-
递归:理解和应用
从一个最最简单的例子出发,我们要对一个数组进行求和,一个想当然的方法就是直接进行遍历求和,我们看看能否考虑使用递归。
递归算法是一种直接或者间接调用自身函数或者方法的算法。说简单了就是程序自身的调用。递归算法就是将原问题不断分解为规模缩小的子问题,然后递归调用方法来表示问题的解。(用同一个方法去解决规模不同的问题)
- 递去:将递归问题分解为若干个规模较小,与原问题形式相同的子问题,这些子问题可以用相同的解题思路来解决
- 归来:当你将问题不断缩小规模递去的时候,必须有一个明确的结束递去的临界点(递归出口),一旦达到这个临界点即就从该点原路返回到原点,最终问题得到解决。
四、递归算法的设计要素
递归思维是一种从下向上的思维方式,使用递归算法往往可以简化我们的代码,而且还帮我们解决了很复杂的问题。递归算法的难点就在于它的逻辑性,一般设计递归算法需要考虑以下几点:
- 明确递归的终止条件
- 提取重复的逻辑,缩小问题的规模不断递去
- 给出递归终止时的处理办法
什么时候使用递归
判断一个问题是否可以使用递归才是掌握递归的开始。先看几个经典的递归问题
1. 顺序打印链表

看到这个问题,最简单的想法就是循环了,老实说考虑使用递归去解的我都觉得是脑子有问题,无奈为了慢慢理解递归只能强行往上靠。
我考虑的时候是非常直接,打印当前的数字,然后递归的调用自身不断缩小问题规模# Definition for singly-linked list. # class ListNode: # def __init__(self, x): # self.val = x # self.next = None class Solution: def printList(self, head: ListNode) -> List[int]: if head is None: return print(head.val) self.printList(head.next)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13

- 明确了递归的停止条件,
head is None的时候到了链表的末尾了,无需进一步打印因此可以停止了 - 提取重复的逻辑,这里的重复逻辑非常的简单,就是
print(head.val) - 缩小问题规模,我们不断调用
head.next,使得head往链表后面移动,缩小了问题规模 - 递归终止的时候我们也无需做其他事情,因此直接返回即可
老实讲,这里的递归其实就是for循环,我们不断的往后遍历。
2. 链表求和
链表求和和打印是一样的,我们使用递归遍历每一个元素然后求和即可。但是这里考虑的是递归的子问题。
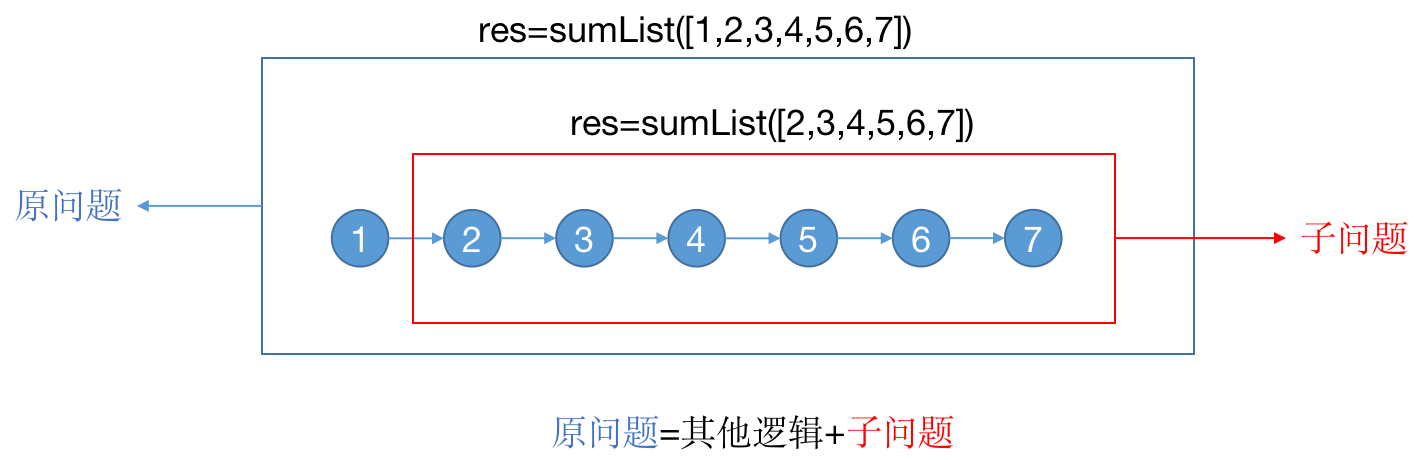
