-
Python机器学习应用入门 - 不断补充中20220807
前言
提示:这里可以添加本文要记录的大概内容
目录 一、概述
数据 -> 模型 -> 预测
1.1 什么是机器学习
简单的理解,就是通过现阶段已知的数据,对未来的新数据进行一个预测,并且可以通过针对于数据学习内容的增加提高它的准确性的一个过程。
- 智慧城市中的交通拥堵预测
- 股市中的量化交易
- 天气预报
- 欺诈检测、语音识别等
而对于学习能力,它的考量一般依赖于两种形式,
数据量及算法的选择,一定程度的数据量及优选的算法中,它的推算准确度应该是呈现一种正比的趋势。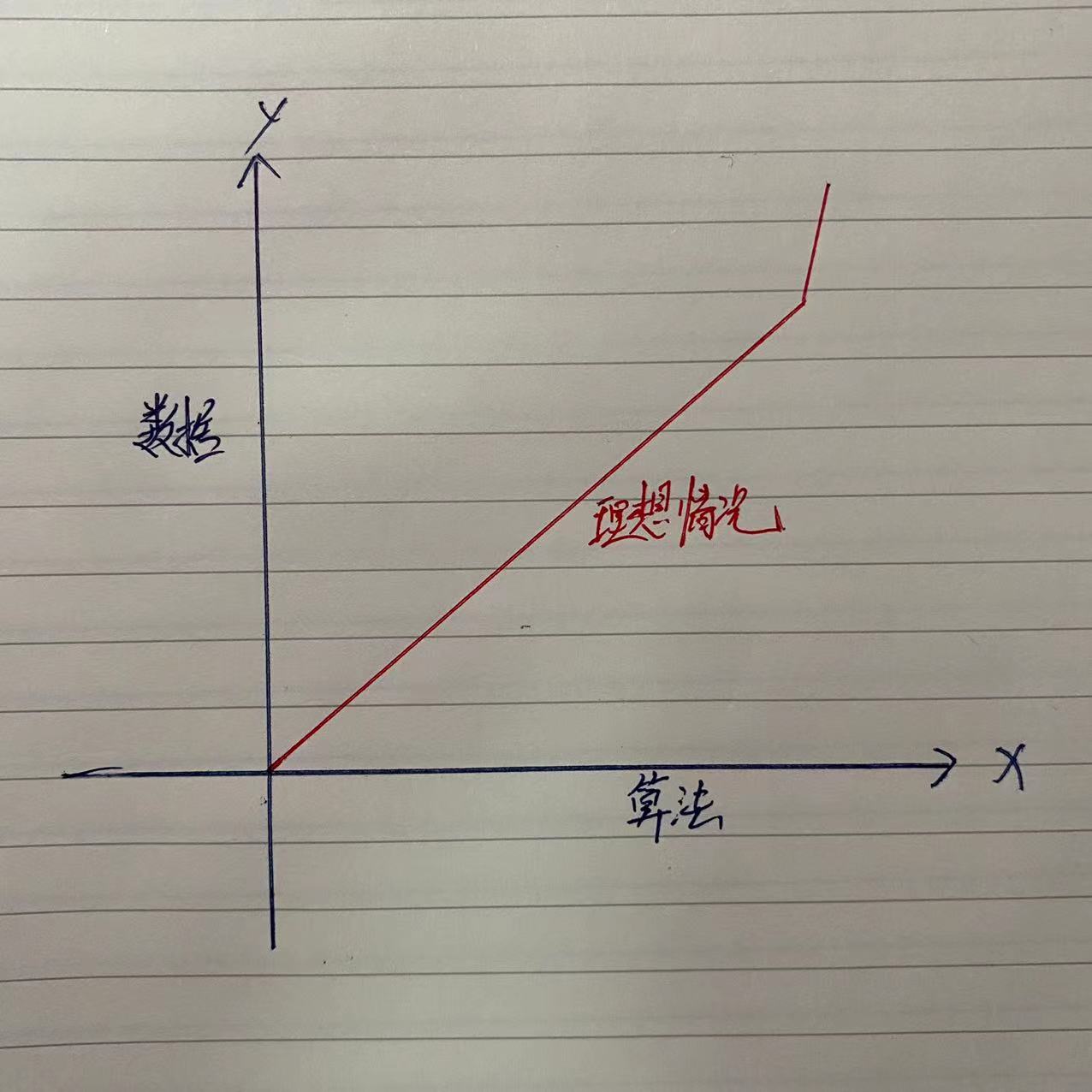
1.2 机器学习的三种方式
在机器学习中,根据学习方式不同,大致归为了如下三类:
-
无监督学习 - Unsupervised Learning
简单描述:对没有事先标记的、无法事先处理的数据进行自动分类/分群,常用的算法有
- 聚类算法
- 数据降维
-
有监督学习 - Supervised Learning
简单描述:对事先处理过的带有标签的数据组进行训练及量化,常见的方式有
- 分类-----类别
- 回归-----连续性数据,如耗电量
-
半监督学习 - Semi-supervised Learning
1.3 机器学习系统构成
大致分为了四个步骤
- 数据预处理 -> 相当于数据的准备;
- 算法学习 -> 根据数据的具体情况选择合适的机器学习方式,根据不同的精度选择合适的算法;
- 模型验证
- 模型预测

二、常用库
提示:这里可以添加本文要记录的大概内容
2.1 Numpy
Numpy,用于矩阵运算、高维数组运算的数学计算库,下面看看简单使用
# 导入库 import numpy as np # demo01:eye(4) 生成对角矩阵 print(np.eye(4))- 1
- 2
- 3
- 4
Ndarray
对于它的介绍
- 一系列同类型的数据的集合
- 多维数组
import numpy as np # 双维度 demo01 = np.array([[1, 2, 3], [4, 5, 6]]) # 最小维度 = 3 demo02 = np.array([[1, 2, 3], [4, 5, 6]], ndmin=3) print(demo01) print("---") print(demo02) # numpy.array(object, dtype = None, copy = True, order = None, subok = False, ndmin = 0)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
参数的说明
名称 描述 object 数组或嵌套的数列 dtype 数组元素的数据类型,可选 copy 对象是否需要复制,可选 order 创建数组的样式,C为行方向,F为列方向,A为任意方向(默认) subok 默认返回一个与基类类型一致的数组 ndmin 指定生成数组的最小维度 关于数组属性
属性 说明 ndarray.ndim 秩,即轴的数量或维度的数量 ndarray.shape 数组的维度,对于矩阵,n 行 m 列 ndarray.size 数组元素的总个数,相当于 .shape 中 n*m 的值 ndarray.dtype ndarray 对象的元素类型 ndarray.itemsize ndarray 对象中每个元素的大小,以字节为单位 ndarray.flags ndarray 对象的内存信息 ndarray.real ndarray元素的实部 ndarray.imag ndarray 元素的虚部 ndarray.data 包含实际数组元素的缓冲区,由于一般通过数组的索引获取元素,所以通常不需要使用这个属性 ndarray.reshape 通常返回的是非拷贝副本,即改变返回后数组的元素,原数组对应元素的值也会改变 数据类型
