-
java基础巩固6
File对象
(1)在计算机系统中,文件是非常重要的存储方式。Java的标准库java.io提供了File对象来操作文件和目录。构造File对象时,既可以传入绝对路径,也可以传入相对路径。注意Windows平台使用\作为路径分隔符,在java字符串中需要使用\表示一个\。Linux平台使用/作为路径分隔符。
(2)File对象有三种格式表示的路径,一种是getPath(),返回构造方法传入的路径,一种是getAbsolutePath(),返回绝对路径,一种是getCanonicalPath,它和绝对路径相似,但是返回的规范路径。
(3)因为windows和linux的路径分割符不同,File对象有一个静态变量用于表示当前平台的系统分割符:File.separator。文件和目录
(1)File对象既可以表示文件,也可以表示目录。当构建一个File对象时,即使传入的文件或目录不存在,代码也不会出错,因为构造一个File对象,并不会导致任何磁盘操作,只有调用File对象的某些方法的时候,才会进行真正的磁盘操作。
(2)当FIle对象表示一个文件时,可以通过createNewFile()创建一个新文件,用delete()删除该文件。
(3)当File对象表示一个目录时,可以使用list()和listFiles()列出目录下的文件和子目录名。listFiles()提供了一系列重载方法,可以过滤不想要的文件和目录。InputStream
(1)InputStream就是Java标准库提供的最基本的输入流。它位于java.io这个包里。java.io提供了所有同步IO的功能。InputStream并不是一个接口,而是一个抽象类,他是所有输入流的超类。这个抽象类定义的一个最重要的方法就是int read(),签名如下:
public abstract int read() throws IOException
这个方法会读取输入流的下一个字节,并返回字节表示的int值(0~255)。如果已经读到末尾,返回-1表示不能继续读取了。FileInputStream是InputStream的一个子类。
(2)在计算机中,类似文件、网络端口这些资源,都是由操作系统统一管理的。应用程序在运行的过程中,如果打开了一个文件进行读写,完成后要及时地关闭,以便让操作系统把资源释放掉,否则,应用程序占用的资源就会越来越多,不但白白占用内存,还会影响其他应用程序的运行。InputStream和OutputStream都是通过close()方法来关闭流。关闭流就会释放对应的底层资源。我们还需注意到在读取和写入IO流的过程中,可能会发成错误,例如文件不存在导致无法读取,没有写权限导致写入失败等,这些底层错误又Java虚拟机自动封装成IOException异常并且抛出。因此,所有与IO操作相关的代码都必须正确处理IOException。如果读取文件过程中发生了IO错误,InputStream就没法正确地关闭,资源也没法及时释放。因此需要使用try…finally来保证InputStream在无论是否发生IO错误的时候都能正确地关闭。缓冲
(1)在读取流的时候,一次读取一个字节并不是最高效的方法。很多流支持一次性读取多个字节到缓冲区,对于文件和网络流来说,利用缓冲区一次性读取多个字节效率往往要高很多。InputStream提供了两个重载方法来支持读取多个字节:
int read(byte[] b):读取若干字节并填充到byte[]数组,返回读取的字节数
int read(byte[] b, int off, int len):指定byte[]数组的偏移量和最大填充数。
(2)利用上述方法一次读取多个字节时,需要先定义一个byte[]数组作为缓冲区,read()方法会尽可能地多读取字节进入缓冲区,但是不会超过缓冲区的大小。read()方法的返回值不再是字节的int值,而是实际读取了多少个字节。如果返回-1,表示没有更多地数据了。
(3)在调用InputStream的read()方法读取数据时,我们说read()方法是阻塞(Blocking)的。因为读取IO流相比执行普通代码,速度会慢很多,因此无法确定read()方法调用到底要花多长时间。OutputStream
(1)和InputStream相反,OutputStream是Java标准库提供的最基本的输出流,和InputStream相似,OutputStream也提供了close()方法关闭输出流,以便于释放系统资源。要特别注意:OutputStream还提供了一个flush()方法,它的目的是将缓冲区的内容真正地输出到目的地。
