-
经典算法——二分查找
世界上有三种人,一种是为了信仰而活着,一种是为了生活坚持的人,一种是为了活着而活着🌟🌟🌟
1. 什么是算法?
任何被明确定义的计算过程都可以称作 算法 ,它将某个值或一组值作为输入,并产生某个值或一组值作为输出。所以 算法可以被称作将输入转为输出的一系列的计算步骤 。
说白了就是步骤明确的解决问题的方法。由于是在计算机中执行,所以通常先用伪代码来表示,清晰的表达出思路和步骤,这样在真正执行的时候,就可以使用不同的语言来实现出相同的效果。
2. 算法的效率
算法效率是指算法 执行的时间,算法执行时间需通过依据该算法编制的程序在计算机上运行时所消耗的时间来度量。在现在的计算机硬件环境中,比较少需要考虑这个问题了,特别是pc机的编程, 内存空间 越来越大,所以被考虑得也越来越少,不过一个好的程序员,都应该对自己的程序有要求,每一个for比别人少一次判断1000个for就能够少掉很多的运行时间。所以能够理解,能够大概的去运用"效率度量"还是有很大意义的。我们一般通过两个方面来衡量一个算法的效率
- 时间复杂度💥
算法的时间复杂度是一个函数,它定性描述一个算法的运行时间。
一个算法的执行所需要的时间,从理论上来说是算不出来的,必须通过上机测试才能得到,但这并不是说我们对于每个算法都要上机测试,我们只需要知道哪个算法所花的时间多,哪个算法所花的时间少就行。
一个算法花费的时间与算法中的语句执行次数成正比,算法中的语句执行次数越多,它花费的时间就越多。一个算法中的语句执行次数成为语句频度或时间频度,记为T(n),n为问题的规模。- 空间复杂度💥
空间复杂度是指执行这个算法所需要的内存空间。
空间复杂度需要考虑在运行过程中为 局部变量分配的存储空间的大小 ,它包括为参数表中形参变量分配的存储空间和为在函数体中定义的局部变量分配的存储空间两个部分。
空间复杂度也就是对一个算法在运行过程中 临时占用存储空间大小 的量度,记做S(n)=O(f(n))。比如直接插入排序的时间复杂度是O(n^2),空间复杂度是O(1) 。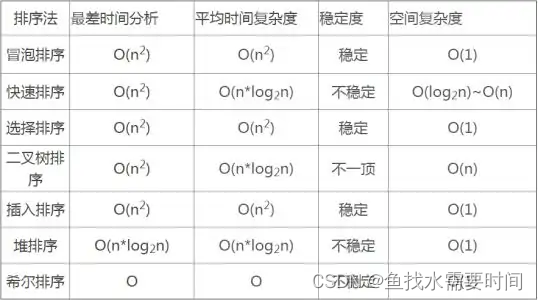
3. 二分查找
查找也被成为检索,主要目的是从某种数据结构中找出符合条件的数据,如果找到满足条件的元素则代表查找成功,否则查找失败。
二分查找也称折半查找,是一种效率相对较高的查找方法。该算法的前提要求是 元素已经有序 ,因为算法的核心思想是尽快的缩小搜索区间,这就需要保证在缩小范围的同时,不能有元素的遗漏。
- 输入
n个数的有序序列,以数组为例,默认升序
待查找元素key- 输出
查找成功,返回元素的位置
查找失败,返回-1或自定义标识符- 说明
算法的核心思想是不断的缩小搜索的范围,每次取区间的中心来进行比较,会有三种情况发生:
- 与key相等:直接返回对应的位置(对于有重复元素的情况,会在其他子专栏中说明)。
- 比key大:由于元素有序,要查找的元素一定在左侧(如有),于是搜索区间变为左一半。
- 比key小:由于元素有序,要查找的元素一定在右侧(如有),于是搜索区间变为右一半。
只要不断地重复取中间比较和指定新的搜索区间这两个步骤,直到区间地两个端点已经重合(代表搜索完毕)或者找到元素时为止。
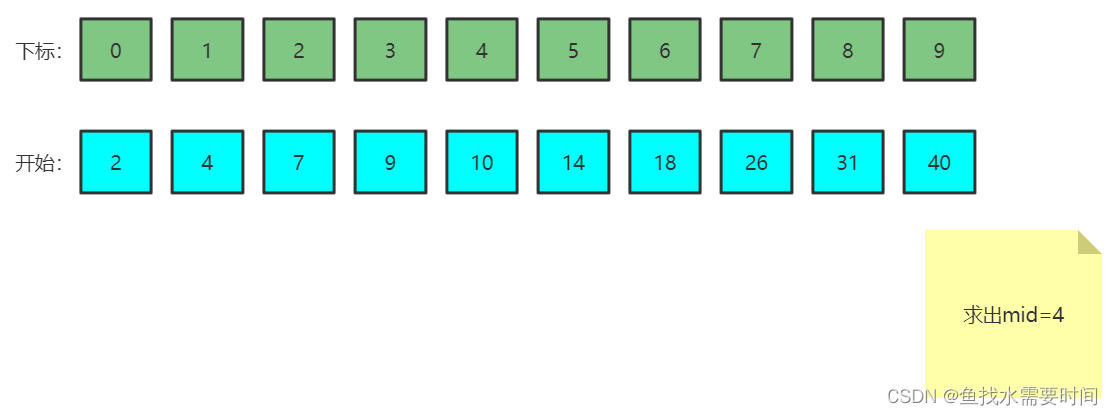
mid就是新的搜索区间中位数下标