名称 描述 bool_ 布尔型数据类型(True 或者 False) int_ 默认的整数类型(类似于 C 语言中的 long,int32 或 int64) intc 与 C 的 int 类型一样,一般是 int32 或 int 64 intp 用于索引的整数类型(类似于 C 的 ssize_t,一般情况下仍然是 int32 或 int64) int8 字节(-128 to 127) int16 整数(-32768 to 32767) int32 整数(-2147483648 to 2147483647) int64 整数(-9223372036854775808 to 9223372036854775807) uint8 无符号整数(0 to 255) uint16 无符号整数(0 to 65535) uint32 无符号整数(0 to 4294967295) uint64 无符号整数(0 to 18446744073709551615) float_ float64 类型的简写 float16 半精度浮点数,包括:1 个符号位,5 个指数位,10 个尾数位 float32 单精度浮点数,包括:1 个符号位,8 个指数位,23 个尾数位 float64 双精度浮点数,包括:1 个符号位,11 个指数位,52 个尾数位 complex_ complex128 类型的简写,即 128 位复数 complex64 复数,表示双 32 位浮点数(实数部分和虚数部分) complex128 复数,表示双 64 位浮点数(实数部分和虚数部分) str_ 表示字符串类型 string_ 表示字节串类型 举个例子
import numpy as np # 自定义数据结构 名字 年龄 成绩 student = np.dtype([('name', 'S20'), ('age', 'int64'), ('marks', 'float64')]) print(student) a = np.array([('cool man', 21, 50.1), ('cool girl', 18, 75.1)], dtype=student) print(a)- 1
- 2
- 3
- 4
- 5
- 6
- 7
不想过多写的常用API
import numpy as np # 切片索引 a = np.arange(10) s = slice(2, 7, 2) # 从索引 2 开始到索引 7 停止,间隔为2 print(a[s]) # 静态/动态数组创建 # ... # 深浅复制 # ... # 迭代数组 nditer() a = np.arange(6).reshape(2, 3) print('原始数组是:') print(a) print('\n') print('迭代输出元素:') for x in np.nditer(a): print(x, end=", ") print('\n')- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
高级函数
位运算
函数 描述 bitwise_and对数组元素执行位与操作 bitwise_or对数组元素执行位或操作 invert按位取反 left_shift向左移动二进制表示的位 right_shift向右移动二进制表示的位 字符串函数
函数 描述 add()对两个数组的逐个字符串元素进行连接 multiply() 返回按元素多重连接后的字符串 center()居中字符串 capitalize()将字符串第一个字母转换为大写 title()将字符串的每个单词的第一个字母转换为大写 lower()数组元素转换为小写 upper()数组元素转换为大写 split()指定分隔符对字符串进行分割,并返回数组列表 splitlines()返回元素中的行列表,以换行符分割 strip()移除元素开头或者结尾处的特定字符 join()通过指定分隔符来连接数组中的元素 replace()使用新字符串替换字符串中的所有子字符串 decode()数组元素依次调用 str.decodeencode()数组元素依次调用 str.encode数学函数
