-
Java数据结构与算法(二)
Java数据结构与算法(二)
第六章 递归
1 递归应用场景
看个实际应用场景,迷宫问题(回溯), 递归(Recursion)

2 递归的概念
简单的说: 递归就是方法自己调用自己,每次调用时传入不同的变量:递归有助于编程者解决复杂的问题,同时可以让代码变得简洁。
3 递归调用机制
我列举两个小案例,来帮助大家理解递归,部分学员已经学习过递归了,这里在给大家回顾一下递归调用机制
1)打印问题
2)阶乘问题
3) 使用图解方式说明了递归的调用机制
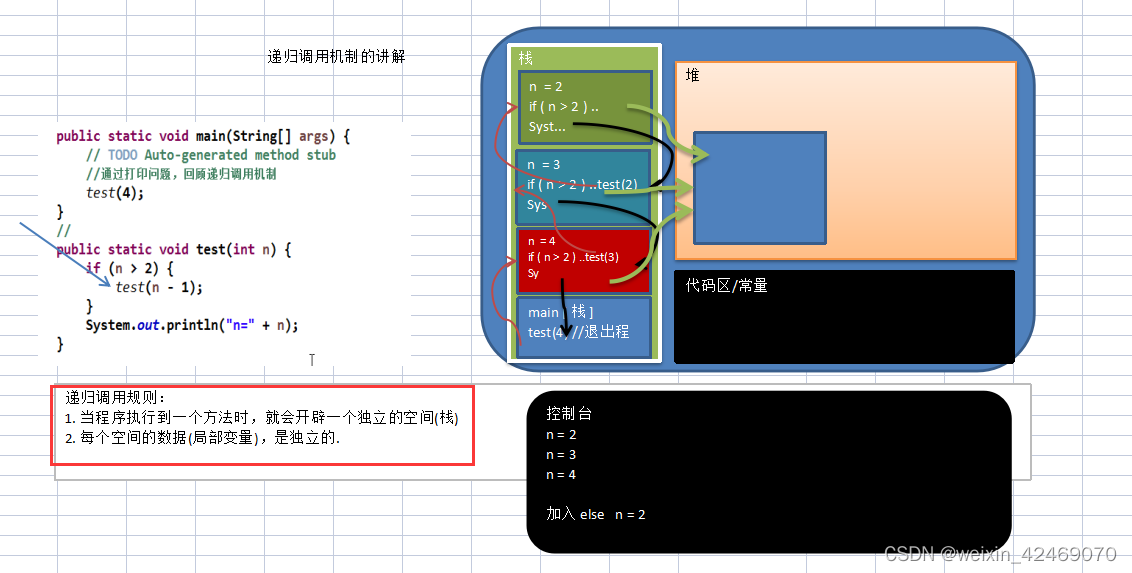
4) 代码演示
public static void main(String[] args) { //通过打印问题,回顾递归调用机制 test(4); //int res = factorial(3); //System.out.println("res=" + res); } //打印问题 public static void test(int n) { if (n > 2) { test(n - 1); } System.out.println("n=" + n); } //输出结果------- n=2 n=3 n=4- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
public static void main(String[] args) { //通过打印问题,回顾递归调用机制 test(4); //int res = factorial(3); //System.out.println("res=" + res); } //打印问题 public static void test(int n) { if (n > 2) { test(n - 1); }else{ System.out.println("n=" + n);//说明 当 n=2 时 n > 2 为false 才进入打印语句 } } //输出结果------- n=2- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
public static void main(String[] args) { int res = factorial(3); System.out.println("res=" + res);//6 } //阶乘问题 public static int factorial(int n) { if (n == 1) { return 1; } else { return factorial(n - 1) * n; // 1 * 2 * 3 } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
4 递归能解决什么样的问题
递归用于解决什么样的问题
1) 各种数学问题如: 8 皇后问题 , 汉诺塔, 阶乘问题, 迷宫问题, 球和篮子的问题(google 编程大赛)
2)各种算法中也会使用到递归,比如快排,归并排序,二分查找,分治算法等.
3)将用栈解决的问题–>第归代码比较简洁
5 递归需要遵守的重要规则
递归需要遵守的重要规则
1) 执行一个方法时,就创建一个新的受保护的独立空间(栈空间)
2) 方法的局部变量是独立的,不会相互影响, 比如 n 变量
3) 如果方法中使用的是引用类型变量(比如数组),就会共享该引用类型的数据.
4) 递归必须向退出递归的条件逼近,否则就是无限递归,出现
StackOverflowError,死龟了:)5) 当一个方法执行完毕,或者遇到
return,就会返回,遵守谁调用,就将结果返回给谁,同时当方法执行完毕或者返回时,该方法也就执行完毕6 递归-迷宫问题
6.1 迷宫问题

6.2 代码实现
public class MiGong { public static void main(String[] args) { // 先创建一个二维数组,模拟迷宫 // 地图 int[][] map = new int[8][7]; // 使用1 表示墙 // 上下全部置为1 for (int i = 0; i < 7; i++) { map[0][i] = 1; map[7][i] = 1; } // 左右全部置为1 for (int i = 0; i < 8; i++) { map[i][0] = 1; map[i][6] = 1; } //设置挡板, 1 表示 map[3][1] = 1; map[3][2] = 1; // map[1][2] = 1; // map[2][2] = 1; // 输出地图 System.out.println("地图的情况"); for (int i = 0; i < 8; i++) { for (int j = 0; j < 7; j++) { System.out.print(map[i][j] + " "); } System.out.println(); } //使用递归回溯给小球找路 //setWay(map, 1, 1); setWay2(map, 1, 1); //输出新的地图, 小球走过,并标识过的递归 System.out.println("小球走过,并标识过的 地图的情况"); for (int i = 0; i < 8; i++) { for (int j = 0; j < 7; j++) { System.out.print(map[i][j] + " "); } System.out.println(); } } //使用递归回溯来给小球找路 //说明 //1. map 表示地图 //2. i,j 表示从地图的哪个位置开始出发 (1,1) //3. 如果小球能到 map[6][5] 位置,则说明通路找到. //4. 约定: 当map[i][j] 为 0 表示该点没有走过 当为 1 表示墙 ; 2 表示通路可以走 ; 3 表示该点已经走过,但是走不通 //5. 在走迷宫时,需要确定一个策略(方法) 下->右->上->左 , 如果该点走不通,再回溯 /** * * @param map 表示地图 * @param i 从哪个位置开始找 * @param j * @return 如果找到通路,就返回true, 否则返回false */ public static boolean setWay(int[][] map, int i, int j) { if (map[6][5] == 2) { // 通路已经找到ok return true; }else { if(map[i][j] == 0) { //如果当前这个点还没有走过 //按照策略 下->右->上->左 走 map[i][j] = 2; // 假定该点是可以走通 if(setWay(map, i+1, j)) {//向下走 return true; }else if (setWay(map, i, j+1)) { //向右走 return true; } else if (setWay(map, i-1, j)) { //向上 return true; }else if (setWay(map, i, j-1)){ // 向左走 return true; }else { //说明该点是走不通,是死路 map[i][j] = 3; return false; } }else { // 如果map[i][j] != 0 , 可能是 1, 2, 3 return false; } } } //修改找路的策略,改成 上->右->下->左 public static boolean setWay2(int[][] map, int i, int j) { if(map[6][5] == 2) { // 通路已经找到ok return true; } else { if(map[i][j] == 0) { //如果当前这个点还没有走过 //按照策略 上->右->下->左 map[i][j] = 2; // 假定该点是可以走通. if(setWay2(map, i-1, j)) {//向上走 return true; } else if (setWay2(map, i, j+1)) { //向右走 return true; } else if (setWay2(map, i+1, j)) { //向下 return true; } else if (setWay2(map, i, j-1)){ // 向左走 return true; } else { //说明该点是走不通,是死路 map[i][j] = 3; return false; } } else { // 如果map[i][j] != 0 , 可能是 1, 2, 3 return false; } } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
6.3 对迷宫问题的讨论
1)小球得到的路径,和程序员设置的找路策略有关即:找路的上下左右的顺序相关
2)再得到小球路径时,可以先使用(下右上左),再改成(上右下左),看看路径是不是有变化
3)测试回溯现象
4)思考: 如何求出最短路径? 思路-》代码实现.
7 递归-八皇后问题(回溯算法)
7.1 八皇后问题介绍
八皇后问题,是一个古老而著名的问题,是回溯算法的典型案例。该问题是国际西洋棋棋手马克斯·贝瑟尔于1848 年提出:在 8×8 格的国际象棋上摆放八个皇后,使其不能互相攻击,即:任意两个皇后都不能处于同一行、同一列或同一斜线上,问有多少种摆法(92)。