从上图也可以很容易明白,我们可以缩小问题规模的,想要求解sum([1,2,3,4,5,6,7]),我们只要先求出sum([2,3,4,5,6,7])的结果,然后再跟head.val相加即可。同样的套娃方式,我们想要求解sum([2,3,4,5,6,7]),只需要求解sum([3,4,5,6,7])即可。

# Definition for singly-linked list. # class ListNode: # def __init__(self, x): # self.val = x # self.next = None class Solution: def listSum(self, head: ListNode) -> List[int]: if head is None: return 0 s = self.listSum(head.next) + head.val # 子问题 return s # 其他逻辑- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 明确了终止条件,当
head is None的时候就不需要再累加了,这个时候我们可以返回0 - 提取重复逻辑,这里的重复逻辑也很简单,就是把当前的值与子问题的值累加即可
self.listSum(head.next) + head.val
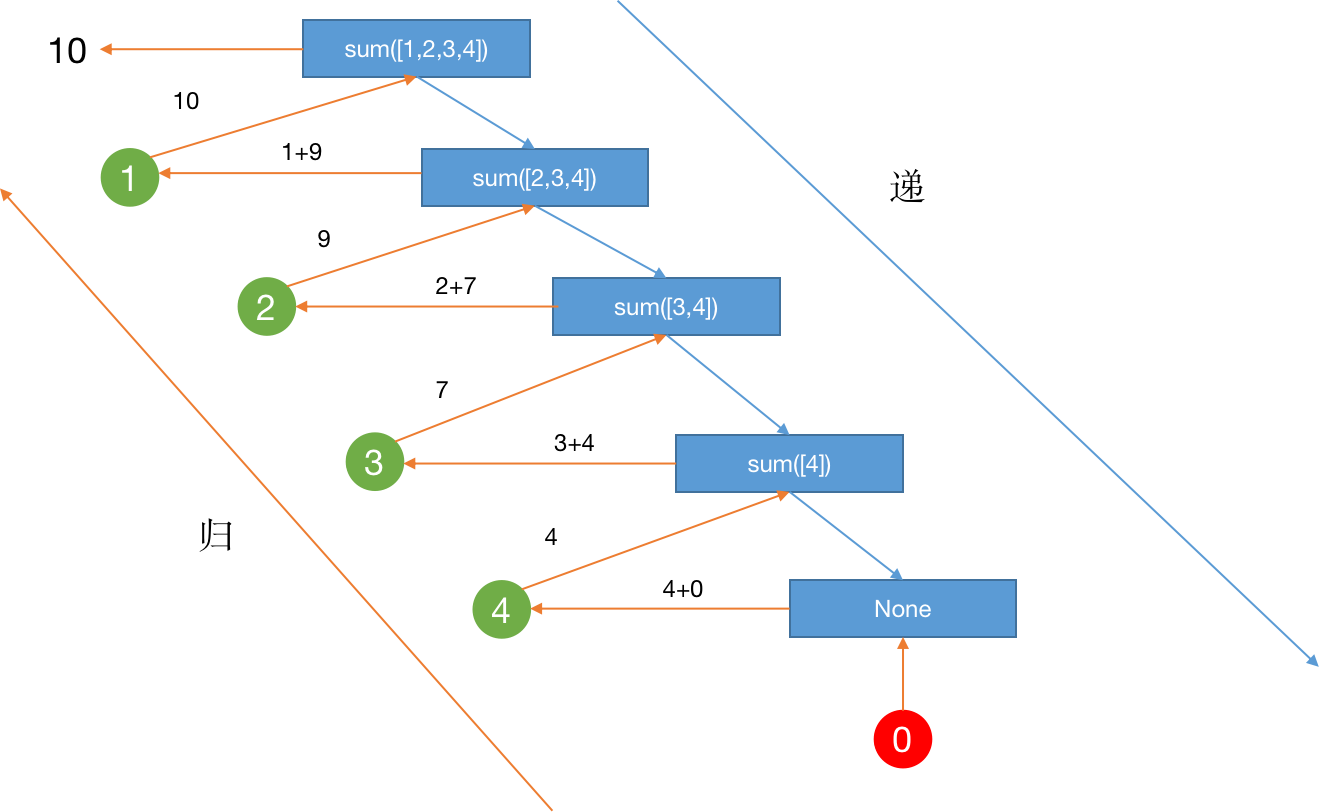
3. 数组求和
数组求和的递归是我自己瞎想的,主要是想要使用归并的思想,我们依然把原问题划分为子问题,进而缩小问题规模。但是这里我们需要调用两次子问题,我们把数组分为两个部分,然后分别求解出左边数组的和,右边数组的和,之后将其相加就是总的和

这个问题也很好的说明了递归的一个特点,那就是缩小问题规模,子问题与原问题是等价的,我们求解出子问题之后,需要再进行一些逻辑操作。现在突然想到一个问题,子问题与原问题等价吗?- 逻辑上肯定是相同的,只是问题规模缩小了。
- 那些逻辑操作则是解决问题的
arr = [-1,2,3,4,5,6] def mergeAdd(arr, l,r): if l >= r: return arr[l] m = (l + r) // 2 lsum = mergeAdd(arr, l, m) rsum = mergeAdd(arr, m+1, r) return lsum + rsum res = mergeAdd(arr,0,len(arr)-1) print(res)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 终止条件,当左游标大于等于右游标的时候,说明只有一个元素了,此时直接返回值即可
- 子问题和重复逻辑,原来求解的是
0到len(arr)-1所有元素的和,现在求解成子问题0到m和子问题m+1到len(arr)-1和,调用了两次子问题,之后将求解的和相加即是总的和