(2)为什么要有flush(),因为向磁盘、网络写入数据的时候,出于效率的考虑,操作系统并不是输出一个字节就立刻写入到文件或者发送到网络,而是把输出的字节先存到到内存的一个缓冲区里(本质上就是一个byte[]数组),等到缓冲区写满了,再一次性写入文件或者网络。对于很多IO设备来说,一次写一个字节和一次写1000个字节,花费的时间几乎是完全一样的,所有OutputStream有个flush()方法,能强制把缓冲区内存输出。
(3)通常情况下,我么不需要调用flush()方法,因为缓冲区写满了OutputStream会自动调用它,并且,在调用close()方法关闭OutputStream之前,也会自动调用flush()方法。Filter模式
(1)Java的IO标准库提供的InputStream根据来源可以包括:
FileInputStream:从文件读取数据,是最终数据源
ServletInputStream:从HTTP请求读取数据,是最终数据源
Socket.getInputStream:从TCP连接读取数据,是最终数据源;
(2)直接使用继承,为各种InputStream附加更多的功能,根本无法控制代码的复杂度,很快就会失控。为了解决依赖继承会导致子类数量失控的问题,JDK首先将InputSteam分为两大类:
一类是直接提供数据的基础InputStream,例如:
FileInputStream、ByteArrayInputStream、ServletInputStream
一类是提供额外附加功能的InputStream,例如:
BufferedInputStream
DigestInputStream
CipherInputStream
(3)当我们需要给一个基础InputStream附加各种功能时,我们先确定这个能提供数据源的InputStream,因为我们需要的数据总得来自某个地方,紧接着,我们希望FileInputStream能提供缓冲的功能来提高读取的效率,因为我们用BufferedInputStream包装这个InputStream,得到的包装类型BufferedInputStream,但它仍然被视为一个InputStream。最后,假设该文件应景用gzip压缩了,我们希望直接读取压缩的内容,就可以再包装一个GZIPInputStream:
InputStream gzip = new GZIPInputStream(buffered);
无论我们包装多少次,得到的对象始终是InputStream,我们直接用InputSream来引用它,就可以正常读取。
上述这种通过一个“基础” 组件再叠加各种“附加”功能组件的模式,称之为Fileter模式(或者装饰器模式:Decorator)。
(4)注意到在叠加多个FilteInputStream,我们只需要持有最外层的InputStream,并且当最外层的InputStream关闭时(在try(resoure)块的结束处自动关闭),内层的InputStream的close()方法也会被自动调用,并最终调用到最核心的基础InputStream,因此不会存在资源泄露。序列化
(1)序列化是指把一个Java对象变成二进制内容,本质上就是一个byte[]数组。因为序列化后可以把byte[]保存到文件中,或者吧byte[]通过网络传输到远程,这样,就相当于把Java对象存储到文件或者通过网络传输出去了。
(2)有序列化,就有反序列化,即把一个二进制内容(也就是byte[]数组)变回java对象。有了反序列化,保存到文件中的byte[]又可以变回Java对象,或者从网络上读取byte[]并把它变回Java对象。一个对象要序列化,必须实现一个特殊的java.io.Serializable接口,Serializable接口没有定义任何方法,它只是一个空接口。我们把这样的空接口称为“标记接口”(Marker Interface),实现了标记接口的类仅仅是给自身贴了个标记,并没有增加任何方法。
(3)把一个Java对象变为byte[]数组,需要使用ObjectOutputStream。它负责把一个java对象写入一个字节流。ObjectOutputStream既可以写入基本类型,如int,boolean,也可以写入String(以UTF-8编码),还可以写入实现了Serializable接口的Object。因为写入Object时需要大量的类型信息,所以写入的内容很大。反序列化
(1)和ObjectOutputStream相反,ObjectInputStream负责从一个字节流读取Java对象。除了能读取基本类型和String类型外,调用readOject()可以直接返回一个Object对象。要把它编程一个特定类型,必须强制转型。
(2)readObject()可能抛出的异常有:
ClassNotFoundExceotion:没有找到对应的Class;
InvalidClassException:Class不匹配;