7.2 八皇后问题算法思路分析
1) 第一个皇后先放第一行第一列
2)第二个皇后放在第二行第一列、然后判断是否 OK, 如果不 OK,继续放在第二列、第三列、依次把所有列都放完,找到一个合适
3) 继续第三个皇后,还是第一列、第二列…直到第 8 个皇后也能放在一个不冲突的位置,算是找到了一个正确解
4) 当得到一个正确解时,在栈回退到上一个栈时,就会开始回溯,即将第一个皇后,放到第一列的所有正确解,全部得到.
5) 然后回头继续第一个皇后放第二列,后面继续循环执行 1,2,3,4 的步骤
6) 示意图:

说明:
理论上应该创建一个二维数组来表示棋盘,但是实际上可以通过算法,用一个一维数组即可解决问题.arr[8] ={0 , 4, 7, 5, 2, 6, 1, 3}//对应 arr 下标 表示第几行,即第几个皇后,arr[i] = val, val 表示第i+1个皇后,放在第i+1
行的第val+1列7.3 八皇后问题算法代码实现
代码演示
public class Queue8 { public static void main(String[] args) { //测试一把 , 8皇后是否正确 Queue8 queue8 = new Queue8(); queue8.check(0); System.out.printf("一共有%d解法", count); System.out.printf("一共判断冲突的次数%d次", judgeCount); // 1.5w } //定义一个max表示共有多少个皇后 int max = 8; //定义数组array, 保存皇后放置位置的结果,比如 arr = {0 , 4, 7, 5, 2, 6, 1, 3} int[] array = new int[max]; static int count = 0; static int judgeCount = 0; //编写一个方法,放置第n个皇后 //特别注意: check 是 每一次递归时,进入到check中都有 for(int i = 0; i < max; i++),因此会有回溯 private void check(int n) { if(n == max) { //n = 8 , 其实8个皇后就既然放好 print(); return; } //依次放入皇后,并判断是否冲突 for(int i = 0; i < max; i++) { //先把当前这个皇后 n , 放到该行的第1列 array[n] = i; //判断当放置第n个皇后到i列时,是否冲突 if(judge(n)) { // 不冲突 //接着放n+1个皇后,即开始递归 check(n+1); // } //如果冲突,就继续执行 array[n] = i; 即将第n个皇后,放置在本行得 后移的一个位置 } } //查看当我们放置第n个皇后, 就去检测该皇后是否和前面已经摆放的皇后冲突 /** * * @param n 表示第n个皇后 * @return */ private boolean judge(int n) { judgeCount++; for(int i = 0; i < n; i++) { // 说明 //1. array[i] == array[n] 表示判断 第n个皇后是否和前面的n-1个皇后在同一列 //2. Math.abs(n-i) == Math.abs(array[n] - array[i]) 表示判断第n个皇后是否和第i皇后是否在同一斜线 // n = 1 放置第 2列 1 n = 1 array[1] = 1 // Math.abs(1-0) == 1 Math.abs(array[n] - array[i]) = Math.abs(1-0) = 1 //3. 判断是否在同一行, 没有必要,n 每次都在递增 if(array[i] == array[n] || Math.abs(n-i) == Math.abs(array[n] - array[i]) ) { return false; } } return true; } //写一个方法,可以将皇后摆放的位置输出 private void print() { count++; for (int i = 0; i < array.length; i++) { System.out.print(array[i] + " "); } System.out.println(); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
第七章 排序算法
1 排序算法的介绍
排序也称排序算法(Sort Algorithm),排序是将一组数据,依指定的顺序进行排列的过程。
2 排序的分类
1)内部排序:
指将需要处理的所有数据都加载到内部存储器(内存)中进行排序。2) 外部排序法:
数据量过大,无法全部加载到内存中,需要借助外部存储(文件等)进行排序。3)常见的排序算法分类:

3 算法的时间复杂度
3.1 度量一个程序(算法)执行时间的两种方法
1)事后统计的方法
这种方法可行, 但是有两个问题:一是要想对设计的算法的运行性能进行评测,需要实际运行该程序;二是所得时间的统计量依赖于计算机的硬件、软件等环境因素, 这种方式,要在同一台计算机的相同状态下运行,才能比较那个算法速度更快。
2) 事前估算的方法
通过分析某个算法的时间复杂度来判断哪个算法更优。
3.2 时间频度
基本介绍
时间频度:一个算法花费的时间与算法中语句的执行次数成正比例,哪个算法中语句执行次数多,它花费时间就多。一个算法中的语句执行次数称为语句频度或时间频度。记为
T(n)。举例说明-基本案例
比如计算 1-100 所有数字之和, 我们设计两种算法:

举例说明-忽略常数项

结论:
- 2n+20 和 2n 随着 n 变大,执行曲线无限接近, 20 可以忽略
- 3n+10 和 3n 随着 n 变大,执行曲线无限接近, 10 可以忽略
举例说明-忽略低次项

结论:
- 2n^2+3n+10 和 2n^2 随着 n 变大, 执行曲线无限接近, 可以忽略 3n+10
- n^2+5n+20 和 n^2 随着 n 变大,执行曲线无限接近, 可以忽略 5n+20
举例说明-忽略系数

结论:
- 随着 n 值变大,5n^2+7n 和 3n^2 + 2n ,执行曲线重合, 说明 这种情况下, 5 和 3 可以忽略。
- 而 n^3+5n 和 6n^3+4n ,执行曲线分离,说明多少次方式关键
3.3 时间复杂度
1) 一般情况下,算法中的基本操作语句的重复执行次数是问题规模 n 的某个函数,用 T(n)表示,若有某个辅助函数 f(n),使得当 n 趋近于无穷大时,T(n) / f(n) 的极限值为不等于零的常数,则称 f(n)是 T(n)的同数量级函数。记作
T(n)=O( f(n) ),称O( f(n) ) 为算法的渐进时间复杂度,简称时间复杂度。2)T(n) 不同,但时间复杂度可能相同。 如:T(n)=n²+7n+6 与 T(n)=3n²+2n+2 它们的 T(n) 不同,但时间复杂度相同,都为 O(n²)。
3)计算时间复杂度的方法
- 用常数 1 代替运行时间中的所有加法常数
T(n)=n²+7n+6 => T(n)=n²+7n+1 - 修改后的运行次数函数中,只保留最高阶项
T(n)=n²+7n+1 => T(n) = n² - 去除最高阶项的系数
T(n) = n² => T(n) = n² => O(n²)
3.4 常见的时间复杂度
-
常数阶 O(1)
-
对数阶 O(log2n)
-
线性阶 O(n)
-
线性对数阶 O(nlog2n)
-
平方阶 O(n^2)
-
立方阶 O(n^3)
-
k 次方阶 O(n^k)
-
指数阶 O(2^n)
常见的时间复杂度对应的图:

说明:
- 常见的算法时间复杂度由小到大依次为:
Ο(1)<Ο(log2n)<Ο(n)<Ο(nlog2n)<Ο(n^2)<Ο(n^3)< Ο(n^k) <Ο(2^n),随着问题规模 n 的不断增大,上述时间复杂度不断增大,算法的执行效率越低 - 从图中可见,我们应该尽可能避免使用指数阶的算法
1)常数阶 O(1)
无论代码执行了多少行,只要是没有循环等复杂结构,那这个代码的时间复杂度就都是O(1)

上述代码在执行的时候,它消耗的时候并不随着某个变量的增长而增长,那么无论这类代码有多长,即使有几万几十万行,都可以用O(1)来表示它的时间复杂度。2) 对数阶 O(log2n)

说明:在while循环里面,每次都将 i 乘以 2,乘完之后,i 距离 n 就越来越近了。假设循环x次之后,i 就大于 2 了,此时这个循环就退出了,也就是说 2 的 x 次方等于 n,那么 x = log2n也就是说当循环 log2n 次以后,这个代码就结束了。因此这个代码的时间复杂度为:O(log2n) 。 O(log2n) 的这个2 时间上是根据代码变化的,i = i * 3 ,则是 O(log3n) .

