-
典型相关分析CCA计算过程
本文介绍了CCA解决的问题,CCA原理的推导过程,以及对计算结果物理意义的解释。并且通过SPSS和R操作演示了一个关于CCA的例子。数据文件下载参考[8],SPSS输出结果文件下载参考[9],R代码文件下载参考[10]。
一.CCA工作原理
1.CCA定义
首先需要搞清楚典型相关分析(Canonical Correlation Analysis)解决了什么问题,它解决的是一组变量与另外一组变量的相关问题。举个例子,比如想要量化家庭特征与家庭消费之间的关系,其中,家庭特征包括户主的年龄、家庭的年收入和户主受教育程序,而家庭消费包括每年去餐厅就餐的频率、每年外出看电影频率。
其实,这个是泛化后的问题,先来看一个更加具体的问题,不是一组变量与另外一组变量的相关问题,而是一个变量与另外一个变量的相关问题,比如计算两个变量 X {X} X和 Y {Y} Y的相关问题,是如何计算的呢,下面的方程是不是很眼熟:
ρ X Y = c o v ( X , Y ) v a r ( X ) v a r ( Y ) {\rho _{XY}} = \frac{{{\mathop{\rm cov}} \left( {X,Y} \right)}}{{\sqrt {{\mathop{\rm var}} \left( X \right){\mathop{\rm var}} \left( Y \right)} }} ρXY=var(X)var(Y)cov(X,Y)再进一步的想一下,如果是计算一个变量和一组变量的相关问题呢。当然更深一步的想象就是这篇文章要讲的一组变量与另外一组变量的相关问题。先来形式化的定义CCA:假设有一组变量 X 1 , ⋯ , X p {X_1}, \cdots ,{X_p} X1,⋯,Xp与另一组变量 Y 1 , ⋯ , Y q {Y_1}, \cdots ,{Y_q} Y1,⋯,Yq,要研究这两组变量的相关关系,如何给两组变量之间的相关性以数量的描述,就是CCA。
二.CCA方程推导过程
1.CCA的数学描述
假设 x 1 {x_1} x1表示每年去餐馆就餐的频率, x 2 {x_2} x2表示每年外出看电影频率, y 1 {y_1} y1表示户主的年龄, y 2 {y_2} y2表示家庭的年收入, y 3 {y_3} y3表示户主受教育程度。典型相关分析的思想是找出第一对线性组合,使其具有最大相关性:
u 1 = a 11 x 1 + a 21 x 2 + . . . + a p 1 x p v 1 = b 11 y 1 + b 21 y 2 + b 31 y 3 + . . . + b q 1 y q ρ ( u 1 , v 1 ) = ?u1=a11x1+a21x2+...+ap1xpv1=b11y1+b21y2+b31y3+...+bq1yqρ(u1,v1)=?u 1 = a 11 x 1 + a 21 x 2 + . . . + a p 1 x p v 1 = b 11 y 1 + b 21 y 2 + b 31 y 3 + . . . + b q 1 y q ρ ( u 1 , v 1 ) = ?
然后再找第二对线性组合,使其具有次大相关性:
u 2 = a 12 x 1 + a 22 x 2 + . . . + a p 2 x p v 2 = b 12 y 1 + b 22 y 2 + b 32 y 3 + . . . + b q 2 y q ρ ( u 2 , v 2 ) = ?u2=a12x1+a22x2+...+ap2xpv2=b12y1+b22y2+b32y3+...+bq2yqρ(u2,v2)=?u 2 = a 12 x 1 + a 22 x 2 + . . . + a p 2 x p v 2 = b 12 y 1 + b 22 y 2 + b 32 y 3 + . . . + b q 2 y q ρ ( u 2 , v 2 ) = ?
