-
0基础跟我学python---进阶篇(1)
📢📢📢📣📣📣
哈喽!大家好,我是「奇点」,江湖人称 singularity。刚工作几年,想和大家一同进步🤝🤝
一位上进心十足的【Java ToB端大厂领域博主】!😜😜😜
喜欢java和python,平时比较懒,能用程序解决的坚决不手动解决😜😜😜
✨ 如果有对【java】感兴趣的【小可爱】,欢迎关注我❤️❤️❤️感谢各位大可爱小可爱!❤️❤️❤️
————————————————如果觉得本文对你有帮助,欢迎点赞,欢迎关注我,如果有补充欢迎评论交流,我将努力创作更多更好的文章。
前3片python文章将python的基本知识讲解完了,详细学习完之后,我们就能够写python代码了。如果不熟悉的可以看一下我前面的文章,熟悉的可以跟我学习一下进阶篇。
对python 0基础的同学可以看一下我的上篇文章,再来学习这篇文章,大佬可以直接跳过。
0基础跟我学python(1)
 https://blog.csdn.net/qq_29235677/article/details/125967844
https://blog.csdn.net/qq_29235677/article/details/1259678440基础跟我学python(2)
https://blog.csdn.net/qq_29235677/article/details/1260338800基础跟我学python(3)
https://blog.csdn.net/qq_29235677/article/details/126096024
我们今天学习一下python的进阶篇,学习一下python的CGI编程 和网络编程
目录
⛳️ 1.CGI编程
📓(1)定义
CGI(Common Gateway Interface) 是WWW技术中最重要的技术之一,有着不可替代的重要地位。CGI是外部应用程序(CGI程序)与Web服务器之间的接口标准,是在CGI程序和Web服务器之间传递信息的过程。CGI规范允许Web服务器执行外部程序,并将它们的输出发送给Web浏览器,CGI将Web的一组简单的静态超媒体文档变成一个完整的新的交互式媒体。
Common Gateway Interface,简称CGI。在物理上是一段程序,运行在服务器上,提供同客户端HTML页面的接口。这样说大概还不好理解。
那么我们看一个实际例子:
现在的个人主页上大部分都有一个留言本。留言本的工作是这样的:先由用户在客户端输入一些信息,如评论之类的东西。接着用户按一下“发布或提交”(到目前为止工作都在客户端),浏览器把这些信息传送到服务器的CGI目录下特定的CGI程序中,于是CGI程序在服务器上按照预定的方法进行处理。在本例中就是把用户提交的信息存入指定的文件中。然后CGI程序给客户端发送一个信息,表示请求的任务已经结束。此时用户在浏览器里将看到“留言结束”的字样。整个过程结束。
CGI 目前由NCSA维护,NCSA定义CGI如下:
CGI(Common Gateway Interface),通用网关接口,它是一段程序,运行在服务器上如:HTTP服务器,提供同客户端HTML页面的接口。
绝大多数的CGI程序被用来解释处理来自表单的输入信息,并在服务器产生相应的处理,或将相应的信息反馈给浏览器。CGI程序使网页具有交互功能。
处理步骤
- 1.浏览器通过HTML表单或超链接请求指向一个CGI应用程序的URL。
- 2.服务器收发到请求。
- 3.服务器执行指定CGI应用程序。
- 4.CGI应用程序执行所需要的操作,通常是基于浏览者输入的内容。
- 5.CGI应用程序把结果格式化为网络服务器和浏览器能够理解的文档(通常是HTML网页)。
- 6.网络服务器把结果返回到浏览器中。
网页浏览
为了更好的了解CGI是如何工作的,我们可以从在网页上点击一个链接或URL的流程:
- 1、使用你的浏览器访问URL并连接到HTTP web 服务器。
- 2、Web服务器接收到请求信息后会解析URL,并查找访问的文件在服务器上是否存在,如果存在返回文件的内容,否则返回错误信息。
