JUC源码学习笔记4——原子类,CAS,Volatile内存屏障,缓存伪共享与UnSafe相关方法
volatile的原理和内存屏障参考《Java并发编程的艺术》 原子类源码基于JDK8
一丶volatile 与内存屏障
volatile修饰的字段,Java线程模型保证所有线程看到这个变量值是一致的。
1.volatile是如何保证可见性
volatile修饰的变量执行写操作的时候多出lock前缀指令的代码,lock前缀的指令会导致
- 将当前这个处理器缓存行的数据写回到系统内存
- 这个写回内存的操作将导致其他CPU里缓存了该地址内存的数据无效
为了提高处理速度,处理器不直接和内存通信,而是先把系统内存的数据读到内部缓存后继续操作,但是操作完不知道何时写回内存。如果对volatile修饰的变量执行写操作,将会让数据写回到系统内存,但是其他线程还是使用缓存中的旧值,还是会存在问题。所以在多处理器下为了保证每一个处理器缓存时一致的,就会实现缓存一致性协议,每个处理器通过嗅探总线上传播的数据来检查自己缓存的数据是否过期,如果发现自己缓存行中对应的内存地址被修改了,就会将当前处理器的缓存行设置成无效,当前处理器对这个数据进行修改操作时,会重新从主内存拉取最新的数据到缓存。
2 指令重排序
在程序执行时,为了提高性能,处理器和编译器通常会对指令进行重排序。
- 编译器优化重排序,编译器在不改变语义的情况下,重新安排语句执行顺序。
- 指令级别并行重排序,如果不存在数据依赖性,处理器改变语句对应机器指令的执行顺序。
- 内存系统重排序,由于处理器使用缓存和读/写缓冲区,这使得加载和存储的操作看起来是乱序执行
为了保证内存可见性,Java编译器在生成指令序列的适当位置会插入内存屏障来禁止处理器级别的(指令级别并行重排序,内存系统重排序)指令重排序
3 JMM中内存屏障的类型
不同硬件实现内存屏障的方式不同,Java内存模型屏蔽了这种底层硬件平台的差异,由JVM来为不同的平台生成相应的机器码。
- Load Barrier: 在读指令前插入读屏障,可以让高速缓存中的数据失效,重新从主内存加载数据
- Store Barrier:在写指令之后插入写屏障,能让写入缓存的最新数据写回到主内存
实际使用中,又分为以下四种:
| 类型 | 解释 |
|---|---|
| LoadLoad | 对于Load1,Loadload,Load2 ,确保Load1所要读入的数据能够在被Load2和后续的load指令访问前读入 |
| StoreStore | 对于Store1,StoreStore,Store2 确保Store1的数据在Store2以及后续Store指令操作相关数据之前对其它处理器可见(例如向主存刷新数据)。 |
| LoadStore | 对于 Load1; LoadStore; Store2 ,确保Load1的数据在Store2和后续Store指令被刷新之前读取 |
| StoreLoad | 对于Store1; StoreLoad; Load2 ,确保Store1的数据在被Load2和后续的Load指令读取之前对其他处理器可见。StoreLoad屏障可以防止一个后续的load指令 不正确的使用了Store1的数据,而不是另一个处理器在相同内存位置写入一个新数据。正因为如此,所以在下面所讨论的处理器为了在屏障前读取同样内存位置存过的数据,必须使用一个StoreLoad屏障将存储指令和后续的加载指令分开。Storeload屏障在几乎所有的现代多处理器中都需要使用,但通常它的开销也是最昂贵的。它们昂贵的部分原因是它们必须关闭通常的略过缓存直接从写缓冲区读取数据的机制。这可能通过让一个缓冲区进行充分刷新(flush),以及其他延迟的方式来实现。 |
4.volatile的内存语义
- 可见性:对一个volatile变量的读一定能看到(任何线程)对这个volatile变量最后的写
- 原子性:对任意单个volatile变量的读和写具有原子性,但是自增这种复合操作不具备原子性
5.volatile内存语义的实现
JMM为了实现volatile的内存语义限制了编译器重排序和处理器重排序

- 当第一个操作是普通变量都或者写且第二个操作是volatile写时,编译器不能重排序这两个操作
- 当第二个操作是volatile写时,无论第一个操作是什么都不可以重排序,保证了volatile写操作前的指令不会重排序到volatile写之后
- 当第一个操作是volatile读时,不管第二个操作是什么,都不可重排序,保证了volatile读之后的指令不会重排序到volatile读之前
- 当第一个操作是volatile写,第二个操作是volatile读,不能重排序
为了实现volatile的内存语义,JMM在volatile读和写的时候会插入内存屏障
-
volatile写的内存屏障

这里的store store 屏障可以保证前面所有普通写对所有处理器可见,实现了在volatile写之前写入缓存的最新数据写回到主内存
volatile写之后的内存屏障,避免与后续的volatile读写出现重排序,由于虚拟机无法判断volatile写之后是否需要一个store load屏障,比如在volatile写之后立即return,为了保证volatile的内存语义,JMM十分保守的插入一个store load屏障。
-
volatile 读的内存屏障

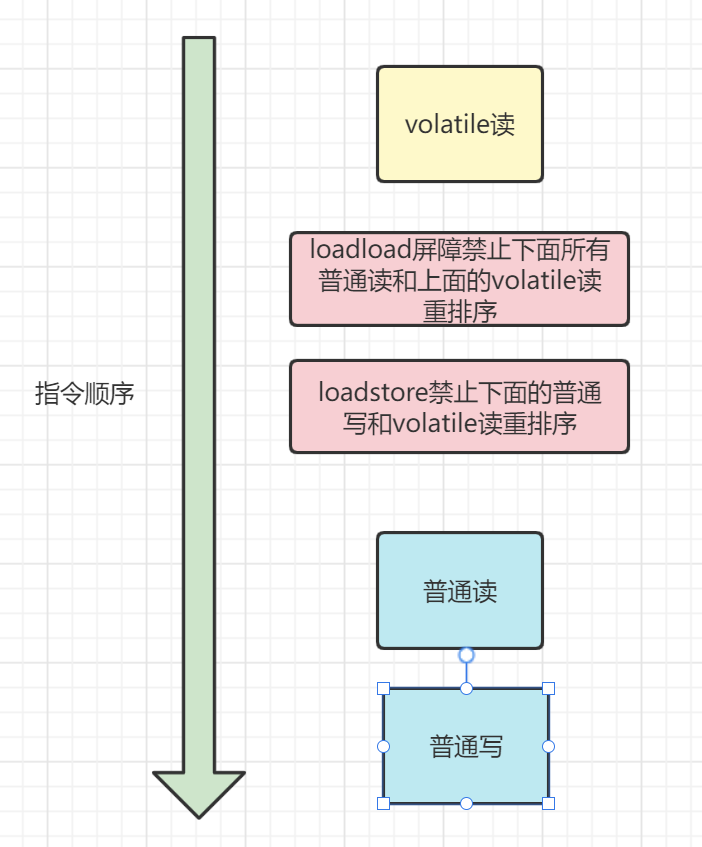
这里的loadload保证了下面普通读不可以在volatile读之前,loadstore保证普通写不可在volatile之前
