-
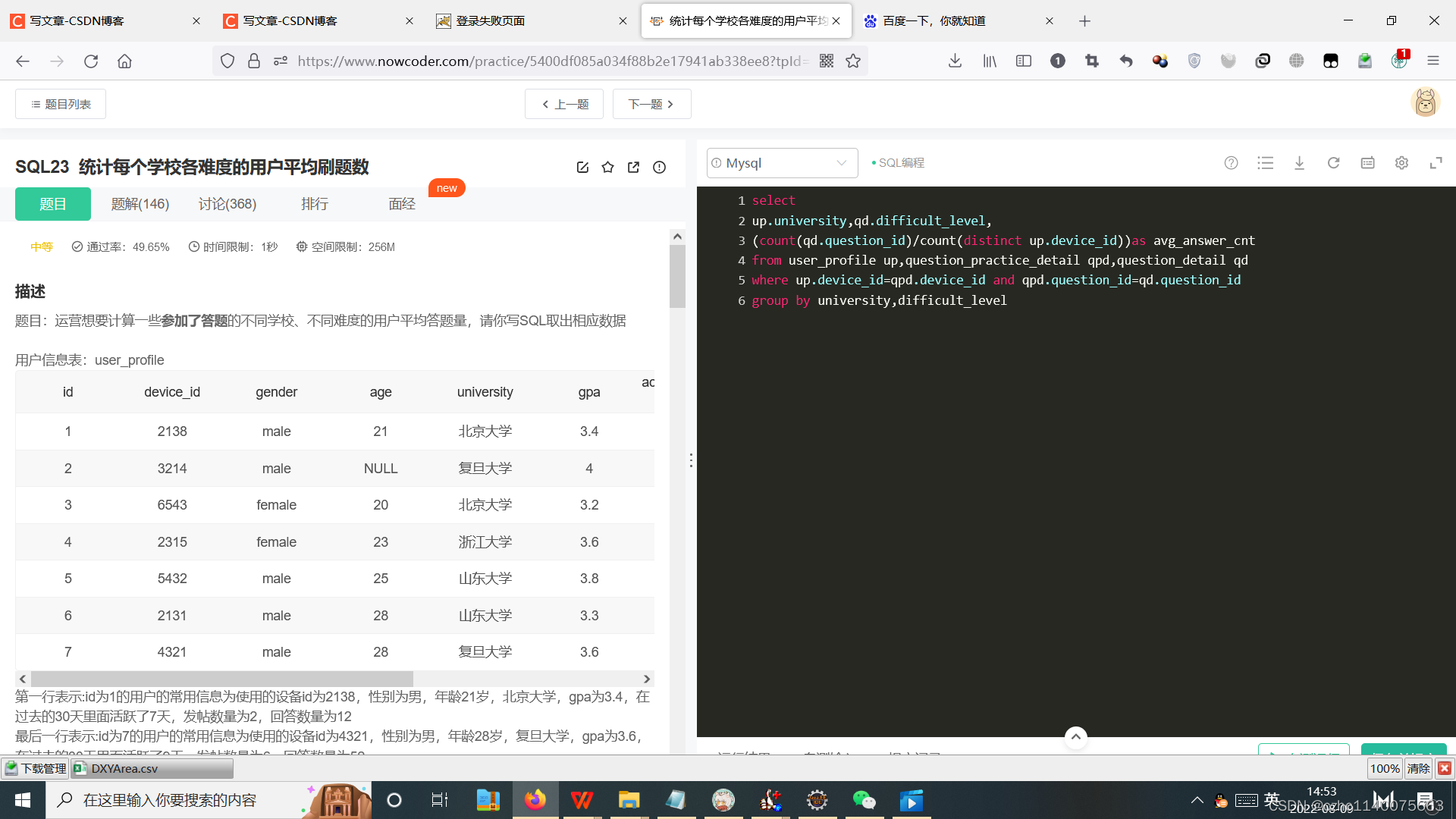
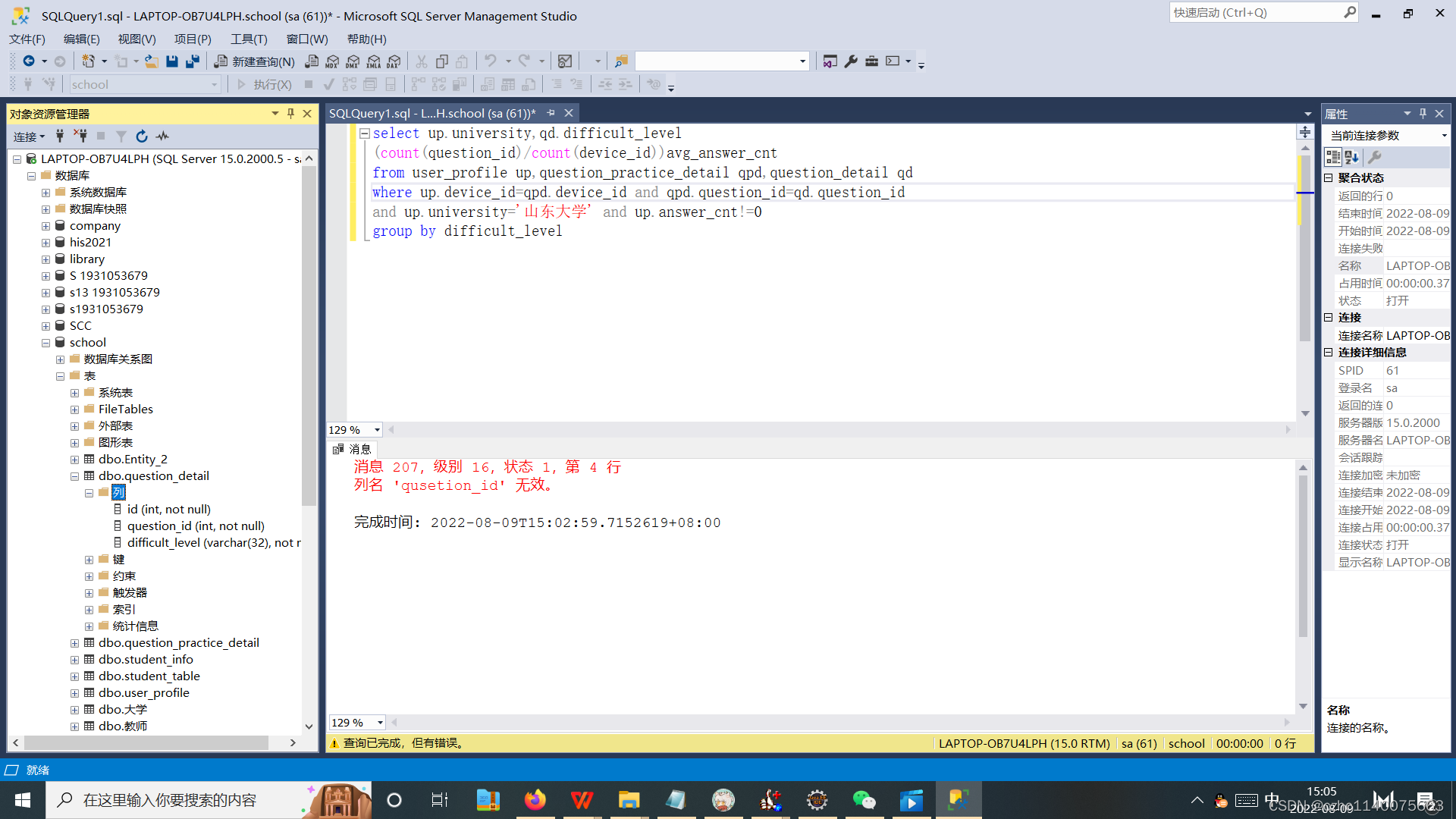
sql 5














 牛客645009817号
牛客645009817号
发表于 2021-10-30 19:52
1
2
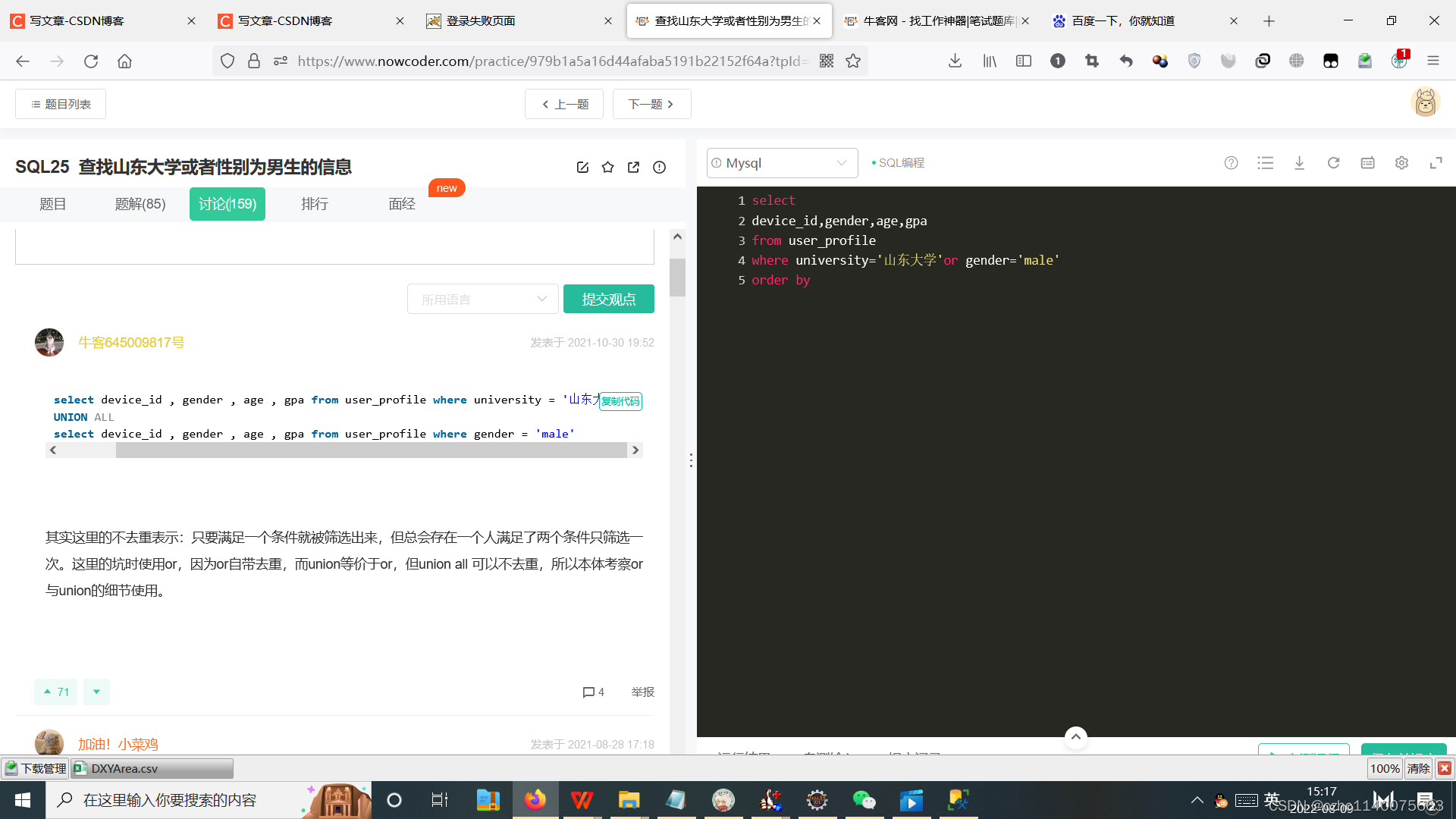
3select device_id , gender , age , gpa from user_profile where university = ‘山东大学’
UNION ALL
select device_id , gender , age , gpa from user_profile where gender = ‘male’其实这里的不去重表示:只要满足一个条件就被筛选出来,但总会存在一个人满足了两个条件只筛选一次。这里的坑时使用or,因为or自带去重,而union等价于or,但union all 可以不去重,所以本体考察or与union的细节使用。
 解析
解析所有选项都是在多表上建立视图,AD选项在视图中重命名了选取列的列名,但是D选项的列名与选取列内容不一致,后续对于视图的操作很容易引起歧义,且指定列名和AS颠倒了位置,错误;B选项增加了将视图存入临时表的操作,然后用临时表来执行语句;C选项未重命名,但是并不影响。
菜鸟葫芦娃
A D
A 聚簇索引也称为聚集索引,聚类索引,簇集索引,聚簇索引确定表中数据的物理顺序。聚簇索引类似于电话簿,后者按姓氏排列数据。由于聚簇索引规定数据在表中的物理存储顺序,因此一个表只能包含一个聚簇索引。但该索引可以包含多个列(组合索引),就像电话簿按姓氏和名字进行组织一样。B 如果使用模糊匹配 这等价于全表扫描 此时索引就不起效果了。这里说的是模糊匹配 ,而不是全文索引。何为全文索引?
