("ageAvg",new AvgUDAF())
- spark.sql("select ageAvg(age) from user").show()
- //TODO 关闭环境
- spark.stop()
- }
- /*
- 自定义函数:计算平均值
- 1.继承
- 2.重写方法
- */
- class AvgUDAF extends UserDefinedAggregateFunction{
- //输入数据的结构
- override def inputSchema: StructType = {
- StructType(
- Array(
- StructField("age",LongType)
- )
- )
- }
- //缓冲区数据的结构
- override def bufferSchema: StructType = {
- StructType(
- Array(
- StructField("total",LongType),
- StructField("count",LongType)
- )
- )
- }
- //函数计算结果数据类型
- override def dataType: DataType = LongType
- //函数稳定性
- override def deterministic: Boolean = true
- //缓冲区初始化
- override def initialize(buffer: MutableAggregationBuffer): Unit = {
- buffer.update(0,0L)
- buffer.update(1,0L)
- }
- //根据输入的值更新缓冲区数据
- override def update(buffer: MutableAggregationBuffer, input: Row): Unit = {
- buffer.update(0,buffer.getLong(0)+input.getLong(0))
- buffer.update(1,buffer.getLong(1)+1)
- }
- //缓冲区数据合并
- override def merge(buffer1: MutableAggregationBuffer, buffer2: Row): Unit = {
- buffer1.update(0,buffer1.getLong(0) + buffer2.getLong(0))
- buffer1.update(1,buffer1.getLong(1) + buffer2.getLong(1))
- }
- //计算平均值
- override def evaluate(buffer: Row): Any = {
- buffer.getLong(0)/buffer.getLong(1)
- }
- }
- }
结果

强类型
- import org.apache.spark.SparkConf
- import org.apache.spark.sql.expressions.Aggregator
- import org.apache.spark.sql.{Encoder, Encoders, Row, SparkSession, functions}
- object sparkSQL_UDAF02 {
- def main(args: Array[String]): Unit = {
- //TODO 创建sparkSQL运行环境
- val sparkConf = new SparkConf().setMaster("local[*]").setAppName("sparkSQL")
- val spark = SparkSession.builder().config(sparkConf).getOrCreate()
- //TODO 执行逻辑操作 计算平均年龄
- //创建DataFrame
- val df = spark.read.json("datas/user.json")
- //创建临时表
- df.createOrReplaceTempView("user")
- //自定义操作
- spark.udf.register("ageAvg",functions.udaf(new AvgUDAF()))
- spark.sql("select ageAvg(age) from user").show()
- //TODO 关闭环境
- spark.stop()
- }
- /*
- 自定义函数:计算平均值
- 1.继承Aggregator
- IN:输入的数据类型Long
- BUF:缓冲区的数据类型Buff
- OUT:输出的数据类型Long
- 2.重写方法
- */
- case class Buff(var total:Long,var count:Long)
- class AvgUDAF extends Aggregator[Long,Buff,Long]{
- //初始值/零值 缓冲区的初始化
- override def zero: Buff = {
- Buff(0L,0L)
- }
- //根据输入的数据更新缓冲区的数据
- override def reduce(buff: Buff, in: Long): Buff = {
- buff.total = buff.total + in
- buff.count = buff.count + 1
- buff
- }
- //合并缓冲区
- override def merge(buff1: Buff, buff2: Buff): Buff = {
- buff1.total = buff1.total + buff2.total
- buff1.count = buff1.count + buff2.count
- buff1
- }
- //计算结果
- override def finish(buff: Buff): Long = {
- buff.total / buff.count
- }
- //缓冲区的编码操作
- override def bufferEncoder: Encoder[Buff] = Encoders.product
- //输出的编码操作
- override def outputEncoder: Encoder[Long] = Encoders.scalaLong
- }
- }
结果

数据的读取与保存
通用的方式
SparkSQL提供了通用的保存数据和读取数据的方式;通用指的是使用相同的API根据不同的参数读取和保存不同格式的数据,SparkSQL默认读取和保存的文件格式是parquet。
(1)读取数据
读取数据的通用方法:spark.read.load
数据类型:csv、format、jdbc、json、load、option、options、orc、parquet、schema、table、text、textFile
读取不同格式的数据要对不同的数据格式进行设定:
spark.read.format("…")[.option("…")].load("…")
format("…"):指定加载的数据类型:csv、jdbc。json、orc、parquet、textFile;
