-
LeetCode高频题互联网大厂笔试题:手撕k-means聚类算法:python代码实现
LeetCode高频题互联网大厂笔试题:手撕k-means聚类算法:python代码实现
提示:本题是系列LeetCode的150道高频题,你未来遇到的互联网大厂的笔试和面试考题,基本都是从这上面改编而来的题目
互联网大厂们在公司养了一大批ACM竞赛的大佬们,吃完饭就是设计考题,然后去考应聘人员,你要做的就是学基础树结构与算法,然后打通任督二脉,以应对波云诡谲的大厂笔试面试题!
你要是不扎实学习数据结构与算法,好好动手手撕代码,锻炼解题能力,你可能会在笔试面试过程中,连题目都看不懂!比如华为,字节啥的,足够让你读不懂题

题目
星球小镇即将建成,班车师傅需要根据员工居住地点,重新建设班车的停靠点,为此,班车师傅专门收集了又乘坐班车需求的员工们的居住地址位置,并找到了你所在的研发团队,洗完你们能帮忙对这些数据进行分析,为班车停靠点的选择提供一些建议。
为此,你们打算开发一套基于kmeans聚类算法的员工居住地点可视化分析工具,而你需要负责完成核心算法k-means的实现。
一、审题
示例:
输入:二维数组列表arr = [ [1.5, 2.1], [0.8, 2.1], [1.3, 2.1], [110.5, 260.6], [21.7, 32.8], [130.9, 150.8], [32.6, 40.7], [41.5, 24.7] ] k = 3- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
输出:
[1,1,1,0,2,0,2,2]
k-means聚类算法思想和手撕代码
之前我记得大华还是谁?就考过
让你手撕代码写这个k-means算法看来有大佬公司们还是希望你有这个实力手撕出来的,k-means聚类代码
其思想:
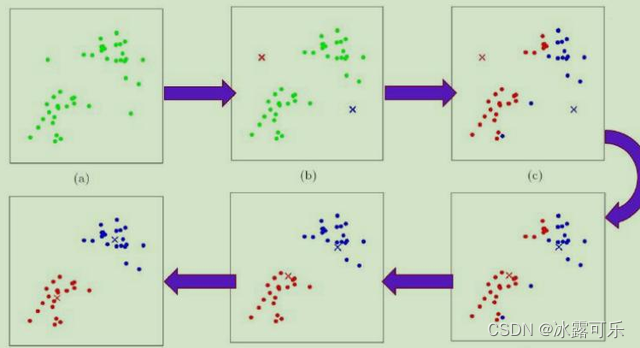
算法实现步骤1、首先确定一个k值,即我们希望将数据集经过聚类得到k个集合。【这个题目给你了,k=3啥的】
2、从数据集中随机选择k个数据点作为质心。【这个其实还不用随机初始化,我们可以就令arr的前k个位置为质心】
3、对数据集arr中每一个点cur,计算其与每一个质心(label从0–k-1个簇)的距离(如欧式距离),离哪个质心label近,cur就划分到哪个质心所属的集合。
4、把所有数据归好集合后,一共有k个集合。然后重新计算每个集合的质心。
5、继续返回1去迭代,T步,经常是需要迭代100步骤。
计算其与每一个质心(label从0–k-1个簇)的距离(如欧式距离)
这再简单不过了,就是求x1,y1点跟x2,y2点的距离
但是也不需要开根号了,反正是正数,何必浪费时间开根号呢???手撕代码:
def getDistance(self, pos1, pos2): # x1,y1,x2,y2二维数组——就是平方距离即可,也不必开根号了 return (pos1[0] - pos2[0])**2 + (pos1[1] - pos2[1])**2- 1
- 2
- 3
重新计算每个集合的质心
给你一个参数:posList,就是一堆点的集合,那么你需要求所有点的平均中心
x和y各自去平均就行,简单def getNewCenter(self, posList): centerX, centerY = 0, 0 for pos in posList: # 取这个中心所有点的距离平均值!!作为最后更新的质心,绝了 centerX += pos[0] centerY += pos[1] return (centerX / len(posList), centerY / len(posList))- 1
- 2
- 3
- 4
- 5
- 6
- 7
k-means聚类算法整体代码:
这思想就很明了,你来算算k-means算法的复杂度度就知道
arr总共有N个点
class_center是k个簇的类中心,初始化的话,取arr前k个就行了
sample_class当做我们每个点最后的聚类结果,放他们的类别cls(0)算法要迭代T=100次
(1)(0)内部每1次迭代,你需要计算N个点中,所有点cur到k簇质心的距离
(2)(1)的内部,你看看cur点到k个质心距离,谁最小,那就把cur归到它这个集合class_cluster中
等k个质心都算过了,那就要不最终归类的结果放到sample_class里面(3)最后拿着这个集合簇class_cluster,更新每个簇的中心
因此实际上复杂度就是**o(T×N×k)**次计算

其实有了这算法复杂度,你就知道大概怎么写代码了