- 3、浏览器从服务器上接收信息,并显示接收的文件或者错误信息。
- CGI程序可以是Python脚本,PERL脚本,SHELL脚本,C或者C++程序等。asp,php,jsp
CGI程序可以是Python脚本,PERL脚本,SHELL脚本,C或者C++程序等。
📒(2)CGI架构图
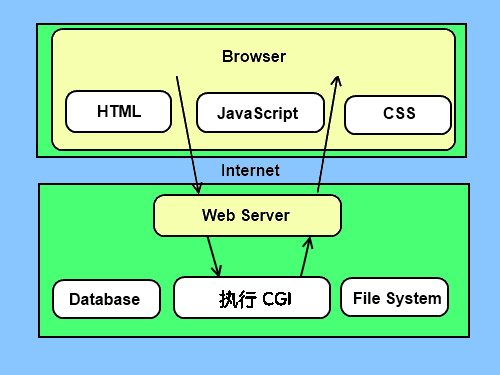
💾(3)Web服务器支持及配置
在你进行CGI编程前,确保您的Web服务器支持CGI及已经配置了CGI的处理程序。
Apache 支持CGI 配置:
设置好CGI目录:
ScriptAlias /cgi-bin/ /var/www/cgi-bin/
所有的HTTP服务器执行CGI程序都保存在一个预先配置的目录。这个目录被称为CGI目录,并按照惯例,它被命名为/var/www/cgi-bin目录。
CGI文件的扩展名为.cgi,python也可以使用.py扩展名。
默认情况下,Linux服务器配置运行的cgi-bin目录中为/var/www。
如果你想指定其他运行CGI脚本的目录,可以修改httpd.conf配置文件,如下所示:
var/www/cgi-bin"> - AllowOverride None
- Options +ExecCGI
- Order allow,deny
- Allow from all
在 AddHandler 中添加 .py 后缀,这样我们就可以访问 .py 结尾的 python 脚本文件:
AddHandler cgi-script .cgi .pl .py第一个CGI程序
我们使用Python创建第一个CGI程序,文件名为hello.py,文件位于/var/www/cgi-bin目录中,内容如下:
- print ("Content-type:text/html")
- print () # 空行,告诉服务器结束头部
- print ('')
- print ('')
- print ('')
- print ('
Hello Word - 我的第一个 CGI 程序! ') - print ('')
- print ('')
- print ('
Hello Word! 我是来自菜鸟教程的第一CGI程序
') - print ('')
- print ('')
文件保存后修改 hello.py,修改文件权限为 755:
chmod 755 hello.py
以上程序在浏览器访问显示结果如下:
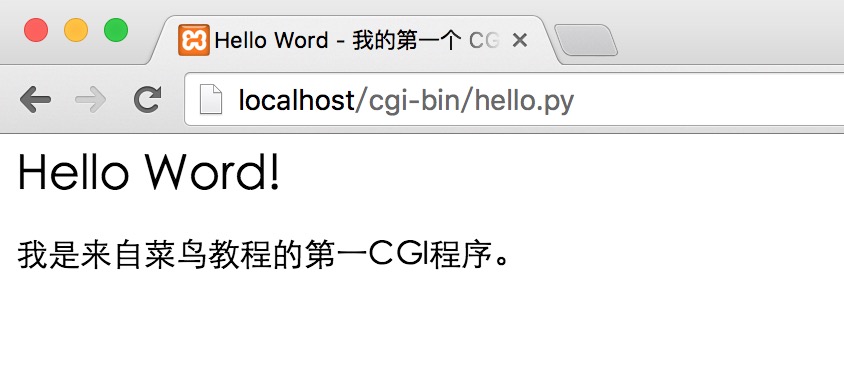
这个的hello.py脚本是一个简单的Python脚本,脚本第一行的输出内容"Content-type:text/html"发送到浏览器并告知浏览器显示的内容类型为"text/html"。
用 print 输出一个空行用于告诉服务器结束头部信息。
⛳️ 2.网络编程
有过其他语言的编程经验的话,网络编程对于大家来说是再熟悉不过的了,同样python也为我们提供了网络编程的方式,接下来我们来看看python是怎么给我们提供网络编程的,都说python简单,那我们看看到底有多么简单

Python 提供了两个级别访问的网络服务。:
- 低级别的网络服务支持基本的 Socket,它提供了标准的 BSD Sockets API,可以访问底层操作系统Socket接口的全部方法。
- 高级别的网络服务模块 SocketServer, 它提供了服务器中心类,可以简化网络服务器的开发。
Socket又称"套接字",应用程序通常通过"套接字"向网络发出请求或者应答网络请求,使主机间或者一台计算机上的进程间可以通讯。
📖(1)socket()函数
Python 中,我们用 socket() 函数来创建套接字,语法格式如下:
socket.socket([family[, type[, proto]]])参数
- family: 套接字家族可以是 AF_UNIX 或者 AF_INET
- type: 套接字类型可以根据是面向连接的还是非连接分为
SOCK_STREAM或SOCK_DGRAM - protocol: 一般不填默认为0.