3) 线性阶 O(n)

说明:这段代码,for循环里面的代码会执行n遍,因此它消耗的时间是随着n的变化而变化的,因此这类代码都可以用O(n)来表示它的时间复杂度
4) 线性对数阶 O(nlogN)

说明:线性对数阶O(nlogN) 其实非常容易理解,将时间复杂度为O(logn)的代码循环N遍的话,那么它的时间复杂度就是 n * O(logN),也就是了O(nlogN)
5) 平方阶 O(n²)

说明:平方阶O(n²) 就更容易理解了,如果把 O(n) 的代码再嵌套循环一遍,它的时间复杂度就是 O(n²),这段代码其实就是嵌套了2层n循环,它的时间复杂度就是 O(nn),即 O(n²) 如果将其中一层循环的n改成m,那它的时间复杂度就变成了 O(mn)
6) 立方阶 O(n³)、K 次方阶 O(n^k)
说明:参考上面的O(n²) 去理解就好了,O(n³)相当于三层n循环,其它的类似
3.5 平均时间复杂度和最坏时间复杂度
1)平均时间复杂度是指所有可能的输入实例均以等概率出现的情况下,该算法的运行时间。
2) 最坏情况下的时间复杂度称最坏时间复杂度。一般讨论的时间复杂度均是最坏情况下的时间复杂度。这样做的原因是:最坏情况下的时间复杂度是算法在任何输入实例上运行时间的界限,这就保证了算法的运行时间不会比最坏情况更长。
3)平均时间复杂度和最坏时间复杂度是否一致,和算法有关(如图:)。

4 算法的空间复杂度简介
4.1 基本介绍
-
类似于时间复杂度的讨论,一个算法的空间复杂度(Space Complexity)定义为该算法所耗费的存储空间,它也是问题规模 n 的函数。
-
空间复杂度(Space Complexity)是对一个算法在运行过程中临时占用存储空间大小的量度。有的算法需要占用的临时工作单元数与解决问题的规模 n 有关,它随着 n 的增大而增大,当 n 较大时,将占用较多的存储单元,例如快速排序和归并排序算法, 基数排序就属于这种情况
-
在做算法分析时,主要讨论的是时间复杂度。从用户使用体验上看,更看重的程序执行的速度。一些缓存产品(redis, memcache)和算法(基数排序)本质就是用空间换时间.
5 冒泡排
5.1 基本介绍
冒泡排序(Bubble Sorting)的基本思想是:通过对待排序序列从前向后(从下标较小的元素开始),依次比较相邻元素的值,若发现逆序则交换,使值较大的元素逐渐从前移向后部,就象水底下的气泡一样逐渐向上冒。
优化:
因为排序的过程中,各元素不断接近自己的位置,如果一趟比较下来没有进行过交换,就说明序列有序,因此要在排序过程中设置一个标志 flag 判断元素是否进行过交换。从而减少不必要的比较。(这里说的优化,可以在冒泡排序写好后,在进行)5.2 演示冒泡过程的例子(图解)

小结上面的图解过程:
(1) 一共进行 数组的大小-1 次 大的循环
(2)每一趟排序的次数在逐渐的减少
(3) 如果我们发现在某趟排序中,没有发生一次交换, 可以提前结束冒泡排序。这个就是优化5.3 冒泡排序应用实
我们举一个具体的案例来说明冒泡法。我们将五个无序的数:3, 9, -1, 10, -2 使用冒泡排序法将其排成一个从小到大的有序数列。
代码实现:
public class BubbleSort { public static void main(String[] args) { //int arr[] = {3, 9, -1, 10, -2}; //int arr[] = {2, 4, 6, 10, 12}; //System.out.println("排序前:" + Arrays.toString(arr)); /* //为了容量理解,我们把冒泡排序的演变过程,给大家展示 // 第一趟排序,就是将最大的数排在最后 int temp;//临时变量 for (int j = 0; j < arr.length - 1; j++) { // 如果前面的数比后面的数大,则交换 if (arr[j] > arr[j + 1]) { temp = arr[j]; arr[j] = arr[j + 1]; arr[j + 1] = temp; } } System.out.println("第一趟排序后的数组:" + Arrays.toString(arr));//[3, -1, 9, -2, 10] // 第二趟排序,就是将第二大的数排在倒数第二位 for (int j = 0; j < arr.length - 1 - 1 ; j++) { // 如果前面的数比后面的数大,则交换 if (arr[j] > arr[j + 1]) { temp = arr[j]; arr[j] = arr[j + 1]; arr[j + 1] = temp; } } System.out.println("第二趟排序后的数组:" + Arrays.toString(arr));//[-1, 3, -2, 9, 10] // 第三趟排序,就是将第三大的数排在倒数第三位 for (int j = 0; j < arr.length - 1 - 2; j++) { // 如果前面的数比后面的数大,则交换 if (arr[j] > arr[j + 1]) { temp = arr[j]; arr[j] = arr[j + 1]; arr[j + 1] = temp; } } System.out.println("第三趟排序后的数组:" + Arrays.toString(arr));//[-1, -2, 3, 9, 10] // 第四趟排序,就是将第4大的数排在倒数第4位 for (int j = 0; j < arr.length - 1 - 3; j++) { // 如果前面的数比后面的数大,则交换 if (arr[j] > arr[j + 1]) { temp = arr[j]; arr[j] = arr[j + 1]; arr[j + 1] = temp; } } System.out.println("第四趟排序后的数组:" + Arrays.toString(arr));//[-2, -1, 3, 9, 10] */ //测试一下冒泡排序的速度O(n^2), 给80000个数据,测试 //创建要给80000个的随机的数组 int[] arr = new int[80000]; for(int i =0; i < 80000;i++) { arr[i] = (int)(Math.random() * 8000000); //生成一个[0, 8000000) 数 } Date data1 = new Date(); SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"); String date1Str = simpleDateFormat.format(data1); System.out.println("排序前的时间是=" + date1Str); //测试冒泡排序 bubbleSort(arr); Date data2 = new Date(); String date2Str = simpleDateFormat.format(data2); System.out.println("排序后的时间是=" + date2Str); //System.out.println("冒泡排序算法后的数组:" + Arrays.toString(arr)); } // 将前面的冒泡排序算法,封装成一个方法 public static void bubbleSort(int[] arr) { // 冒泡排序 的时间复杂度 O(n^2), 自己写出 int temp = 0; // 临时变量 boolean flag = false; // 标识变量,表示是否进行过交换 for (int i = 0; i < arr.length - 1; i++) { for (int j = 0; j < arr.length - 1 - i; j++) { // 如果前面的数比后面的数大,则交换 if (arr[j] > arr[j + 1]) { flag = true; temp = arr[j]; arr[j] = arr[j + 1]; arr[j + 1] = temp; } } // System.out.println("第" + (i + 1) + "趟排序后的数组"); // System.out.println(Arrays.toString(arr)); if (!flag) { // 在一趟排序中,一次交换都没有发生过 break; } else { flag = false; // 重置flag!!!, 进行下次判断 } } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
6 选择排序
6.1 基本介绍
选择式排序也属于内部排序法,是从欲排序的数据中,按指定的规则选出某一元素,再依规定交换位置后达到排序的目的。
6.2 选择排序思想
选择排序(select sorting)也是一种简单的排序方法。它的基本思想是:第一次从
arr[0]~arr[n-1]中选取最小值,与 arr[0]交换,第二次从arr[1]~arr[n-1]中选取最小值,与 arr[1]交换,第三次从arr[2]~arr[n-1]中选取最小值,与 arr[2]交换,…,第 i 次从arr[i-1]~arr[n-1]中选取最小值,与 arr[i-1]交换,…, 第 n-1 次从arr[n-2]~arr[n-1]中选取最小值,与 arr[n-2]交换,总共通过 n-1 次,得到一个按排序码从小到大排列的有序序列。6.3 选择排序思路分析图

对一个数组的选择排序再进行讲解

6.4 选择排序应用实例
有一群牛 , 颜值分别是 101, 34, 119, 1 请使用选择排序从低到高进行排序 [101, 34, 119, 1]

