-
机器学习——聚类算法
11. 聚类算法
文章目录
使用不同的聚类准则,产生的聚类结果不同11.1 现实应用
-
用户画像,广告推荐,Data Segmentation,搜索引擎的流量推荐,恶意流量识别
-
基于位置信息的商业推送,新闻聚类,筛选排序
-
图像分割,降维,识别;离群点检测;信用卡异常消费;发掘相同功能的基因片段
11.2 概念
一种典型的无监督学习算法,主要用于将相似的样本自动归到一个类别中
11.3 聚类算法与分类算法最大的区别
聚类算法是无监督的学习算法,而分类算法属于监督的学习算法
11.4 API
11.4.1 sklearn.cluster.KMeans(n_clusters=8)
-
n_clusters:开始的聚类中心数量
- 整型,缺省值=8,生成的聚类数,即产生的质心(centroids)数
11.4.2 方法
- estimator.fit(x)
- estimator.predict(x)
- estimator.fit_predict(x)
11.5 聚类算法实现流程
11.5.1 k-means其实包含两层内容
- K : 初始中心点个数(计划聚类数)
- means:求中心点到其他数据点距离的平均值
11.5.2 k-means聚类步骤
-
- 随机设置K个特征空间内的点作为初始的聚类中心
-
- 对于其他每个点计算到K个中心的距离,未知的点选择最近的一个聚类中心点作为标记类别
-
- 接着对着标记的聚类中心之后,重新计算出每个聚类的新中心点(平均值)
-
- 如果计算得出的新中心点与原中心点一样(质心不再移动),那么结束,否则重新进行第二步过程
由于每次都要计算所有的样本与每一个质心之间的相似度,故在大规模的数据集上,K-Means算法的收敛速度比较慢
11.6 模型评估
11.6.1 误差平方和(SSE \The sum of squares due to error)
-

-
SSE图最终的结果,对图松散度的衡量
-
SSE随着聚类迭代,其值会越来越小,直到最后趋于稳定
11.6.2 “肘”方法 (Elbow method) — K值确定
- 下降率突然变缓时即认为是最佳的k值
11.6.3 轮廓系数法(Silhouette Coefficient)
- 结合了聚类的凝聚度(Cohesion)和分离度(Separation)
- 目的:内部距离最小化,外部距离最大化
11.6.4 CH系数(Calinski-Harabasz Index)
- 目的:用尽量少的类别聚类尽量多的样本,同时获得较好的聚类效果
- 类别内部数据的协方差越小越好,类别之间的协方差越大越好

11.7 算法优化
11.7.1 k-means算法
-
优点
- 原理简单(靠近中心点),实现容易
- 聚类效果中上(依赖K的选择)
- 空间复杂度o(N),时间复杂度o(IKN)
-
缺点
- 对离群点,噪声敏感 (中心点易偏移)
- 很难发现大小差别很大的簇及进行增量计算
- 结果不一定是全局最优,只能保证局部最优(与K的个数及初值选取有关)
11.7.2 优化方法
- Canopy算法配合初始聚类
- K-means++
- 二分k-means
- k-medoids(k-中心聚类算法)
- Kernel k-means
- ISODATA
- Mini Batch K-Means