二丶CAS
1.什么是CAS
即比较并替换,实现并发算法时常用到的一种技术。CAS操作包含三个操作数——内存位置、预期原值及新值。执行CAS操作的时候,将内存位置的值与预期原值比较,如果相匹配,那么处理器会自动将该位置值更新为新值,否则,处理器不做任何操作。CAS是一条CPU的原子指令(cmpxchg指令),不会造成所谓的数据不一致问题,Unsafe提供的CAS方法(如compareAndSwapXXX)底层实现即为CPU指令cmpxchg。
2.CAS的缺点
-
ABA问题是指在CAS操作时,其他线程将变量值A改为了B,但是又被改回了A,等到本线程使用期望值A与当前变量进行比较时,发现变量A没有变,于是CAS就将A值进行了交换操作,但是实际上该值已经被其他线程改变过,这与乐观锁的设计思想不符合。ABA问题的解决思路是,每次变量更新的时候把变量的版本号加1,那么A-B-A就会变成A1-B2-A3,只要变量被某一线程修改过,改变量对应的版本号就会发生递增变化,从而解决了ABA问题。
-
热点数据更新问题
如果一个数据同时被1000个线程更新,那么存在一个倒霉蛋线程自旋1000次才能成功修改,第一个成功的线程会导致999个线程失败,999个线程必须自旋,依次类推,自旋是消耗CPU资源的,如果一直不成功,那么会占用CPU资源。
解决方法:破坏掉for死循环,当超过一定时间或者一定次数时,return退出。或者把热点数据拆分开,最后再汇总
这些问题在后面的原子类代码中都有具体的实践
三丶原子类
Java8在java.util.atomic具有16个类,大致可以分为
- 原子更新基本类型
AtomicBooleanAtomicIntegerAtomicLong
- 原子更新数组
AtomicIntegerArrayAtomicLongArrayAtomicReferenceArray原子更新引用数组
- 原子更新引用类型
AtomicReference原子更新引用类型AtomicReferenceFieldUpdater原子更新引用类型的字段AtomicMarkableReference原子更新代标记位的引用类型,可以更新一个布尔类型的标记位和引用类型。AtomicStampedReference原子更新带有版本号,引用类型,该类把版本和引用类型关联起来,可以用于原子更新数据和数据的版本号,可以解决CAS出现的ABA问题
- 累加器
DoubleAccumulatorDoule类型累加器,支持函数是表达式描述值要如何变化DoubleAdderDoule类型累加器,支持增大减小多少LongAccumulatorLong类型累加器,支持函数是表达式描述值要如何变化LongAdderLong类型累加器,支持增大减小多少
四丶原子类源码解析
1.原子更新基本类型
AtomicBoolean ,AtomicInteger,AtomicLong的原理类似,选择AtomicInteger看下。
1.1AtomicInteger 源码解析
1.1.1 字段和偏移量
-
使用
volatile修饰内部int类型的value 字段java private volatile int value; //value字段就是用于存储整形变量的,后续操作也是对这个字段的CAS操作 volatile修饰保证了value字段对所有线程的可见性,也保证了对value的修改可以立即刷新会主存,以及对value的读取操作也会从主存读取。 -
静态代码块获取
value对于AtomicInteger对象的偏移量java private static final Unsafe unsafe = Unsafe.getUnsafe(); //value字段偏移量 private static final long valueOffset; static { try { //调用Unsafe中的objectFieldOffset 方法获取value字段相对的偏移量 //cas操作需要需要知道当前value字段的地址, //这个地址是相对AtomicInteger的偏移量, //知道AtomicInteger的地址再加上偏移就可以直接操作value地址的值了 valueOffset = unsafe.objectFieldOffset (AtomicInteger.class.getDeclaredField("value")); } catch (Exception ex) { throw new Error(ex); } }
1.1.2 构造方法
1.1.3 获取和设置value值
这里没有进行任何线程安全的控制,因为JMM保证了从主存读取volatile修饰的变量,和写入volatile修饰的变量是原子性的操作
1.1.4 获取并赋值 getAndSet
这个方法获取后赋值value为入参newValue,直接调用了Unsafe的getAndSetInt方法
注意这里的getIntVolatile 是带有内存屏障的读取volatile变量,如果这里使用getInt也许会导致重排序出现
1.1.5 比较并设置 compareAndSet
1.1.6 获取并自增1或自减1
还是调用的Unsafe的getAndAddInt方法
1.1.7 自增1,自增1并获取,增加并获取
1.1.8 支持函数式接口的几个方法
这几个方法式JDK8支持函数式接口后新增的方法
-