import numpy as np # 四舍五入、三角函数 # sin()、cos()、tan()、around() # 加减乘除 # add(),subtract(),multiply() 和 divide() # 统计函数 # numpy.amin() 计算数组中的元素沿指定轴的最小值 # numpy.amax() 计算数组中的元素沿指定轴的最大值 # numpy.ptp() 计算数组中元素最大值与最小值的差 # numpy.percentile() 百分位数是统计中使用的度量 表示小于这个值的观察值的百分比 # numpy.median() 计算数组 a 中元素的中位数(中值) # numpy.mean() 返回数组中元素的算术平均值 如果提供了轴 则沿其计算 # numpy.average() 根据在另一个数组中给出的各自的权重计算数组中元素的加权平均值 # print (np.std([1,2,3,4])) 标准差 # print (np.var([1,2,3,4])) 方差 # 排序 # ...- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
线性代数
函数 描述 dot两个数组的点积,即元素对应相乘。 vdot两个向量的点积 inner两个数组的内积 matmul两个数组的矩阵积 determinant数组的行列式 solve求解线性矩阵方程 inv计算矩阵的乘法逆矩阵 矩阵库
2.2 Pandas
待定
2.3 Matplotlib
一句话囊括:数据可视化工具,下面做一个简单的二维绘图
import matplotlib.pyplot as plt import numpy as np x_points = np.array([0, 6]) y_points = np.array([0, 100]) plt.plot(x_points, y_points) plt.show()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
实际效果如下

为了把兴趣提起来,把三维也玩一下
import numpy as np import matplotlib.pyplot as plt # 求向量积(outer()方法又称外积) x = np.outer(np.linspace(-2, 2, 30), np.ones(30)) # 矩阵转置 y = x.copy().T # 数据z z = np.cos(x ** 2 + y ** 2) # 绘制曲面图 fig = plt.figure() ax = plt.axes(projection='3d') # 调用plot_surface()函数 ax.plot_surface(x, y, z, cmap='viridis', edgecolor='none') ax.set_title('Surface plot') plt.show()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
实际效果如下

1
1
2.4 Statsmodels
待定
2.5 Scikit-learn
三、算法实践
提示:这里可以添加本文要记录的大概内容
1
1
四、Java业务集成
提示:这里可以添加本文要记录的大概内容
1
1
总结
提示:这里对文章进行总结:
例如:以上就是今天要讲的内容。 -
相关阅读:
Unity3D 连接 SQLite 作为数据库基础功能【详细图文教程】
RK3562开发板:升级摄像头ISP,突破视觉体验边界
规则解读(三)| 本地资源检测 For Unreal
【Flink实战】新老用户方案优化使用状态与布隆过滤器的方式
从零开始学习Dubbo4——让模块独立运行
百叶帘系统内置于玻璃内,分为手动和电动两种控制方式
ABP微服务系列学习-搭建自己的微服务结构(三)
企业内容管理(ECM)软件如何为敏感文档创建安全访问
域渗透 | kerberos认证及过程中产生的攻击
【MySQL架构篇】存储引擎
- 原文地址:https://blog.csdn.net/weixin_48518621/article/details/126209948