代码实现
//选择排序 public class SelectSort { public static void main(String[] args) { // int [] arr = {101, 34, 119, 1}; // System.out.println("排序前:" + Arrays.toString(arr)); // selectSort(arr); // System.out.println("排序后:" + Arrays.toString(arr)); //创建要给80000个的随机的数组 int[] arr = new int[80000]; for (int i = 0; i < 80000; i++) { arr[i] = (int) (Math.random() * 8000000); // 生成一个[0, 8000000) 数 } Date data1 = new Date(); SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"); String date1Str = simpleDateFormat.format(data1); System.out.println("排序前的时间是=" + date1Str); selectSort(arr); Date data2 = new Date(); String date2Str = simpleDateFormat.format(data2); System.out.println("排序后的时间是=" + date2Str); } //选择排序 public static void selectSort(int[] arr) { //在推导的过程,我们发现了规律,因此,可以使用for来解决 //选择排序时间复杂度是 O(n^2) for (int i = 0; i < arr.length - 1; i++) { int minIndex = i; int min = arr[i]; for (int j = i + 1; j < arr.length; j++) { if (min > arr[j]) { // 说明假定的最小值,并不是最小 min = arr[j]; // 重置min minIndex = j; // 重置minIndex } } // 将最小值,放在arr[0], 即交换 if (minIndex != i) { arr[minIndex] = arr[i]; arr[i] = min; } //System.out.println("第"+(i+1)+"轮后:" + Arrays.toString(arr));// 1, 34, 119, 101 } /*//使用逐步推导的方式来,讲解选择排序 //第1轮 //原始的数组 : 101, 34, 119, 1 //第一轮排序 : 1, 34, 119, 101 //算法 先简单--》 做复杂, 就是可以把一个复杂的算法,拆分成简单的问题-》逐步解决 //第1轮 int minIndex = 0;//假定最小索引 int min = arr[0];//假定最小值 for(int j = 0 + 1; j < arr.length; j++) { if (min > arr[j]) { //说明假定的最小值,并不是最小 min = arr[j]; //重置min minIndex = j; //重置minIndex } } //将最小值,放在arr[0], 即交换 if(minIndex != 0) { arr[minIndex] = arr[0]; arr[0] = min; } System.out.println("第1轮后的数组:" + Arrays.toString(arr));//1, 34, 119, 101 //第2轮 minIndex = 1; min = arr[1]; for (int j = 1 + 1; j < arr.length; j++) { if (min > arr[j]) { // 说明假定的最小值,并不是最小 min = arr[j]; // 重置min minIndex = j; // 重置minIndex } } // 将最小值,放在arr[0], 即交换 if(minIndex != 1) { arr[minIndex] = arr[1]; arr[1] = min; } System.out.println("第2轮后:" + Arrays.toString(arr));// 1, 34, 119, 101 //第3轮 minIndex = 2; min = arr[2]; for (int j = 2 + 1; j < arr.length; j++) { if (min > arr[j]) { // 说明假定的最小值,并不是最小 min = arr[j]; // 重置min minIndex = j; // 重置minIndex } } // 将最小值,放在arr[0], 即交换 if (minIndex != 2) { arr[minIndex] = arr[2]; arr[2] = min; } System.out.println("第3轮后:" + Arrays.toString(arr));// 1, 34, 101, 119*/ } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
7 插入排序
7.1 插入排序法介绍
插入式排序属于内部排序法,是对于欲排序的元素以插入的方式找寻该元素的适当位置,以达到排序的目的。
7.2 插入排序法思想
插入排序(Insertion Sorting)的基本思想是:把 n 个待排序的元素看成为一个有序表和一个无序表,开始时有序表中只包含一个元素,无序表中包含有 n-1 个元素,排序过程中每次从无序表中取出第一个元素,把它的排序码依次与有序表元素的排序码进行比较,将它插入到有序表中的适当位置,使之成为新的有序表。
7.3 插入排序思路图

7.4 插入排序法应用实例
有一群小牛, 考试成绩分别是 101, 34, 119, 1 请从小到大排
代码实现
public class InsertSort { public static void main(String[] args) { // int[] arr = {101, 34, 119, 1}; // System.out.println("排序前:" + Arrays.toString(arr)); // insertSort(arr); //System.out.println("排序后:" + Arrays.toString(arr)); //创建要给80000个的随机的数组 int[] arr = new int[80000]; for (int i = 0; i < 80000; i++) { arr[i] = (int) (Math.random() * 8000000); // 生成一个[0, 8000000) 数 } Date data1 = new Date(); SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"); String date1Str = simpleDateFormat.format(data1); System.out.println("排序前的时间是=" + date1Str); insertSort(arr); Date data2 = new Date(); String date2Str = simpleDateFormat.format(data2); System.out.println("排序后的时间是=" + date2Str); } //插入排序 public static void insertSort(int[] arr) { int insertVal = 0; int insertIndex = 0; //使用for循环来把代码简化 for(int i = 1; i < arr.length; i++) { //定义待插入的数 insertVal = arr[i]; insertIndex = i - 1; // 即arr[1]的前面这个数的下标 // 给insertVal 找到插入的位置 // 说明 // 1. insertIndex >= 0 保证在给insertVal 找插入位置,不越界 // 2. insertVal < arr[insertIndex] 待插入的数,还没有找到插入位置 // 3. 就需要将 arr[insertIndex] 后移 while (insertIndex >= 0 && insertVal < arr[insertIndex]) { arr[insertIndex + 1] = arr[insertIndex];// arr[insertIndex] insertIndex--; } // 当退出while循环时,说明插入的位置找到, insertIndex + 1 // 举例:理解不了,我们一会 debug //这里我们判断是否需要赋值 if(insertIndex + 1 != i) { arr[insertIndex + 1] = insertVal; } //System.out.println("第"+i+"轮插入:" + Arrays.toString(arr)); } /* //使用逐步推导的方式来讲解,便利理解 //第1轮 {101, 34, 119, 1}; => {34, 101, 119, 1} //{101, 34, 119, 1}; => {101,101,119,1} //定义待插入的数 int insertVal = arr[1]; int insertIndex = 1 - 1; //即arr[1]的前面这个数的下标 //给insertVal 找到插入的位置 //说明 //1. insertIndex >= 0 保证在给insertVal 找插入位置,不越界 //2. insertVal < arr[insertIndex] 待插入的数,还没有找到插入位置 //3. 就需要将 arr[insertIndex] 后移 while(insertIndex >= 0 && insertVal < arr[insertIndex] ) { arr[insertIndex + 1] = arr[insertIndex];// arr[insertIndex] insertIndex--; } //当退出while循环时,说明插入的位置找到, insertIndex + 1 //举例:理解不了,我们一会 debug arr[insertIndex + 1] = insertVal; System.out.println("第1轮插入:" + Arrays.toString(arr)); //第2轮 insertVal = arr[2]; insertIndex = 2 - 1; while(insertIndex >= 0 && insertVal < arr[insertIndex] ) { arr[insertIndex + 1] = arr[insertIndex];// arr[insertIndex] insertIndex--; } arr[insertIndex + 1] = insertVal; System.out.println("第2轮插入:" + Arrays.toString(arr)); //第3轮 insertVal = arr[3]; insertIndex = 3 - 1; while (insertIndex >= 0 && insertVal < arr[insertIndex]) { arr[insertIndex + 1] = arr[insertIndex];// arr[insertIndex] insertIndex--; } arr[insertIndex + 1] = insertVal; System.out.println("第3轮插入:" + Arrays.toString(arr));*/ } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
8 希尔排序
8.1 简单插入排序存在的问题
我们看简单的插入排序可能存在的问题
数组 arr = {2,3,4,5,6,1} 这时需要插入的数 1(最小), 这样的过程是:
{2,3,4,5,6,6} {2,3,4,5,5,6} {2,3,4,4,5,6} {2,3,3,4,5,6} {2,2,3,4,5,6} {1,2,3,4,5,6}- 1
- 2
- 3
- 4
- 5
- 6
结论: 当需要插入的数是较小的数时,后移的次数明显增多,对效率有影响.
8.2 希尔排序法介绍
希尔排序是希尔(Donald Shell)于 1959 年提出的一种排序算法。希尔排序也是一种插入排序,它是简单插入排序经过改进之后的一个更高效的版本,也称为缩小增量排序。
8.3 希尔排序法基本思想
希尔排序是把记录按下标的一定增量分组,对每组使用直接插入排序算法排序;随着增量逐渐减少,每组包含的关键词越来越多,当增量减至 1 时,整个文件恰被分成一组,算法便终止
8.4 希尔排序法的示意图


