-
Week 7 - Distributional Representations(分布表示)
目录
一、Meaning and Lexical Semantics(词汇语义)
三、Count-based Distributed Representations(基于计数的分布式表示)
3、TF-IDF(Term Frequency-Inverse Document Frequency-词频-逆文档频率)
4、PMI(点互信息-Pointwise Mutual Information)
四、Sparse vs. Dense Representation(稀疏与密集表示)
2、SVD(奇异值分解-Singular Value Decomposition)
3、LSA( 截断:潜在语义分析-Latent Semantic Analysis)
3.2 CBOW(参考Week 6 Learning Representation: Word Embedding (symbolic →numeric)_金州饿霸的博客-CSDN博客)
七、Contextualized Word Embeddings(上下文词嵌入)
1、ELMo(语言模型的嵌入-Embeddings from Language Models)
2、BERT(Bidirectional Encoder Representation from Transforme)
一、Meaning and Lexical Semantics(词汇语义)
1、词汇数据库的问题
- 需要手工构建
- 成本高
- 人类的注解可能存在偏见和噪音
- 语言是动态的
- 新的单词:俚语、专业术语等等
- 新的词义(senses)
2、分布假设
- “You shall know a word by the company it keeps(你可以通过其周围的上下文单词来了解一个目标单词)” —— (Firth, 1957)
- 共现文档通常指示了主题(文档(document) 作为上下文)。
- 例如:voting(投票)和 politics(政治)
如果我们观察文档,会发现这两个单词经常出现在同一文档中。因此,不同单词的共现文档在一定程度上反映了这些单词在某种主题方面的关联。
- 例如:voting(投票)和 politics(政治)
- 局部上下文反映了一个单词的语义类别(单词窗口(word window) 作为上下文)。
- 例如:eat a pizza, eat a burger
可以看到,“pizza” 和 “burger” 这两个单词都具有共同的局部上下文 “eat a”,由此我们可以知道这两个单词都具有和 “eat a” 相关的某种含义。
- 例如:eat a pizza, eat a burger
3、根据上下文猜测单词含义
-
根据其用法来学习一个未知单词。
-
例如:现在我们有一个单词 tezgüino,我们并不知道其含义,我们试图通过从该单词的一些用法中学习到其含义。
下面是该单词出现过的一些例句:
作为人类,通过结合常识,我们可以大概猜测到 tezgüino 可能是某种含酒精饮品。
-
我们再查看一下在相同(或者类似)上下文中的其他单词的情况。

可以看到,单词 wine 出现过的类似场景最多。因此,尽管我们并不知道 tezgüino 的具体含义,我们还是可以认为 tezgüino 和 wine 在单词含义方面非常相近。
二、Vector Semantics(向量语义)
1、词向量
在前面的例子中,我们可以将这些由 0 和 1 组成的行视为词向量,因为它们能够很好地代表这些用例。例如:给定 100 个非常好的例句,我们可以基于这些单词是否出现在这些例句中,将其转换为 100 维的向量。
- 每一行都可以视为一个 词向量(word vector)。
- 它描述了单词的分布特性(目标单词附近的上下文单词信息)。
- 捕获各种语义关系,例如:同义(synonymy)、类比(analogy)等。
2、词嵌入

- 在之前的神经网络的章节中,我们已经见过另一种词向量:词嵌入(word embeddings)。
- 例如:在使用前馈神经网络进行文本分类时,第一层相当于是词嵌入层,该层的权重矩阵即词嵌入矩阵。
- 这里,我们将学习通过其他方法产生词向量:
- 基于计数的方法
- 专为学习词向量而设计的更高效的神经网络方法
三、Count-based Distributed Representations(基于计数的分布式表示)
1、向量空间模型
这里,我们学习的第一个模型是 向量空间模型(Vector Space Model,VSM)。
- 基本思想:将单词含义表示为一个向量。
- 通常,我们将 文档(documents)视为上下文。
- 一个矩阵,两种视角:
- 一个文档由其所包含的单词表示
- 一个单词由其出现过的文档表示