🖱️(2)Socket 对象(内建)方法
函数 描述 服务器端套接字 s.bind() 绑定地址(host,port)到套接字, 在AF_INET下,以元组(host,port)的形式表示地址。 s.listen() 开始TCP监听。backlog指定在拒绝连接之前,操作系统可以挂起的最大连接数量。该值至少为1,大部分应用程序设为5就可以了。 s.accept() 被动接受TCP客户端连接,(阻塞式)等待连接的到来 客户端套接字 s.connect() 主动初始化TCP服务器连接,。一般address的格式为元组(hostname,port),如果连接出错,返回socket.error错误。 s.connect_ex() connect()函数的扩展版本,出错时返回出错码,而不是抛出异常 公共用途的套接字函数 s.recv() 接收TCP数据,数据以字符串形式返回,bufsize指定要接收的最大数据量。flag提供有关消息的其他信息,通常可以忽略。 s.send() 发送TCP数据,将string中的数据发送到连接的套接字。返回值是要发送的字节数量,该数量可能小于string的字节大小。 s.sendall() 完整发送TCP数据,完整发送TCP数据。将string中的数据发送到连接的套接字,但在返回之前会尝试发送所有数据。成功返回None,失败则抛出异常。 s.recvfrom() 接收UDP数据,与recv()类似,但返回值是(data,address)。其中data是包含接收数据的字符串,address是发送数据的套接字地址。 s.sendto() 发送UDP数据,将数据发送到套接字,address是形式为(ipaddr,port)的元组,指定远程地址。返回值是发送的字节数。 s.close() 关闭套接字 s.getpeername() 返回连接套接字的远程地址。返回值通常是元组(ipaddr,port)。 s.getsockname() 返回套接字自己的地址。通常是一个元组(ipaddr,port) s.setsockopt(level,optname,value) 设置给定套接字选项的值。 s.getsockopt(level,optname[.buflen]) 返回套接字选项的值。 s.settimeout(timeout) 设置套接字操作的超时期,timeout是一个浮点数,单位是秒。值为None表示没有超时期。一般,超时期应该在刚创建套接字时设置,因为它们可能用于连接的操作(如connect()) s.gettimeout() 返回当前超时期的值,单位是秒,如果没有设置超时期,则返回None。 s.fileno() 返回套接字的文件描述符。 s.setblocking(flag) 如果 flag 为 False,则将套接字设为非阻塞模式,否则将套接字设为阻塞模式(默认值)。非阻塞模式下,如果调用 recv() 没有发现任何数据,或 send() 调用无法立即发送数据,那么将引起 socket.error 异常。 s.makefile() 创建一个与该套接字相关连的文件 看样子确实很简单,提供了很多内置的方法供我们调用,接下来举个🌰
服务端
我们使用 socket 模块的 socket 函数来创建一个 socket 对象。socket 对象可以通过调用其他函数来设置一个 socket 服务。
现在我们可以通过调用 bind(hostname, port) 函数来指定服务的 port(端口)。
接着,我们调用 socket 对象的 accept 方法。该方法等待客户端的连接,并返回 connection 对象,表示已连接到客户端。
完整代码如下:
创建一个TCP连接的服务端和客户端
服务端:
- import socket
- server = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
- server.bind(("127.0.0.1", 8888))
- server.listen(5) # 最大并发
- print("服务端已经启动,等待客户端连接")
- client, address = server.accept() # 创建新的线程
- """
- 连接的客户端 (
- family=AddressFamily.AF_INET, type=SocketKind.SOCK_STREAM,
- proto=0,
- laddr=('127.0.0.1', 8888),
- raddr=('127.0.0.1', 50290)>,('127.0.0.1', 50290))
- """
- print("已经建立连接")
- data = client.recv(1024)
- print("接收到客户端的数据", data.decode("utf-8"))
- print("请输入回复的内容")
- client.send(input().encode("utf-8"))
- # print("连接的客户端", client)
- server.close()
客户端
- import socket
- client = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
- client.connect(("127.0.0.1", 8888))
- print("客户端已经建立连接")
- print("客户端已经建立连接,请输入要发送的内容")
- client.send(input().encode("utf-8"))
- data = client.recv(1024)
- print("接收到服务端的响应", data.decode("utf-8"))
- client.close()
服务端的结果
服务端已经启动,等待客户端连接
已经建立连接
接收到客户端的数据 1
请输入回复的内容
2客户端的结果
客户端已经建立连接
客户端已经建立连接,请输入要发送的内容
1
接收到服务端的响应 2上面实现的的TCP连接是不是很简单,接下来说一下UDP的方式
服务端:
- import socket