getAndAccumulatejava public final int getAndAccumulate(int x, IntBinaryOperator accumulatorFunction) { int prev, next; do { //旧值 prev = get(); //CAS将设置成的值 调用IntBinaryOperator获取 next = accumulatorFunction.applyAsInt(prev, x); } while (!compareAndSet(prev, next)); return prev; } 比如说我要实现增大到旧值的x倍,并且返回旧值,那么就可以使用
java //这里的2 就是增大两倍, int doubleReturnPre = ai.getAndAccumulate(2, (pre, x) -> pre * x); -
accumulateAndGetjava public final int accumulateAndGet(int x, IntBinaryOperator accumulatorFunction) { int prev, next; do { prev = get(); next = accumulatorFunction.applyAsInt(prev, x); } while (!compareAndSet(prev, next)); return next; } 和
getAndAccumulate不同在于返回是CAS更新成功的值,意味着下面这行代码返回的是增大后的值,而不是增大前的值java //这里的2 就是增大两倍, int doubleReturnNew = ai.accumulateAndGet(2, (pre, x) -> pre * x); -
updateAndGetjava public final int updateAndGet(IntUnaryOperator updateFunction) { int prev, next; do { prev = get(); next = updateFunction.applyAsInt(prev); } while (!compareAndSet(prev, next)); return next; } IntUnaryOperator的applyAsInt只接受一个参数,这里传入了当前值,可以在applyAsInt中定义如何更新。updateAndGet返回新值
-
getAndUpdatejava public final int getAndUpdate(IntUnaryOperator updateFunction) { int prev, next; do { prev = get(); next = updateFunction.applyAsInt(prev); } while (!compareAndSet(prev, next)); return prev; } 和updateAndGet类似,返回的是旧值
1.1.9lazySet
lazySet提供一个store store屏障(在当代系统中是很低成本的操作,或者说没有操作),但是没有store load屏障,我的理解是把volatile的写后store load替换成了store store,Store load屏障可以让后续的load指令对其他处理器可见,但是需要将其他处理器的缓存设置成无效让它们重新从主层读取,store store,是保证后续处理器在写volatile变量的时候可以看见lazyset方法改变的值,但是后续的读不保证一定可见,但是对于volatile变量的读自然是会读到最新值的,从而减少了开销。lazySet的lazy 意味着最终数据的一致性,但是当前是进行了偷懒的(指store store替代了storeload)
2.AtomicBoolean
源码基本上和AtomicInteger类似,但是并不是底层存的布尔类型,而是使用int类型,0代表false,1代表true
3.AtomicLong
和AtomicInteger类似
2.原子更新数组
AtomicIntegerArray,AtomicLongArray,AtomicReferenceArray的原理类似,数组类型更新的问题在于,我要更新下标为i的元素,我怎么知道i这个元素的地址。如果我们知道第一个元素相对于对象的偏移base,和每个元素的偏移s,那么第i个元素就是base+i*s
2.1计算第i个元素的位置
2.2 获取和设置
其他方法和AtomicInteger中大差不大都是调用Unsafe中的相关方法
3.原子更新引用
AtomicReference还是老套路,不多赘述
3.1 原子更新引用的一个字段
AtomicReferenceFieldUpdater 是一个抽象类,使用的时候必须调用newUpdater(持有字段类的class,字段类型,字段名称)来获取它的实现AtomicReferenceFieldUpdaterImpl(调用了AtomicReferenceFieldUpdaterImpl的构造方法涉及一些类加载器知识)后续的更新也是调用unsafe的cas相关操作
3.2 原子的更新引用和布尔标记
AtomicMarkableReference可以同时更新引用和引用的标记,上面我们提到CAS的一个缺点——ABA问题,比如说,当前商店存在一个活动,如果账户办理冲一百送50,每个账户依次机会,A用户充值后获得150元立马消费成0元接着充值100,如果用普通的原子类AtomicInteger程序还会再次送50元给用户A(ABA问题,程序不知道是否赠送过了),我们可以使用锁充值后获取锁往集合里面记录当前用户赠送了,也可以使用AtomicMarkableReference通过更新mark来记录用户赠送过了