load("…"):在csv、jdbc、json、orc、parquet、textFile格式下传入数据的路径;
option("…"):在jdbc格式下需要传入JDBC相应参数:url、user、password、dbtable;
注:直接在文件上进行查询:文件格式 ‘文件路径’
spark.sql("select * from json.`datas/user.json`").show(2)保存数据
保存数据的通用方法:df.write.save
保存不同格式的数据,可以对不同的数据格式进行设定:
df.write.format("…")[.option("…")].save("…")
format("…"):指定保存的数据类型:csv、jdbc、json、orc、parquet、textFile;
save ("…"):在csv、orc、parquet、textFile格式下保存数据的路径;
option("…"):在jdbc格式下需要传入JDBC相应参数:url、user、password、dbtable;
保存操作可以使用SaveMode用来指明如何处理数据,使用mode()方法来设置;有一点很重要这些 SaveMode都是没有加锁的, 也不是原子操作。
Scala/Java any language meaning SaveMode ErrorIfExists(默认) “error” 如果文件已经存在则异常 SaveMode Append “append” 如果文件已经存在则追加 SaveMode Overwrite “overwrite” 如果文件已经存在则覆盖
SaveMode Ignore “ignore” 如果文件已经存在则忽略 df.write.mode("append").json("/data/output")数据类型
(1)JSON
SparkSQL能够自动推测JSON数据集的结构,并将它加载为一个Dataset[Row],可以通过 SparkSession.read.json()去加载JSON文件,且读取的JSON文件不是传统的JSON文件,每一行都应该是一个JSON串。
如:
{"username": "zj","age": 25} {"username": "qq","age": 32} {"username": "ww","age": 43}- //导入隐式转换
- import spark.implicits._
- //加载JSON文件
- val path = "input/user.json"
- val df = spark.read.json(path)
- //创建临时表
- df.createOrReplaceTempView("user")
- //数据查询
- val userDF = spark.sql("select name from user where age between 20 and 40")
- userDF.show()
(2)CSV
SparkSQL可以配置CSV文件的列表信息、读取CSV文件;CSV文件的第一行设置为数据列。
spark.read.format("csv").option("sep", ";").option("inferSchema","true").option("header", "true").load("input/user.csv").show
(3)Parquet
SparkSQL的默认数据源为Parquet格式;
Parquet是一种能够有效存储嵌套数据的列式存储格式;
数据源为Parquet文件时,SparkSQL可以方便的执行所有的操作,不需要使用format;
修改配置项spark.sql.sources.default可修改默认数据源格式。
- //加载数据
- val df = spark.read.load("/input/users.parquet")
- df.show
- //保存数据
- df.write.mode("append").save("/output")
(4)MySQL
SparkSQL可以通过JDBC从关系型数据库中以读取数据的方式创建DataFrame,通过对 DataFrame一系列的计算后,还可以将数据再写回关系型数据库中。
使用spark-shell操作可在启动shell时指定相关的数据库驱动路径或者将相关的数据库驱动放到spark的类路径下。
1)导入依赖
- <dependency>
- <groupId>mysqlgroupId>
- <artifactId>mysql-connector-javaartifactId>
- <version>5.1.27version>
- dependency>
2)读取数据/写入数据
创建数据库
- create database spaek;
- use spark;
创建表
- CREATE TABLE IF NOT EXISTS Produce
- (
- id int NOT NULL,
- name varchar(45) NOT NULL,
- age INT NULL,
- PRIMARY KEY (id)
- )
- ENGINE = innodb;
添加mysql数据
insert into user values (1,'zj',24),(2,'zjj',34),(7,'zjjj',42);
spark代码:
- import java.util.Properties
- import org.apache.spark.SparkConf
- import org.apache.spark.sql.{DataFrame, Dataset, Row, SaveMode, SparkSession}
- object sparkSQL_JDBC {
- def main(args: Array[String]): Unit = {
- //TODO 创建sparkSQL运行环境
- val sparkConf = new SparkConf().setMaster("local[*]").setAppName("sparkSQL")
- val spark = SparkSession.builder().config(sparkConf).getOrCreate()
- import spark.implicits._
- //TODO 执行逻辑操作
- //读取MySQL数据 方式一
- val df = spark.read
- .format("jdbc")
- .option("url","jdbc:mysql://hadoop01:3306/spark")
- .option("driver","com.mysql.jdbc.Driver")
- .option("user","root")
- .option("password","123456")
- .option("dbtable","user")
- .load()
- df.show()
- //读取MySQL数据 方式二
- spark.read.format("jdbc")
- .options(Map("url"->"jdbc:mysql://hadoop01:3306/spark?user=root&password=123456","dbtable"->"user","driver"->"com.mysql.jdbc.Driver")).load().show
