-
基于python实现Web自动化测试(selenium)、API自动化测试(requests)&附学习视频
另一篇文章:自动化测试框架(pytest)&附学习视频
web自动化
说明:
1紧跟着写的不加/,不加空格-表示同一级别信息,加空格表示后代
2.css定位tag,id,class时分别有不同的标识,其他属性都要加[]进行搜索,
Xpath所有属性都要都加【】,tag不用
3. css在使用tag,id,class定位时可以不写全信息,其他要写全
4.//用在xpath 空格用在css
5.xpath 写属性时,前面一定要加标签,或者是* //*[@id=‘west’]>
6. //div/button[1] xpath的1就是list的0


API测试
1.什么是接口测试?
对软件系统消息交互接口的测试,叫接口测试。链接
- SMS系统前端 和 后端服务器之间是消息交互接口,2.使用美团订餐, 美团APP和美团服务器之间, 也是消息交互的。
- HTTP协议的特点是,客户端发出一个HTTP请求给 服务端,服务端就返回一个HTTP响应。好像程序的API调用。
- API接口请求消息,通常都需要 服务端程序进行 一番处理,比如:对请求的权限检查,从数据库中读出数据,进行信息过滤和 格式转换,最后在HTTP响应中返回给客户端。
- 为什么 获取网页、图片这些 HTTP消息 通常不叫 API 接口消息呢?
答:网页、图片、css 这些资源,都是 静态资源 , 就是一个个文件存储在服务器上的,获取这些信息,服务端直接读取文件,返回给客户端即可,无需特别的数据处理。 - 基于 HTTP 的接口测试工具, 常见的 有 Postman、Jmeter等,这些工具核心功能都是类似,都是用来构建HTTP请求消息,并且解析收到的HTTP响应消息, 用户来判断是否符合预期,也完全python+requsets库实现自己开发测试工具,进行测试。
- web测试,测试的是整个系统(前段+后端),接口测试就是前后端之前的消息交互
2.内外部接口
内部接口: 产品(也就是被测系统) 内部子系统之间 的接口。
外部接口:产品(也就是被测系统)和 另外的系统交互的接口。

3.fiddler抓包工具
浏览器,F12可以查看http请求消息,http响应消息。
Requests 库 是用来发送HTTP请求,接收HTTP响应的一个Python库。
当软件运行时,发送的http请求会经过fiddler,关闭软件,恢复正常

4.Python实现接口测试
4.1简单看一下测试文档
根据下面的这种测试接口文档的要求,我们利用requests库进行http的请求,看服务器是否返回我们的需求。
大量工作时,建立一个package, 将相应方法封装到类中。

4.2Requsets库发送http请求
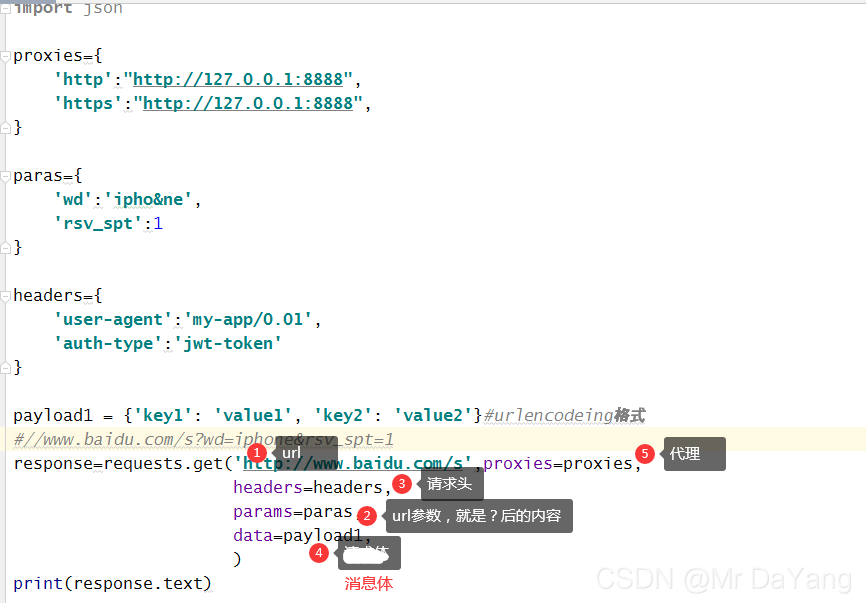
4.3检查http响应

注意消息体- 传送数据时,将本地写的字符串,通过encode编码成字节串,发送给服务器,服务器处理完,返回字节串,我们需要再解码成字符串方便阅读。
- response.content(字节码格式) response.text(字符串格式) 都是消息体。