在大微软的数据库中:
MicroSoft SqlServer 中的全文索引是由一系列存储过程来完成的,这些存储过程按先后顺序罗列如下:
1、启动数据库的全文索引服务存储过程:sp_fulltext_service
2、初始化全文索引存储过程:sp_fulltext_database
3、建立全文索引目录存储过程:sp_fulltext_catalog
4、在全文索引目录中添加删除表标记存储过程:sp_fulltext_table
5、在全文索引目录的表中添加或删除列标记存储过程:sp_fulltext_column
说到底是调用一些列存储过程搞定的而并非模糊查询 。个人这么认为全文索引和普通索引(唯一索引、聚集、非聚集之类)的区别(从百度知道搞来的,讲的还是有道理的,连接:http://zhidao.baidu.com/question/1818128608088158588.html)
两种索引的功能和结构都是不同的
普通索引的结构主要以B+树和哈希索引为主,用于实现对字段中数据的精确查找,比如查找某个字段值等于给定值的记录,A=10这种查询,因此适合数值型字段和短文本字段
全文索引是用于检索字段中是否包含或不包含指定的关键字,有点像搜索引擎的功能,其内部的索引结构采用的是与搜索引擎相同的倒排索引结构,其原理是对字段中的文本进行分词,然后为每一个出现的单词记录一个索引项,这个索引项中保存了所有出现过该单词的记录的信息,也就是说在索引中找到这个单词后,就知道哪些记录的字段中包含这个单词了。因此适合用大文本字段的查找。大字段之所以不适合做普通索引,最主要的原因是普通索引对检索条件只能进行精确匹配,而大字段中的文本内容很多,通常也不会在这种字段上执行精确的文本匹配查询,而更多的是基于关键字的全文检索查询,例如你查一篇文章信息,你会只输入一些关键字,而不是把整篇文章输入查询(如果有整篇文章也就不用查询了)。而全文索引正是适合这种查询需求。
C 哈希索引精确查找是比较给力的。
哈希索引的限制:
a、哈希索引只包含哈希码和行指针,不存储字段值,所以无法用索引中的值来避免去读取行。
b、哈希索引数据并不是按照索引值顺序存储的,所以也就无法用于排序。
c、哈希索引也不支持部分索引列匹配查找,必须利用所有索引列,因为哈希值是通过所有索引列计算的。
d、哈希索引只支持等值比较查询,包括=、in()、<=>(安全比较)比较包含null的时候用。哈希也不支持任何范围查询,比方说where price > 100
e、哈希索引非常快,除非有哈希冲突(不同的索引值会有相同的哈希值),这个时候引擎必须遍历链表中的所有行来匹配。
f、哈希冲突较多的时候,比方列上相同的值比较多的时候,索引维护代价就会比较高。D 是对 字段太多 查询的时候索引会根据索引立面包含的列进行检测和排序,所以建立索引也要视情况而定。
正确答案: A B C E 你的答案: C E (错误)
A B C E 你的答案: C E
R4 简历不是原子项,不满足第一范式所以不能作为关系数据库
有联系才有关系,所以关系模式必须要能够连接
正确答案: A 你的答案: C (错误)
牛客7372827号
数据库领域公认的标准结构是三级模式结构,它包括外模式、概念模式、内模式,有效地组织、管理数据,提高了数据库的逻辑独立性和物理独立性。外模式又称子模式或用户模式,对应于用户级;概念模式又称模式或逻辑模式,对应于概念级,是对数据库中全部数据的逻辑结构和特征的总体描述;内模式又称存储模式,对应于物理级,它是数据库中全体数据的内部表示或底层描述。
发表于 2018-09-01 22:03:07
回复(0)
安替数据库标准结构是三层模式结构:外模式、概念模式、内模式。有效的组织、管理数据,调高了数据库的逻辑独立性和物理独立性。 外模式:又称子模式或用户模式,对应于用户级 概念模式:又称逻辑模式,对应于概念级,是对数据库中全部数据的逻辑结构和特征的总体描述 内模式:又称存储模式,对应于物理级,是数据库中全体数据的内部表示或底层描述- 1
- 2
- 3
- 4
-
相关阅读:
它来了,Nacos 2.1.1 正式发布
Rust : 与C交互动态库和静态库的尝试
ubuntu中如何用docker下载华为opengauss数据库(超简单)
Android自定义View之条件筛选菜单
2022年12月4日 SVD学习笔记
容器云平台初始化(harbor的安装部署)
“如果哪天腾讯遇到了更大的挑战,也许就是新的一天开始了。“
学习Java Web开发的关键技术和概念
Total derivative
【Selenium & Other】一键杀死进程 & 进程清理大师
- 原文地址:https://blog.csdn.net/czhc1140075663/article/details/126247786