- # print(type({"a":"a"}))
- # socket.SOCK_DGRAM UDP
- # socket.SOCK_STREAM TCP
- # 创建服务端
- server = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
- server.bind(("127.0.0.1", 8888))
- print("UDP服务端启动...")
- """
- 常用socket.AF_INET 多个协议层编解码,消耗cpu,要网卡收到网卡带宽消耗 ----->跨网传输
- socket.AF_UNIX不用网卡,在内核完成,也不用不同协议的编码 节省cpu不受带宽限制 --->本地
- """
- while True:
- data, client = server.recvfrom(1024)
- print("接收到消息", data.decode("utf-8"))
- server.sendto("你好这是服务端".encode("utf-8"), client) # 回复消息
客户端:
- import socket
- client = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
- client.sendto(input().encode("utf-8"), ("127.0.0.1", 8888))
- data, server = client.recvfrom(1024)
- print("收到的消息是", data.decode("utf-8"))
- client.close()
客户端输入9之后的结果
9
收到的消息是 你好这是服务端服务端的结果
UDP服务端启动...
接收到消息 9💾(3)Python内置的urllib模块
Python urllib 库用于操作网页 URL,并对网页的内容进行抓取处理。
本文主要介绍 Python3 的 urllib。
urllib 包 包含以下几个模块:
- urllib.request - 打开和读取 URL。
- urllib.error - 包含 urllib.request 抛出的异常。
- urllib.parse - 解析 URL。
- urllib.robotparser - 解析 robots.txt 文件。

urllib.request
urllib.request 定义了一些打开 URL 的函数和类,包含授权验证、重定向、浏览器 cookies等。
urllib.request 可以模拟浏览器的一个请求发起过程。
我们可以使用 urllib.request 的 urlopen 方法来打开一个 URL,语法格式如下:
urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None)- url:url 地址。
- data:发送到服务器的其他数据对象,默认为 None。
- timeout:设置访问超时时间。
- cafile 和 capath:cafile 为 CA 证书, capath 为 CA 证书的路径,使用 HTTPS 需要用到。
- cadefault:已经被弃用。
- context:ssl.SSLContext类型,用来指定 SSL 设置。
- from urllib.request import urlopen
- myURL = urlopen("https://www.runoob.com/")
- print(myURL.read())
以上代码使用 urlopen 打开一个 URL,然后使用 read() 函数获取网页的 HTML 实体代码。
read() 是读取整个网页内容,我们可以指定读取的长度:
- from urllib.request import urlopen
- myURL = urlopen("https://www.runoob.com/")
- print(myURL.read(300))
除了 read() 函数外,还包含以下两个读取网页内容的函数:
-
readline() - 读取文件的一行内容
- from urllib.request import urlopen
- myURL = urlopen("https://www.runoob.com/")
- print(myURL.readline()) #读取一行内容
- readlines() - 读取文件的全部内容,它会把读取的内容赋值给一个列表变量。
- from urllib.request import urlopen
- myURL = urlopen("https://www.runoob.com/")
- lines = myURL.readlines()
- for line in lines:
- print(line)
和文件处理的读法是相似的
我们在对网页进行抓取时,经常需要判断网页是否可以正常访问,这里我们就可以使用 getcode() 函数获取网页状态码,返回 200 说明网页正常,返回 404 说明网页不存在:
- import urllib.request
- myURL1 = urllib.request.urlopen("https://www.runoob.com/")
- print(myURL1.getcode()) # 200
- try:
- myURL2 = urllib.request.urlopen("https://www.runoob.com/no.html")
- except urllib.error.HTTPError as e:
- if e.code == 404:
- print(404) # 404
如果要将抓取的网页保存到本地,可以使用 Python3 File write() 方法 函数:
- from urllib.request import urlopen
- myURL = urlopen("https://www.runoob.com/")
- f = open("runoob_urllib_test.html", "wb")
