-
Fiddler工具讲解
下载
下载地址:Fiddler
选择classic进行下载,然后在跳转的页面中输入需要的信息即可下载,下载安装包之后双击打开,会弹出同意协议,点击I agree,然后把它安装到本地,安装完成之后,进入它的下载路径,找到 Fiddler.exe,双击运行即可。
可以添加一个桌面的快捷方式,这样下次就方便打开了。
注意:安装的时候杀毒软件要关闭

原理
Fiddler是以代理web服务器的形式进行工作的,它使用的代理地址是127.0.0.1,端口号8888,这是fiddler的默认端口,也就是我们发送的请求都会经过fiddler,这样子,fiddler就可以抓包了。
需要注意的是,如果fiddler非正常退出了,会造成别的网页无法访问,这是因为fiddler没有自动注销,fiddler正常关闭的时候是不会有这种情况的。使用场景
- 需要做接口测试,但是接口文档匮乏。
- 浏览器请求一个页面,查看请求参数是否正确,响应结果是否正确。
- mock:不修改任何环境,修改返回的结果
- 复杂场景:同一域名下的请求,xxx资源发送到ServerA,xxxx资源发送到ServerB上。
界面介绍
主界面分布

辅助工具栏
辅助工具栏中包含了很多操作,具体含义见下图:
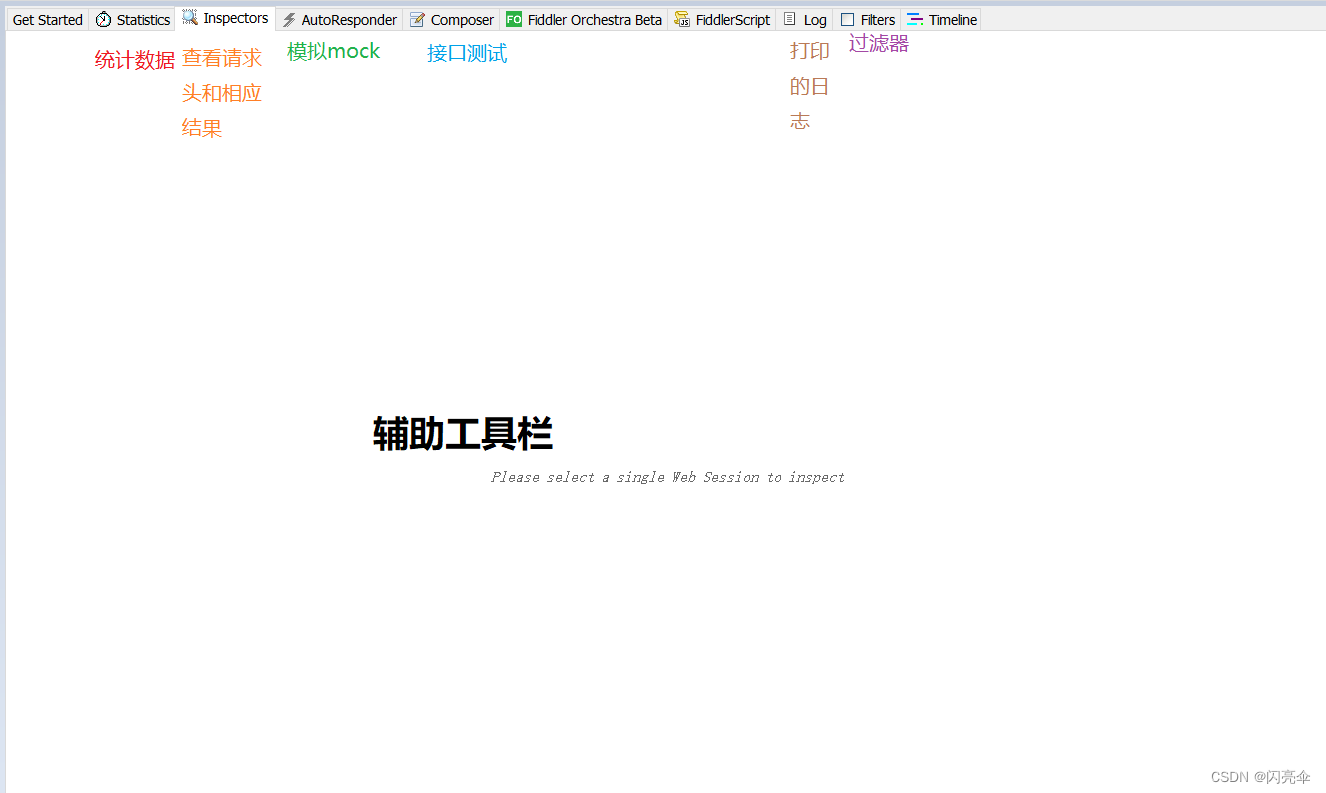
工具条
工具条的每个icon代表的含义如图所示:
其中清空会话列表可以在命令行中输入clear进行清空。

