-
C++类和对象【上】
面向对象和面向过程
C语言是面向过程的,关注的是过程,分析求解问题的步骤,通过函数调用逐步解决问题
C++是基于面向对象的,关注的是对象,将一件事情拆分成不同的对象,靠对象的交互完成
C++不是纯面向对象的,因为兼容C,所以可以面向对象和面向过程混合
二者区别:(以外卖点餐系统为例)
面向过程:主要考虑点餐、接单、送餐的过程(函数实现)
面向对象:主要考虑买家、卖家、骑手等对象(对象存在一定的属性和方法)
类的引入
在C语言中描述一个复杂对象用结构体 struct
但是结构体中只能定义变量 具体的功能,比如数据结构栈 的push和pop功能,需要额外定义函数
但是在C++中,struct得到了升级(升级成了类),不仅可以定义变量还可以在struct中定义函数。也就是说,同一个栈在C++中用可以把push和pop等功能放在struct内部定义
也就是说 C++中struct可以包含两个东西
成员变量成员函数
并且在C中,函数名字受具体数据结构的限制
如栈的push:
StackPush
队列的push:QueuePush在C++中升级后的struct完全不用考虑,因为只需要把函数定义在不同的struct中即可,栈的push函数就叫push, 只不过定义在Stack这个struct中,由于域的限制,不会冲突
并且在C++中,struct由于升级成了类,类直接可以做类名
C中定义结构体:
struct Stack stC++中定义:
Stack st(类名可以直接做类型)总结一句就是,C++的struct兼容C的使用语法,同时把struct升级成了类(类名直接可以做类型),且类中可以定义成员函数
类的定义以及作用域
C++中虽然对struct进行了升级,struct变成了类,但是C++中并不怎么使用它,相比struct,class更贴合"类"这个名称。所以C++中更为官方的类 用 class定义
class className { // 类体:由成员函数和成员变量组成 }; //注意一定要有分号!- 1
- 2
- 3
- 4
class : 定义类的关键字
className:类的名字
{ } 内部为类的主体 ,包括成员变量和成员方法
类定义了一个新的作用域,在
{}内部就是类的作用域,类的所有成员都在类的作用域中。在类体外定义成员时,需要使用
::作用域操作符指明成员属于哪个类域访问修饰限定符和封装
访问限定符
现在我们知道了,类里面可以定义成员变量和成员函数
但是,有时候我们并不想暴露成员变量,如果外部需要访问,我们只是提供对外接口即可。因此也就有了访问修饰限定符
访问修饰限定符:限制类外部对类内成员的访问权限,针对的是类外

其中:
public修饰的成员在类外可以直接被访问protected和private修饰的成员在类外不能直接被访问注意
-
某一个访问限定符的作用范围是: 从该访问限定符出现的位置到遇到下一个访问限定符出现为止
-
如果某一个访问限定符后面没有出现其他访问限定符,那么作用域就到
}结束 -
class的默认权限为
private,而struct为public(因为要兼容C的语法)
注意:一般我们都把成员变量设置为private
封装
什么是封装?
封装:将数据和操作数据的方法进行有机结合,隐藏对象的属性和实现细节,仅对外公开接口来和对象进行交互
说人话就是一种管理,对于类来说就是把不想让你直接访问的数据用private和protected修饰起来,这样在类外面就没有权限访问这些数据了。 如果外部需要用到说这些数据,只提供相关的接口让外部可以使用这些数据,这些接口用public修饰,所有人都能访问
封装的好处
- 保护想要封装的对象或者数据。需要保护的数据外部是不可以直接访问和修改的,只可以通过接口拿到相关数据进行使用而不能直接接触,这样就保护了核心数据
- 方便调用者使用。对于内部数据的结构的实现,用户可能并不清楚,比如对于栈来说要取栈顶元素。假设用数组实现,如果暴露数组给外部,用户可能以
arr[top]的形式来获取栈顶数据,但是top不一定指的就是栈顶元素,可能是栈顶数据的下一位(具体需要看栈实现的逻辑设计)。而直接提供一个对外接口getTop让用户使用,就不会出现问题,并且还简化了用户的使用。
就比如一个电脑,核心的电路元件CPU等都被盒子封装了起来,只给你提供几个USB接口,而你简单的使用鼠标、键盘就可以操作使用电脑
并且接触不到CPU等元件,也防止了小白用户由于不懂这些而导致损坏元件的情况
区分声明和定义
//全局变量 int g_val; //定义 class Person { public: //函数定义 void showInfo() { cout<<_name<<endl; cout<<_age<<endl; } private: char _name[20];//声明 int _age;//声明 }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 成员变量都是声明,没有开辟空间(就像strcut中的成员,并没有开辟空间)。当用类名作为类型去定义变量的时候,才会给成员变量开辟空间
- 全局变量不初始化就是定义,因为会全局变量会默认开辟空间并初始化为0
类的两种定义方式
类有两种定义方式:
- 声明和定义都在类里面定义
- 声明放在.h文件,类的定义放在.cpp文件
1. 声明和定义都在类里面定义
如下图所示,声明和定义都放在类的内部