AtomicMarkableReference内部维护了一个Pair,并且private volatile Pair 持有一个pair

3.2.1compareAndSet(旧引用,新引用,旧标记,新标记)
current = pair;
也就是说,首先要求旧值是和当前pair相同的,如果修改之前被其他线程修改了那么短路返回false,如果引用从始至终都没改变,那么都不需要CAS操作,否则CAS pair属性,下面是casPair的源码——还是老套路
cmp, Pair val) {
3.2.2 attemptMark(旧引用,新标记)
current = pair;
和compareAndSet的区别在于,其只要求引用相同,如果mark相同那么什么都不做,反之CAS修改pair
3.3 原子的更新引用和版本号
AtomicStampedReference也是用来解决ABA问题的,不同的是其标记不只是true和false,可以是1,2,3等等等版本号,我们把AtomicMarkableReference中活动改下,每一个账户可以参与3次活动,那么在充值的时候我们把版本号加1,最后版本号来到3 表示这个账户参与了3次,后续充值就不赠送了。
AtomicStampedReference 实现和AtomicMarkableReference简直一模一样,区别在于AtomicStampedReference中Pair类是引用和版本号

4.累加器
上面我们提到CAS的缺点说到存在热点数据更新导致多数线程失败自旋的问题,其中一个解决办法是自旋次数,失败就返回活动太火爆这种劝退消息,另外一种解决办法是——热点数据拆分开,最后再汇总。这个思路和ConcurrentHashMap的分段锁思路类似,既然我如同HashTable导致性能低下(修改key A和B都受一把锁的影响)那么我把数据,不同的数据使用不同的锁,就可以提高吞吐量了。在累加器中的体现就是,在最初无竞争时,只更新base的值,当有多线程竞争时通过分段的思想,让不同的线程更新不同的段,最后把这些段相加就得到了完整存储的值。
累加器的思路都类似,我们选择LongAdder 和 LongAccumulator来看下
4.1 LongAdder
4.1.1 LongAdder的内部结构
LongAdder 内部有base用于在没有竞争的情况下,进行CAS更新,其中还有Cell数组在冲突的时候根据线程唯一标识对Cell数组长度进行取模,让线程去更新Cell数组中的内容。这样最后的值就是 base+Cell数组之和,LongAdder自然只能保证最终一致性,如果边更新边获取总和不能保证总和正确。

4.1.2 LongAdder的继承关系
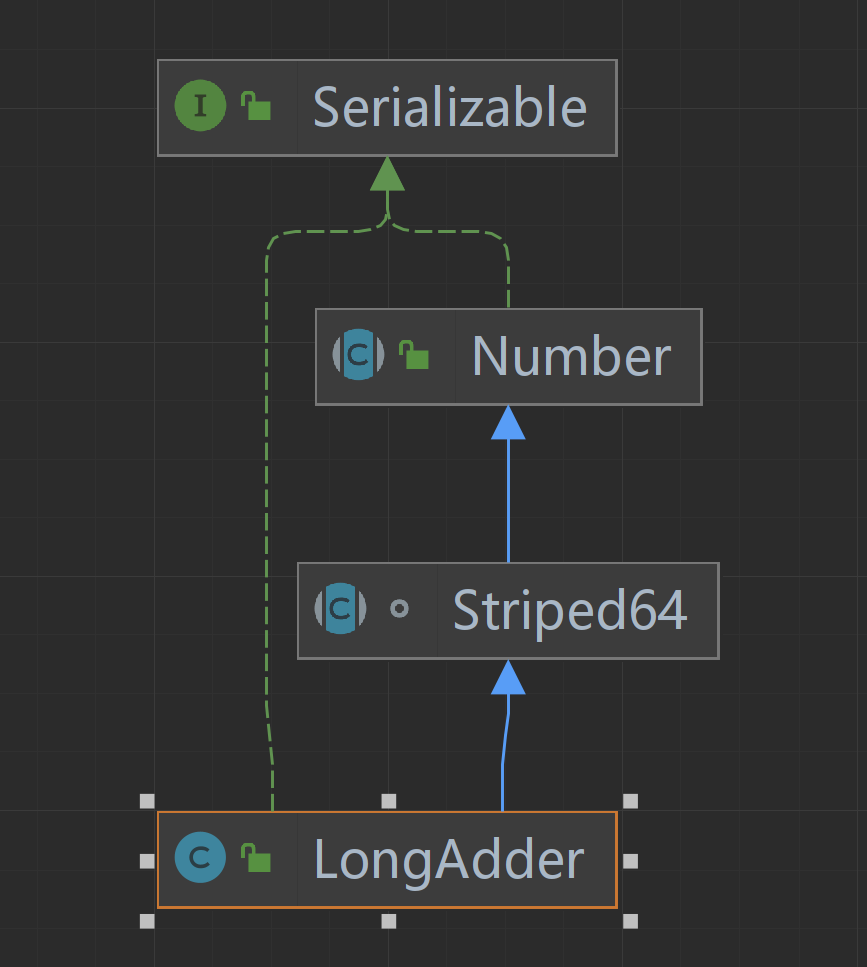
这里比较迷惑的就是Striped64这个类,此类是一个内部类,用于实现 Adder 和 Accumulator,我们上面所说的base,Cell数组其实就是在此类中的。
4.1.3 LongAdder 源码解析
4.1.3.1Cell 类
此类位于Striped64中,就是我们上面说的Cell数组进行热点数据分离的Cell
Cell 这个类还是老套路,唯一不同的是它类上面具有一个注解 @sun.misc.Contended 此注解会进行缓存填充,避免缓存伪共享 (这部分内容在文末);
4.1.3.2 Striped64中的属性
NCPU记录了系统 CPU 的核数,因为真正的并发数最多只能是 CPU 核数,因此cells数组只能小于等于这个数。cells数组,大小是 2 的次方,这样将线程映射到cells元素时方便计算。base,基本数值,一般在无竞争能用上,同时在cells初始化时也会用到。cellsBusy,自旋锁,在创建或扩充cells时使用
4.1.3.3 LongAdder #void add(long x)
A.对于第一个if
-
从来没有发生过竞争
并发量很低的时候
Cell数组就是空,这个时候第一个if中的(as = cells) != null就是false 会继续执行后续的!casBase(b = base, b + x)这一步会cas的更新bese 值- 如果cas更新base成功了,那么皆大欢喜,直接结束了,说明当前并发还是很低
- 如果cas 更新失败,说明这一瞬间有多个线程都在更新base值,并发比较高,当前线程是一个倒霉蛋,cas更新没有抢过别人。这个时候会进入到 if代码块中
-
之前发生过竞争
这个时候第一个if的
(as = cells) != null就成立了 ,不会走第一个if中的cas操作,直接进入第二个if
B.对于第二个if
进入第二个if,当前线程需要把值更新到对应的cell中
-
as == null || (m = as.length - 1) < 0这意味着cell数组没有初始化,也就是说这是第一次存在高并发竞争的情况,那么调用longAccumulate这个方法会帮我们初始化cell数组的 -
(a = as[getProbe() & m]) == null这意味着,cell数组初始化了,但是当前线程标识取模数组长度得到当前线程应该更新的cell为空- getProbe方法是获取线程的一个标识,获取的是当前线程中的
