-
零代码获取数据工具
相信大家很多情况下都会为了在一些网站上拿到其中想要的数据而非常头疼,因为不论你是开发者或不是开发者,都有一定的困扰,如果大数据工程师看见此篇文章可以直接忽略哈!!!
在这里给大家安利2款零代码数据爬取的工具,并附上使用教程,帮助一些没有爬虫基础的同学获取数据。
一、Microsoft Excel
没错,它就是我们电脑上都有的 Excel 表格,让我教教大家如何使用 Excel 爬取一些数据。
1)新建Excel,点击“数据”——“自网站”
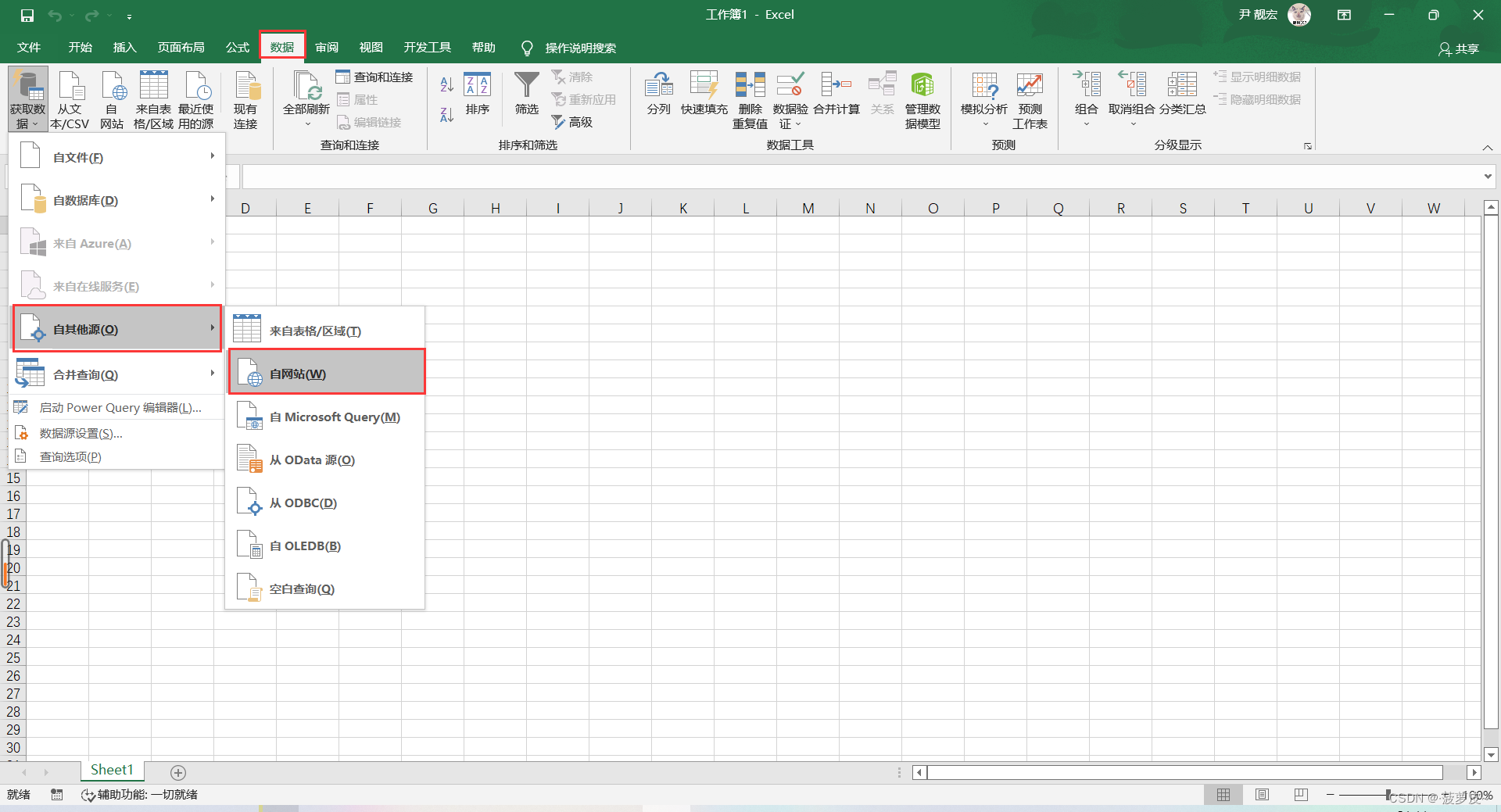
(2)在弹出的对话框中输入目标网址,连接上对网点之后就会获得网页数据,点击加载即可
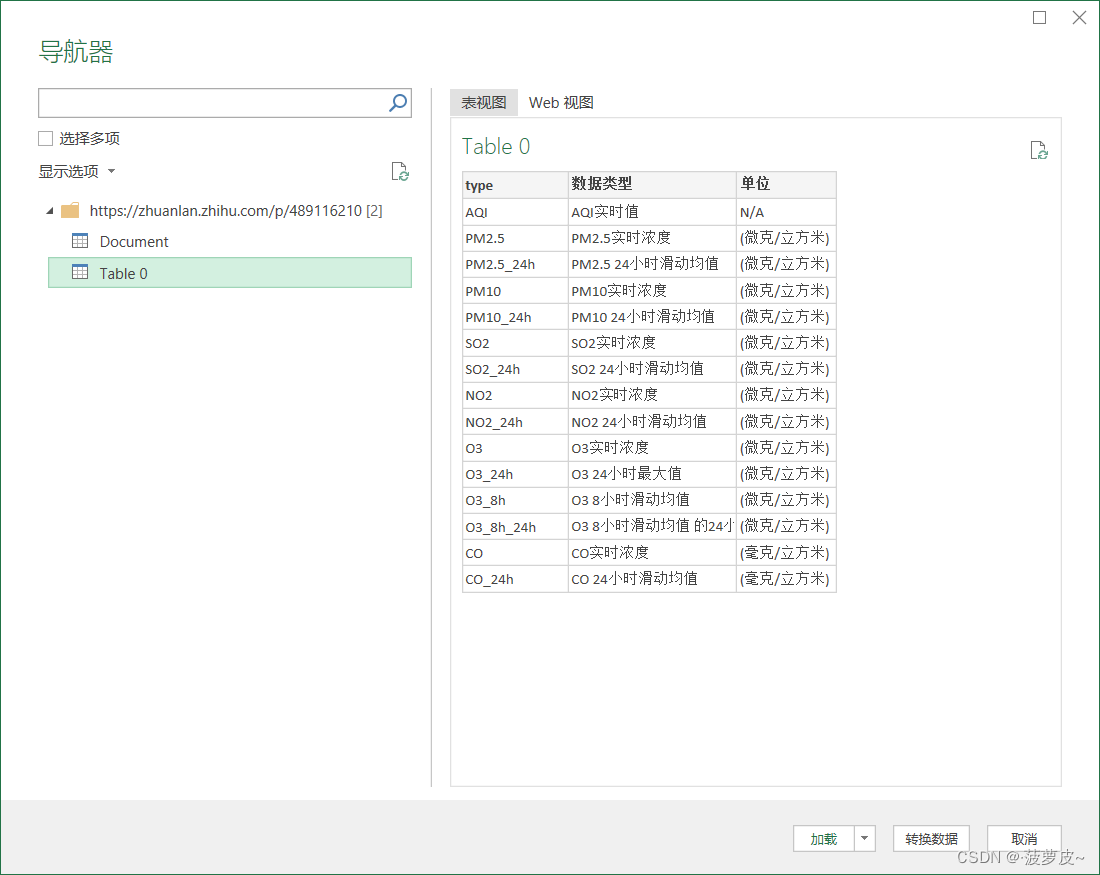
(3)结果如下图所示

缺点:这种方式虽然很简单,但是它会把页面上所有的文字信息都抓取过来,所以可能会抓取一部分我们不需要的数据,处理起来比较麻烦。总结:适合爬取一些表格数据,不适合做细节筛选的数据