就这样一直进行计算下去,直到第 r r r步,这两组变量的相关性被提取完毕为止,其中 r ≤ min ( p , q ) r \le \min \left( {{\rm{p}},{\rm{q}}} \right) r≤min(p,q),即可以得到 r r r组变量。2.CCA的推导过程
假设两组变量的向量 Z = ( x 1 , x 2 , . . . , x p , y 1 , y 2 , . . . , y q ) {\bf{Z}} = \left( {{x_1},{x_2},...,{x_p},{y_1},{y_2},...,{y_q}} \right) Z=(x1,x2,...,xp,y1,y2,...,yq),其协方差矩阵如下:
∑ = [ ∑ 11 ∑ 12 ∑ 21 ∑ 12 ] \sum = \left[\right] ∑=[∑11∑12∑21∑12]∑ 11 ∑ 12 ∑ 21 ∑ 12
其中, ∑ 11 \sum\nolimits_{11} ∑11是第一组变量的协方差矩阵, ∑ 22 \sum\nolimits_{22} ∑22是第二组变量的协方差矩阵, ∑ 12 \sum\nolimits_{12} ∑12和 ∑ 21 \sum\nolimits_{21} ∑21是 X X X和 Y Y Y的协方差矩阵,它们之间的关系是转置相等,即 ∑ 12 = ∑ 21 T \sum\nolimits_{12} = {\sum\nolimits_{21} ^{\rm{T}}} ∑12=∑21T。这样两组变量的第一对线性组合记为:
u 1 = a 1 T X v 1 = b 1 T Yu1=a1TXv1=b1TYu 1 = a 1 T X v 1 = b 1 T Y 其中 a 1 {\bf{a}}_1 a1和 b 1 {\bf{b}}_1 b1表示:
a 1 = ( a 11 , a 21 , . . . , a p 1 ) T b 1 = ( b 11 , b 21 , . . . , b q 1 ) Ta1=(a11,a21,...,ap1)Tb1=(b11,b21,...,bq1)Ta 1 = ( a 11 , a 21 , . . . , a p 1 ) T b 1 = ( b 11 , b 21 , . . . , b q 1 ) T
接下来推导 ρ u 1 , v 1 {\rho _{{{\bf{u}}_1},{{\bf{v}}_1}}} ρu1,v1的计算,通过求 a 1 {\bf{a}}_1 a1和 b 1 {\bf{b}}_1 b1,使 ρ u 1 , v 1 {\rho _{{{\bf{u}}_1},{{\bf{v}}_1}}} ρu1,v1最大,这个是CCA最核心的思想:
v a r ( u 1 ) = a 1 T v a r ( X ) a 1 = a 1 T ∑ 11 a 1 = 1 v a r ( v 1 ) = b 1 T v a r ( Y ) b 1 = b 1 T ∑ 22 b 1 = 1 ρ u 1 , v 1 = c o v ( u 1 , v 1 ) = a 1 T c o v ( X , Y ) b 1 = a 1 T ∑ 12 b 1var(u1)=a1Tvar(X)a1=a1T∑11a1=1var(v1)=b1Tvar(Y)b1=b1T∑22b1=1ρu1,v1=cov(u1,v1)=a1Tcov(X,Y)b1=a1T∑12b1var ( u 1 ) = a 1 T var ( X ) a 1 = a 1 T ∑ 11 a 1 = 1 var ( v 1 ) = b 1 T var ( Y ) b 1 = b 1 T ∑ 22 b 1 = 1 ρ u 1 , v 1 = c o v ( u 1 , v 1 ) = a 1 T c o v ( X , Y ) b 1 = a 1 T ∑ 12 b 1 接下来就是典型相关系数的过程。根据高等数学中条件极致的求法,即拉格朗日乘数法,通过引入拉格朗日乘数 λ \lambda λ和 ν \nu ν来求极值的问题,转换为求方程1的极大值:
ϕ ( a 1 , b 1 ) = a 1 T ∑ 12 b 1 − λ 2 ( a 1 T ∑ 11 a 1 − 1 ) − ν 2 ( b 1 T ∑ 22 b 1 − 1 ) \phi \left( {{{\bf{a}}_1},{{\bf{b}}_1}} \right) = {\bf{a}}_1^{\rm{T}}\sum\nolimits_{12} {} {{\bf{b}}_1} - \frac{\lambda }{2}\left( {{\bf{a}}_1^{\rm{T}}\sum\nolimits_{11} {{{\bf{a}}_1}} - 1} \right) - \frac{\nu }{2}\left( {{\bf{b}}_1^{\rm{T}}\sum\nolimits_{22} {{{\bf{b}}_1}} - 1} \right) ϕ(a1,b1)=a1T∑12b1−2λ(a1T∑11a1−1)−2ν(b1T∑22b1−1)接下来就是求极大值的思路了,各种求偏导,方程2如下所示:
∂ ϕ ∂ a 1 = ∑ 12 b 1 − λ ∑ 11 a 1 = 0 ∂ ϕ ∂ b 1 = ∑ 21 a 1 − v ∑ 22 b 1 = 0∂a1∂ϕ=∑12b1−λ∑11a1=0∂b1∂ϕ=∑21a1−v∑22b1=0∂ ϕ ∂ a 1 = ∑ 12 b 1 − λ ∑ 11 a 1 = 0 ∂ ϕ ∂ b 1 = ∑ 21 a 1 − v ∑ 22 b 1 = 0 方程3如下所示:
∑ 12 b 1 − λ ∑ 11 a 1 = 0 ∑ 21 a 1 − v ∑ 22 b 1 = 0∑12b1−λ∑11a1=0∑21a1−v∑22b1=0∑ 12 b 1 − λ ∑ 11 a 1 = 0 ∑ 21 a 1 − v ∑ 22 b 1 = 0 将方程3分别左乘 a 1 T {\bf{a}}_1^{\rm{T}} a1T和 b 1 T {\bf{b}}_1^{\rm{T}} b1T,得到方程4:
a 1 T ∑ 12 b 1 − λ a 1 T ∑ 11 a 1 = 0 b 1 T ∑ 21 a 1 − v b 1 T ∑ 22 b 1 = 0a1T∑12b1−λa1T∑11a1=0b1T∑21a1−vb1T∑22b1=0a 1 T ∑ 12 b 1 − λ a 1 T ∑ 11 a 1 = 0 b 1 T ∑ 21 a 1 − v b 1 T ∑ 22 b 1 = 0 进一步推导得出方程5:
a 1 T ∑ 12 b 1 = λ b 1 T ∑ 21 a 1 = va1T∑12b1=λb1T∑21a1=va 1 T ∑ 12 b 1 = λ b 1 T ∑ 21 a 1 = v 因此得到方程6:
λ = v = a 1 T ∑ 12 b 1 = ρ ( u 1 , v 1 ) \lambda = v = {\bf{a}}_1^{\rm{T}}\sum\nolimits_{12} {{{\bf{b}}_1}} = {\rho _{\left( {{{\bf{u}}_1},{\bf{v}}1} \right)}} λ=v=a1T∑12b1=ρ(u1,v1)可见 λ \lambda λ和 v v v是相等的,并且就是要求的 ρ u 1 , v 1 {\rho _{{{\bf{u}}_1},{{\bf{v}}_1}}} ρu1,v1。
将 ∑ 12 ∑ 22 − 1 \sum\nolimits_{12} \sum\nolimits_{22}^{ - 1} ∑12∑22−1左乘方程3的第二式,得到方程7:
∑ 12 ∑ 22 − 1 ∑ 21 a 1 − v ∑ 12 ∑ 22 − 1 ∑ 22 b 1 = 0 \sum\nolimits_{12} \sum\nolimits_{22}^{ - 1} \sum\nolimits_{21} {{\bf{a}}_1} - v\sum\nolimits_{12} \sum\nolimits_{22}^{ - 1} \sum\nolimits_{22} {} {{\bf{b}}_1} = 0 ∑12∑22−1∑21a1−v∑12∑22−1∑22b1=0进一步简化得到方程8:
∑ 12 ∑ 22 − 1 ∑ 21 a 1 − v ∑ 12 b 1 = 0 \sum\nolimits_{12} \sum\nolimits_{22}^{ - 1} \sum\nolimits_{21} {} {{\bf{a}}_1} - v\sum\nolimits_{12} {{\bf{b}}_1} = 0 ∑12∑22−1∑21a1−v∑12b1=0将方程3的第一式代入方程8,得到方程9:
∑ 12 ∑ 22 − 1 ∑ 21 a 1 − λ 2 ∑ 11 a 1 = 0 \sum\nolimits_{12} \sum\nolimits_{22}^{ - 1} \sum\nolimits_{21} {{\bf{a}}_1} - {\lambda ^2}\sum\nolimits_{11} {{\bf{a}}_1} = 0 ∑12∑22−1∑21a1−λ2∑11a1=0将方程9左乘 ∑ 11 − 1 \sum\nolimits_{11}^{ - 1} ∑11−1得到方程10:
∑ 11 − 1 ∑ 12 ∑ 22 − 1 ∑ 21 a 1 − λ 2 a 1 = 0 \sum\nolimits_{11}^{ - 1} {} \sum\nolimits_{12} {} \sum\nolimits_{22}^{ - 1} {} \sum\nolimits_{21} {} {{\bf{a}}_1} - {\lambda ^2}{{\bf{a}}_1} = 0 ∑11−1∑12∑22−1∑21a1−λ2a1=0在方程10中, ∑ 11 − 1 ∑ 12 ∑ 22 − 1 ∑ 21 \sum\nolimits_{11}^{ - 1} \sum\nolimits_{12} \sum\nolimits_{22}^{ - 1} \sum\nolimits_{21} ∑11−1∑12∑22−1∑21的特征根是 λ 2 {\lambda ^2} λ2,相应的特征向量为 a 1 {{\bf{a}}_1} a1。
将 ∑ 12 ∑ 11 − 1 \sum\nolimits_{12} \sum\nolimits_{11}^{ - 1} ∑12∑11−1左乘方程3的第一式,并且将第二式代入得到方程11:
∑ 21 ∑ 11 − 1 ∑ 21 b 1 − λ ∑ 12 a 1 = 0 ∑ 21 ∑ 11 − 1 ∑ 12 b 1 − λ 2 ∑ 22 b 1 = 0 ∑ 22 − 1 ∑ 21 ∑ 11 − 1 ∑ 12 b 1 − λ 2 b 1 = 0∑21∑11−1∑21b1−λ∑12a1=0∑21∑11−1∑12b1−λ2∑22b1=0∑22−1∑21∑11−1∑12b1−λ2b1=0∑ 21 ∑ 11 − 1 ∑ 21 b 1 − λ ∑ 12 a 1 = 0 ∑ 21 ∑ 11 − 1 ∑ 12 b 1 − λ 2 ∑ 22 b 1 = 0 ∑ 22 − 1 ∑ 21 ∑ 11 − 1 ∑ 12 b 1 − λ 2 b 1 = 0 在方程11中, ∑ 22 − 1 ∑ 21 ∑ 11 − 1 ∑ 12 \sum\nolimits_{22}^{ - 1} \sum\nolimits_{21} \sum\nolimits_{11}^{ - 1} \sum\nolimits_{12} ∑22−1∑21∑11−1∑12的特征根是 λ 2 {\lambda ^2} λ2,相应的特征向量为 b 1 {{\bf{b}}_1} b1。