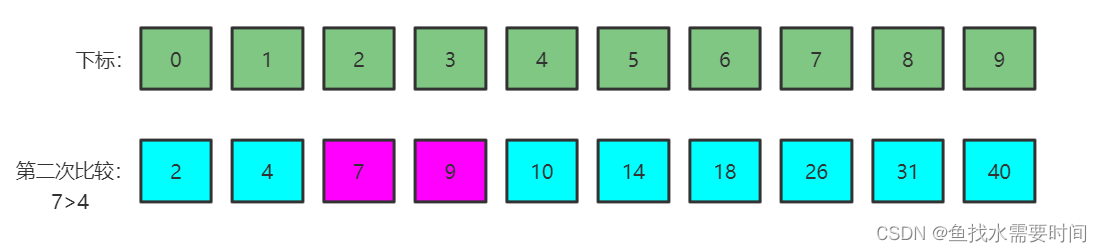

- 第一次比较:mid坐标为4,对应元素为10,大于7,则区间变为左一半:下标[0,3]。
- 第二次比较:mid坐标为1,对应元素为1,小于7,则区间变为右一半:下标[2,3]。
- 第三次比较:mid坐标为2,对应元素为7,等于7,返回逻辑序号:mid + 1 = 3。
3.1 算法实践
public static void main(String[] args) { // input data int[] a = {10, 11, 12, 14, 20, 32, 34, 35, 41, 43}; int key = 12; // 调用算法,并输出结果 int result = search(a, key); System.out.println(result); } private static int search(int[] a, int key) { // 初始化变量 int left = 0; int right = a.length - 1; // 循环终止条件为:左右端点发生交错 while (left <= right) { // 取中间元素,以下写法防止数据量较大时发生溢出 int mid = (right - left) / 2 + left; if (a[mid] == key) { // 情况1:与key相等 return mid + 1; } else if (a[mid] > key) { // 情况2:比key大 right = mid - 1; } else { // 情况3:比key小 left = mid + 1; } } // 循环结束还未触发内部的return则代表未找到,此时返回-1 return -1; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
执行结果为:
33.2 时间复杂度
- 最坏的情况
最坏的情况就是最后一次才找到key,或者查找失败。也就是说只要能计算除最多找多少次,就能直到最快的情况。
寻找的次数肯定是和n相关,由于每次区间都缩小一半,所以就像一张A4纸,对折多少次才能到不能再折为止。所以就是一个以2为底,相对于n的对数O(log2n),也就是循环最多会执行的次数(循环内部的代码都是常量级别)。- 最好的情况
第一次就找到了key,此时的时间复杂度为常熟级:O(1)。
- 平均情况
综合两种情况,二分查找的时间复杂度为O(log2n)。
3.3 空间复杂度
该算法不会改变原有的元素集合,只需要几个额外的变量记录关键信息,所以空间复杂度为常数级:O(1)。
-
相关阅读:
LabVIEW代码生成错误 61056
【Java每日一题】— —第三十一题:银行账号管理程序设计(2023.10.15)
Node.js(2)-模块化管理
DPDK系列之三十内存中的环形队列
Servlet生命周期与线程安全
CSND BUG
【教3妹学算法-每日3题(1)】重新格式化字符串
聊聊C#中的Mixin
UniPro荣获鲲鹏应用创新大赛三等奖 国产信创产品“携手”共赢
如何估算业务需要多少代理IP量?
- 原文地址:https://blog.csdn.net/weixin_43847283/article/details/126256717