对于ClassNotFoundExceotion,这种情况常见于一台电脑上的JAVA程序把一个Java对象,例如,Person对象序列化后,通过网络传给另一台电脑上的另一个Java程序,但是这台电脑的java程序并没有定义Person类,所以无法反序列化。
对于InvalidClassException,这种情况常见于序列化的Person对象定义了一个int类型的age字段,但是反序列化时,Person类定义的age字段被改成了long类型,所以导致class不兼容。为了避免这种class定义变动导致的不兼容,java徐泪花允许class定义一个特殊的serialVersionUID静态变量,用于标识Java类的序列化“版本”,通常可以由IDE自动生成。如果增加或者修改了字段,可以改变serialVersionUID的值,这样就能自动阻止不匹配的class版本。
(3)反序列化时,由JVM直接构造出Java对象,不调用构造方法,构造方法内部的代码,在反序列化时根本不可能执行。
(4)java的序列化机制仅适用于Java,如果需要与其他语言交换数据,必须使用通用的序列化方法,例如JSON。Reader
(1)Reader是Java的IO库提供的另一个输入流接口,和InputStream的区别是,InputStream是一个字节流,即以byte为单位读取,而Reader是一个字符流,即以char为单位获取:
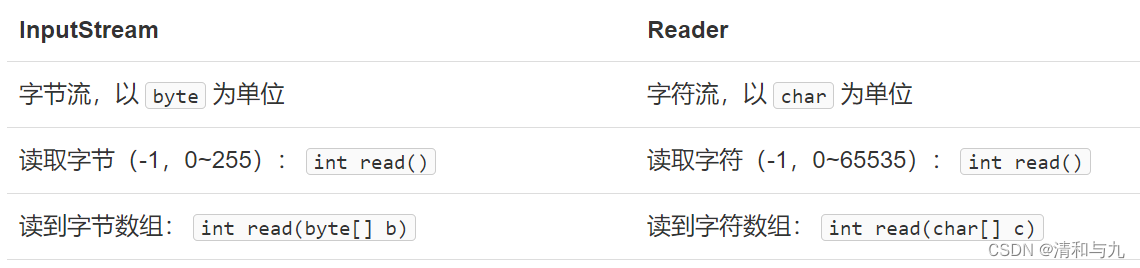
java.io.Reader是所有字符输入流的超类,它最主要的方法是:
public int read() throws IOException;
这个方法读取字符流的下一个字符,并返回字符表示的int,范围是0~65532。如果读到末尾,返回-1。FileReader
(1)FileReader是Reader的一个字类,它可以代开文件并获取Reader。为了避免乱码问题,我们需要在创建FileReader时指定编码:
Reader reader = new FileReader(“src/readme.txt”, StandardCharsets.UTF_8);
和InputStream类似,Reader也是一种资源,需要保证出错的时候也能正确关闭,所以我们同样需要使用try(resource)来保证Reader在无论有没有IO错误的时候都能正确地关闭。
(2)Reader还提供了一次性读取若干字符并填充到char[]数组的方法,它返回实际读入的字符个数,最大不超过char[]数组的长度,返回-1表示流结束。利用这个方法,我们可以先设置一个缓冲区,然后,每次尽可能地填充缓冲区。
(3)除了特殊的CharArrayReader和StringReader,普通的Reader实际上基于InputStream构造的,因为Reader需要从InputStream中读入字节流(byte),然后,根据编码设置,再转换为char就可以实现字符流。如果我们查看FileReader的源码,它在内部实际上持有一个FileInputStream。既然Reader本质上是一个基于InputStream的byte到char的转换器,那么,如果我们已经有一个InputStream,想把它转换为Reader,是完全可行的。InputStreamReader就是这样一个转换器,它可以把任何InputStream转换为Reader。Writer
Reader是带编码转换器的InputStream,它把byte转换为char,而Writer就是带编码转换器的OutputStream,它把char转换为byte并输出。
Writer和OutputStream的区别如下:
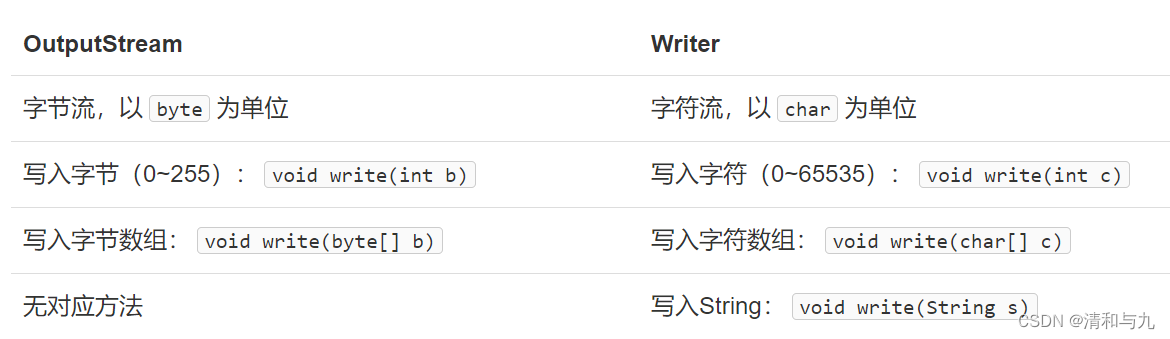
使用Files
FIles提供的读写方法,受内存限制,只能读写小文件,例如配置文件等,不可一次读入几个G的大文件。读写大文件仍然要使用文件流,每次只读写一部门文件内容。
-
相关阅读:
磨金石教育摄影技能干货分享|中国风摄影大师——郎静山
Nginx 平滑升级
图像处理之理想带阻滤波器、巴特沃斯带阻滤波器和高斯带阻滤波器的matlab实现去噪
76. 最小覆盖子串
Spark 3.0 - 9.Ml 朴素贝叶斯中文分类分析与实战
架构师必备:HBase行键设计与应用
web前端面试高频考点——Vue3.x(Composition API的逻辑复用、Proxy实现响应式)
差异化出圈之后,蕉下布局城市户外寻找“起跳”机会
C++模板 —— 万字带你了解C++模板(蓝桥杯算法比赛必备知识STL基础)
SpirngMVC获取请求参数
- 原文地址:https://blog.csdn.net/weixin_49131718/article/details/126228887