注意:
如果成员函数直接在类中定义,那么编译器默认把函数当作
inline,也就是说,默认给函数提了一个建议,如果函数展开汇编指令之后规模较小(一般是满足函数小于10行左右)。那么该函数就是内联函数,在调用的地方直接展开2. 声明和定义分离
函数声明放在类里面,函数的定义放在其他的.cpp文件中。
这样有什么好处呢?
因为声明比较简短,这样可以直接让我们看到类中都有什么,了解类的大框架
如图所示:

注意
-
在.cpp文件中进行定义的时候,需要添加
类名::来访问类域,定义函数的时候,函数内部使用的变量也会自动去类中寻找。如果不加类名来表明类域,就会找不到(出现报错) -
声明和定义分离,意味着所有的函数不可以是内联。因为内联在声明和定义分离的时候会出现链接错误!
3. 总结
- 一般把较短的、频繁调用的函数直接放在类中直接定义,使其成为内联函数,减小函数栈帧开销
- 较长的函数,声明和定义分离。有利于观察类的框架
类的实例化
- 类名就是一个类型,当使用这个类型去创建变量的时候,就叫做类的实例化。一个类相当于一个模板,可以创建很多的对象,每个对象都有成员变量。
把类比作人类,那么对象就是一个个人,人类的属性每一个人也会有
-
类并没有分配实际空间来存储,实例化出的对象才会分配空间
-
不能直接用类来访问成员变量,如下
int main() { Person._age=30; return 0; }- 1
- 2
- 3
- 4
- 5
-
虽然类不占用空间,但是可以利用
sizeof(类名)计算出类的大小实际上计算出的是类创建出的对象的大小
类的大小
类的存储方式探讨
类中既可以有成员变量,又可以有成员函数,那么一个类的对象中包含了什么?那么类的大小如何计算呢?
最开始设计的时候是有三种选择的
-
对象中包含类的成员变量和成员函数
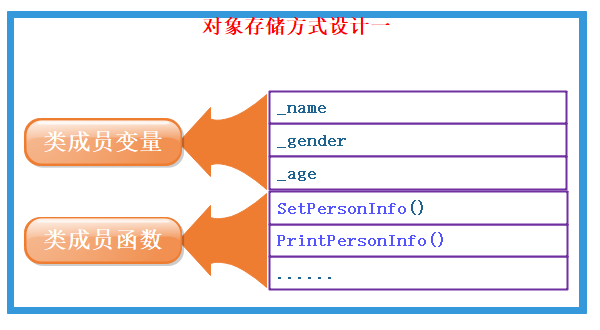
这中设计中,每一个对象的成员变量都是独立的,同样代码每一个对象都有一份,但是成员函数是相同的,比如
showInfo函数是为了打印成员变量,显然只需要有一份即可。但是此种模式,当一个类创建多个对象的时候,每一个对象都保存一份代码,相同的代码多次保存显然浪费了进空间 -
代码只保存一份,在对象中保存存放代码的地址