threadLocalRandomProbe字段,字段没有初始化的时候默认是0 - m是 cell数组的长度-1,cell数组的长度为2的n此幂,m的二进制全1,getProbe() & m就是对cell数组长度进行取模,这点在HashMap源码中也使用到了
如果当前线程所属的Cell为空,那么也会调用
longAccumulatenone 这里我们要关注一点 getProbe 方法初始的时候都是0,0取模任何数都是0 那么每一个线程最开始都会分配第一个Cell, 那么第一个Cell为空意味着什么昵, 这个问题需要我们看完longAccumulate 方法才能揭晓 其实probe=0在longAccumulate方法中意味着 当前线程没有和其他线程发生冲突更新 在longAccumulate 会初始化probe 设置冲突更新表示为false - getProbe方法是获取线程的一个标识,获取的是当前线程中的
-
!(uncontended = a.cas(v = a.value, v + x))这里是调用Cell的cas方法,就是更新Cell对象中的value字段,如果这里cas失败了,说明当前存在一个线程也在更新当前cell对象的value,两个线程要更新一个cell,说明出现了冲突,也会调用longAccumulate进行自旋更新cell单元格中的值。
4.1.3.4 Striped64#longAccumulate
longAccumulate 方法非常长,我们拆看慢慢看
-
初始化
threadLocalRandomProbejava //如果是0 表示没有是没有初始化的 //这里会为当前线程生成一个probe if ((h = getProbe()) == 0) { ThreadLocalRandom.current(); // force initialization h = getProbe(); //设置为没有竞争, wasUncontended = true; } -
自旋保证当前线程能把值写入
A.如果Cell数组已经成功初始化,下面都是A的子情况
-
情况1:如果当前线程threadLocalRandomProbe取模后对应的cell为空,那么我们需要在当前线程对应的位置new一个cell赋值上去
java //as——cells数组引用 //a 当前线程对应的cell //n 当前数组长度 //v 期望值 //h 当前线程的threadLocalRandomProbe //x是当前线程要增加的值 Cell[] as; Cell a; int n; long v; //如果cells初始化了 if ((as = cells) != null && (n = as.length) > 0) { //如果当前线程threadLocalRandomProbe取模后对应的cell为空 //==========代码点1(后续解析中会使用到)============== if ((a = as[(n - 1) & h]) == null) { //cellsBusy是一个自旋锁保证Cell数组的线程安全 //0代表无线程调整Cell数组大小or或创建单元格 //1 则反之 //==========代码点2(后续解析中会使用到)============== if (cellsBusy == 0) { //为当前线程创建一个cell, //x直接赋值给其中的value 后续求和会加上这个x,从而实现增加 Cell r = new Cell(x); //0代表无线程调整Cell数组大小or或创建单元格 //casCellsBusy 是从0设置成1 表示当前线程尝试获取这把锁 //==========代码点3(后续解析中会使用到)============== if (cellsBusy == 0 && casCellsBusy()) { boolean created = false; try { Cell[] rs; int m, j; //重新判断cell数组初始化了,且当前cell是空 //看下方解析为何需要重新 //==========代码点4(后续解析中会使用到)============== if ((rs = cells) != null && (m = rs.length) > 0 && rs[j = (m - 1) & h] == null) { //设置到cell数组上 rs[j] = r; created = true; } } finally { //释放锁 cellsBusy = 0; } //如果这里成功创建了cell,说明成功把值加上去了 //那么退出自旋 if (created) break; continue; // Slot is now non-empty } } collide = false; //....省略部分代码,这部分也会在后续解析 //重新刷新当前线程的Probe //==========代码点5(后续解析中会使用到)============== h = advanceProbe(h); } 这里比较有意思有
-
在判断
(a = as[(n - 1) & h]) == null即当前线程对应的cell为空(代码点1),首先在代码点2是判断了cellsBusy == 0说明当前无线程在创建Cell单元格的,然后new了一个Cell,继续在代码点3还是会判断cellsBusy == 0,是由于我们在new一个cell的过程中可能存在消耗完时间片的情况,然后其他线程恰好可能已经获得到了cellsBusy这把锁,这里再次判断cellsBusy反之无脑获取锁执行casCellsBusy,可以说doug lea真的是性能狂魔 -
在