4.4三种请求消息体格式: XML,urlencode,JSON,
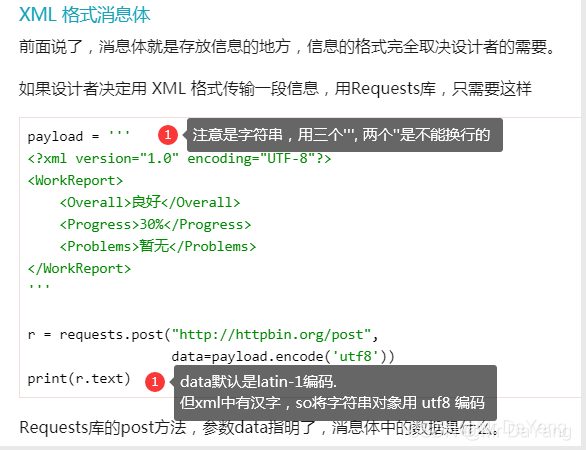

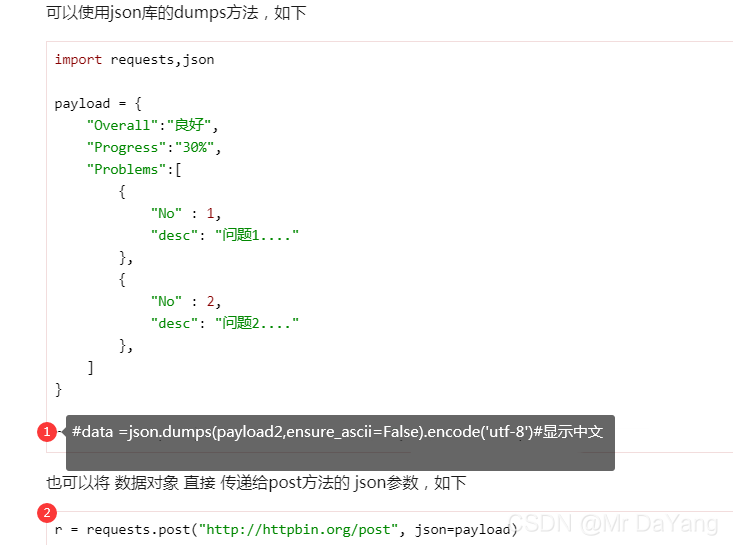
5.三种鉴权机制(cookie,session,token)
鉴权机制就是让服务器知晓,收到的两个请求,是否来自同一个用户。这样才能保证我自己淘宝收藏的东西,不会跑到其他用户那。


- http是一种无状态协议(对事务处理没有记忆能力),是无连接的(每次连接只处理一个请求,用后立即断开连接),因此需要鉴权机制进行来接用户,之前的古老操作是 每次操作都要带上用户id,很繁琐,所以来了cookie,session,token鉴权机制
- cookie
a. cookie的本质是一小段的文本信息,格式的字典,key=value。cookie的名称不是国定的,是由开发自定义的。
b. 第一次c访问s,s将cookie信息放到响应头的Set-cookie中,返给c。
c. 分类:会话cookie 1保存在内存,当浏览器的会话关闭之后自动消失。持久cookie :保存在硬盘,只有当失效时间到期了才会自动消失。
d. 当客户端从第2次开始直到后面的所有请求,在请求头的Cookie都会自动的带上以上的Cookie的信息。从而实现鉴权。
因为cookie是保存在客户端,可被截获,对于支付密码,银行卡号的信息存储就不安全,so->session,密码,直接变成了一个新的字段 - seesion
sessionid ( phpwindid , phpid ,windowsuers ),一般是一个比较长的经过加密的字符串,sessionid在服务器和客户端分别都保存了一份,,然后通过cookie的鉴权的方式实现session的鉴权(sessionid 是存储在cookie中的)。
安全性

- token
a. 由于京东淘宝用户大,对于存储session的话还是很大,session生命周期默认30分钟,所以大项目时,满足不了需求
b. 小程序,app,公众号是没有浏览器的,是不好传cookie,session的,so token

5.1session机制
网站服务程序怎么知道每个HTTP请求(比如付费 HTTP 请求)对应的是哪个客户的呢?—>建立seesion机制(会话机制)
使用session 机制区分用户,当然还有其他机制

实现:- 我们可以通过查找字典的方式获取响应头的cookie,然后加到请求头中
- 使用requests.Session()类,直接记录cookie
# 创建 Session 对象 s = requests.Session() # 通过 Session 对象 发送请求 response = s.post("http://127.0.0.1/api/mgr/signin", data={ 'username': 'byhy', 'password': '88888888' }) printResponse(response) # 通过 Session 对象 发送请求 response = s.get("http://127.0.0.1/api/mgr/customers", params={ 'action' : 'list_customer', 'pagesize' : 10, 'pagenum' : 1, 'keywords' : '', }) printResponse(response)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
5.2python实现session
import requests # 打印请求消息, 参数为 PreparedRequest 对象 def pretty_print_request(req): if req.body == None: msgBody = '' else: msgBody = req.body print( '{}\n{}\n{}\n\n{}'.format( '\n\n----------- 发送请求 -----------', req.method + ' ' + req.url, '\n'.join('{}: {}'.format(k, v) for k, v in req.headers.items()), msgBody, )) # 打印响应消息 def pretty_print_response(res): print( '{}\nHTTP/1.1 {}\n{}\n\n{}'.format( '\n\n----------- 得到响应 -----------', res.status_code, '\n'.join('{}: {}'.format(k, v) for k, v in res.headers.items()), res.text, )) req = requests.Request( 'post', 'http://www.baidu.com', headers={ 'head1':'value1', 'head2':'value2', }, data={ 'item1':'body-value1', 'item2':'body-value2', }) prepared = req.prepare() pretty_print_request(prepared) session = requests.Session() r = session.send(prepared) pretty_print_response(r)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44

-
相关阅读:
figma都有哪些小技巧,分享3个给你
设计师的好帮手!在线PS网页版工具让创意无限发挥!
canal1.1.5不能同步update(修改)类型的数据到ES中
最完整的Windows系统安装教程(Win7、Win10、Win11)
外汇天眼:亏亏亏,为什么亏损的总是我?大数据分析报告告诉你答案
在Windows的Docker上部署Mysql服务
前端自动化测试入门教程
Java开发学习(八)----IOC/DI配置管理第三方bean、加载properties文件
MySQL 社区开源备份工具 Xtrabackup 详解
删除链表的倒数第 N 个结点
- 原文地址:https://blog.csdn.net/m0_46204224/article/details/119883168