4. 逆序打印链表
逆序打印链表体现了递归的归,我们知道执行函数的时候其实就是在压栈。对递归的考虑其实非常的简单,就是不断的深入深入在深入,一直等到遇到停止条件之后再回去,如果是想要正序的话就直接处理输出即可,如果想要逆序就不断递归,然后在处理
def dfs(head): # 逆序 stop condition dfs(head.next) # 不断往后 do something() # 到最后再处理 def dfs(head): # 顺序 stop condition do something() # 先处理输出 dfs(head.next) # 然后再向下寻找- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
# Definition for singly-linked list. # class ListNode: # def __init__(self, val=0, next=None): # self.val = val # self.next = next class Solution: def reverseList(self, head: Optional[ListNode]) -> Optional[ListNode]: if head is None: return self.reverseList(head.next) print(head.val)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12

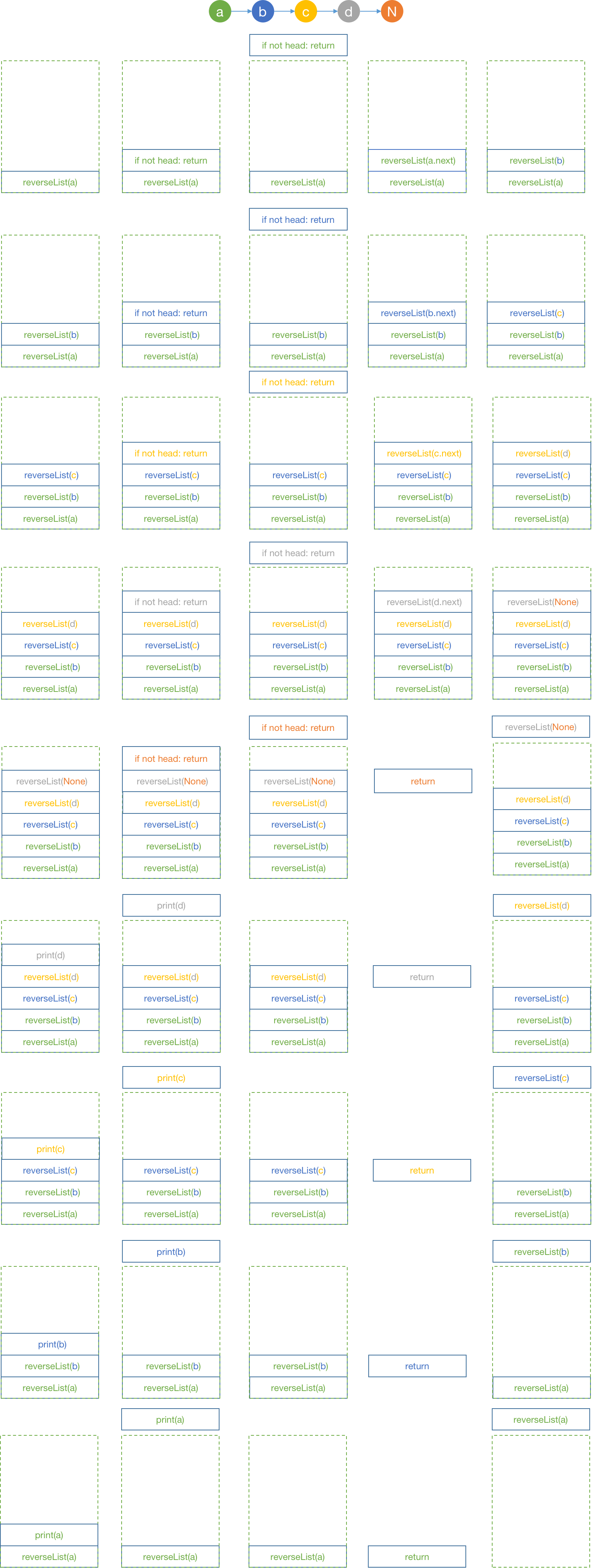
5. 二叉树的遍历
链表可以递归,这是因为链表子部分也是链表,这与递归的思路不谋而合,二叉树也是这个样子的,二叉树的左右子树都是二叉树。
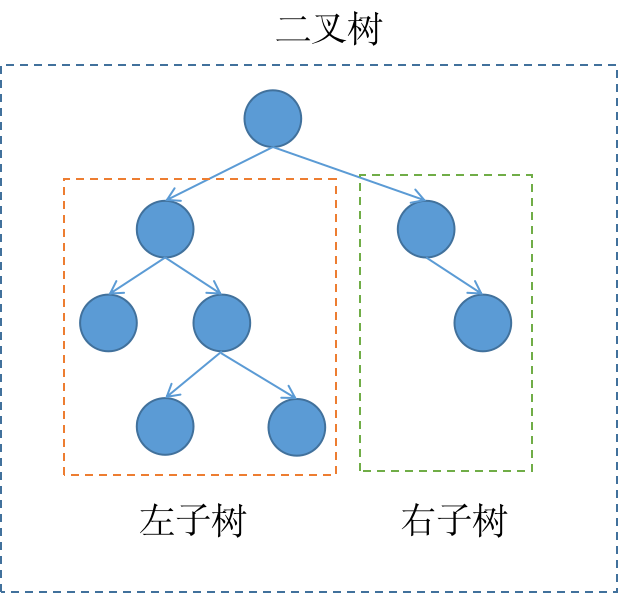
根据二叉树的结构我们很容易写出二叉树的遍历代码
# Definition for a binary tree node. # class TreeNode: # def __init__(self, val=0, left=None, right=None): # self.val = val # self.left = left # self.right = right class Solution: def traversal(self, root: Optional[TreeNode]) -> List[int]: if root is None: return print(root.val) self.traversal(root.left) self.traversal(root.right)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
代码是非常的简单,而且逻辑也非常的简单