def kmeans(self, positions, k): # 返回一个列表,int表示类别 class_center = positions[:k] # 初始化默认自己就是自己中心 sample_class = [None for i in range(len(positions))] # 聚类结果 iteration = 0 while iteration < 100: # 迭代T次 # 记录k个类别的簇,编号呗 class_cluster = collections.defaultdict(list) # 字典,收集key-value,value就是类别key的归类类别 for i in range(len(positions)): # N个点 cur = positions[i] # 取出这个点xy min_distance = float('inf') # max trulabel = -1 # 目前默认没有类别 for label in range(k): # k个簇 # 计算cur跟所有k个簇质心的距离——把前面k个点,作为标准的聚类中心 center = class_center[label] distance = self.getDistance(cur, center) # 计算cur跟原类别质心的距离 if distance < min_distance: min_distance = distance trulabel = label # 新来的一个距离不错,就将其归类到这里 # 最后一个OK的结果,放for外面哦 class_cluster[trulabel].append(cur) # 每个簇类别记录了cur属于自己——记录的就是一个一个点的xy坐标 sample_class[i] = trulabel # 这一轮迭代的结果——取最小这个簇囊括i这个点 # 更新几个簇的质心 for label in class_cluster: # 每个类别里面都放了哪些下标 new_center = self.getNewCenter(class_cluster[label]) class_center[label] = new_center # 换中心了 iteration += 1 return sample_class # 最后一次的结果,就是最终的聚类结果- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
上面这个代码你细细体会
确实k-means聚类还不错也不是很难,就是很明了的一个算法,简单的思路
上面三个函数封装起来放入class Solution:
测试:
if __name__ == '__main__': arr = [ [1.5, 2.1], [0.8, 2.1], [1.3, 2.1], [110.5, 260.6], [21.7, 32.8], [130.9, 150.8], [32.6, 40.7], [41.5, 24.7] ] k = 3 solution = Solution() ans = solution.kmeans(positions=arr, k=k) for cls in ans: print(cls)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
结果很OK
1 1 1 0 2 0 2 2- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
笔试必然ac
总结
提示:重要经验:1)k-means算法思想简单,思路明了,写代码也好搞,python代码比java代码简单
2)其复杂度为o(TNk)
3)笔试求AC,可以不考虑空间复杂度,但是面试既要考虑时间复杂度最优,也要考虑空间复杂度最优。 -
相关阅读:
rocketMQ是如何利用MQFaultStrategy规避延迟故障的?
SpringBoot 基础知识汇总 (史上最全)
解决异常 java.net.URISyntaxException: Illegal character in query at index
java基于SpringBoot+Vue的大学生体质健康测试管理系统 element
SpringCloud学习笔记-注册微服务到Eureka注册中心
基于长短期神经网络铜期货价格预测,基于LSTM的铜期货价格预测,LSTM的详细原理
无人机生态环境监测、图像处理与 GIS 数据分析
智慧工地抽烟识别检测系统
MySQL 连接报错,致命错误怎么解决呢?
Vim实用技巧
- 原文地址:https://blog.csdn.net/weixin_46838716/article/details/126225022