令 M 1 = ∑ 11 − 1 ∑ 12 ∑ 22 − 1 ∑ 21 {{\bf{M}}_{\rm{1}}} = \sum\nolimits_{11}^{ - 1} {} \sum\nolimits_{12} {} \sum\nolimits_{22}^{ - 1} {} \sum\nolimits_{21} {} M1=∑11−1∑12∑22−1∑21和 M 2 = ∑ 22 − 1 ∑ 21 ∑ 11 − 1 ∑ 12 {{\bf{M}}_2}{\rm{ = }}\sum\nolimits_{22}^{ - 1} {} \sum\nolimits_{21} {} \sum\nolimits_{11}^{ - 1} {} \sum\nolimits_{12} {} M2=∑22−1∑21∑11−1∑12,得到方程12:
M 1 a = λ 2 a M 2 b = λ 2 bM1a=λ2aM2b=λ2bM 1 a = λ 2 a M 2 b = λ 2 b 至此可以得出结论:第一个典型相关系数为 λ 1 \lambda_1 λ1(最大特征值),其中 λ 1 2 \lambda _1^2 λ12既是 M 1 {\bf{M}}_{\rm{1}} M1又是 M 2 {\bf{M}}_{\rm{2}} M2的特征根,第一对典型变量的系数 a 1 {{\bf{a}}_1} a1和 b 1 {{\bf{b}}_1} b1是相应于 M 1 {\bf{M}}_{\rm{1}} M1和 M 2 {\bf{M}}_{\rm{2}} M2的特征向量。这样就把典型相关分析的求解转换成了求 M 1 {\bf{M}}_{\rm{1}} M1和 M 2 {\bf{M}}_{\rm{2}} M2的特征根和特征向量的问题。
说明:第一对典型变量提取了原始变量 X X X和 Y Y Y之间相关的主要部分,如果这部分不能足以解释原始变量,可以在剩余的相关中再求出第二对典型变量和它们的典型相关系数。如此反复,直到这两组变量的相关性被提取完毕为止。
3.CCA的物理意义
还是以量化家庭特征与家庭消费之间的关系为例子,假设 x 1 {x_1} x1表示每年去餐馆就餐的频率, x 2 {x_2} x2表示每年外出看电影频率, y 1 {y_1} y1表示户主的年龄, y 2 {y_2} y2表示家庭的年收入, y 3 {y_3} y3表示户主受教育程度。如果计算出第一典型相关系数为0.687948,第二典型相关系数为0.186865。第一典型变量和第二典型变量代入方程如下所示:
(1)第一对典型变量
u 1 = 0.9866 x 1 + 0.8872 x 2 v 1 = 0.4211 y 1 + 0.9822 y 2 + 0.5145 y 3u1=0.9866x1+0.8872x2v1=0.4211y1+0.9822y2+0.5145y3u 1 = 0.9866 x 1 + 0.8872 x 2 v 1 = 0.4211 y 1 + 0.9822 y 2 + 0.5145 y 3 - u 1 {u_1} u1量化的是家庭消费特征,它与 x 1 {x_1} x1和 x 2 {x_2} x2的相关系数分别为0.9866和0.8872,这2个值都是比较高的。
- v 1 {v_1} v1量化的是家庭特征,它与 y 2 {y_2} y2的相关系数为0.9822,其它的相关系数较小,因此 v 1 {v_1} v1主要代表的就是家庭收入。
- u 1 {u_1} u1和 v 1 {v_1} v1的相关系数为0.687948,说明一个家庭的消费和家庭的收入关系密切。
(2)第二对典型变量