8.5 希尔排序法应用实例
有一群小牛, 考试成绩分别是 {8,9,1,7,2,3,5,4,6,0} 请从小到大排序. 请分别使用
1)希尔排序时, 对有序序列在插入时采用交换法, 并测试排序速度【慢】.
2)希尔排序时, 对有序序列在插入时采用移动法, 并测试排序速度【快】.
3) 代码实现
public class ShellSort { public static void main(String[] args) { // int[] arr = { 8, 9, 1, 7, 2, 3, 5, 4, 6, 0 }; // System.out.println("排序前=" + Arrays.toString(arr)); // shellSort(arr); // 创建要给80000个的随机的数组 int[] arr = new int[8000000]; for (int i = 0; i < 8000000; i++) { arr[i] = (int) (Math.random() * 8000000); // 生成一个[0, 8000000) 数 } System.out.println("排序前"); Date data1 = new Date(); SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"); String date1Str = simpleDateFormat.format(data1); System.out.println("排序前的时间是=" + date1Str); //shellSort(arr); //交换式 shellSort2(arr);//移位方式 Date data2 = new Date(); String date2Str = simpleDateFormat.format(data2); System.out.println("排序后的时间是=" + date2Str); } // 使用逐步推导的方式来编写希尔排序 // 希尔排序时, 对有序序列在插入时采用交换法, // 思路(算法) ===> 代码 public static void shellSort(int[] arr) { int temp = 0; int count = 0; // 根据前面的逐步分析,使用循环处理 for (int gap = arr.length / 2; gap > 0; gap /= 2) { for (int i = gap; i < arr.length; i++) { // 遍历各组中所有的元素(共gap组,每组有个元素), 步长gap for (int j = i - gap; j >= 0; j -= gap) { // 如果当前元素大于加上步长后的那个元素,说明交换 if (arr[j] > arr[j + gap]) { temp = arr[j]; arr[j] = arr[j + gap]; arr[j + gap] = temp; } } } //System.out.println("希尔排序第" + (++count) + "轮 =" + Arrays.toString(arr)); } /* // 希尔排序的第1轮排序 // 因为第1轮排序,是将10个数据分成了 5组 for (int i = 5; i < arr.length; i++) { // 遍历各组中所有的元素(共5组,每组有2个元素), 步长5 for (int j = i - 5; j >= 0 ; j -= 5) { // 如果当前元素大于加上步长后的那个元素,说明交换 if(arr[j] > arr[j + 5]){ temp = arr[j]; arr[j] = arr[j + 5]; arr[j + 5] = temp; } } } System.out.println("希尔排序1轮后=" + Arrays.toString(arr));//[3, 5, 1, 6, 0, 8, 9, 4, 7, 2] // 希尔排序的第2轮排序 // 因为第2轮排序,是将10个数据分成了 5/2 = 2组 for (int i = 2; i < arr.length; i++) { // 遍历各组中所有的元素(共5组,每组有2个元素), 步长5 for (int j = i - 2; j >= 0 ; j -= 2) { // 如果当前元素大于加上步长后的那个元素,说明交换 if(arr[j] > arr[j + 2]){ temp = arr[j]; arr[j] = arr[j + 2]; arr[j + 2] = temp; } } } System.out.println("希尔排序2轮后=" + Arrays.toString(arr));//[0, 2, 1, 4, 3, 5, 7, 6, 9, 8] // 希尔排序的第3轮排序 // 因为第3轮排序,是将10个数据分成了 2/2 = 1组 for (int i = 1; i < arr.length; i++) { // 遍历各组中所有的元素(共5组,每组有2个元素), 步长5 for (int j = i - 1; j >= 0; j -= 1) { // 如果当前元素大于加上步长后的那个元素,说明交换 if (arr[j] > arr[j + 1]) { temp = arr[j]; arr[j] = arr[j + 1]; arr[j + 1] = temp; } } } System.out.println("希尔排序3轮后=" + Arrays.toString(arr));//[0, 1, 2, 3, 4, 5, 6, 7, 8, 9] */ } //对交换式的希尔排序进行优化->移位法 public static void shellSort2(int[] arr) { // 增量gap, 并逐步的缩小增量 for (int gap = arr.length / 2; gap > 0; gap /= 2) { // 从第gap个元素,逐个对其所在的组进行直接插入排序 for (int i = gap; i < arr.length; i++) { int j = i; int temp = arr[j]; if (arr[j] < arr[j - gap]) { while (j - gap >= 0 && temp < arr[j - gap]) { //移动 arr[j] = arr[j-gap]; j -= gap; } //当退出while后,就给temp找到插入的位置 arr[j] = temp; } } } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
9 快速排序
9.1 快速排序法介绍
快速排序(Quicksort)是对冒泡排序的一种改进。基本思想是:通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列
9.2 快速排序法示意图


9.3 快速排序法应用实例
要求: 对 [-9,78,0,23,-567,70] 进行从小到大的排序,要求使用快速排序法。【测试 8w 和 800w】
说明[验证分析]:
1)如果取消左右递归,结果是 -9 -567 0 23 78 70
2) 如果取消右递归,结果是 -567 -9 0 23 78 70
3)如果取消左递归,结果是 -9 -567 0 23 70 78
4)代码实现
public class QuickSort { public static void main(String[] args) { // int[] arr = {-9,78,0,23,-567,70}; // quickSort(arr, 0, arr.length-1); //测试快排的执行速度 // 创建要给80000个的随机的数组 int[] arr = new int[8000000]; for (int i = 0; i < 8000000; i++) { arr[i] = (int) (Math.random() * 8000000); // 生成一个[0, 8000000) 数 } System.out.println("排序前"); Date data1 = new Date(); SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"); String date1Str = simpleDateFormat.format(data1); System.out.println("排序前的时间是=" + date1Str); quickSort(arr, 0, arr.length-1); Date data2 = new Date(); String date2Str = simpleDateFormat.format(data2); System.out.println("排序后的时间是=" + date2Str); //System.out.println("arr=" + Arrays.toString(arr)); } public static void quickSort(int[] arr,int left, int right) { int l = left; //左下标 int r = right; //右下标 //pivot 中轴值 int pivot = arr[(left + right) / 2]; int temp = 0; //临时变量,作为交换时使用 //while循环的目的是让比pivot 值小放到左边 //比pivot 值大放到右边 while( l < r) { //在pivot的左边一直找,找到大于等于pivot值,才退出 while( arr[l] < pivot) { l += 1; } //在pivot的右边一直找,找到小于等于pivot值,才退出 while(arr[r] > pivot) { r -= 1; } //如果l >= r说明pivot 的左右两的值,已经按照左边全部是 //小于等于pivot值,右边全部是大于等于pivot值 if( l >= r) { break; } //交换 temp = arr[l]; arr[l] = arr[r]; arr[r] = temp; //如果交换完后,发现这个arr[l] == pivot值 相等 r--, 前移 if(arr[l] == pivot) { r -= 1; } //如果交换完后,发现这个arr[r] == pivot值 相等 l++, 后移 if(arr[r] == pivot) { l += 1; } } // 如果 l == r, 必须l++, r--, 否则为出现栈溢出 if (l == r) { l += 1; r -= 1; } //向左递归 if(left < r) { quickSort(arr, left, r); } //向右递归 if(right > l) { quickSort(arr, l, right); } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
10 归并排序
10.1 归并排序介绍
归并排序(MERGE-SORT)是利用归并的思想实现的排序方法,该算法采用经典的分治(divide-and-conquer)策略(分治法将问题分(divide)成一些小的问题然后递归求解,而治(conquer)的阶段则将分的阶段得到的各答案"修
补"在一起,即分而治之)。10.2 归并排序思想示意图 1-基本思想

说明:
可以看到这种结构很像一棵完全二叉树,本文的归并排序我们采用递归去实现(也可采用迭代的方式去实现)。分阶段可以理解为就是递归拆分子序列的过程。10.3 归并排序思想示意图 2-合并相邻有序子序列
再来看看治阶段,我们需要将两个已经有序的子序列合并成一个有序序列,比如上图中的最后一次合并,要将[4,5,7,8]和[1,2,3,6]两个已经有序的子序列,合并为最终序列[1,2,3,4,5,6,7,8],来看下实现步骤