- content = myURL.read() # 读取网页内容
- f.write(content)
- f.close()
URL 的编码与解码可以使用 urllib.request.quote() 与 urllib.request.unquote() 方法:
- import urllib.request
- encode_url = urllib.request.quote("https://www.runoob.com/") # 编码
- print(encode_url)
- unencode_url = urllib.request.unquote(encode_url) # 解码
- print(unencode_url)
https%3A//www.runoob.com/ https://www.runoob.com/
模拟头部信息
我们抓取网页一般需要对 headers(网页头信息)进行模拟,这时候需要使用到 urllib.request.Request 类:
class urllib.request.Request(url, data=None, headers={}, origin_req_host=None, unverifiable=False, method=None)- url:url 地址。
- data:发送到服务器的其他数据对象,默认为 None。
- headers:HTTP 请求的头部信息,字典格式。
- origin_req_host:请求的主机地址,IP 或域名。
- unverifiable:很少用整个参数,用于设置网页是否需要验证,默认是False。。
- method:请求方法, 如 GET、POST、DELETE、PUT等。
- import urllib.request
- import urllib.parse
- url = 'https://www.runoob.com/?s=' # 菜鸟教程搜索页面
- keyword = 'Python 教程'
- key_code = urllib.request.quote(keyword) # 对请求进行编码
- url_all = url+key_code
- header = {
- 'User-Agent':'Mozilla/5.0 (X11; Fedora; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'
- } #头部信息
- request = urllib.request.Request(url_all,headers=header)
- reponse = urllib.request.urlopen(request).read()
- fh = open("./urllib_test_runoob_search.html","wb") # 将文件写入到当前目录中
- fh.write(reponse)
- fh.close()
打开 urllib_test_runoob_search.html 文件(可以使用浏览器打开),内容如下:

表单 POST 传递数据,我们先创建一个表单,代码如下,我这里使用了 PHP 代码来获取表单的数据:
- html>
- <html>
- <head>
- <meta charset="utf-8">
- <title>菜鸟教程(runoob.com) urllib POST 测试title>
- head>
- <body>
- <form action="" method="post" name="myForm">
- Name: <input type="text" name="name"><br>
- Tag: <input type="text" name="tag"><br>
- <input type="submit" value="提交">
- form>
- <hr>
- // 使用 PHP 来获取表单提交的数据,你可以换成其他的if(isset($_POST['name']) && $_POST['tag'] ) {echo $_POST["name"] . ', ' . $_POST['tag'];}?>body>html>
- import urllib.request
- import urllib.parse
- url = 'https://www.runoob.com/try/py3/py3_urllib_test.php' # 提交到表单页面
- data = {'name':'RUNOOB', 'tag' : '菜鸟教程'} # 提交数据
- header = {
- 'User-Agent':'Mozilla/5.0 (X11; Fedora; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'
- } #头部信息
- data = urllib.parse.urlencode(data).encode('utf8') # 对参数进行编码,解码使用 urllib.parse.urldecode
- request=urllib.request.Request(url, data, header) # 请求处理
- reponse=urllib.request.urlopen(request).read() # 读取结果
- fh = open("./urllib_test_post_runoob.html","wb") # 将文件写入到当前目录中
- fh.write(reponse)
- fh.close()
urllib.error
urllib.error 模块为 urllib.request 所引发的异常定义了异常类,基础异常类是 URLError。
urllib.error 包含了两个方法,URLError 和 HTTPError。
URLError 是 OSError 的一个子类,用于处理程序在遇到问题时会引发此异常(或其派生的异常),包含的属性 reason 为引发异常的原因。