u 2 = − 0.1632 x 1 + 0.4614 x 2 v 2 = 0.8464 y 1 + − 0.1101 y 2 + 0.3013 y 3u2=−0.1632x1+0.4614x2v2=0.8464y1+−0.1101y2+0.3013y3u 2 = − 0.1632 x 1 + 0.4614 x 2 v 2 = 0.8464 y 1 + − 0.1101 y 2 + 0.3013 y 3 - u 2 {u_2} u2和 x 2 {x_2} x2的相关系数为0.4614,可见 u 2 {u_2} u2主要代表的是每年外出看电影频率。
- v 2 {v_2} v2和 y 1 {y_1} y1的相关系数为0.8464,可见 v 2 {v_2} v2主要代表的是家庭成员的年龄特征。
- u 2 {u_2} u2和 v 2 {v_2} v2的相关系数为0.186865,说明一个家庭每年外出看电影频率和家庭成员的年龄特征关系密切。
三.CCA代码例子
1.SPSS28实现
(1)变量视图和数据视图
(2)分析->相关->典型相关分析
将控制情绪、自我调节、自我激励作为集合1,将语文、数学、英语和才艺作为集合2:

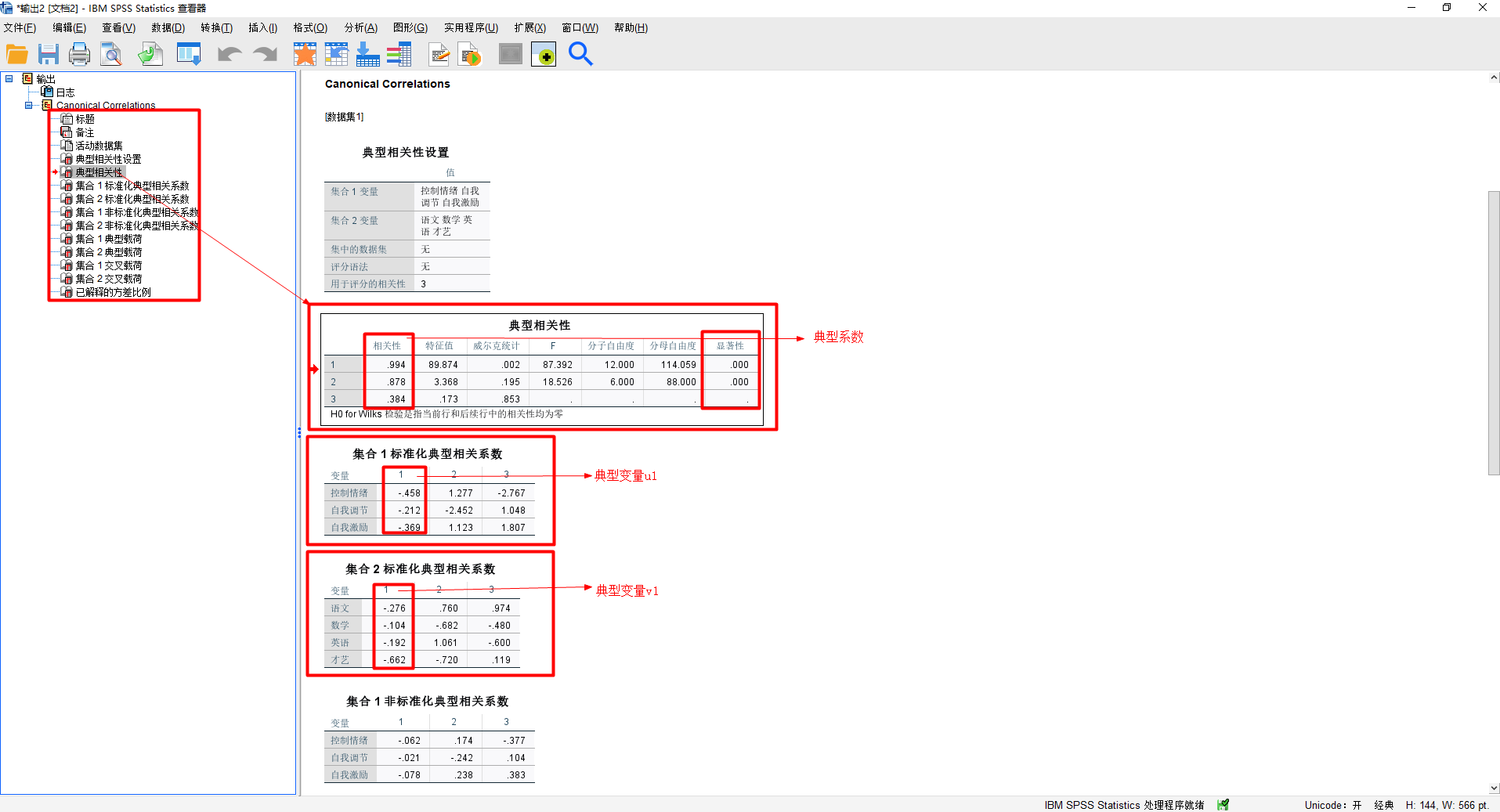
(3)生成结果
2.R编程实现
(1)安装R包
操作系统使用的Windows10,版本号为20H2,R语言版本使用64位的R-3.6.3。期初在安装R包的时候总是报错,经过查找资料,需要将Packages页面中的第2和3个复选框去掉,重启RStudio即可:

依次安装openxlsx、CCA和CCP包:install.packages("openxlsx", dependencies=TRUE) install.packages("CCA", dependencies=TRUE) install.packages("CCP", dependencies=TRUE)- 1
- 2
- 3
(2)R代码实现

# 1.加载数据 library(openxlsx) rawdata <- read.xlsx("F:/cca_data.xlsx", sheet = "典型相关分析") names(rawdata) # 2.对两组变量的数据做标准化处理 xdata = scale(rawdata[, 1:3]) ydata = scale(rawdata[, 4:7]) # 3.执行典型相关分析 library(CCA) mycca = cc(xdata, ydata) mycca # 4.检验典型相关系数在统计上是否显著 library(CCP) rho = mycca$cor n = dim(rawdata)[1] p = dim(xdata)[2] q = dim(ydata)[2] p.asym(rho, n, p, q, tstat = 'Wilks')- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
(3)输出结果
> # 1.加载数据 > library(openxlsx) > rawdata <- read.xlsx("F:/cca_data.xlsx", sheet = "典型相关分析") > names(rawdata) [1] "控制情绪" "自我调节" "自我激励" "语文" "数学" "英语" "才艺" > > # 2.对两组变量的数据做标准化处理 > xdata = scale(rawdata[, 1:3]) > ydata = scale(rawdata[, 4:7]) > > # 3.