-
【数据结构】万字链表详解
前言
1. 链表的概念及结构
概念:链表是一种物理存储结构上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的 。
换句话说,分散存储是链表最显著的特征,为了能够保持数据元素间的顺序关系,在创建每个元素的同时都要配备一个指针,用于指向它的后继元素。这样由指针相互连接的数据就具有了线性的关联。
链表中的数据有俩个部分组成:一是本身存储的数据信息,二是指向后继元素的指针。这两部分组成数据元素的存储结构称为链表的结点,所有的节点通过指针相互链接就组成了一个链表。链表的特点:
- 可以按需申请和释放
- 不存在扩容的问题
- 插入删除元素的效率高

注意:- 上图可以看出,链式结构在逻辑上是连续的,但是在物理上不一定连续
- 现实中的节点一般都是从堆上申请出来的
- 申请堆上的空间,可能连续也可能不连续
2. 链表的分类
实际中链表的结构非常多样,以下情况组合起来就有以下几种链表结构:
- 单向或双向
- 带头或不带头
- 循环或非循环
- 无头单向非循环链表
- 带头双向循环链表
虽然有这么多的链表的结构,但是实际中最常用还是两种结构:

- 无头单向非循环链表:结构简单,一般不会单独用来存数据。实际中更多是作为其他数据结构的子结构,如哈希桶、图的邻接表等等。
- 带头双向循环链表:结构最复杂,一般用在单独存储数据。实际中使用的链表数据结构,都是带头双向循环链表。另外这个结构虽然结构复杂,但是使用代码实现以后会发现结构会带来很多优势,实现反而简单了。
3. 单链表的实现
无头+单向+非循环链表增删查改实现:
//测试文件 #define _CRT_SECURE_NO_WARNINGS #include "SList.h" void test2() { SLTNode* pList = NULL; //注意修改pList的指向要传它的地址 LinkListPushFront(&pList, 1); PrintLinkList(pList); LinkListPushBack(&pList, 7); pos = SearchLinkList(pList, 5); if (pos) { InsertLinkList(&pList, pos, 33); } PrintLinkList(pList); DestroyLinkList(&pList); } int main() { /*test(); test1();*/ test2(); return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
//逻辑实现 #include "SList.h" //创建新结点 //头插尾插都需要新结点 SLTNode* BuyNewNode(SLTypeData elem) { SLTNode* newNode = (SLTNode*)malloc(sizeof(SLTNode)); if (newNode == NULL) { perror("malloc::"); exit(-1); } //创建后把它的成员初始化 //最后返回newNode的地址 newNode->val = elem; newNode->next = NULL; return newNode; } //打印链表 //这里不用进行断言 //当链表没有元素时为空是正常情况 void PrintLinkList(SLTNode* phead) { SLTNode* tmp = phead; while (tmp) { printf("%d -> ", tmp->val); //打印完后把tmp指向的下一个元素地址赋值给tmp tmp = tmp->next; } puts("NULL"); } //头插 void LinkListPushFront(SLTNode** pphead, SLTypeData elem) { assert(pphead); SLTNode* newNode = BuyNewNode(elem); //把创建好的新节点的指针赋值为当前的头指针 //这时newNode->next就指向了头结点 newNode->next = *pphead; //然后把新节点的地址赋值给头指针 //newNode就成了新的头指针指向第一个结点 *pphead = newNode; } //尾插 void LinkListPushBack(SLTNode** pphead, SLTypeData elem) { assert(pphead); SLTNode* newNode = BuyNewNode(elem); //两种情况: //1. 链表为空 if (*pphead == NULL) { //直接调用头插 //LinkListPushFront(pphead, elem); //或者直接赋值 *pphead = newNode; } else { //2. 