HTTPError 是 URLError 的一个子类,用于处理特殊 HTTP 错误例如作为认证请求的时候,包含的属性 code 为 HTTP 的状态码, reason 为引发异常的原因,headers 为导致 HTTPError 的特定 HTTP 请求的 HTTP 响应头。
对不存在的网页抓取并处理异常:
- import urllib.request
- import urllib.error
- myURL1 = urllib.request.urlopen("https://www.runoob.com/")
- print(myURL1.getcode()) # 200
- try:
- myURL2 = urllib.request.urlopen("https://www.runoob.com/no.html")
- except urllib.error.HTTPError as e:
- if e.code == 404:
- print(404) # 404
urllib.parse
urllib.parse 用于解析 URL,格式如下:
urllib.parse.urlparse(urlstring, scheme='', allow_fragments=True)urlstring 为 字符串的 url 地址,scheme 为协议类型,
allow_fragments 参数为 false,则无法识别片段标识符。相反,它们被解析为路径,参数或查询组件的一部分,并 fragment 在返回值中设置为空字符串。
- from urllib.parse import urlparse
- o = urlparse("https://www.runoob.com/?s=python+%E6%95%99%E7%A8%8B")
- print(o)
ParseResult(scheme='https', netloc='www.runoob.com', path='/', params='', query='s=python+%E6%95%99%E7%A8%8B', fragment='')
从结果可以看出,内容是一个元组,包含 6 个字符串:协议,位置,路径,参数,查询,判断。
我们可以直接读取协议内容:
- from urllib.parse import urlparse
- o = urlparse("https://www.runoob.com/?s=python+%E6%95%99%E7%A8%8B")
- print(o.scheme)
https
完整内容
属性
索引
值
值(如果不存在)
scheme0
URL协议
scheme 参数
netloc1
网络位置部分
空字符串
path2
分层路径
空字符串
params3
最后路径元素的参数
空字符串
query4
查询组件
空字符串
fragment5
片段识别
空字符串
username用户名
Nonepassword密码
Nonehostname主机名(小写)
Noneport端口号为整数(如果存在)
Noneurllib.robotparser
urllib.robotparser 用于解析 robots.txt 文件。
robots.txt(统一小写)是一种存放于网站根目录下的 robots 协议,它通常用于告诉搜索引擎对网站的抓取规则。
urllib.robotparser 提供了 RobotFileParser 类,语法如下:
class urllib.robotparser.RobotFileParser(url='')
这个类提供了一些可以读取、解析 robots.txt 文件的方法:
-
set_url(url) - 设置 robots.txt 文件的 URL。
-
read() - 读取 robots.txt URL 并将其输入解析器。
-
parse(lines) - 解析行参数。
-
can_fetch(useragent, url) - 如果允许 useragent 按照被解析 robots.txt 文件中的规则来获取 url 则返回 True。
-
mtime() -返回最近一次获取 robots.txt 文件的时间。 这适用于需要定期检查 robots.txt 文件更新情况的长时间运行的网页爬虫。
-
modified() - 将最近一次获取 robots.txt 文件的时间设置为当前时间。
-
crawl_delay(useragent) -为指定的 useragent 从 robots.txt 返回 Crawl-delay 形参。 如果此形参不存在或不适用于指定的 useragent 或者此形参的 robots.txt 条目存在语法错误,则返回 None。
-
request_rate(useragent) -以 named tuple RequestRate(requests, seconds) 的形式从 robots.txt 返回 Request-rate 形参的内容。 如果此形参不存在或不适用于指定的 useragent 或者此形参的 robots.txt 条目存在语法错误,则返回 None。
-
site_maps() - 以 list() 的形式从 robots.txt 返回 Sitemap 形参的内容。 如果此形参不存在或者此形参的 robots.txt 条目存在语法错误,则返回 None。
- >>> import urllib.robotparser
- >>> rp = urllib.robotparser.RobotFileParser()
- >>> rp.set_url("http://www.musi-cal.com/robots.txt")
- >>> rp.read()
- >>> rrate = rp.request_rate("*")
- >>> rrate.requests
- 3
- >>> rrate.seconds
- 20
- >>> rp.crawl_delay("*")
- 6
- >>> rp.can_fetch("*", "http://www.musi-cal.com/cgi-bin/search?city=San+Francisco")