10.4 归并排序的应用实例
给你一个数组, val arr = Array(8, 4, 5, 7, 1, 3, 6, 2 ), 请使用归并排序完成排序。
代码演示:
public class MergetSort { public static void main(String[] args) { // int arr[] = { 8, 4, 5, 7, 1, 3, 6, 2 }; // System.out.println("排序前=" + Arrays.toString(arr)); // int temp[] = new int[arr.length]; //归并排序需要一个额外空间 // mergeSort(arr, 0, arr.length - 1, temp); //测试快排的执行速度 // 创建要给80000个的随机的数组 int[] arr = new int[8000000]; for (int i = 0; i < 8000000; i++) { arr[i] = (int) (Math.random() * 8000000); // 生成一个[0, 8000000) 数 } System.out.println("排序前"); Date data1 = new Date(); SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"); String date1Str = simpleDateFormat.format(data1); System.out.println("排序前的时间是=" + date1Str); int temp[] = new int[arr.length]; //归并排序需要一个额外空间 mergeSort(arr, 0, arr.length - 1, temp); Date data2 = new Date(); String date2Str = simpleDateFormat.format(data2); System.out.println("排序后的时间是=" + date2Str); //System.out.println("归并排序后=" + Arrays.toString(arr)); } //分+合方法 public static void mergeSort(int[] arr, int left, int right, int[] temp) { if(left < right) { int mid = (left + right) / 2; //中间索引 //向左递归进行分解 mergeSort(arr, left, mid, temp); //向右递归进行分解 mergeSort(arr, mid + 1, right, temp); //合并 merge(arr, left, mid, right, temp); } } /** * 合并的方法 * @param arr 排序的原始数组 * @param left 左边有序序列的初始索引 * @param mid 中间索引 * @param right 右边索引 * @param temp 做中转的数组 */ public static void merge(int[] arr, int left, int mid, int right, int[] temp) { int i = left; // 初始化i, 左边有序序列的初始索引 int j = mid + 1; //初始化j, 右边有序序列的初始索引 int t = 0; // 指向temp数组的当前索引 //(一) //先把左右两边(有序)的数据按照规则填充到temp数组 //直到左右两边的有序序列,有一边处理完毕为止 while (i <= mid && j <= right) {//继续 //如果左边的有序序列的当前元素,小于等于右边有序序列的当前元素 //即将左边的当前元素,填充到 temp数组 //然后 t++, i++ if(arr[i] <= arr[j]) { temp[t] = arr[i]; t += 1; i += 1; } else { //反之,将右边有序序列的当前元素,填充到temp数组 temp[t] = arr[j]; t += 1; j += 1; } } //(二) //把有剩余数据的一边的数据依次全部填充到temp while( i <= mid) { //左边的有序序列还有剩余的元素,就全部填充到temp temp[t] = arr[i]; t += 1; i += 1; } while( j <= right) { //右边的有序序列还有剩余的元素,就全部填充到temp temp[t] = arr[j]; t += 1; j += 1; } //(三) //将temp数组的元素拷贝到arr //注意,并不是每次都拷贝所有 t = 0; int tempLeft = left; // //第一次合并 tempLeft = 0 , right = 1 // tempLeft = 2 right = 3 // tL=0 ri=3 //最后一次 tempLeft = 0 right = 7 // System.out.println("tempLeft=" + tempLeft + " right=" + right); while(tempLeft <= right) { arr[tempLeft] = temp[t]; t += 1; tempLeft += 1; } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
11 基数排序
11.1 基数排序(桶排序)介绍
-
基数排序(radix sort)属于“分配式排序”(distribution sort),又称“桶子法”(bucket sort)或 bin sort,顾名思义,它是通过键值的各个位的值,将要排序的元素分配至某些“桶”中,达到排序的作用
-
基数排序法是属于稳定性的排序,基数排序法的是效率高的稳定性排序法
-
基数排序(Radix Sort)是桶排序的扩展
-
基数排序是 1887 年赫尔曼·何乐礼发明的。它是这样实现的:将整数按位数切割成不同的数字,然后按每个位数分别比较。
11.2 基数排序基本思想
-
将所有待比较数值统一为同样的数位长度,数位较短的数前面补零。然后,从最低位开始,依次进行一次排序。这样从最低位排序一直到最高位排序完成以后, 数列就变成一个有序序列。
-
这样说明,比较难理解,下面我们看一个图文解释,理解基数排序的步骤
11.3 基数排序图文说明
将数组 {53, 3, 542, 748, 14, 214} 使用基数排序, 进行升序排序



11.4 基数排序代码实现
要求:将数组 {53, 3, 542, 748, 14, 214} 使用基数排序, 进行升序排序
1) 思路分析:前面的图文已经讲明确
2)代码实现:
public class RadixSort { public static void main(String[] args) { // int arr[] = { 53, 3, 542, 748, 14, 214}; // System.out.println("排序前:" + Arrays.toString(arr)); // radixSort(arr); // 80000000 * 11 * 4 / 1024 / 1024 / 1024 =3.3G int[] arr = new int[8000000]; for (int i = 0; i < 8000000; i++) { arr[i] = (int) (Math.random() * 8000000); // 生成一个[0, 8000000) 数 } System.out.println("排序前"); Date data1 = new Date(); SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"); String date1Str = simpleDateFormat.format(data1); System.out.println("排序前的时间是=" + date1Str); radixSort(arr); Date data2 = new Date(); String date2Str = simpleDateFormat.format(data2); System.out.println("排序后的时间是=" + date2Str); } //基数排序方法 public static void radixSort(int[] arr) { //定义一个二维数组,表示10个桶, 每个桶就是一个一维数组 //说明 //1. 二维数组包含10个一维数组 //2. 为了防止在放入数的时候,数据溢出,则每个一维数组(桶),大小定为arr.length //3. 很明确,基数排序是使用空间换时间的经典算法 int[][] bucket = new int[10][arr.length]; //为了记录每个桶中,实际存放了多少个数据,我们定义一个一维数组来记录各个桶的每次放入的数据个数 //可以这里理解 //比如:bucketElementCounts[0] , 记录的就是 bucket[0] 桶的放入数据个数 int[] bucketElementCounts = new int[10]; //根据下面面的推导过程,我们可以得到最终的基数排序代码 //1. 得到数组中最大的数的位数 int max = arr[0]; //假设第一数就是最大数 for(int i = 1; i < arr.length; i++) { if (arr[i] > max) { max = arr[i]; } } //得到最大数是几位数 int maxLength = (max + "").length(); //这里我们使用循环将代码处理 for(int i = 0 , n = 1; i < maxLength; i++, n *= 10) { //(针对每个元素的对应位进行排序处理), 第一次是个位,第二次是十位,第三次是百位.. for(int j = 0; j < arr.length; j++) { //取出每个元素的对应位的值 int digitOfElement = arr[j] / n % 10; //放入到对应的桶中 bucket[digitOfElement][bucketElementCounts[digitOfElement]] = arr[j]; bucketElementCounts[digitOfElement]++; } //按照这个桶的顺序(一维数组的下标依次取出数据,放入原来数组) int index = 0; //遍历每一桶,并将桶中是数据,放入到原数组 for(int k = 0; k < bucketElementCounts.length; k++) { //如果桶中,有数据,我们才放入到原数组 if(bucketElementCounts[k] != 0) { //循环该桶即第k个桶(即第k个一维数组), 放入 for(int l = 0; l < bucketElementCounts[k]; l++) { //取出元素放入到arr arr[index++] = bucket[k][l]; } } //第i+1轮处理后,需要将每个 bucketElementCounts[k] = 0 !!!! bucketElementCounts[k] = 0; } // System.out.println("第"+(i+1)+"轮,对个位的排序处理 arr =" + Arrays.toString(arr)); } /* //第1轮(针对每个元素的个位进行排序处理) for(int j = 0; j < arr.length; j++) { //取出每个元素的个位的值 int digitOfElement = arr[j] / 1 % 10; //放入到对应的桶中 bucket[digitOfElement][bucketElementCounts[digitOfElement]] = arr[j]; bucketElementCounts[digitOfElement]++; } //按照这个桶的顺序(一维数组的下标依次取出数据,放入原来数组) int index = 0; //遍历每一桶,并将桶中是数据,放入到原数组 for(int k = 0; k < bucketElementCounts.length; k++) { //如果桶中,有数据,我们才放入到原数组 if(bucketElementCounts[k] != 0) { //循环该桶即第k个桶(即第k个一维数组), 放入 for(int l = 0; l < bucketElementCounts[k]; l++) { //取出元素放入到arr arr[index++] = bucket[k][l]; } } //第l轮处理后,需要将每个 bucketElementCounts[k] = 0 !!!! bucketElementCounts[k] = 0; } System.out.println("第1轮,对个位的排序处理 arr =" + Arrays.toString(arr)); //========================================== //第2轮(针对每个元素的十位进行排序处理) for (int j = 0; j < arr.length; j++) { // 取出每个元素的十位的值 int digitOfElement = arr[j] / 10 % 10; //748 / 10 => 74 % 10 => 4 // 放入到对应的桶中 bucket[digitOfElement][bucketElementCounts[digitOfElement]] = arr[j]; bucketElementCounts[digitOfElement]++; } // 按照这个桶的顺序(一维数组的下标依次取出数据,放入原来数组) index = 0; // 遍历每一桶,并将桶中是数据,放入到原数组 for (int k = 0; k < bucketElementCounts.length; k++) { // 如果桶中,有数据,我们才放入到原数组 if (bucketElementCounts[k] != 0) { // 循环该桶即第k个桶(即第k个一维数组), 放入 for (int l = 0; l < bucketElementCounts[k]; l++) { // 取出元素放入到arr arr[index++] = bucket[k][l]; } } //第2轮处理后,需要将每个 bucketElementCounts[k] = 0 !!!! bucketElementCounts[k] = 0; } System.out.println("第2轮,对个位的排序处理 arr =" + Arrays.toString(arr)); //第3轮(针对每个元素的百位进行排序处理) for (int j = 0; j < arr.length; j++) { // 取出每个元素的百位的值 int digitOfElement = arr[j] / 100 % 10; // 748 / 100 => 7 % 10 = 7 // 放入到对应的桶中 bucket[digitOfElement][bucketElementCounts[digitOfElement]] = arr[j]; bucketElementCounts[digitOfElement]++; } // 按照这个桶的顺序(一维数组的下标依次取出数据,放入原来数组) index = 0; // 遍历每一桶,并将桶中是数据,放入到原数组 for (int k = 0; k < bucketElementCounts.length; k++) { // 如果桶中,有数据,我们才放入到原数组 if (bucketElementCounts[k] != 0) { // 循环该桶即第k个桶(即第k个一维数组), 放入 for (int l = 0; l < bucketElementCounts[k]; l++) { // 取出元素放入到arr arr[index++] = bucket[k][l]; } } //第3轮处理后,需要将每个 bucketElementCounts[k] = 0 !!!! bucketElementCounts[k] = 0; } System.out.println("第3轮,对个位的排序处理 arr =" + Arrays.toString(arr));*/ } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
11.5 基数排序的说明
-
基数排序是对传统桶排序的扩展,速度很快.
-
基数排序是经典的空间换时间的方式,占用内存很大, 当对海量数据排序时,容易造成
OutOfMemoryError。 -
基数排序时稳定的。[注:假定在待排序的记录序列中,存在多个具有相同的关键字的记录,若经过排序,这些记录的相对次序保持不变,即在原序列中,r[i]=r[j],且 r[i]在 r[j]之前,而在排序后的序列中,r[i]仍在 r[j]之前,则称这种排序算法是稳定的;否则称为不稳定的]
-
有负数的数组,我们不用基数排序来进行排序
12 常用排序算法总结和对比
12.1 一张排序算法的比较图