链表不为空 //找到最后一个结点 SLTNode* tail = *pphead; while (tail->next) { tail = tail->next; } //让最后一个结点的next指向newNode tail->next = newNode; //这里改变了指向为什么不用二级指针 //这要分情况讨论 //第一种情况如果链表为空 //要修改的是pList,这是一个结构体指针 //修改结构体指针就需要二级指针也就是pList的地址 //第二种情况链表不为空 //要修改的是tail所指向的结构体成员next //修改结构体成员,因此一级结构体指针就够了 } } //尾删 void LinkListPopBack(SLTNode** pphead) { assert(pphead); //暴力的检查,直接报错 //assert(*pphead); //温柔的检查 //判断是否为空,不为空才有的删 if(*pphead == NULL) { puts("无结点可以删除"); return; } //如果只有一个结点直接free //多个结点才有下面的情况 if ((*pphead)->next == NULL) { free(*pphead); *pphead = NULL; } else { SLTNode* tail = *pphead; //第一种写法 //找到倒数第二个结点直接释放 /*while (tail->next->next) { tail = tail->next; } free(tail->next); tail->next = NULL;*/ //第二种写法 //双指针一前一后遍历链表 SLTNode* prev = tail; while (tail->next) { prev = tail; tail = tail->next; } free(prev->next); prev->next = NULL; } } //头删 void LinkListPopFront(SLTNode** pphead) { assert(pphead); //暴力的检查,直接报错 //assert(*pphead); //温柔的检查 //同样判断是否为空 if (*pphead) { SLTNode* tmp = *pphead; //先把头指针存起来 //把头指针赋值为下一个节点的地址 *pphead = (*pphead)->next; //然后释放前一个结点 free(tmp); tmp = NULL; } else { puts("无结点可以删除!"); return; } } //销毁链表 void DestroyLinkList(SLTNode** pphead) { assert(pphead); //快慢指针释放空间 SLTNode* tmp = *pphead; while (tmp) { SLTNode* cur = tmp; tmp = tmp->next; free(cur); } *pphead = NULL; } //查找链表 //该函数还可以充当修改删除和插入的作用 SLTNode* SearchLinkList(SLTNode* phead, SLTypeData targrt) { assert(phead); SLTNode* tmp = phead; while (tmp) { if (tmp->val == targrt) { return tmp; } tmp = tmp->next; } return NULL; } //在pos之前插入结点 void InsertLinkList(SLTNode** pphead, SLTNode* pos, SLTypeData target) { assert(pphead); assert(pos); SLTNode* newNode = BuyNewNode(target); //如果pos等于头节点就相当于头插调用头插即可 if (pos == *pphead) { //头插 //LinkListPushFront(pphead, target); newNode->next = *pphead; *pphead = newNode; } else { //找到pos前一个结点进行插入 SLTNode* prev = *pphead; while (prev->next != pos) { prev = prev->next; } newNode->next = pos; prev->next = newNode; } } //在pos之后插入结点 void InsertAfterLinkList(SLTNode* pos, SLTypeData target) { assert(pos); SLTNode* newNode = BuyNewNode(target); newNode->next = pos->next; pos->next = newNode; } //删除pos位置的结点 void DeleteLinkList(SLTNode** pphead, SLTNode* pos) { assert(pphead); assert(pos); if (pos == *pphead) { LinkListPopFront(pphead); } else { //找到pos的前一个结点直接让prev->next指向pos->next //然后释放pos SLTNode* prev = *pphead; while (prev->next != pos) { prev = prev->next; //检查是否pos传错了 assert(prev); } prev->next = pos->next; free(pos); } } //删除pos位置后面的结点 void DeleteAfterLinkList(SLTNode* pos) { assert(pos); if (pos->next != NULL) { SLTNode* tmp = pos->next; pos->next = pos->next->next; free(tmp); } else { puts("无元素可以删除"); return; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
- 233
- 234
- 235
- 236
- 237
- 238
- 239
- 240
- 241
- 242
- 243
- 244
- 245
- 246
- 247
- 248
- 249
- 250
- 251
- 252
- 253
- 254
- 255
- 256
- 257
- 258
- 259
- 260
- 261
- 262
- 263
- 264
- 265
- 266
- 267
- 268
- 269
- 270
- 271
- 272
- 273
- 274
- 275
- 276
- 277
- 278
- 279
- 280
//头文件包含和函数声明 #pragma once #include#include #include #include typedef int SLTypeData; //结构体成员 //一个数据元素 //一个指向下一个结点的指针 typedef struct SLinkListNode { SLTypeData val; struct SLinkListNode* next; }SLTNode; //创建结点 SLTNode* BuyNewNode(SLTypeData); //打印链表 void PrintLinkList(SLTNode*); //头插 void LinkListPushFront(SLTNode**, SLTypeData); //尾插 void LinkListPushBack(SLTNode**, SLTypeData); //尾删 void LinkListPopBack(SLTNode**); //头删 void LinkListPopFront(SLTNode**); //查找链表 SLTNode* SearchLinkList(SLTNode*, SLTypeData); //在pos之前插入结点 void InsertLinkList(SLTNode**, SLTNode*, SLTypeData); //在pos之后插入结点 void InsertAfterLinkList(SLTNode*, SLTypeData); //删除pos位置的结点 void DeleteLinkList(SLTNode**, SLTNode*); //销毁链表 void DestroyLinkList(SLTNode**); - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
写到这里不难发现,单链表只适合头插和头删,其它操作效率都是比较低的。
4. 两道经典链表面试题
4.1 环形链表2
给定一个链表的头节点 head ,返回链表开始入环的第一个节点。 如果链表无环,则返回 null。
如果链表中有某个节点,可以通过连续跟踪 next 指针再次到达,则链表中存在环。 为了表示给定链表中的环,评测系统内部使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始)。如果 pos 是 -1,则在该链表中没有环。注意:pos 不作为参数进行传递,仅仅是为了标识链表的实际情况。
不允许修改 链表。
示例:

输入:head = [3,2,0,-4], pos = 1
输出:返回索引为 1 的链表节点
解释:链表中有一个环,其尾部连接到第二个节点。来源:力扣(LeetCode)
链接:环形链表有两种解法:
- 公式法
- 转换法,转换成链表相交
先来看第一种方法:
定义两个指针fast 与 slow。它们起始都位于链表的头部。随后,slow 指针每次向后移动一个位置,而fast 指针向后移动两个位置。如果链表中存在环,则fast 指针最终将再次与slow 指针在环中相遇。进环后快指针开始追赶慢指针,由于每次之间的距离会缩小1,因此最终快慢指针会在一处相遇。
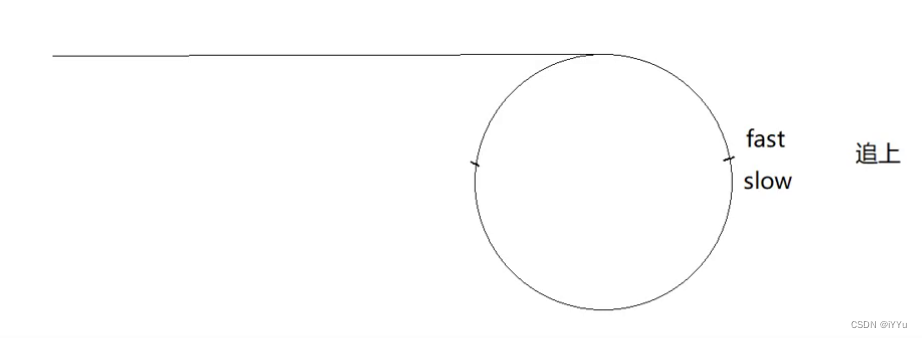
有了上面的概念接下来推导公式:
fast走的距离 = 2*slow走的距离,然后假设一些可能的情况。

根据上面可以得出距离公式为:
2(L+X) = L+X+N*C
进一步化简:
L+X = N*C
L = N*C-X
L = (N-1)*C+C-X
由这个公式可以得出一个结论:一个指针从头开始走,另一个指针从相遇点走,之后会在入口点相遇。