二、八爪鱼采集器
网站:https://www.bazhuayu.com/
八爪鱼采集器是用过最简单易用的采集器,很适合新手使用。采集原理类似火车头采集器,用户设定抓取规则,软件执行。八爪鱼的优点是提供了常见抓取网站的模板,如果不会写规则, 就直接用套用模板就好了。它是基于浏览器内核实现可视化抓取数据,所以存在卡顿、采集数据慢的现象。不过整体来说还是不错的,毕竟能基本满足新手在短时间抓取数据的场景,比如翻页查询,Ajax 动态加载数据等。
操作步骤:
(1)登陆后找到主页面,选择主页左边的简易采集,如图:

(2)选择简易采集中淘宝图标,如图红框:
(3)进入到淘宝版块后可以进行具体规则模板的选择,根据楼主截图,应该手提包列表的数据信息采集,此时我们选择“淘宝网-商品列表页采集”,如图:
(4)然后会进入到信息设置页面,根据个人需要设置相关关键词,例如此处我们输入的商品名称为“手提包”,如图:
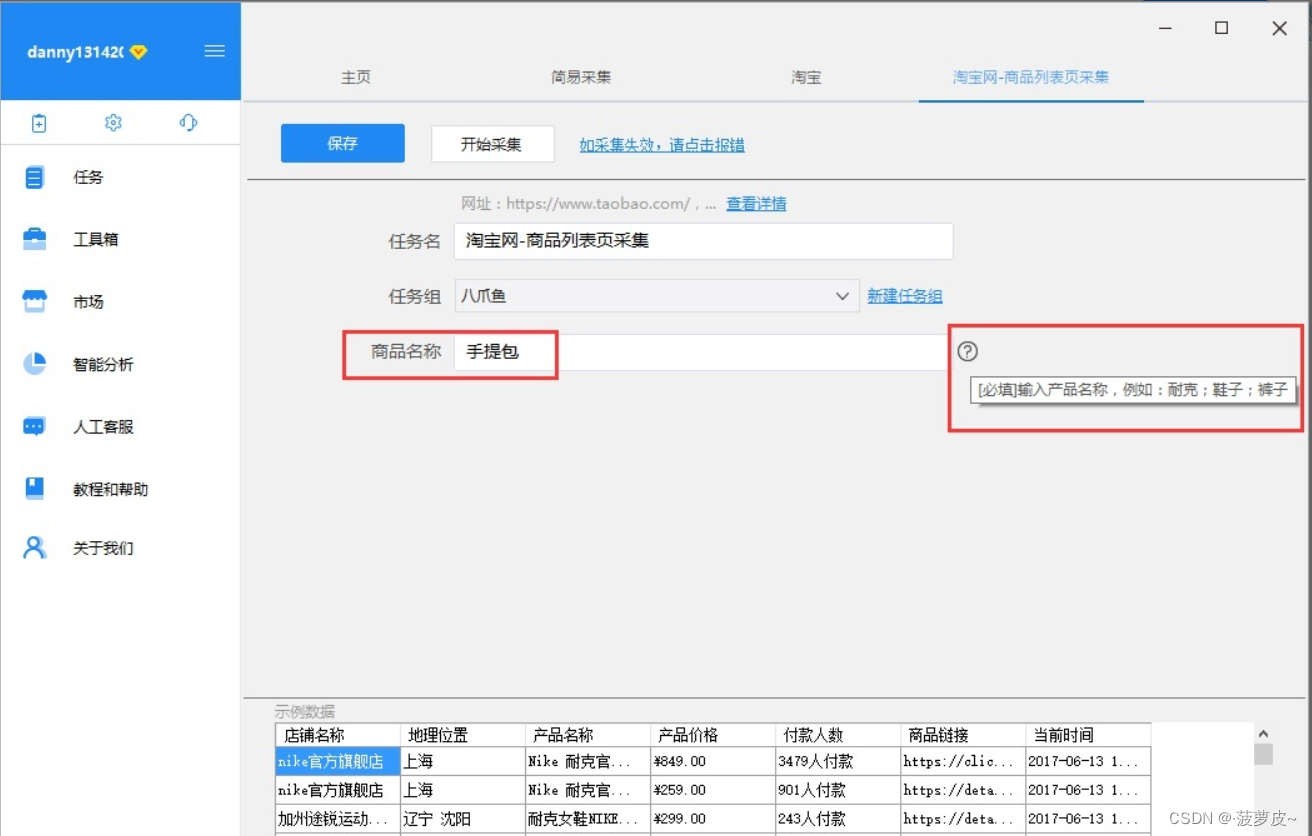
(5)点击保存并启动后就可以进行数据采集了,以下是本地采集效果示例,如图:

缺点:需要一定的费用
总结:能够详尽的获取到自己所需要的数据,且操作便捷。 -
相关阅读:
fatal: Authentication failed for ‘https://github.com
《Orange‘s 一个操作系统的实现》第六章
打造高效运营底座,极智嘉一体化软件系统彰显科技威能
盘点 10 个 GitHub 上的前端高仿项目
leetcode刷题记录
Redis中的慢查询日志(一)
【Java每日一题】——第三十三题:思考应用题(2023.10.17)
CSS盒子模型、列表样式
网络安全行业在经济下行期仍然稳步增长,快抓住风口入行
Spring Boot如何优雅实现动态灵活可配置的高性能数据脱敏功能
- 原文地址:https://blog.csdn.net/weixin_47627102/article/details/126130330