- 打印节点的值
- 遍历左子树
- 遍历右子树
但是为什么这样就可以遍历整棵二叉树呢?我觉得有可能是因为我逻辑搞反了,先想着递归然后去解决问题。正确的逻辑应该是先解决问题,然后再去看是不是递归。首先逻辑是不变,我们肯定是先打印根节点的值,然后再打印左右子树所有的节点,我把这个问题一般化
class Solution: def traversal(self, root: Optional[TreeNode]) -> List[int]: print(root.val) # 打印当前节点 traversal_left(root.left) # 打印左子树 traversal_right(root.right) # 打印右子树- 1
- 2
- 3
- 4
- 5
然后我们再定义打印左子树的代码
class Solution: def traversal_left(self, root: Optional[TreeNode]) -> List[int]: print(root.val) # 打印当前节点 traversal_left(root.left) # 打印左子树 traversal_right(root.right) # 打印右子树- 1
- 2
- 3
- 4
- 5
打印右子树的代码
class Solution: def traversal_right(self, root: Optional[TreeNode]) -> List[int]: print(root.val) # 打印当前节点 traversal_left(root.left) # 打印左子树 traversal_right(root.right) # 打印右子树- 1
- 2
- 3
- 4
- 5
看到了吧,代码逻辑没有任何的变化,这本身就是递归
-
相关阅读:
Elasticsearch:Geo-grid query - Elastic Stack 8.3
神经网络气温预测
MapReduce程序设计2
《UDS协议从入门到精通》系列——图解0x35:请求上传
(原创)[C#] 一步一步自定义拖拽(Drag&Drop)时的鼠标效果:(一)基本原理及基本实现
华为云云耀云服务器L实例评测|无人值守羽毛球馆预约小程序系统搭建方案 | 在线场馆预订 | 共享空间
01-服务与服务间的通信
替代MySQL半同步复制,Meta技术团队推出MySQL Raft共识引擎
JAVA中的集合类型的理解及应用
OceanBase社区版4.0,给了我很多惊喜
- 原文地址:https://blog.csdn.net/he_wen_jie/article/details/126196945