-
MindSpore:【mindinsight】【Profiler】用execution_time推导出来的训练耗时远小于真实的耗时
问题描述:
【功能模块】
【mindinsight】【Profiler】
起因是,之前我们模型中最耗时的两个算子是transpose和confusion transpose d:

一个epoch需要979.7s:
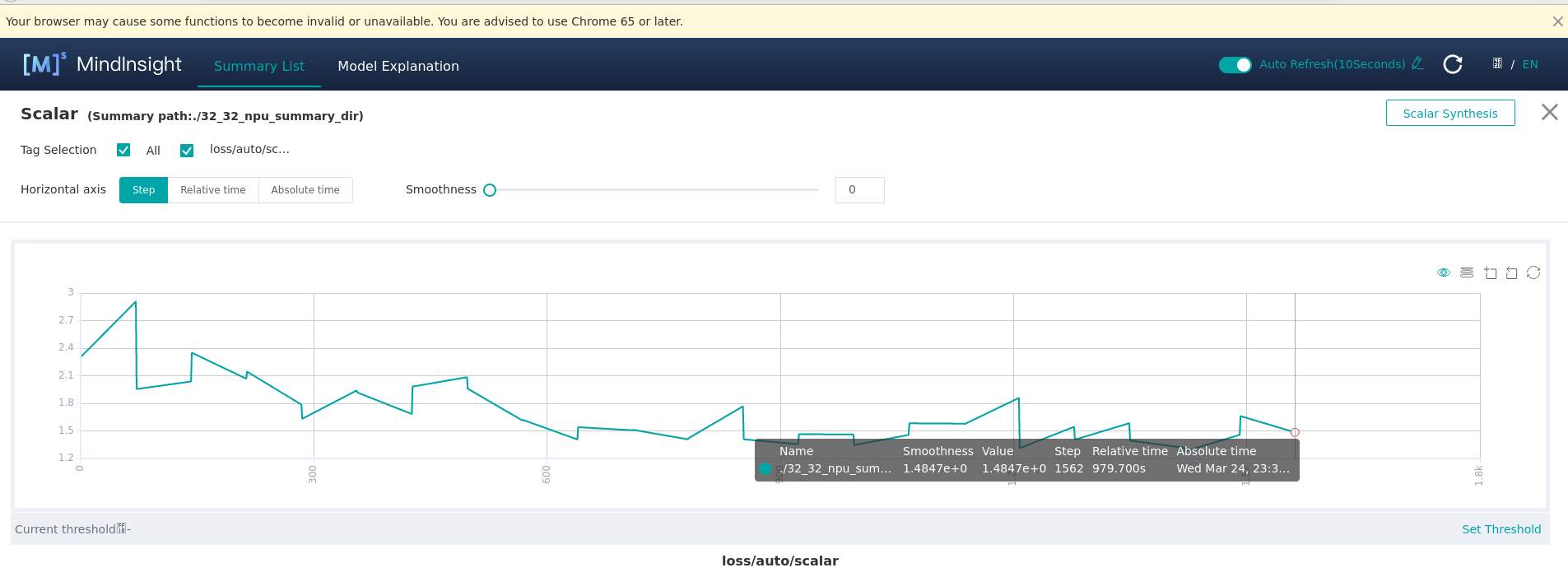
我们进行优化,把transpose和confusion_transpose_d两个算子的耗时优化到可以忽略不计,优化后:
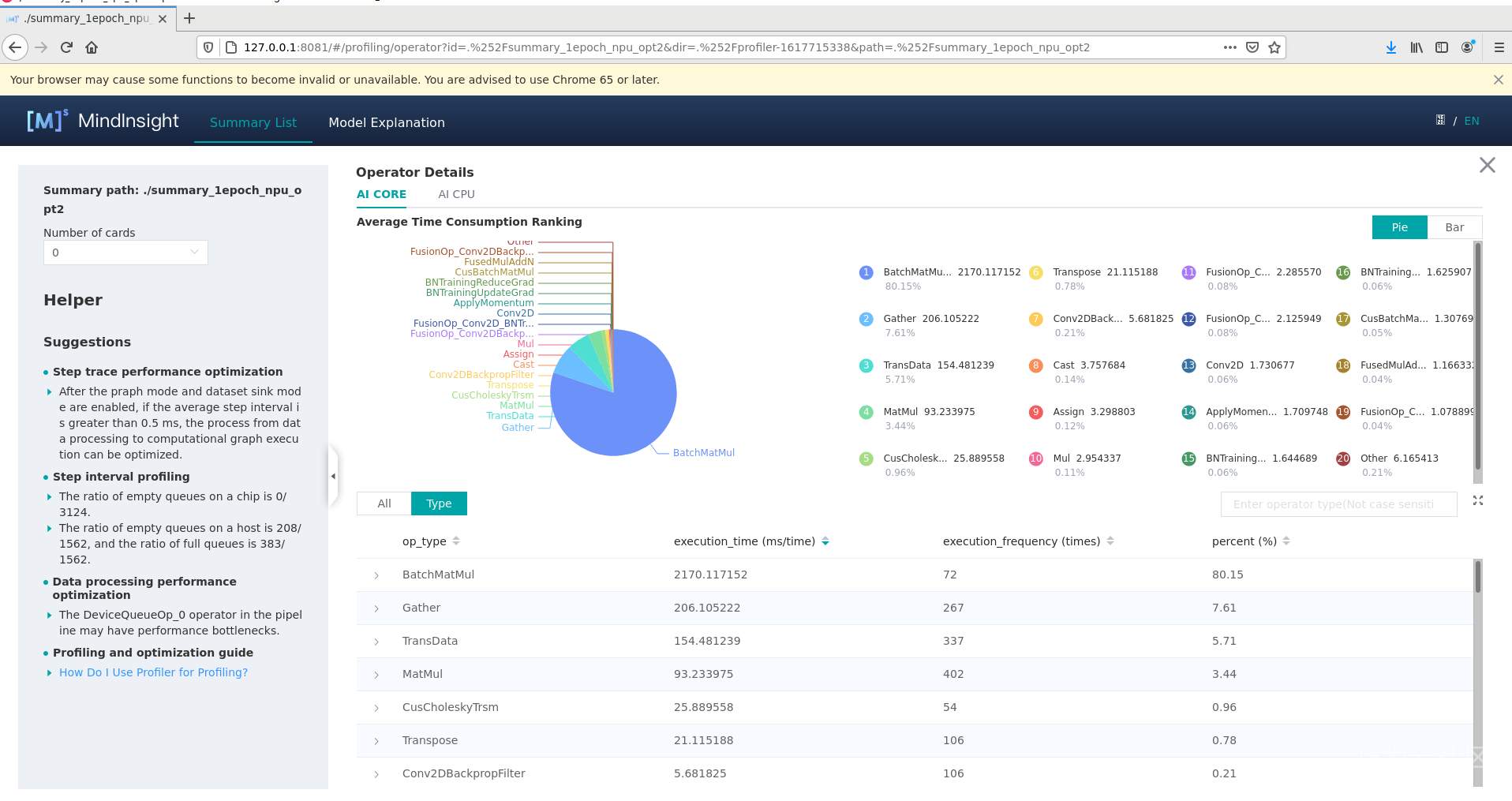
可以看到transpose和confusion_transpose_d两个算子的耗时已经可以忽略不计了,而其他算子的耗时没有明显改变。由于transpose和confusion_transpose_d在优化前的占比达到了91.95%,所以理论上一个epoch的时间应该会缩短到100s左右,但实际上优化后一个epoch仍然需要328s:

所以是否说明每个epoch有228s左右的时间没有被统计到算子的execution_time中?
我们进一步算了一下:
一个epoch是1562个step。由于开启了dataset_sink_mode,更新频率是71,所以execution_time应该是每71个step的总时间?。
优化前:用ConfusionTransposeD算子的耗时计算一个epoch的耗时:execution_time / percent * (1562 / 71) = 22458 / 0.6666 * (1562 / 71) = 741188.119ms ≈ 741s
而实际一个epoch耗时979s,所以有238s的差距
优化后:用BatchMatMul算子的耗时计算一个epoch的耗时:execution_time / percent * (1562 / 71) = 2170 / 0.8015 * (1562 / 71) = 59563.3188ms ≈ 60s
而实际一个epoch耗时328s,所以有268s的差距
也就是说,优化前后,用execution_time推导出来的一个epoch的训练时间,都比真实的训练时间少了两百多秒。而在优化后,这两百多秒已经成为性能的最主要瓶颈。我们想知道其中的原因,以及如何进一步优化训练时间?