执行典型相关分析 > library(CCA) > mycca = cc(xdata, ydata) > mycca $cor [1] 0.9944827 0.8781065 0.3836057 $names $names$Xnames [1] "控制情绪" "自我调节" "自我激励" $names$Ynames [1] "语文" "数学" "英语" "才艺" $names$ind.names [1] "1" "2" "3" "4" "5" "6" "7" "8" "9" "10" "11" "12" "13" "14" "15" "16" "17" "18" "19" "20" "21" "22" "23" "24" "25" "26" [27] "27" "28" "29" "30" "31" "32" "33" "34" "35" "36" "37" "38" "39" "40" "41" "42" "43" "44" "45" "46" "47" "48" "49" "50" $xcoef [,1] [,2] [,3] 控制情绪 -0.4576880 -1.277214 2.767301 自我调节 -0.2118578 2.451745 -1.048019 自我激励 -0.3687696 -1.122893 -1.806735 $ycoef [,1] [,2] [,3] 语文 -0.2755155 -0.7599743 -0.9739351 数学 -0.1040424 0.6822849 0.4802843 英语 -0.1916330 -1.0607433 0.5995720 才艺 -0.6620838 0.7198947 -0.1194195 $scores $scores$xscores [,1] [,2] [,3] 1 0.97838292 -0.362539552 0.81938141 2 1.40651588 -0.410239408 0.05351720 ...... 49 -0.68982939 -1.133476875 0.34804581 50 -0.86681530 1.107521445 0.63269334 $scores$yscores [,1] [,2] [,3] 1 0.97479103 0.09430244 -0.08851950 2 1.40034960 -0.76140727 0.45769014 ...... 49 -0.64792179 -1.26188686 -0.66195176 50 -0.73030445 0.62990478 0.08452069 $scores$corr.X.xscores [,1] [,2] [,3] 控制情绪 -0.9798776 0.0006477883 0.199598477 自我调节 -0.9464085 0.3228847489 -0.007504408 自我激励 -0.9518620 -0.1863009724 -0.243414776 $scores$corr.Y.xscores [,1] [,2] [,3] 语文 -0.6348095 -0.1894059 -0.24988439 数学 -0.7171837 0.2086069 0.02598458 英语 -0.6436782 -0.4402237 0.22027544 才艺 -0.9388771 0.1734549 0.03614570 $scores$corr.X.yscores [,1] [,2] [,3] 控制情绪 -0.9744713 0.0005688272 0.076567107 自我调节 -0.9411869 0.2835272081 -0.002878734 自我激励 -0.9466102 -0.1635921013 -0.093375287 $scores$corr.Y.yscores [,1] [,2] [,3] 语文 -0.6383313 -0.2156981 -0.65140953 数学 -0.7211626 0.2375644 0.06773775 英语 -0.6472493 -0.5013329 0.57422365 才艺 -0.9440859 0.1975329 0.09422619 > # 4.