代码点4,来到代码点4其实已经在代码点1处已经判断了当前线程对应的Cell单元格为空啊,为什么这里还要判断一次昵,因为可能在当前new 一个cell的这段时间有另外一个线程也设置了这个位置的Cell,或者改变了cell数组,并且释放了cellsBusy锁,为了保证此位置的Cell单元格的值不被当前线程无脑覆盖,所有再次进行了判断。 -
什么时候会结束自旋,这段代码其实给出了一个答案——created为true
这里的
created只会在当前线程成功设置其对应的单元格为new Cell(增加的值)时为true,也就代表着当前线程已经成功进行了一个增加操作 -
什么时候会继续自旋
-
代码点2处的if (cellsBusy == 0)不成立这意味着,当前线程对应的Cell为空,但是存在其他线程正在调整Cell数组大小or或创建单元格,为了保证Cell数组中的值不被覆盖,这个时候会执行到
代码点5调用advanceProbe重新为当前线程生成一个probejava //使用位操作,把当前线程的probe随机打散,为啥这里这样进行位操作 //我只能说,可能时doug lea研究后的,或者他喜欢这个几个数字 //但是这几个数组都是质数,大概率后面是存在理论支撑的, static final int advanceProbe(int probe) { probe ^= probe << 13; // xorshift probe ^= probe >>> 17; probe ^= probe << 5; UNSAFE.putInt(Thread.currentThread(), PROBE, probe); return probe; } -
代码点3处的if(cellsBusy == 0 && casCellsBusy())不成立和上面的1差不多
-
if (created)不成立这意味,
代码点4处的判断不成立,说明存在线程A已经完成了cell数组的扩容,导致当前线程对应的Cell改变了(数组长度扩大2,probe%长度=n,可能是原来的位置n,也可以是n+当前长度/2 )也可能是线程A给当前线程对应Cell单元格赋值了(线程A的probe对数组长度取模后和当前线程相同,但是线程A抢先一步设置了单元格)但是这时候不会调用到advanceProbe因为可以沿用之前的probe找到对应的位置进行设置值,这个坑位还是可以设置值的只是有人抢先一步了,不能直接new Cell(x),需要让这个Cell值增加x,但是1和2调用advanceProbe的原因是,为了提升性能,让他随便找个其他坑位做增加的操作。none 再次给看跪了,doug lea真性能狂魔
-
-
-
情况2:如果在
LongAdder#add方法中对应Cell进行CAS失败,那么rehash后继续自旋java if ((as = cells) != null && (n = as.length) > 0) { if ((a = as[(n - 1) & h]) == null) { //省略了情况1的代码 } else if (!wasUncontended) // CAS already known to fail wasUncontended = true; //....省略部分代码,这部分也会在后续解析 //重新刷新当前线程的Probe h = advanceProbe(h); wasUncontended这个变量位false只可能是调用longAccumulate这个方法入参就为false,让我们回到LongAdder#addjava public void add(long x) { Cell[] as; long b, v; int m; Cell a; if ((as = cells) != null || !casBase(b = base, b + x)) { //初始为true boolean uncontended = true; if (as == null || (m = as.length - 1) < 0 || (a = as[getProbe() & m]) == null || //注意这里 !(uncontended = a.cas(v = a.value, v + x))) //要让uncontended为false //那么说明上面的a.cas(v = a.value, v + x)失败了 longAccumulate(x, null, uncontended) } } 这里我们可以看到,必须是当前线程对其cell进行cas操作失败才可能为false,这里的false意味着,当前并发很高,有几个老六线程在对这个一个cell进行cas,那么这个时候会执行到
else if (!wasUncontended) wasUncontended = true然后执行advanceProbe,这意味着,只能说当前线程命不好执行重新rehash下probe换一个Cell单元格进行操作,可以理解为Java就业太卷了,换Go语言了。这样做的好处是提高了其他cell单元格的利用率,性能up,这里把wasUncontended随后设置为true,可以理解为,当前线程都要rehash了,后续发生还不行那就是“岗位不够了”得扩容Cell数组了,后续也就用不着wasUncontended -
情况3:成功把值增加到对应的Cell
