-
hdfs 副本放置策略及快照功能简介
一. hdfs默认每个数据块都对应有三个副本,出于安全性和数据本地性等方面的考虑,hdfs对于副本放置的位置是有策略实现的,首先基于要求写数据块的请求方的位置归为两大类:
假设有如下的网络拓扑:
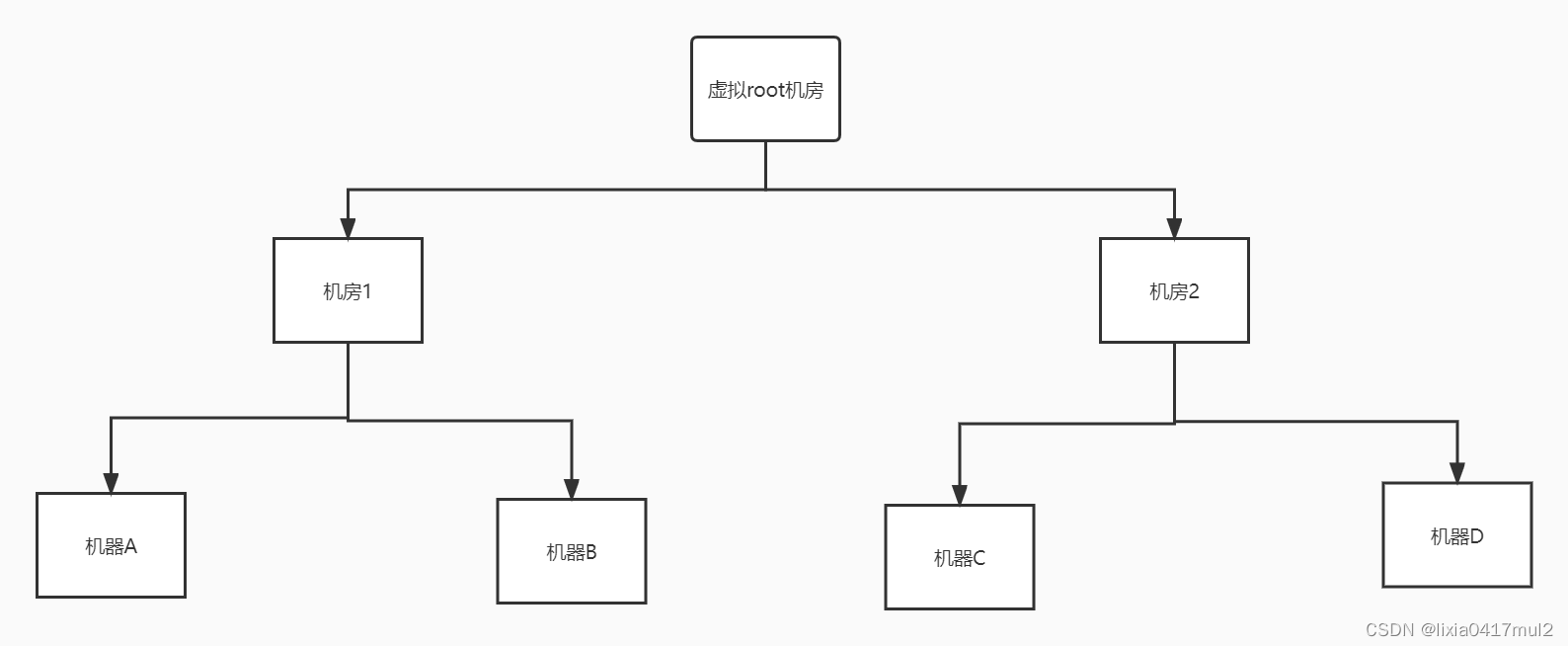
1.1 请求方来源于外部的客户端
a. 第一个副本的选择就可以随机一台机器,比如机器A
b. 第二个副本的选择就是选择和机器A属于同一个机房的机器上了,比如机器B
c.第三个副本的选择为了数据备份期间会选择另一个机房2下的机器,比如机器C1.2 请求方来源于内部的DataNode机器,比如机器C
a.第一个副本的选择要选择和机器C相同的机器上,也就是本地机器C放置一份数据
b.第二个副本的选择就是选择和机器C属于同一个机房的机器上了,比如机器D
c.第三个副本的选择为了数据备份期间会选择另一个机房1下的机器,比如机器A以上在寻找离当前机器最近的其他机器时,有一个距离的概念,距离的相关算法是最近公共祖先算法.
通过如下命令可以查看一个文件的数据块的详细位置信息:
hdfs fsck /tmp/1.txt -files -blocks -locations二:hdfs的快照功能
2.1 创建快照的命令:hadoop fs -createsnapshot path snapshotname
2.2 比较两个快照的命令: hdfs snapshopdiff 快照1 快照2
2.3 快照的实现原理是存放对应目录的一个快照,他只会保存和当前目录文件中有变化的数据,没有变化的数据他是不记录的,实现原理类似于创建子进程时对内存的写拷贝操作,只有和当前目录中有变化的文件才需要记录起来
2.4 快照的用途:其一是可以恢复丢失的数据,也就是把这个目录下的数据恢复到快照时间点的数据
2.5 快照的用途: 其二利用快照的diff功能,结合DistCp命令可以实现集群数据间的同步 -
相关阅读:
开发工程师必备————【Day1】网络编程
C语言进阶 -- 回调函数以及qsort函数的使用
MySQL系列3:缓冲池Buffer Pool的设计思想
Vue2之防抖_debounce封装函数&v-debounce自定义指令(传参/不传)
设计模式篇---组合模式
银河麒麟V10系统下软RAID调试,使用两个磁盘组raid0
机器视觉Halcon-焊点提取排序设计思路一
AWS 使用Lambda实现钉钉机器人报警
刷题《剑指Offer》day14
计算机挑战赛java c组2020年赛题
- 原文地址:https://blog.csdn.net/lixia0417mul2/article/details/126132750