12.2 相关术语解释
-
稳定:如果 a 原本在 b 前面,而 a=b,排序之后 a 仍然在 b 的前面;
-
不稳定:如果 a 原本在 b 的前面,而 a=b,排序之后 a 可能会出现在 b 的后面;
-
内排序:所有排序操作都在内存中完成;
-
外排序:由于数据太大,因此把数据放在磁盘中,而排序通过磁盘和内存的数据传输才能进行;
-
时间复杂度: 一个算法执行所耗费的时间。
-
空间复杂度:运行完一个程序所需内存的大小。
-
n: 数据规模
-
k: “桶”的个数
-
In-place: 不占用额外内存
-
Out-place: 占用额外内存
第八章 查找算法
1 查找算法介绍
在 java 中,我们常用的查找有四种:
- 顺序(线性)查找
- 二分查找/折半查找
- 插值查找
- 斐波那契查找
2 线性查找算法
有一个数列: {1,8, 10, 89, 1000, 1234} ,判断数列中是否包含此名称【顺序查找】 要求: 如果找到了,就提示找到,并给出下标值。
代码实现:
public class SeqSearch { public static void main(String[] args) { int arr[] = { 1, 9, 11, -1, 34, 89 };// 没有顺序的数组 int index = seqSearch(arr, 11); if(index == -1) { System.out.println("没有找到到"); } else { System.out.println("找到,下标为=" + index); } } /** * 这里我们实现的线性查找是找到一个满足条件的值,就返回 * @param arr * @param value * @return */ public static int seqSearch(int[] arr, int value) { // 线性查找是逐一比对,发现有相同值,就返回下标 for (int i = 0; i < arr.length; i++) { if(arr[i] == value) { return i; } } return -1; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
3 二分查找算法
3.1 二分查找
请对一个
有序数组进行二分查找 {1,8, 10, 89, 1000, 1234} ,输入一个数看看该数组是否存在此数,并且求出下标,如果没有就提示"没有这个数"。3.2 二分查找算法的思路

3.3 二分查找的代码
说明:增加了找到所有的满足条件的元素下标:
课后思考题: {1,8, 10, 89, 1000, 1000,1234} 当一个有序数组中,有多个相同的数值时,如何将所有的数值都查找到,比如这里的 1000//注意:使用二分查找的前提是 该数组是有序的. public class BinarySearch { public static void main(String[] args) { int arr[] = { 1, 8, 10, 89,1000,1000, 1234 }; // int resIndex = binarySearch(arr, 0, arr.length - 1, 11); // System.out.println("resIndex=" + resIndex); // int arr[] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 , 11, 12, 13,14,15,16,17,18,19,20 }; List<Integer> resIndexList = binarySearch2(arr, 0, arr.length - 1, 1000); System.out.println("resIndexList=" + resIndexList); } /** * 二分查找算法 * * @param arr 数组 * @param left 左边的索引 * @param right 右边的索引 * @param findVal 要查找的值 * @return 如果找到就返回下标,如果没有找到,就返回 -1 */ public static int binarySearch(int[] arr, int left, int right, int findVal) { // 当 left > right 时,说明递归整个数组,但是没有找到 if (left > right) { return -1; } int mid = (left + right) / 2; int midVal = arr[mid]; if (findVal > midVal) { // 向 右递归 return binarySearch(arr, mid + 1, right, findVal); } else if (findVal < midVal) { // 向左递归 return binarySearch(arr, left, mid - 1, findVal); } else { return mid; } } //完成一个课后思考题: /* * 课后思考题: {1,8, 10, 89, 1000, 1000,1234} 当一个有序数组中, * 有多个相同的数值时,如何将所有的数值都查找到,比如这里的 1000 * * 思路分析 * 1. 在找到mid 索引值,不要马上返回 * 2. 向mid 索引值的左边扫描,将所有满足 1000, 的元素的下标,加入到集合ArrayList * 3. 向mid 索引值的右边扫描,将所有满足 1000, 的元素的下标,加入到集合ArrayList * 4. 将Arraylist返回 */ public static List<Integer> binarySearch2(int[] arr, int left, int right, int findVal) { System.out.println("hello~"); // 当 left > right 时,说明递归整个数组,但是没有找到 if (left > right) { return new ArrayList<Integer>(); } int mid = (left + right) / 2; int midVal = arr[mid]; if (findVal > midVal) { // 向 右递归 return binarySearch2(arr, mid + 1, right, findVal); } else if (findVal < midVal) { // 向左递归 return binarySearch2(arr, left, mid - 1, findVal); } else { // * 思路分析 // * 1. 在找到mid 索引值,不要马上返回 // * 2. 向mid 索引值的左边扫描,将所有满足 1000, 的元素的下标,加入到集合ArrayList // * 3. 向mid 索引值的右边扫描,将所有满足 1000, 的元素的下标,加入到集合ArrayList // * 4. 将Arraylist返回 List<Integer> resIndexlist = new ArrayList<Integer>(); //向mid 索引值的左边扫描,将所有满足 1000, 的元素的下标,加入到集合ArrayList int temp = mid - 1; while(true) { if (temp < 0 || arr[temp] != findVal) {//退出 break; } //否则,就temp 放入到 resIndexlist resIndexlist.add(temp); temp -= 1; //temp左移 } resIndexlist.add(mid); // //向mid 索引值的右边扫描,将所有满足 1000, 的元素的下标,加入到集合ArrayList temp = mid + 1; while(true) { if (temp > arr.length - 1 || arr[temp] != findVal) {//退出 break; } //否则,就temp 放入到 resIndexlist resIndexlist.add(temp); temp += 1; //temp右移 } return resIndexlist; } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
4 插值查找算法
插值查找原理介绍:
1)插值查找算法类似于二分查找,不同的是插值查找每次从自适应 mid 处开始查找。
2)将折半查找中的求 mid 索引的公式 , low 表示左边索引 left, high 表示右边索引 right。key 就是前面我们讲的 findVal