java if ((as = cells) != null && (n = as.length) > 0) { //省略讲过的代码。。。 // 成功把值增加到对应的cell else if (a.cas(v = a.value, ((fn == null) ? v + x : fn.applyAsLong(v, x)))) //自旋结束 break; 这里出现了自旋退出的另外一个情况,那就是当前线程成功把增加的值设置到其对应的cell单元格,这时候结束自旋,很合理。
这里出现了一个
fn指的是调用当前方法传入的LongBinaryOperator是一个函数式接口。LongAdder的add方法默认传入的是空,会执行v + x也就是增加cell单元格的值,这个LongBinaryOperator在LongAccumulator使用到,后续我们看下java @FunctionalInterface public interface LongBinaryOperator { long applyAsLong(long left, long right); } -
情况四:对Cell数组进行扩容
如果并发实在是太大了,Cell数组单元格的数量已经容纳不下这么多线程一起执行了,那么为了避免想
AtomicLong一样无脑自旋,浪费CPU,这时候会选择对Cell数组进行扩容。java if ((as = cells) != null && (n = as.length) > 0) { //省略讲过的代码。。。 //==========代码点1(后续解析中会使用到)============== //collide 表示扩容的意向,为true并不代表一定会扩容 //如果cell数组的长度大于了jvm可以使用的核心数 或者cells数组引用改变了 else if (n >= NCPU || cells != as) collide = false; //==========代码点2(后续解析中会使用到)============== else if (!collide) collide = true; //拿到cellsBusy这把锁 else if (cellsBusy == 0 && casCellsBusy()) { try { //判断下cells引用没有改变 //==========代码点3(后续解析中会使用到)============== if (cells == as) { //扩容 扩大1倍 Cell[] rs = new Cell[n << 1]; for (int i = 0; i < n; ++i) rs[i] = as[i]; //改变cells应用指向 cells = rs; } } finally { //释放锁 cellsBusy = 0; } //扩容意向为false collide = false; continue; } //rehash probe h = advanceProbe(h); } 这里有意思的点有
-
(n >= NCPU || cells != as)如果cell数组长度已经大于等于jvm可以使用的cpu核心数了,或者cells引用指向改变了,那么扩容意向设置为false,然后执行advanceProbe对当前线程的probe进行rehashjava线程模型的学习笔记中,我们指出,java线程和操作系统是一对一模型,我理解这里一个cpu核心执行在一个时刻运行一个线程,所以cells数组太大也没什么用。那么为什么
cells != as成立也是进行rehash probe然后继续自旋昵,这里可以理解为当前线程尝试对它对应的cell单元格进行cas操作,但是失败了,这个时候发现cells != as说明有其他线程对当前cell数组进行了扩容,从而改变了cells数组的引用指向(as是就的cells数组)为了防止多次扩容,这个时候就设置以下扩容意向为false 然后让当前线程“从卷java,转变为卷Go”换一个并发不那么高的Cell数组单元格进行cas操作。 -
代码点2进入到这里的情况有(a = as[(n - 1) & h]) == null但是被其他线程初始化了对应位置的Cell,cas设置对应cell失败,cell数组已经达到jvm可用cpu,当前线程执行的途中没有其他线程完成扩容。但是当前还是无法在自己对应的cell上成功进行cas,说明和其他线程发生了冲突,这个时候让当前线程rehash以下probe然后再次自旋一次,如果还是无法在自己对应的cell进行cas操作,且没有发生扩容的话会来到下面的3 -
拿到锁,对cell数组进行扩容,进入这里,说明没有其他线程进行扩容,当前线程对应的cell不为null,但是对cell进行CAS操作还是失败。这时候为了提高性能只能牺牲一点空间了,进行扩容。有意思的点在于
代码点3,为什么在这里还是需要进行一次判断昵,因为cellsBusy == 0 && casCellsBusy()这两个操作不是原子的,可能cellsBusy == 0执行完失去了时间片,这时候有一个老六进行了扩容,改变了cells数组引用指向,并且释放了锁,这时候如果不做这个判断,可能导致cell数组元素的丢失。后续就是对cells进行扩容,然后释放锁,设置扩容意向为false,然后continue,注意这个continue,这会导致当前线程不会执行advanceProbe,为什么昵,哥们都扩容了,你现在让我换个格子,那我为啥要扩容,属于是“Java太卷,但是我命由我不由天,为自己创造岗位”,后续这个线程进行自旋的时候随机到的Cell数组可能还是原来的,可能是原来位置加上当前cell数组长度的一半,但是还是可以把一些“竞争者”分散开了
-
B.当前Cell数组没有初始化,当前线程进行初始化