- //读取MySQL数据 方式三
- val props: Properties = new Properties()
- props.setProperty("user", "root")
- props.setProperty("password", "123456")
- val dff: DataFrame = spark.read.jdbc("jdbc:mysql://hadoop01:3306/spark",
- "user", props)
- dff.show
- //保存数据
- df.write
- .format("jdbc")
- .option("url","jdbc:mysql://hadoop01:3306/spark")
- .option("driver","com.mysql.jdbc.Driver")
- .option("user","root")
- .option("password","123456")
- .option("dbtable","user1")
- .mode(SaveMode.Append)
- .save()
- //TODO 关闭环境
- spark.stop()
- }
- }
运行结果:

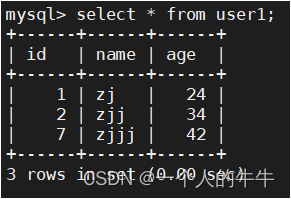
(5)hive
1)Apache Hive是Hadoop上的SQL引擎,SparkSQL包含Hive支持,支持Hive表访问、UDF、Hive查询语言HQL等。
2)在Spark SQL中包含Hive库,并不需要事先安装Hive。最好还是在编译Spark SQL时引入Hive支持,这样就可以使用这些特性了。如果下载的是二进制版本的Spark,应该已经在编译时添加了Hive支持。
3)若要把Spark SQL连接到一个部署好的Hive上,必须把hive-site.xml复制到Spark的配置文件目录中($SPARK_HOME/conf)。
4)没有部署好Hive,Spark SQL也可以运行。 需要注意的是,如果没有部署好Hive,Spark SQL会在当前的工作目录中创建出自己的Hive元数据仓库metastore_db。尝试使用HQL中的CREATE TABLE语句来创建表,这些表会被放在你默认的文件系统中的 /user/hive/warehouse目录中。
注:如果classpath中有配好的hdfs-site.xml,默认的文件系统就是HDFS,否则就是本地文件系统,spark-shell默认Hive支持;代码中默认不支持,需要手动指定)。
5)连接外部已经部署好的Hive,需要几个步骤:
Spark要接管Hive需要把hive-site.xml拷贝到conf/目录下;
把Mysql的驱动拷贝到jars/目录下;
如果访问不到hdfs,则需要把core-site.xml和hdfs-site.xml拷贝到conf/目录下;
重启spark-shell。
6)Spark SQL CLI 可以在本地运行Hive元数据服务以及从命令行执行查询任务。在Spark目录下执行命令bin/spark-sql启动Spark SQL CLI,直接执行SQL语句,类似Hive窗口。
7)Spark Thrift Server是Spark基于HiveServer2实现的一个Thrift服务,无缝兼容HiveServer2;Spark Thrift Server的接口和协议都和HiveServer2完全一致,因此我们部署好Spark Thrift Server后,可以直接使用hive的beeline访问Spark Thrift Server执行相关语句。Spark Thrift Server的目的只是取代HiveServer2,它依旧可以和Hive Metastore进行交互,获取到 hive 的元数据。
连接Thrift Server,需要几个步骤:
Spark要接管Hive需要把hive-site.xml拷贝到conf/目录下;
把Mysql的驱动拷贝到jars/目录下;
如果访问不到hdfs,则需要把core-site.xml和hdfs-site.xml拷贝到conf/目录下;
启动Thrift Server。
注:sbin/start-thriftserver.sh
使用beeline连接Thrift Server:bin/beeline -u jdbc:hive2://hadoop01:10000 -n root
8)导入依赖
- <dependency>
- <groupId>org.apache.sparkgroupId>
- <artifactId>spark-hive_2.12artifactId>
- <version>3.0.0version>
- dependency>
- <dependency>
- <groupId>org.apache.hivegroupId>
- <artifactId>hive-execartifactId>
- <version>1.2.1version>
- dependency>
9)将hive-site.xml文件拷贝到项目的resources目录中,代码实现:
- import org.apache.spark.SparkConf
- import org.apache.spark.sql.{SparkSession}
- object sparkSQL_hive {
- def main(args: Array[String]): Unit = {
- //TODO 创建sparkSQL运行环境
- val sparkConf = new SparkConf().setMaster("local[*]").setAppName("sparkSQL")
- val spark = SparkSession.builder().config(sparkConf).getOrCreate()
- //TODO 执行逻辑操作
- //使用sparkSQL连接hive
- //1.拷贝hive-site.xml文件到classpath下
- //2.启用hive支持
- //3.增加依赖
- spark.sql("show tables").show()
- //TODO 关闭环境
- spark.stop()
- }
- }

本文仅仅是学习笔记的记录!!
-
相关阅读:
2023数维杯国际赛数学建模D题完整论文分享!
里程碑,用自己的编程语言实现了一个网站
上周热点回顾(5.2-5.8)
LeetCode --- 1380. Lucky Numbers in a Matrix 解题报告
数据结构-字符串详解
mysql load data infile导入数据主键重复怎么解决
deepfm内容理解
pytest 的使用===谨记
【Vue3+Ts】项目启动准备和配置项目代码规范和css样式的重置
异硫氰酸荧光素标记磁性四氧化三铁纳米粒FITC-Hyd-PEG-Fe3O4|近红外染料CY7.5标记纳米二氧化硅CY7.5-SiO2 NPs
- 原文地址:https://blog.csdn.net/qq_55906442/article/details/126241967