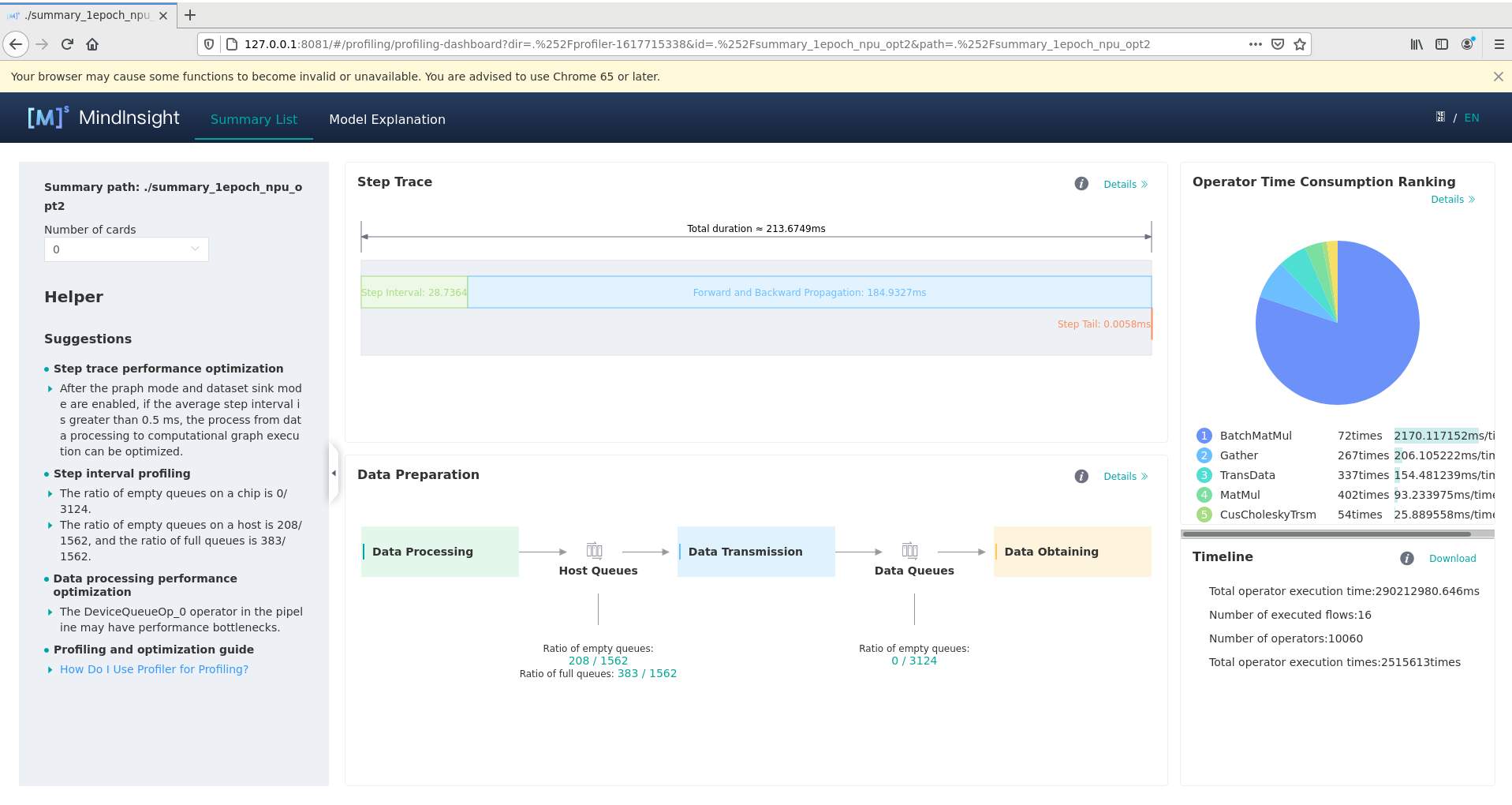
优化前:
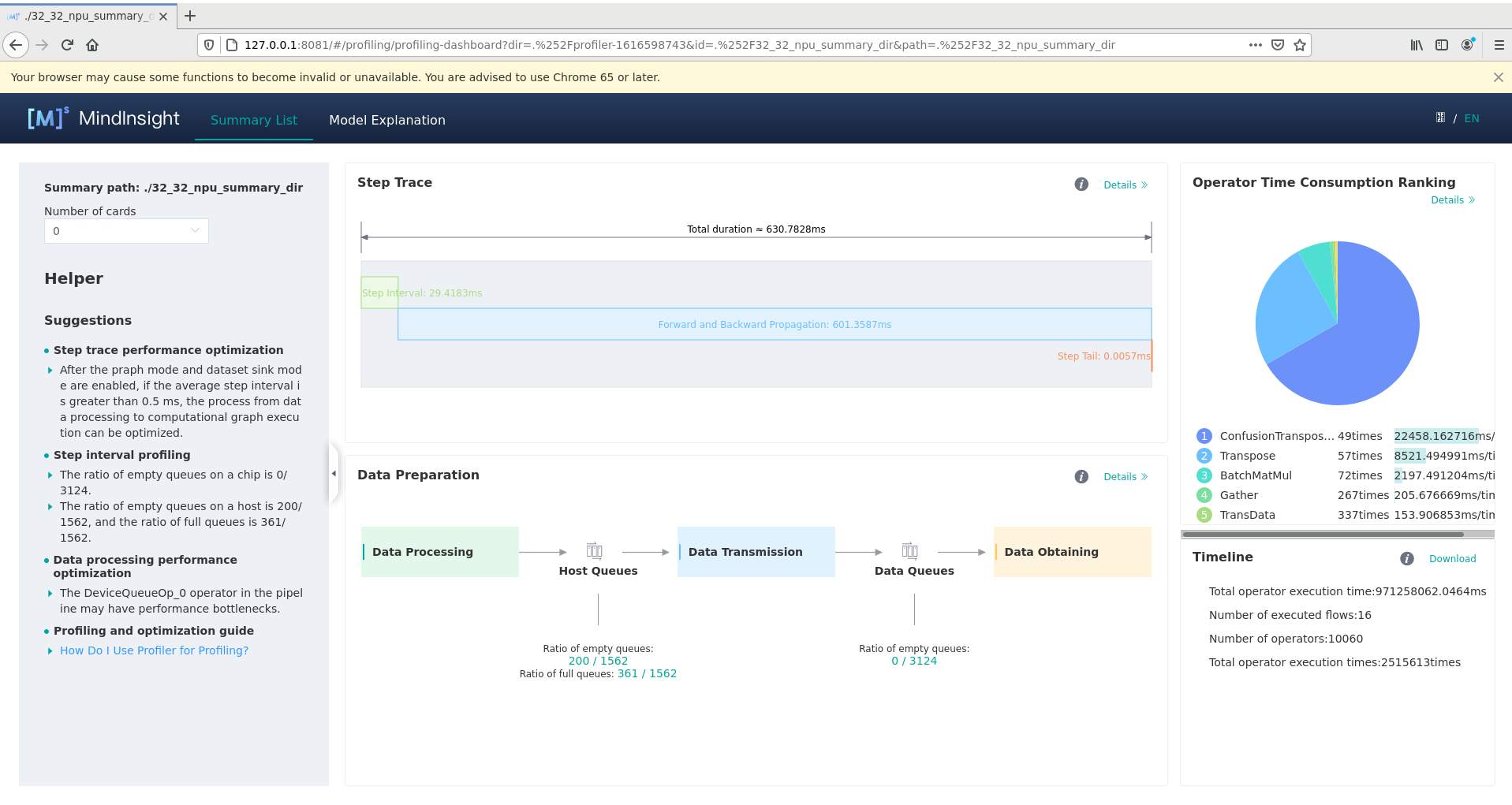
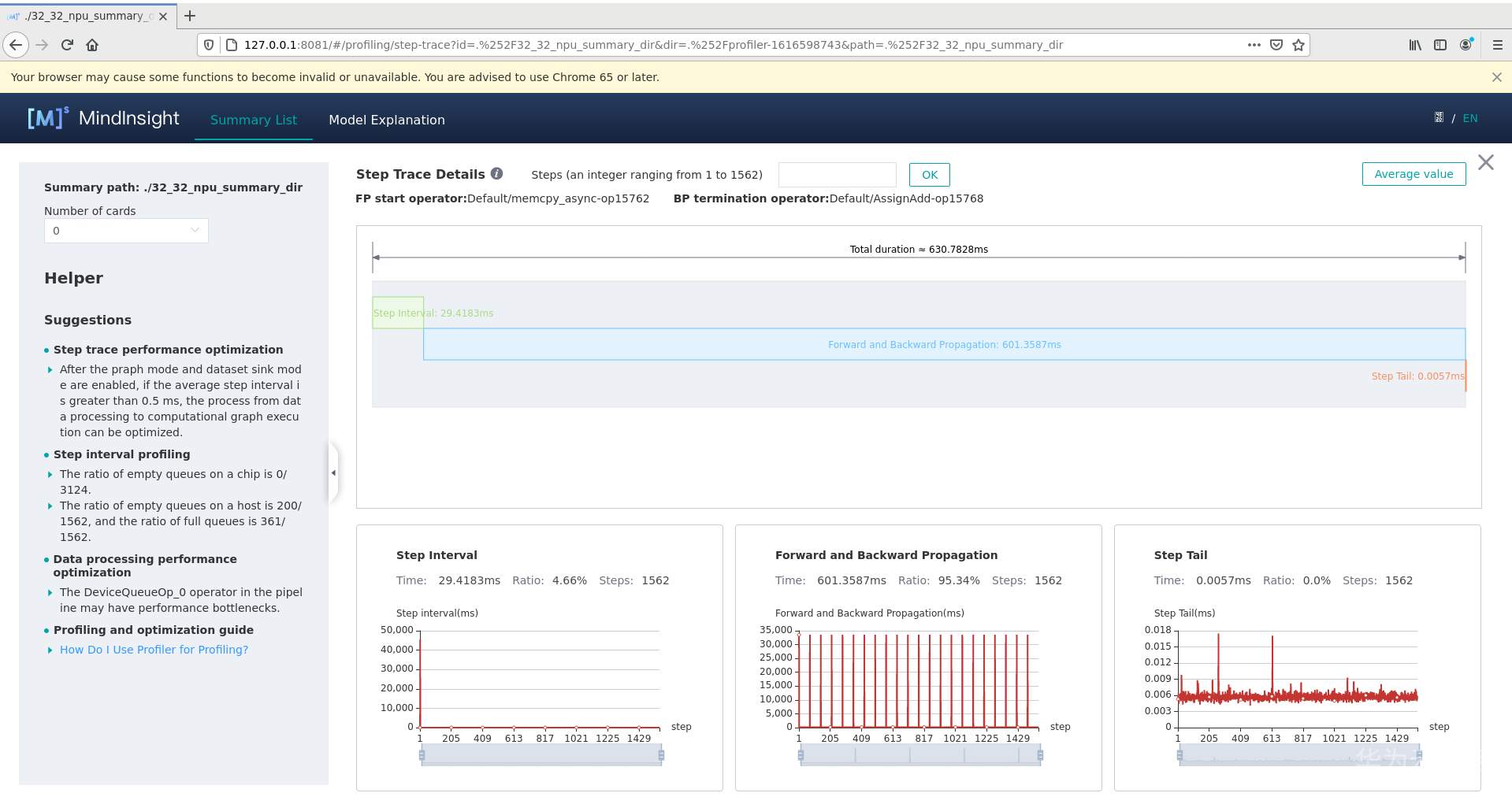
优化后:
解决方案:
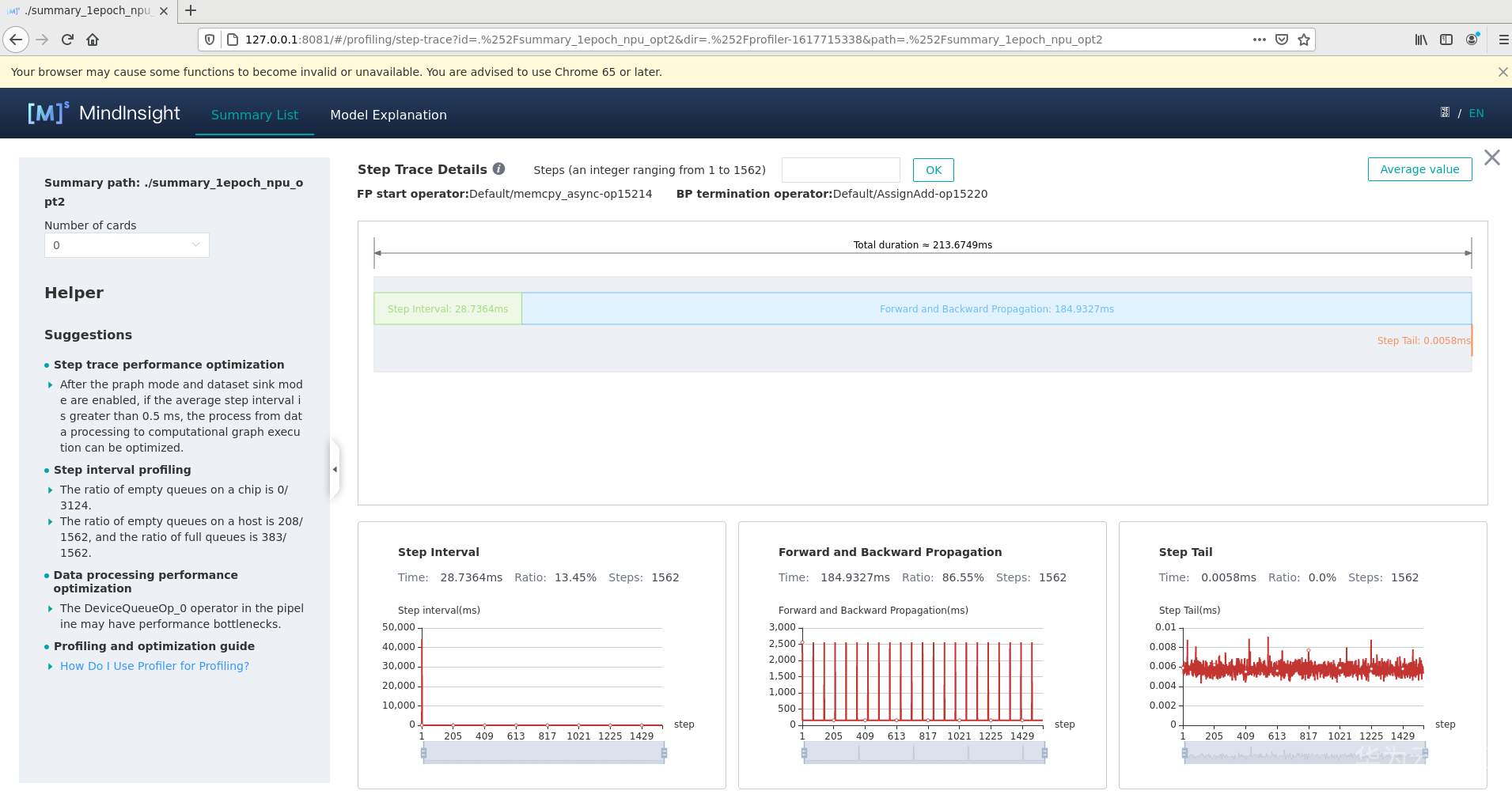