java else if (cellsBusy == 0 && cells == as && casCellsBusy()) { //是否完成了初始化 boolean init = false; try { //==========代码点1(后续解析中会使用到)============== //确认没有其他老六抢先初始化 if (cells == as) { // 初始化 Cell[] rs = new Cell[2]; //选择一个格子 设置为x,probe奇数那么选择rs[1] 反之rs[0] rs[h & 1] = new Cell(x); cells = rs; init = true; } } finally { //释放锁 cellsBusy = 0; } //如果成功初始化 那么结束 if (init) break; } -
这里有意思的点,在代码点1还是会进行cells == as的判断,这是由于cellsBusy == 0 && cells == as && casCellsBusy() 并不是一个原子操作,可能存在其他线程,抢先初始化cell数组,所以需要再次判断以下。这里我们可以看到初始化的cell数组大小为2,后续都是扩大一倍
C.Cell没有初始化,但是当前线程尝试初始化失败,尝试操作base值
来到这里,说明A和B都是不成立的,也就意味着,当前线程进来的时候发现cell没有初始化,然后来到B,但是cellsBusy == 0 && cells == as && casCellsBusy()发现不成立,不成立的情况有
cellsBusy == 0不成立,说明之前有线程已经拿到锁了,正在初始化cells == as不成立,有一个线程已经完成了初始化,导致cell引用指向改变casCellsBusy()不成立,竞争锁的过程中失败了
这个时候会让当前线程尝试更新下base值,说不定很多线程都在尝试更新cell元素,这个时候更新下base 可能也许会成功。
4.1.3.5 sum
没什么好说的,强于doug lea也只能保证最终一致性,显然如果存在其他线程并发add的时候,这个方法只能拿到快照数据
4.1.3.6 reset
没什么好说的,线程不安全,如果存在其他线程add,这时候调用reset,可能导致并没有reset成功,或者说如果其他线程扩容到一般,调用reset,那么reset也会不成功。还有一点是reset并不会改变cell数组大小
4.1.3.7 sumThenReset
求和并设置为0并不会改变cell数组大小。
4.2 LongAccumulator
大致和LongAdder类似,LongAccumulator需要指定如何如果操作 ——LongBinaryOperator(旧值没有冲突时时base,冲突时是cell,accumulate传入的值)
4.2.1 accumulate
4.2.3 get
这一这里返回的值,不是进行累加而是function.applyAsLong(result, a.value)取决于你定义的操作——LongBinaryOperator
4.3 DoubleAdder 和DoubleAccumulator
和LongAdder 与LongAccumulator 类似,但是是通过把Double转换成Long调用doubleAccumulate来完成的
五.缓存伪共享
我们在解析LongAdder源码的时候看到 Striped64中的Cell类上面存在一个@sun.misc.Contended 的注解,我们说这是为了反正缓存伪共享,下面我们聊下啥是缓存伪共享
1.什么是伪共享
缓存是由缓存行组成的,通常一个缓存行是 64 字节,在程序运行的过程中,缓存每次更新都从主内存中加载连续的 64 个字节。因此,如果访问一个 long 类型的数组时,当数组中的一个值被加载到缓存中时,另外 7 个连续的元素也会被加载到缓存中,地址上不连续的就不会加载到同一个缓存行了。这种免费加载也有一个坏处。设想如果我们有个 long 类型的变量 a,它不是数组的一部分,而是一个单独的变量,并且还有另外一个 long 类型的变量 b 紧挨着它,那么当加载 a 的时候将免费加载 b。如果一个 CPU 核心的线程在对 a 进行修改,另一个 CPU 核心的线程却在对 b 进行读取,当前者修改 a 时,会把 a 和 b 同时加载到前者核心的缓存行中,更新完 a 后其它所有包含 a 的缓存行都将失效,因为其它缓存中的 a 不是最新值了,而当后者读取 b 时,发现这个缓存行已经失效了,需要从主内存中重新加载。这就很坑爹了,我只是想更新a,但是却让有效的b无效了。
2.解决伪共享的办法
2.1填充无用字节
只要我填一些无用的字节,在a和b之间,让a和b不在一个缓存行中就解决了这个问题,但是现在虚拟机很聪明,会对我们手动填充的无用字节进行忽视
2.2 使用@sun.misc.Contended
这也是一种填充无用字节的做法,但是是jvm帮我填充。
如下Long1这个类标注了@sun.misc.Contended我们在启动的jvm的时候加上 -XX:-RestrictContended 对比不加 @sun.misc.Contended注解的时候,其实有很大的差别(几个数量级的差距)
3.为什么Cell要加@sun.misc.Contended
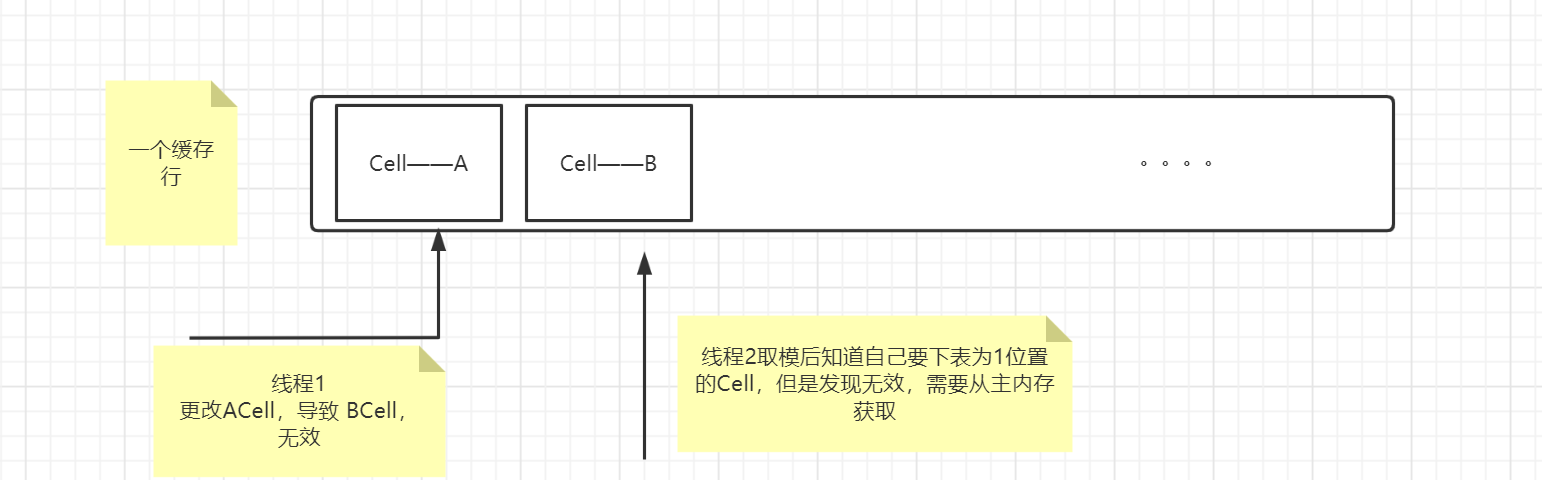
如果使用@sun.misc.Contended那么ACell 和BCell不在一个缓冲行,就不会发生这样的情况了,从主内存加载数据到缓存还是需要消耗一定时间的。
__EOF__