3)
int mid = low + (high - low) * (key - arr[low]) / (arr[high] - arr[low]) ;/*插值索引*/
对应前面的代码公式:
int mid = left + (right – left) * (findVal – arr[left]) / (arr[right] – arr[left])4) 举例说明插值查找算法 1-100 的数组

4.1 插值查找应用案例
请对一个有序数组进行插值查找 {1,8, 10, 89, 1000, 1234} ,输入一个数看看该数组是否存在此数,并且求出下标,如果没有就提示"没有这个数"。
代码实现:
public class InsertValueSearch { public static void main(String[] args) { // int [] arr = new int[100]; // for(int i = 0; i < 100; i++) { // arr[i] = i + 1; // } int arr[] = { 1, 8, 10, 89,1000,1000, 1234 }; int index = insertValueSearch(arr, 0, arr.length - 1, 1000); // int index = binarySearch(arr, 0, arr.length, 1); System.out.println("index = " + index); //System.out.println(Arrays.toString(arr)); } public static int binarySearch(int[] arr, int left, int right, int findVal) { System.out.println("二分查找被调用~"); // 当 left > right 时,说明递归整个数组,但是没有找到 if (left > right) { return -1; } int mid = (left + right) / 2; int midVal = arr[mid]; if (findVal > midVal) { // 向 右递归 return binarySearch(arr, mid + 1, right, findVal); } else if (findVal < midVal) { // 向左递归 return binarySearch(arr, left, mid - 1, findVal); } else { return mid; } } /** * 编写插值查找算法 * 说明:插值查找算法,也要求数组是有序的 * @param arr 数组 * @param left 左边索引 * @param right 右边索引 * @param findVal 查找值 * @return 如果找到,就返回对应的下标,如果没有找到,返回-1 */ public static int insertValueSearch(int[] arr, int left, int right, int findVal) { System.out.println("插值查找次数~~"); //注意:findVal < arr[0] 和 findVal > arr[arr.length - 1] 必须需要 //否则我们得到的 mid 可能越界 if (left > right || findVal < arr[0] || findVal > arr[arr.length - 1]) { return -1; } // 求出mid, 自适应 int mid = left + (right - left) * (findVal - arr[left]) / (arr[right] - arr[left]); int midVal = arr[mid]; if (findVal > midVal) { // 说明应该向右边递归 return insertValueSearch(arr, mid + 1, right, findVal); } else if (findVal < midVal) { // 说明向左递归查找 return insertValueSearch(arr, left, mid - 1, findVal); } else { return mid; } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
4.2 插值查找注意事项
- 对于数据量较大,关键字分布比较均匀的查找表来说,采用插值查找, 速度较快.
- 关键字分布不均匀的情况下,该方法不一定比折半查找要好
5 斐波那契(黄金分割法)查找算法
5.1 斐波那契(黄金分割法)查找基本介绍
1)黄金分割点是指把一条线段分割为两部分,使其中一部分与全长之比等于另一部分与这部分之比。取其前三位数字的近似值是
0.618。由于按此比例设计的造型十分美丽,因此称为黄金分割,也称为中外比。这是一个神奇的数字,会带来意向不大的效果。2) 斐波那契数列 {1, 1, 2, 3, 5, 8, 13, 21, 34, 55 } 发现斐波那契数列的两个相邻数 的比例,无限接近 黄金分割值
0.618
5.2 斐波那契(黄金分割法)原理
斐波那契查找原理与前两种相似,仅仅改变了中间结点(mid)的位置,mid 不再是中间或插值得到,而是位于黄金分割点附近,即
mid=low+F(k-1)-1(F 代表斐波那契数列),如下图所示
对 F(k-1)-1 的理解:
1) 由斐波那契数列
F[k]=F[k-1]+F[k-2]的性质,可以得到(F[k]-1)=(F[k-1]-1)+(F[k-2]-1)+1。该式说明:只要顺序表的长度为F[k]-1,则可以将该表分成长度为F[k-1]-1 和 F[k-2]-1的两段,即如上图所示。从而中间位置为mid=low+F(k-1)-12)类似的,每一子段也可以用相同的方式分割
3)但顺序表长度
n不一定刚好等于F[k]-1,所以需要将原来的顺序表长度n增加至F[k]-1。这里的k值只要能使得F[k]-1恰好大于或等于n即可,由以下代码得到,顺序表长度增加后,新增的位置(从n+1到F[k]-1位置),都赋为n位置的值即可。while(n>fib(k)-1) k++;- 1
- 2
5.3 斐波那契查找应用案例
请对一个有序数组进行斐波那契查找 {1,8, 10, 89, 1000, 1234} ,输入一个数看看该数组是否存在此数,并且求出下标,如果没有就提示"没有这个数"。
代码实现:
public class FibonacciSearch { public static int maxSize = 20; public static void main(String[] args) { int [] arr = {1,8, 10, 89, 1000, 1234}; System.out.println("index=" + fibSearch(arr, 1234)); } //因为后面我们mid=low+F(k-1)-1,需要使用到斐波那契数列,因此我们需要先获取到一个斐波那契数列 //非递归方法得到一个斐波那契数列 public static int[] fib() { int[] f = new int[maxSize]; f[0] = 1; f[1] = 1; for (int i = 2; i < maxSize; i++) { f[i] = f[i - 1] + f[i - 2]; } return f; } /** * 编写斐波那契查找算法 * 使用非递归的方式编写算法 * @param a 数组 * @param key 我们需要查找的关键码(值) * @return 返回对应的下标,如果没有-1 */ public static int fibSearch(int[] a, int key) { int low = 0; int high = a.length - 1; int k = 0; //表示斐波那契分割数值的下标 int mid = 0; //存放mid值 int f[] = fib(); //获取到斐波那契数列 //获取到斐波那契分割数值的下标 while(high > f[k] - 1) { k++; } //因为 f[k] 值 可能大于 a 的 长度,因此我们需要使用Arrays类,构造一个新的数组,并指向temp[] //不足的部分会使用0填充 int[] temp = Arrays.copyOf(a, f[k]); //实际上需求使用a数组最后的数填充 temp //举例: //temp = {1,8, 10, 89, 1000, 1234, 0, 0} => {1,8, 10, 89, 1000, 1234, 1234, 1234,} for(int i = high + 1; i < temp.length; i++) { temp[i] = a[high]; } // 使用while来循环处理,找到我们的数 key while (low <= high) { // 只要这个条件满足,就可以找 mid = low + f[k - 1] - 1; if(key < temp[mid]) { //我们应该继续向数组的前面查找(左边) high = mid - 1; //为甚是 k-- //说明 //1. 全部元素 = 前面的元素 + 后边元素 //2. f[k] = f[k-1] + f[k-2] //因为 前面有 f[k-1]个元素,所以可以继续拆分 f[k-1] = f[k-2] + f[k-3] //即 在 f[k-1] 的前面继续查找 k-- //即下次循环 mid = f[k-1-1]-1 k--; } else if ( key > temp[mid]) { // 我们应该继续向数组的后面查找(右边) low = mid + 1; //为什么是k -=2 //说明 //1. 全部元素 = 前面的元素 + 后边元素 //2. f[k] = f[k-1] + f[k-2] //3. 因为后面我们有f[k-2] 所以可以继续拆分 f[k-1] = f[k-3] + f[k-4] //4. 即在f[k-2] 的前面进行查找 k -=2 //5. 即下次循环 mid = f[k - 1 - 2] - 1 k -= 2; } else { //找到 //需要确定,返回的是哪个下标 if(mid <= high) { return mid; } else { return high; } } } return -1; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
-
相关阅读:
java中的代理模式
【Go编程语言】流程控制
MySQL数据库UDF提权学习
Xshell的下载与安装
CodeToN cf #3 Div.1+2 (A-D)
Linux安装RabbitMQ详细教程
【Call for papers】ICML-2023(CCF-A/人工智能/2023年1月26日截稿)
面经汇总--校招--金山办公
idea常用快捷键
Python,图像处理,骨架线,中轴线
- 原文地址:https://blog.csdn.net/weixin_42469070/article/details/125877187