类函数表地址就是一个函数数组指针,该指针指向的数组数组里面存放了成员函数的地址,可以根据这个指针来调用成员函数
但是最后没有使用这种方法,因为调用的时候还需要 先访问表地址这个成员变量,再利用指针去额外指向成员函数
-
对象只保存成员变量,成员函数存放在公共的代码段
C++遵循这一种方式

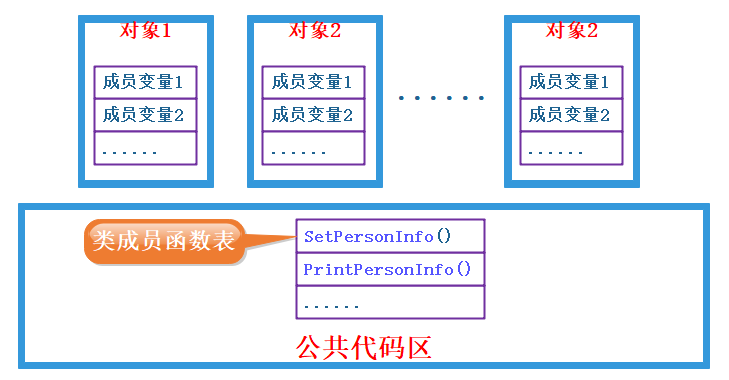
这种模式中,成员函数放在公共代码区。
这种设计使得,在编译链接的时候,就根据函数名去公共代码区加载出来函数的地址,成员函数调用的地方就已经换成了函数的地址,这样当运行的时候,根本不需要去对象中找,直接call即可。如:
class A { public: void PrintA() { cout<<_name<<endl; cout<<_age<<endl; } private: char _name[20]; int _age; }; int main() { A aa1; A aa2; aa1.PrintA();//调用成员函数 aa2.PrintA();//调用成员函数 return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21

而之所以使用
对象.成员函数这样去调用,一是因为类域的限制,这个函数是属于这个类域的,访问受到限制,并且要去这个类相关的公共代码区域去找函数的地址。所以对象.的作用就类似于访问限定符二是因为this指针问题
所以就存在这样一个问题:
int main() { A* ptr = nullptrl; ptr->PrintA();// 此时并不会报错 return 0; }- 1
- 2
- 3
- 4
- 5
- 6
这里存在空指针的解引用? 为什么不会崩溃呢?
这是因为,成员函数并没有存放在对象里面,在公共代码区,
编译的时候就确定要call的函数地址了,所以它根本不会真的解引用去对象里面寻找函数。
看一下汇编:

可以看到,直接是调用的地址,没有进行解引用
类的大小计算
由上面存储方式的探讨可知道,一个对象中只存在成员变量
成员函数放在公共代码区。
所以对象(类)的大小也就是只计算成员变量
注意:对象的大小遵循结构体对齐的规则
而类的大小其实就是实例化出的对象的大小,即sizeof(类) == sizeof(对象),因为类就相当于一个类型,如int类型4个字节
仅有成员函数的类 和 空类的大小
// 仅有成员函数的类 class A1 { public: void PrintA1() {} }; //空类 -什么都没有 class A2 {};- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
这两种类中比较特殊:类没有成员变量
但是如果把这种类的大小设置成0,那么其实是不合理的,因为这样实例化出来的对象的大小是0,而我们知道 不论是变量还是对象,其本质就是开辟了一块内存,里面存放着一些数据,并且存在其对应的地址。
所以一个大小为0的对象似乎不太合适,0已经说明其不存在了,也就没有地址,所以给空类一个1字节的大小,用来占位,不存储数据。来标识这个类创建的对象是存在的
this指针
什么是this指针
先看这样下面两个问题
class Date() { public: //初始化函数 void Init(int year,int month,int day) { // 给对象的成员变量赋初始值 year=year; month=month; day=day; } private: int year; int month; int day; }; int main() { Date d1,d2; d1.Init(2022,8,5); d2.Init(2022,8,6); return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
问题1
上面这段代码中,可以看到
year=year等语句感觉就很别扭,虽然说成员变量和形参并不一样,但是其名字相同,给人的感觉就是错的。
其实上面这段代码是没问题的,可以编译通过
不过编译器是怎么区分的呢?
问题2
main函数中定义了两个Date对象,d1和d2
然后d1和d2都调用了Init函数,而Init作为成员函数函数只有一个
当d1调用Init函数的时候,该函数是怎么知道要设置d1而不是设置d2呢?
实际上,在C++中,C++编译器给每一个 非静态的成员函数 增加了一个隐藏的指针参数,让该指针指向当前对象(函数运行时调用该函数的对象),在函数体中所有的 成员变量 的操作,都是通过这个指针来访问。但是这个指针对于用户是透明的,用户无法看到并且用户也不能自己来传递,编译器自动完成这个工作。
这个指针就叫做:this指针
如下图所示:

所以,this就可以用来区分给哪一个对象调用成员函数
并且当成员变量的名字和形参的名字一样时也不会报错
关于成员变量的命名
上面的问题中存在
year = year的问题在编译器看来其实是
this->year = year并没有太大问题但是对于我们来说,看的时候就比较不友好了
所以一般命名规则是:成员变量的前面加一个
_即:
private: int _year; int _month; int _day;- 1
- 2
- 3
- 4
诸如这样,来区分成员变量和普通变量的区别
this指针的特性*
- this指针的类型是 : 类类型* const, 也就是说this是固定死的,this指针不能改变(不能给this赋值),但是this指针指向的内容可以改变
- this指针本质上是一个形参,当调用成员函数的时候由编译器默认传递,由于是形参所以对象中并不存储this指针
- this指针只能在成员函数的内部使用
- this指针永远是成员函数的第一个隐含形参,一般由编译器通过寄存器ecx传递,不需要用户传递
- 在成员函数内部,用户可以显示写
this->成员变量,也可以直接写成员变量,不写编译器实际上在编译的时候会自动加上 - this指针是形参一般存放在栈上,但是有些编译器会进行优化,即把this放到寄存器中,因为this可能是使用频繁的(比如成员变量很多的时候),所以利用寄存器可以提高访问速度。
this指针为空时调用成员函数
由上面可以知道,调用成员函数的时候其实是存在一个this指针的
那么如果this为空呢?
class A { public: void Print1() { cout<<"Print()"<<endl; } void Print2() { cout<<_a<<endl; } private: int _a; } int main() { A* p = nullptr; p->Print1();//情况1:会报错吗? p->Print2();//情况2:会报错吗? return 0; } // 情况1:正常运行 // 情况2:运行崩溃- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
p是空指针,在调用Print1()函数和Print2()函数的时候
p作为隐含的参数传进去
但是Print1()函数中,虽然有空指针this,并没有利用this指针进行解引用,正常运行
但是在Print2()函数中,访问了成员变量,通过
this->进行了解引用,所以就会崩溃总结
this可以为空,但是this为空的时候,不能访问成员变量
-
相关阅读:
QtService实现Qt后台服务程序其一_基本使用步骤
HTTPS基础原理和配置-2
【Python Web】Flask框架(九)MYSQL+python案例
计算一串输出数字的累加和
干洗店预约下单管理系统收衣开单拍照必备软件
0070__Postman如何导出接口的几种方法
【Redis】hash数据类型-常用命令
【COSBench系列】1. COSBench认识、使用、结果分析
国庆作业 10月1 用select实现服务器并发
用R语言实现神经网络预测股票实例
- 原文地址:https://blog.csdn.net/K_04_10/article/details/126201522