会话列表
- fiddler抓取到的每一个请求(session)
- 主要包含了:请求ID、状态码、协议、主机名、URL、body大小,Caching,内容类型、进程信息、自定义信息。其中Caching解释了内容是来源于服务器还是缓存,

状态栏
黑色的框是输入命令的地方,比如输入
clear就可以清空session列表。
其中断点是可以控制全局的断点。

设置HTTPs
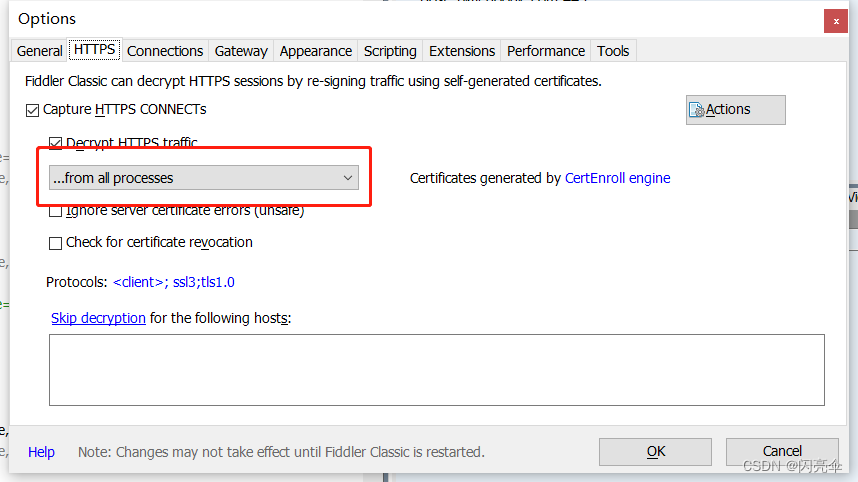
如果我们想要抓取https协议的数据包,就要在fiddler中设置https,否则会抓不到https的数据。
设置方法:在菜单栏中找到Tools,点击options,然后点击到https的tab中去,勾选from all processes
Filters
我们在抓包的时候会抓到很多的数据,但是我们只想要百度这个网站抓出来的数据,我们可以使用过滤器来决定绘画列表显示哪些网站的信息。
设置方法:- 辅助工具栏中找到Filters,点击它
- 就会看到如下所示的页面,选中Use Filters,选择Show only the following Hosts
- 然后把百度的域名放进去
- 点击Actions
- 选择 Run FilterSet Now.

-
相关阅读:
MySQL数据库————数据库语言(DDL与DML)
【EI会议2023】12.20之后ddl
【postgresql】 ERROR: multiple assignments to same column “XXX“
springboot整合datax的使用
了解string以及简单模拟实现(c++)
GraphQL 进阶——DataLoader
备考新境界:考研竞争中的超级助推器,让AIGC点亮你的学术之路!
如何在 Linux 服务器上配置基于 SSH 密钥的身份验证
不要再说你不会了——网络性能问题排查思路
vue+openlayers地图上实现网格线信息显示(附源码)
- 原文地址:https://blog.csdn.net/weixin_43831559/article/details/126089377