代码实现:struct ListNode *detectCycle(struct ListNode *head) { struct ListNode *slow = head, *fast = head; while (fast && slow && fast->next && slow->next) { slow = slow->next; fast = fast->next->next; if (fast == slow) { struct ListNode* ptr = head; while (ptr != slow) { ptr = ptr->next; slow = slow->next; } return ptr; } } return NULL; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
方法二,转换成链表相交问题:
找到相遇点,然后再找到相遇点的下一个位置,把相遇点置空后,一个指针从头开始,另一个指针从当前位置开始计算出两个链表的长度,然后让长的链表先走差距步,在同时走,当两个链表相交也就遇到了两个地址相同的结点,返回此结点就是要求的解了。struct ListNode *getIntersectionNode(struct ListNode *headA, struct ListNode *headB) { struct ListNode * longA = headA, *shortB = headB; int lenA = 0; int lenB = 0; while(longA->next) { ++lenA; longA = longA->next; } while(shortB->next) { ++lenB; shortB = shortB->next; } longA = headA; shortB = headB; if(lenA < lenB) { longA = headB; shortB = headA; } int gap = abs(lenB - lenA); while(gap--) { longA = longA->next; } while(longA != shortB) { longA = longA->next; shortB = shortB->next; } return longA; } struct ListNode *detectCycle(struct ListNode *head) { struct ListNode *slow = head, *fast = head; while (fast && slow && fast->next && slow->next) { slow = slow->next; fast = fast->next->next; if (fast == slow) { struct ListNode* ptr = fast->next; fast->next = NULL; struct ListNode* ret = getIntersectionNode(ptr, head); fast->next = ptr; return ret; } } return NULL; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
4.2 赋值带随机指针的链表【中等难度】
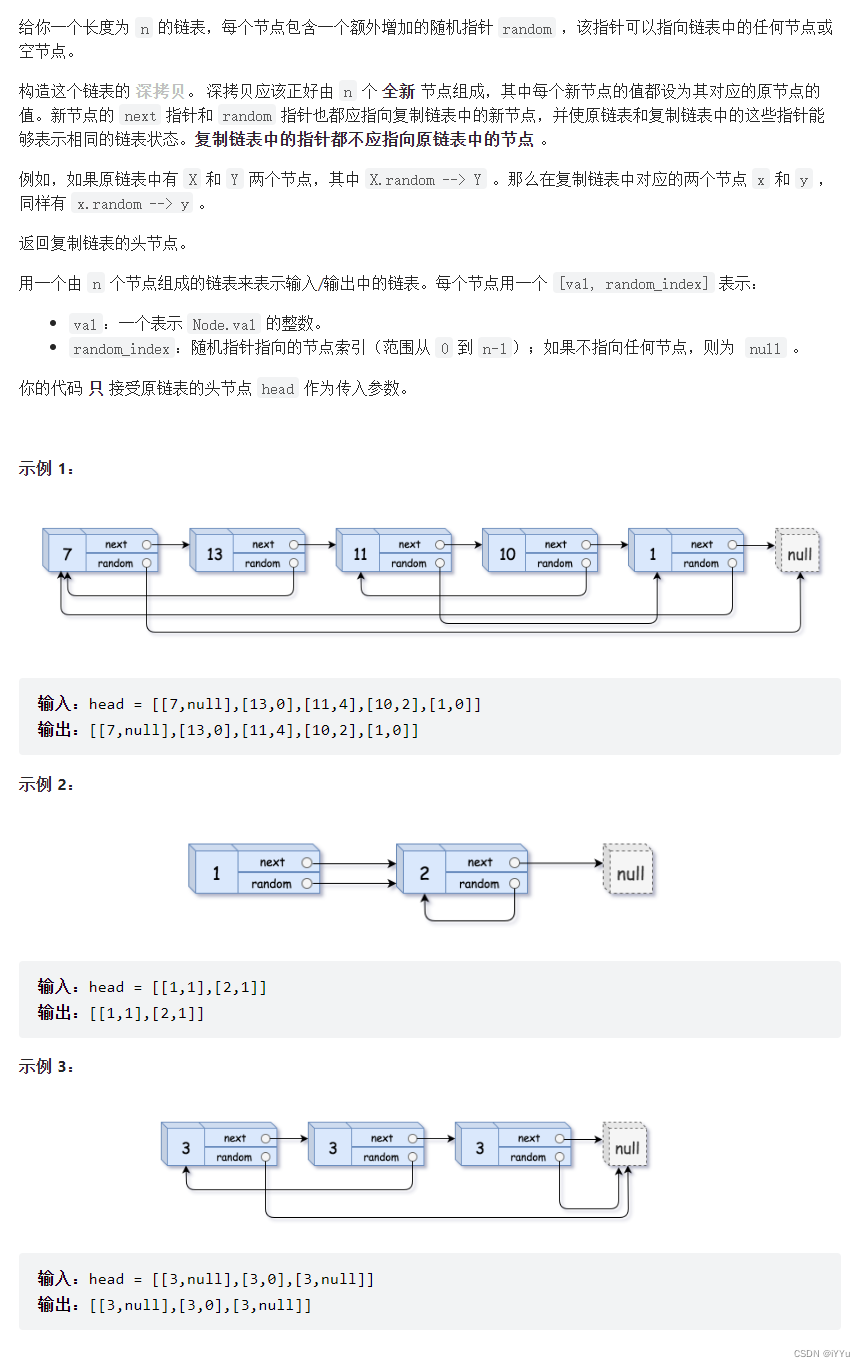
来源:力扣(LeetCode)
链接:赋值带随机指针的链表同样有两种解题思路:
- 暴力法
- 迭代 + 节点拆分
先来分析暴力法:
1.遍历原链表,复制原链表结点尾插到新链表。
2.遍历原链表中的random指针指向的结点,并把新链表中的random也指向新链表对应的结点即可。代码实现:
struct Node* copyRandomList(struct Node* head) { //创建新链表 struct Node* newGuard = (struct Node*)malloc(sizeof(struct Node)); struct Node* tmphead = head, *tmpnewNode = newGuard; while(tmphead) { //复制原链表到新链表 struct Node* newNode = (struct Node*)malloc(sizeof(struct Node)); newNode->val = tmphead->val; newNode->next = tmphead->next; newNode->random = tmphead->random; tmpnewNode->next = newNode; tmpnewNode = tmpnewNode->next; tmphead = tmphead->next; } tmpnewNode->next = NULL; //同时遍历新链表和原链表中random指向的结点 //原链表random指向第i个结点 //对应新链表的random也指向新链表中对应结点 for(struct Node* tmp = newGuard->next, *tmphead = head; tmp; tmp = tmp->next) { for(struct Node* tmptar = newGuard->next, *tmpheadtar = head; tmptar; tmptar = tmptar->next) { if(tmphead->random == tmpheadtar) { tmp->random = tmptar; goto there; } tmpheadtar = tmpheadtar->next; } tmp->random = NULL; there: tmphead = tmphead->next; } return newGuard->next; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
这种方法可以解决此问题,但是暴力法的时间复杂度为O(N2),效率是比较低的。
这道题最大的问题在于要去找对应的copy结点,原链表的random指向对应的结点,但是新链表的random怎么找自己的指向的结点呢?原链表的和新链表的结点地址并没有必然的关系,所以就只能用暴力去找相应的对应关系。
根据上面的信息接下来分析第二种方法的思路:
1.拷贝原结点,并链接在原结点的后面。原结点与拷贝结点建立链接关系,找到原结点就可以找到拷贝结点

2.更新每个拷贝节点的random,因为每个拷贝结点都在原结点的下一个结点,因此如果原链表的random不为空,那么copy->random = head->random->next,找到了head的random指向的结点,它的下一个结点就是copy的random指向的结点,如果为空对应的copy的random也为空。妙!太妙了!遍历原链表的random也就可以更新新链表的random。
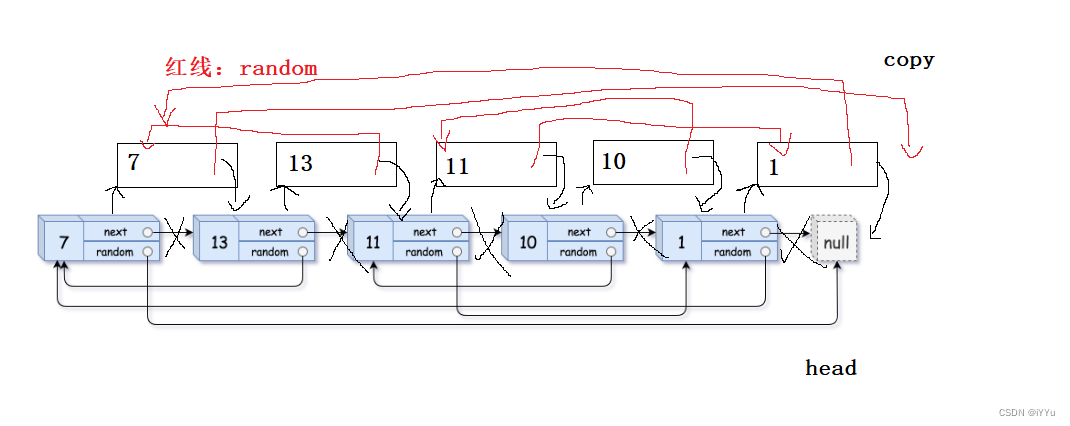
3.copy结点更新结束后,应该取下copy结点,链接为新链表,并把原结点的指向恢复为链接copy结点前相应的指向关系。代码实现:
struct Node* copyRandomList(struct Node* head) { if(!head) return NULL; struct Node* tmphead = head; struct Node* newNode = NULL; while(tmphead) { //链接拷贝结点到原结点的后面 struct Node* tmpheadNext = tmphead->next; newNode = (struct Node*)malloc(sizeof(struct Node)); newNode->val = tmphead->val; tmphead->next = newNode; newNode->next = tmpheadNext; //迭代走 tmphead = tmpheadNext; } //遍历原链表的random更新拷贝结点的random tmphead = head; while(tmphead) { newNode = tmphead->next; if(tmphead->random) { newNode->random = tmphead->random->next; } else { newNode->random = NULL; } tmphead = newNode->next; } //把copy链表截取下来,恢复原链表 tmphead = head; //定义哨兵结点,把copy结点依次拿下来尾插 struct Node* retList = (struct Node*)malloc(sizeof(struct Node)); struct Node* tmpList = retList; while(tmphead) { //尾插 tmpList->next = tmphead->next; tmpList = tmpList->next; //迭代 tmphead = tmpList->next; } return retList->next; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
5. 带头双向循环链表的实现
链表的分类有很多,但是用的最多的就是单链表和带头双向循环链表,而此链表是最为复杂的结构,因此本篇只介绍这两种,对于其它类型的链表,在掌握了带头双向循环链表就很容易理解了。

这里的head结点也称为哨兵结点,它通常不存储有效数据,是可以用来简化边界条件。是一个附加的链表节点,该节点作为第一个节点,只是为了操作的方便而设置。
如果一个链表有哨兵节点,那么该链表的第一个元素应该是链表的第二个节点。哨兵结点有两个指针,一个指针指向尾结点,另一个指针指向它的后继结点。并且之后的结点都配备两个指针,可以指向自己的前一个和后一个结点,而最后一个结点的一个指针可以指针头节点。因此称为带头双向循环链表。
该链表结构虽然复杂,但是实现比较简单,接下来开始实现。