这里,每一行都表示语料库中的一个文档,每一列表示语料库的词汇表中的一个单词,单元格中的数字表示该单词在对应文档中出现的频率。例如:单词 state 没有在文档 425 中出现过,所以对应的值为 0,但是它在文档 426 中出现过 3 次,所以对应值为 3。
当我们构建完成这样一个矩阵后,我们可以从两种视角来看待它:如果我们观察每一行,我们可以将其视为每个文档的词袋模型(BOW)表示;如果我们观察每一列,我们可以将其视为每个单词的词向量表示。
2、操作 VSM(向量空间模型)
一旦我们构建了一个向量空间模型,我们可以对其进行一些操作:
- 给值进行加权(不仅是频率)
我们可以对矩阵中的值进行一些除了词频之外的更好的加权方式。 - 创建低维的密集向量
假如我们有非常多的文档,例如 100 万个,那么我们的词向量的维度也将会是 100 万维,因为每个维度都代表一个文档。但是,这样的话词向量的维度过高了,并且非常稀疏,其中大部分维度的值都是 0。 - 一旦我们完成了这些,我们就可以比较不同的词向量,并计算彼此之间的相似度等等。
3、TF-IDF(Term Frequency-Inverse Document Frequency-词频-逆文档频率)
首先,我们学习一种比单纯的词频更好的加权方法:TF-IDF (Term Frequency-Inverse Document Frequency)。它是 信息检索(information retrieval)领域的一种标准加权方案。

TF 矩阵
我们首先可以得到一个 TF(term-frequency)矩阵,和之前一样,单元格中的数字表示该单词在对应文档中出现的频率。
然后,我们将计算该单词对应的 IDF(inverse document frequency)值:

TF-IDF值:

其中,|D| 表示文档总数。dfw 表示单词 w 的文档频率,即该单词在所有文档(即语料库)中出现的总次数(TF 矩阵中最后一行)。这里,log 的底数为 2。
例如:假设一共有 500 个文档,单词 “the” 的 df 值为 500,那么这里单词 “the” 的 IDF 值为:
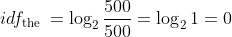
分别计算每个单词的 IDF 值,并将其和对应单元格的 TF 值相乘,我们可以得到下面的 TF-IDF 矩阵:

TF-IDF 矩阵
可以看到,单词 “the” 对应的列的值都为 0,这是因为其 IDF 值为 0,所以无论对应单元格的 TF 值为多少,相乘后得到的结果都是 0。
TF-IDF 的核心思想在于:对于在大部分文档中都频繁出现的单词(例如:“the”),我们给予更低的权重,因为它们包含的信息量很少。
4、PMI(点互信息-Pointwise Mutual Information)
4.1 PMI 公式
点互信息(Pointwise Mutual Information,PMI)的思想非常简单,对于两个事件 x 和 y(即两个单词),PMI 计算二者的差异:
- 它们的联合概率分布
- 它们各自的概率分布(假设彼此之间互相独立)
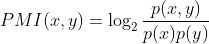
4.2 例子:计算 PMI
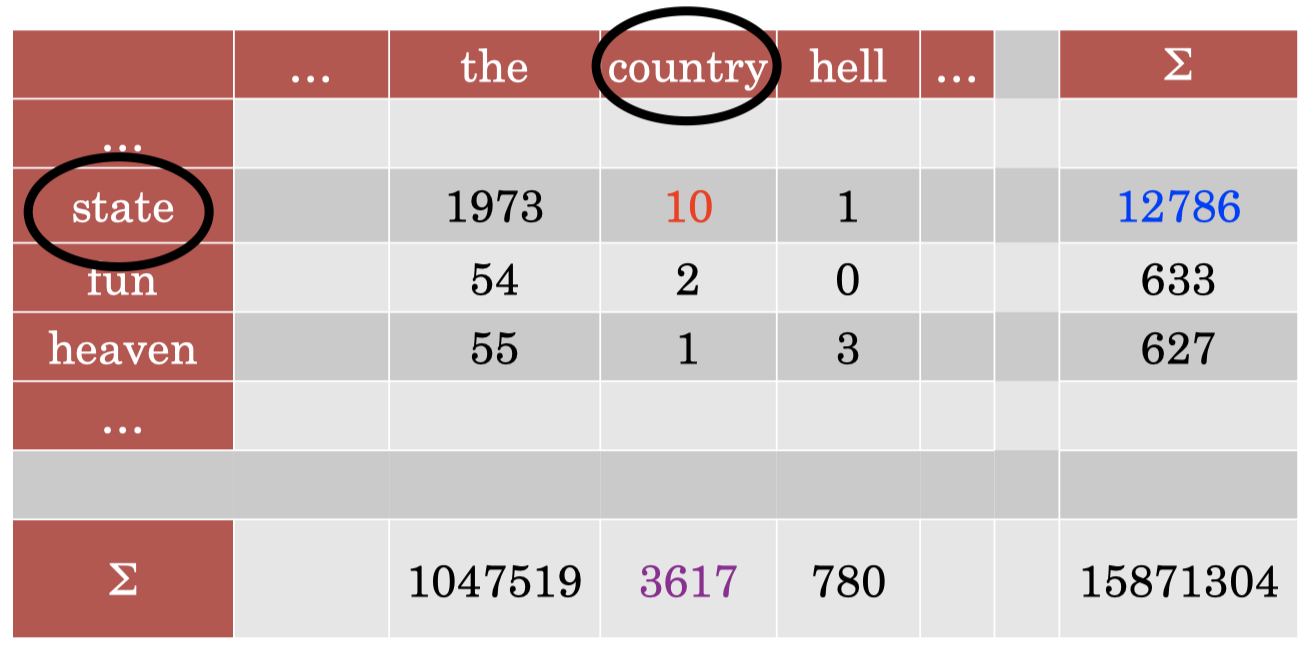
假设 x=state,y=country,我们可以得到:
4.3 PMI 矩阵
我们可以按照前面的方法计算所有单元格的 PMI,从而得到 PMI 矩阵。