1、通过迭代轨迹看,迭代间隙有28ms左右,即每个step获取数据的时间。
2、迭代轨迹中,前反向耗时除了每个算子的耗时外,还要考虑每个算子的调度间隙,即算子间的空隙是不是比较大。
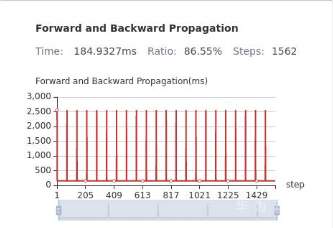
另外,看这个前反向耗时的变化趋势,会有一个周期性的变化,这个要确认下原因是什么导致的。周期性的保存CKPT文件?
-
相关阅读:
pm2:node进程管理工具
VF01销售开票发票金额控制增强
【数据分享】1961—2022年全国范围的逐日降水栅格数据
int 0x13 读取磁盘到内存 Loading Sectors
初识dubbo(随笔)
C++20开发工程师 系列 笔记 环境搭建之gcc12.2(2022/11/30)
北京陪诊小程序|陪诊系统开发|陪诊小程序未来发展不可小觑
Java 性能优化实战案例分析:乐观锁和无锁
以太网基础学习(三)——UDP协议
从Opencv之图像直方图源码,探讨高性能计算设计思想
- 原文地址:https://blog.csdn.net/weixin_45666880/article/details/126149061