//头文件函数声明 #pragma once #include#include #include #include #include #include typedef int DATAType; typedef struct DoubleListNode { struct DoubleListNode* prev; struct DoubleListNode* next; DATAType data; }DLNode; //初始化 DLNode* InitDList(); //打印链表 void PrintList(DLNode* phead); //销毁链表 void Destroy(DLNode* pHead); //头插 void ListPushFront(DLNode* phead, DATAType data); //头删 void ListPopBack(DLNode* phead); //尾插 void ListPushBack(DLNode* phead, DATAType data); //尾删 void ListPopFront(DLNode* phead); //判空 bool isListEmpty(DLNode* phead); //链表结点个数 size_t ListNum(DLNode* phead); //查找链表 DLNode* FineNode(DLNode* phead, DATAType target); //在目标位置前插入结点 void InsertPosNode(DLNode* pos, DATAType data); //删除目标位置结点 void DeletePosNode(DLNode* pos); - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
#define _CRT_SECURE_NO_WARNINGS 1 #include "dList.h" //函数实现 //初始化 DLNode* InitDList() { DLNode* guard = (DLNode*)malloc(sizeof(DLNode)); if (!guard) { perror("malloc fail"); exit(-1); } guard->next = guard; guard->prev = guard; return guard; } //打印链表 void PrintList(DLNode* phead) { assert(phead); DLNode* tmpHead = phead->next; printf("Guard <-> "); while (tmpHead != phead) { printf("%d <-> ", tmpHead->data); tmpHead = tmpHead->next; } puts("Guard"); } //创建结点 DLNode* BuyNode(DATAType data) { DLNode* newNode = (DLNode*)malloc(sizeof(DLNode)); if (!newNode) { perror("newNode malloc fail"); exit(-1); } newNode->next = NULL; newNode->prev = NULL; newNode->data = data; return newNode; } //尾插 void ListPushBack(DLNode* phead, DATAType data) { assert(phead); DLNode* newNode = BuyNode(data); /*DLNode* tail = phead->prev; tail->next = newNode; newNode->prev = tail; newNode->next = phead; phead->prev = newNode; */ //把头传过去就是尾插 InsertPosNode(phead, data); } //头插 void ListPushFront(DLNode* phead, DATAType data) { assert(phead); DLNode* newNode = BuyNode(data); //先链接phead->next和newNode的关系 /*newNode->next = phead->next; phead->next->prev = newNode; phead->next = newNode; newNode->prev = phead;*/ //不关心顺序 /*DLNode* next = phead->next; phead->next = newNode; newNode->prev = phead; newNode->next = next; next->prev = newNode;*/ //哨兵结点的下一个位置就是头插 InsertPosNode(phead->next, data); } //判空 bool isListEmpty(DLNode* phead) { assert(phead); return phead->next == phead; } //尾删 void ListPopBack(DLNode* phead) { assert(phead); assert(!isListEmpty(phead)); /*DLNode* delTail = phead->prev; DLNode* prev = delTail->prev; prev->next = phead; phead->prev = prev; free(delTail);*/ DeletePosNode(phead->prev); } //头删 void ListPopFront(DLNode* phead) { assert(phead); assert(!isListEmpty(phead)); /*DLNode* delNode = phead->next; phead->next = delNode->next; delNode->next->prev = phead; free(delNode);*/ DeletePosNode(phead->prev); } //链表结点个数 size_t ListNum(DLNode* phead) { assert(phead); size_t sum = 0; DLNode* tmpHead = phead->next; while (tmpHead != phead) { ++sum; tmpHead = tmpHead->next; } return sum; } //查找链表 DLNode* FineNode(DLNode* phead, DATAType target) { assert(phead); DLNode* tmpHead = phead->next; while (tmpHead != phead) { if (tmpHead->data == target) { return tmpHead; } tmpHead = tmpHead->next; } return NULL; } //在目标位置前插入结点 void InsertPosNode(DLNode* pos, DATAType data) { assert(pos); DLNode* newNode = BuyNode(data); DLNode* tmpPosPrev = pos->prev; pos->prev = newNode; newNode->next = pos; tmpPosPrev->next = newNode; newNode->prev = tmpPosPrev; } //有了插入就不需要尾插头插了 //删除目标位置结点 void DeletePosNode(DLNode* pos) { assert(pos); pos->prev->next = pos->next; pos->next->prev = pos->prev; free(pos); pos = NULL; } //销毁链表 void Destroy(DLNode* phead) { assert(phead); DLNode* tmpHead = phead->next; while (tmpHead != phead) { DLNode* next = tmpHead->next; free(tmpHead); tmpHead = next; } free(phead); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
6. 顺序表和链表的区别
顺序表的优点:
- 尾插尾删效率很高
- 支持下标随机访问,这是链表无法比拟的。
- 相比链表,顺序表cpu高速缓存利用率更高
缺点:
- 扩容问题,如果是异地扩容会造成一定的性能消耗
- 扩容会存在一定的空间浪费
链表的优点:
- 任意位置插入和删除效率很高
- 按需申请和释放
缺点:
- 无法随机访问
不同点 顺序表 链表 存储空间上 物理上一定连续 逻辑上连续,物理上不一定 随机访问 支持O(1) 不支持:O(N) 任意位置插入或者删除元素 可能需要挪动数据,效率低O(N) 只需要修改指针的指向 插入 动态顺序表,空间不够时需要扩容 没有容量的概念 应用场景 元素高效存储+频繁访问 频繁任意位置插入或者删除 缓存利用率 高 低 
个人理解:由于顺序表在内存中的地址是连续的,而链表的地址却并不连续,因此当缓存从内存中读取一段连续的字节数据后,cpu会直接访问缓存中加载的数据,因此如果是顺序表,缓存中的一段字节数据都是有效的顺序表数据,执行起来比较高效,但是链表的地址不连续,所以缓存会不断的去内存中加载链表相应的数据,所以相比而言顺序表cpu高速缓存利用率更高。
本篇完
-
相关阅读:
劲松中西医医院谭巍主任在线分析:HPV复阳的三大祸首
猿创征文|我的焚膏继晷之路
C#变量命名规则(命名规范)
c++ 类的特殊成员函数:移动构造函数(五)
【单目3D目标检测】SMOKE + MonoFlex 论文解析与代码复现
机器视觉中的工业光源选择技巧
软考-高项-论文-信息系统项目的质量管理
超好用!在线即可制作电子产品图册
VUE前端工程化-2
论文阅读:GPT-too- A language-model-first approach for AMR-to-text generation Manuel
- 原文地址:https://blog.csdn.net/weixin_66672501/article/details/126076108