- False
- >>> rp.can_fetch("*", "http://www.musi-cal.com/")
- True
📖(4)requests模块
我们已经讲解了Python内置的urllib模块,用于访问网络资源。但是,它用起来比较麻烦,而且,缺少很多实用的高级功能。
更好的方案是使用requests。它是一个Python第三方库,处理URL资源特别方便。
安装requests
如果安装了Anaconda,requests就已经可用了。否则,需要在命令行下通过pip安装:
pip install requests如果遇到Permission denied安装失败,请加上sudo重试。
GET请求
- import requests
- res = requests.get('http://www.baidu.com/')
- res.encoding = 'utf-8'
- print(res.status_code)
- print(res.text)
200
百度一下,你就知道 对于带参数的URL,传入一个dict作为
params参数:r = requests.get('https://www.douban.com/search', params={'q': 'python', 'cat': '1001'})无论响应是文本还是二进制内容,我们都可以用
content属性获得bytes对象:b'html>\r\n<html> <head><meta http-equiv=content-type content=text/html;charset=utf-8><meta http-equiv=X-UA-Compatible content=IE=Edge><meta content=always name=referrer><link rel=stylesheet type=text/css href=http://s1.bdstatic.com/r/www/cache/bdorz/baidu.min.css><title>\xe7\x99\xbe\xe5\xba\xa6\xe4\xb8\x80\xe4\xb8\x8b\xef\xbc\x8c\xe4\xbd\xa0\xe5\xb0\xb1\xe7\x9f\xa5\xe9\x81\x93title>head> <body link=#0000cc> <div id=wrapper> <div id=head> <div class=head_wrapper> <div class=s_form> <div class=s_form_wrapper> <div id=lg> <img hidefocus=true src=//www.baidu.com/img/bd_logo1.png width=270 height=129> div> <form id=form name=f action=//www.baidu.com/s class=fm> <input type=hidden name=bdorz_come value=1> <input type=hidden name=ie value=utf-8> <input type=hidden name=f value=8> <input type=hidden name=rsv_bp value=1> <input type=hidden name=rsv_idx value=1> <input type=hidden name=tn value=baidu><span class="bg s_ipt_wr"><input id=kw name=wd class=s_ipt value maxlength=255 autocomplete=off autofocus>span><span class="bg s_btn_wr"><input type=submit id=su value=\xe7\x99\xbe\xe5\xba\xa6\xe4\xb8\x80\xe4\xb8\x8b class="bg s_btn">span> form> div> div> <div id=u1> <a href=http://news.baidu.com name=tj_trnews class=mnav>\xe6\x96\xb0\xe9\x97\xbba> <a href=http://www.hao123.com name=tj_trhao123 class=mnav>hao123a> <a href=http://map.baidu.com name=tj_trmap class=mnav>\xe5\x9c\xb0\xe5\x9b\xbea> <a href=http://v.baidu.com name=tj_trvideo class=mnav>\xe8\xa7\x86\xe9\xa2\x91a> <a href=http://tieba.baidu.com name=tj_trtieba class=mnav>\xe8\xb4\xb4\xe5\x90\xa7a> <noscript> <a href=http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u=http%3A%2F%2Fwww.baidu.com%2f%3fbdorz_come%3d1 name=tj_login class=lb>\xe7\x99\xbb\xe5\xbd\x95a> noscript> <script>document.write(\'<a href="http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u=\'+ encodeURIComponent(window.location.href+ (window.location.search === "" ? "?" : "&")+ "bdorz_come=1")+ \'" name="tj_login" class="lb">\xe7\x99\xbb\xe5\xbd\x95a>\');script> <a