11.8 特征工程 - 特征降维
降维是指在某些限定条件下,降低随机变量(特征)个数,得到一组“不相关”主变量的过程
11.8.1 方式
-
特征选择
-
数据中包含冗余或无关变量(或称特征、属性、指标等),旨在从原有特征中找出主要特征
-
方法
-
Filter(过滤式):主要探究特征本身特点、特征与特征和目标值之间关联
-
方差选择法:低方差特征过滤
-
删除低方差的一些特征
-
特征方差小:某个特征大多样本的值比较相近
-
特征方差大:某个特征很多样本的值都有差别
-
API
- sklearn.feature_selection.VarianceThreshold(threshold = 0.0)
-
-
相关系数
-
实现方式
-
皮尔逊相关系数
-
反映变量之间相关关系密切程度的统计指标
-
API
- from scipy.stats import pearsonr
-
-
斯皮尔曼相关系数
-
反映变量之间相关关系密切程度的统计指标
-
API
- from scipy.stats import spearmanr
-
-
-
-
-
Embedded (嵌入式):算法自动选择特征(特征与目标值之间的关联)
- 决策树:信息熵、信息增益
- 正则化:L1、L2
- 深度学习:卷积等
-
-
-
主成分分析PCA
-
高维数据转化为低维数据的过程,在此过程中可能会舍弃原有数据、创造新的变量
-
作用
- 数据维数压缩,尽可能降低原数据的维数(复杂度),损失少量信息
-
应用
- 回归分析
- 聚类分析
-
API
-
sklearn.decomposition.PCA(n_components=None)
-
将数据分解为较低维数空间
-
n_components
- 小数:表示保留百分之多少的信息
- 整数:减少到多少特征
-
PCA.fit_transform(X) X:numpy array格式的数据[n_samples,n_features]
-
返回值:转换后指定维度的array
-
-
-
11.9 案例:探究用户对物品类别的喜好细分降维
11.10 算法选择
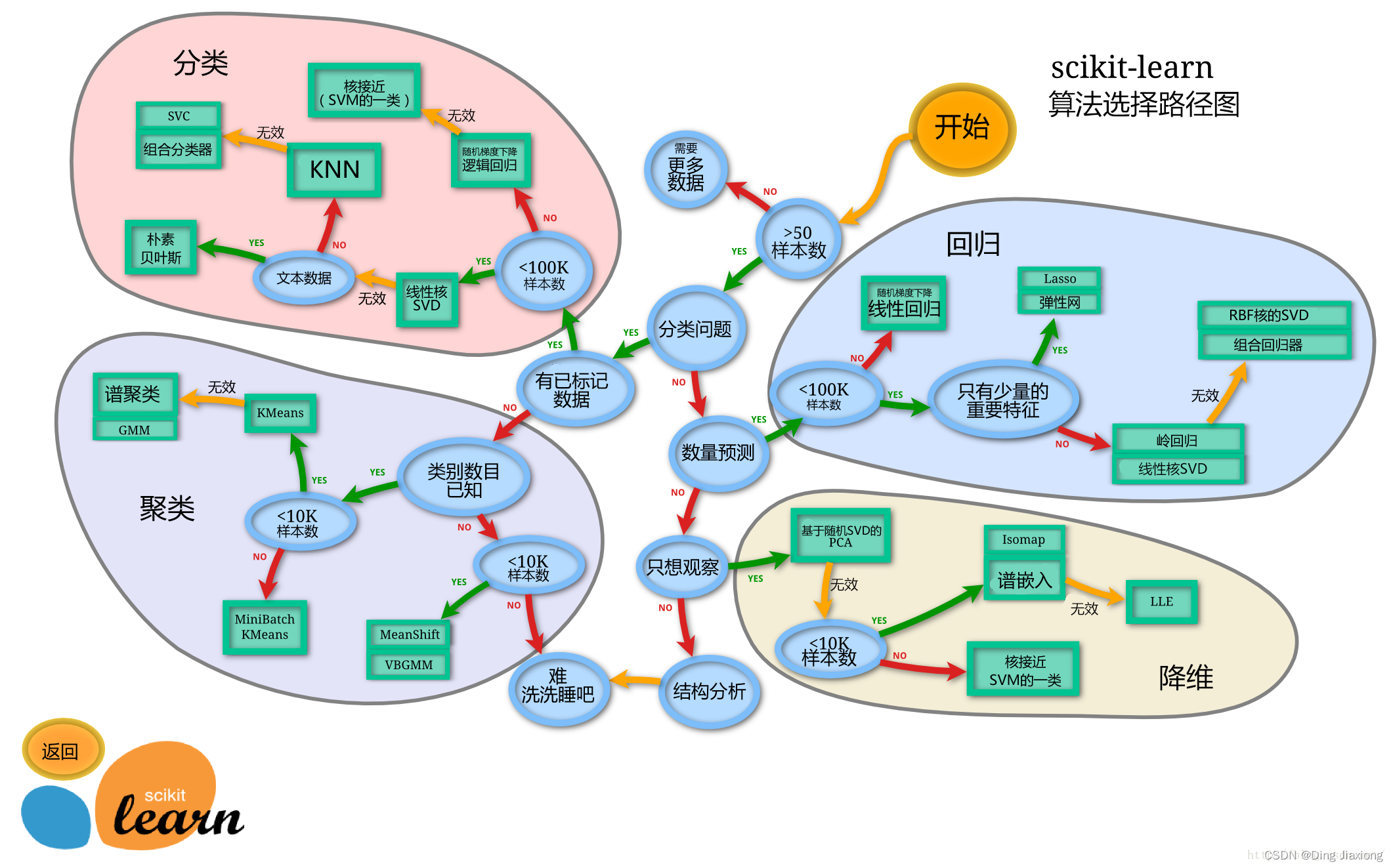
-
-
相关阅读:
硕士论文怎么寻找创新点?
html_语义化标签
自动化测试和测试自动化你分的清楚吗?
Linux软件包和进程管理
开源MyBatisGenerator组件源码分析
2 资源关系 | 到底什么是”局“-- 清华宁向东的管理学课总结
【Linux】——目录结构
ESP32-S2 st7789 SPI TFT彩屏240X320
SpringCloud(8月25号)
达梦数据库使用中遇到的问题和解决方案
- 原文地址:https://blog.csdn.net/weixin_44226181/article/details/126170299