检验典型相关系数在统计上是否显著 > library(CCP) > rho = mycca$cor > n = dim(rawdata)[1] > p = dim(xdata)[2] > q = dim(ydata)[2] > p.asym(rho, n, p, q, tstat = 'Wilks') Wilks' Lambda, using F-approximation (Rao's F): stat approx df1 df2 p.value 1 to 3: 0.002148472 87.391525 12 114.0588 0.000000e+00 2 to 3: 0.195241267 18.526265 6 88.0000 8.248957e-14 3 to 3: 0.852846693 3.882233 2 45.0000 2.783536e-02- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
从结果上来看,无论是SPSS还是R,计算的结果都是完全相同的。
参考文献:
[1]典型相关分析:https://www.bilibili.com/video/BV1LZ4y1S7Vd
[2]sklearn.cross_decomposition.CCA:https://scikit-learn.org/stable/modules/generated/sklearn.cross_decomposition.CCA.html
[3]协方差矩阵:https://baike.baidu.com/item/协方差矩阵/9822183
[4]典型相关分析(CCA)原理及Python实现:https://developer.aliyun.com/article/839949
[5]CCA典型关联分析原理与Python案例:https://cloud.tencent.com/developer/article/1652998
[6]典型关联分析(CCA)原理总结:https://www.cnblogs.com/pinard/p/6288716.html
[7]典型相关分析:https://www.docin.com/p-212673286.html
[8]数据文件cca_data.xlsx:https://url39.ctfile.com/f/2501739-631515818-1a4a0d?p=2096 (访问密码: 2096)
[9]SPSS输出结果文件:https://url39.ctfile.com/f/2501739-631515819-214c93?p=2096 (访问密码: 2096)
[10]R代码文件:https://url39.ctfile.com/f/2501739-631515820-50502e?p=2096 (访问密码: 2096) -
相关阅读:
【药材识别】基于matlab GUI SVM色差色温判断药材炮制程度系统【含Matlab源码 2241期】
【数据结构】HashSet的底层数据结构
VSFTP服务简介
分享5款有趣的软件,你都知道吗?
感知机的认识和简单的实现
黑豹程序员-Spring Task实现定时任务
2041. 面试中被录取的候选人
C++ Primer (第五版)第一章习题部分答案
Python:实现lorenz transformation 洛伦兹变换算法(附完整源码)
自动化测试项目学习笔记(三):加载测试用例的四种方法(unittest)
- 原文地址:https://blog.csdn.net/shengshengwang/article/details/126129801