href=//www.baidu.com/more/ name=tj_briicon class=bri style="display: block;">\xe6\x9b\xb4\xe5\xa4\x9a\xe4\xba\xa7\xe5\x93\x81a> div> div> div> <div id=ftCon> <div id=ftConw> <p id=lh> <a href=http://home.baidu.com>\xe5\x85\xb3\xe4\xba\x8e\xe7\x99\xbe\xe5\xba\xa6a> <a href=http://ir.baidu.com>About Baidua> p> <p id=cp>©2017 Baidu <a href=http://www.baidu.com/duty/>\xe4\xbd\xbf\xe7\x94\xa8\xe7\x99\xbe\xe5\xba\xa6\xe5\x89\x8d\xe5\xbf\x85\xe8\xaf\xbba> <a href=http://jianyi.baidu.com/ class=cp-feedback>\xe6\x84\x8f\xe8\xa7\x81\xe5\x8f\x8d\xe9\xa6\x88a> \xe4\xba\xacICP\xe8\xaf\x81030173\xe5\x8f\xb7 <img src=//www.baidu.com/img/gs.gif> p> div> div> div> body> html>\r\n'requests的方便之处还在于,对于特定类型的响应,例如JSON,可以直接获取:
r = requests.get('https://query.yahooapis.com/v1/public/yql?q=select%20*%20from%20weather.forecast%20where%20woeid%20%3D%202151330&format=json')需要传入HTTP Header时,我们传入一个dict作为
headers参数:r = requests.get('https://www.douban.com/', headers={'User-Agent': 'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit'})POST请求
要发送POST请求,只需要把
get()方法变成post(),然后传入data参数作为POST请求的数据:r = requests.post('https://accounts.douban.com/login', data={'form_email': 'abc@example.com', 'form_password': '123456'})requests默认使用
application/x-www-form-urlencoded对POST数据编码。如果要传递JSON数据,可以直接传入json参数:- params = {'key': 'value'}
- r = requests.post(url, json=params) # 内部自动序列化为JSON
类似的,上传文件需要更复杂的编码格式,但是requests把它简化成
files参数- upload_files = {'file': open('report.xls', 'rb')}
- r = requests.post(url, files=upload_files)
在读取文件时,注意务必使用
'rb'即二进制模式读取,这样获取的bytes长度才是文件的长度。把
post()方法替换为put(),delete()等,就可以以PUT或DELETE方式请求资源。除了能轻松获取响应内容外,requests对获取HTTP响应的其他信息也非常简单。例如,获取响应头:
r.headersContent-Type': 'text/html; charset=utf-8', 'Transfer-Encoding': 'chunked', 'Content-Encoding': 'gzip', ...}r.headers['Content-Type']'text/html; charset=utf-8'requests对Cookie做了特殊处理,使得我们不必解析Cookie就可以轻松获取指定的Cookie:
r.cookies['ts']结果
'example_cookie_12345'要在请求中传入Cookie,只需准备一个dict传入
cookies参数:- cs = {'token': '12345', 'status': 'working'}
- r = requests.get(url, cookies=cs)
最后,要指定超时,传入以秒为单位的timeout参数:
r = requests.get(url, timeout=2.5) # 2.5秒后超时
用requests获取URL资源,就是这么简单!短短两行代码就完成了get/post请求,真实太方便了,不得不说python对基本功能的封装真实做的太好了。程序员能解放自己干点别的东西了
————————————————
如果觉得本文对你有帮助,欢迎点赞,欢迎关注我,如果有补充欢迎评论交流,我将努力创作更多更好的文章。
- 相关阅读:
【开源打印组件】vue-plugin-hiprint初体验
【PyTorch】深度学习实践之 RNN基础篇——实现RNN
Tmall商城系统后台管理订单模块分析
网络编程 tcp/ip下的c/s模型介绍
如何使用积分系统增强用户留存?会员积分体系建设方式介绍
linux环境下的MySQL UDF提权
5-5配置Mysql复制 基于日志点的复制
深入解析kubernetes controller-runtime
[Rust GUI]0.10.0版本iced代码示例 - progress_bar
docker 网络简介
- 原文地址:https://blog.csdn.net/qq_29235677/article/details/126129465