对于从来没有共同出现过的单词对,其对应的 PMI 矩阵中的值为 −inf,因为在这种情况下,计算时分子 p(x,y) 的值为 0,而 log20=−∞。
- 可以看到,PMI 在捕获我们感兴趣的语义方面做得更好。
- 例如:单词 “the” 和其他单词之间的 PMI 都很小,单词 “heaven” 和 “hell” 之间的 PMI 值较大,因为二者在语义上很接近。
- 但是很明显,这种方法会偏向于给予低频单词较大的 PMI 值。
- 因为根据 PMI 计算公式,其分母部分为 p(x)p(y)。对于低频单词,其概率很小,这会导致计算 PMI 时分母变得非常小,从而导致很大的 PMI 值。
- 并且,无法很好地处理频率为 0 的情况(会得到 −∞ 的 PMI 值)。
4.4 PMI 技巧
们可以采取一些技巧来避免 PMI 的一些问题:
- 将所有负值取 0(PPMI)
- 避免了−inf 和不可靠的负值,该方法在实践中效果很好。
- 处理罕见事件的偏见问题
- 方法类似之前 n-grams 中的平滑概率。
5、单词作为上下文
我们已经学习了将文档作为上下文,我们还可以将单词作为上下文。
- 构建一个矩阵,关于目标单词随着其他单词一起出现的频率。
-
在某些预定义的上下文中(通常是一个窗口)。
相比将文档作为上下文,我们可以选择目标单词附近固定范围内的某些单词作为上下文。例如:我们可以选择窗口大小为 5,即目标单词前后长度为 5 的范围内的单词作为上下文单词。

可以看到,在上面的矩阵中,每一行都表示一个单词,每一列也表示一个单词。单元格中的数字表示目标单词和上下文单词在整个语料库中所有大小为 5 的窗口内(即从语料库中提取所有的 five-grams)共同出现的频率。
-
- 但是,原始频率存在一个明显的问题:整个矩阵被常见单词所主导。
- 例如:我们可以看到,由于单词 “the” 出现频率很高,使得对应单元格内的值非常大。之前,我们采用 TF-IDF 加权来给予常见单词的值一个折扣。但是这里,我们无法采用 TF-IDF,因为这里我们没有涉及到文档。相应地,这里我们可以采用点互信息(PMI)的方法来处理这个问题。
6、相似度
- 词相似度(Word similarity)= 词向量之间的比较(例如:余弦相似度,cosine similarity)。
- 根据向量空间中的 邻近度(proximity)查找 同义词(synonyms)。
- 自动构建词汇资源
- 将词向量作为分类器中的特征:相比其他输入形式(例如词频等)更具鲁棒性。
- 例如:movie vs. film 二者的词向量距离实际上非常近。
四、Sparse vs. Dense Representation(稀疏与密集表示)
1、降维
- Term-document 矩阵过于 稀疏(sparse)
- 降维(Dimensionality reduction):创建更短、更密集的向量。
- 更实用(特征更少)
- 消除噪声(更好地避免过拟合)
2、SVD(奇异值分解-Singular Value Decomposition)

我们已经学习了将文档作为上下文的 TF-IDF 矩阵,以及将单词作为上下文的 PMI/PPMI 矩阵。很重要的一点是,无论我们采用文档还是单词作为上下文信息,我们都可以利用 SVD 来创建密集向量。但是,通过不同的上下文信息所捕获到的关系是不一样的,如果我们采用 TF-IDF,我们捕获到的语义学信息会更加宽泛,通常和某种主题关联;如果我们采用 PMI/PPMI,我们捕获到的词向量更多是关于局部单词上下文的语义学信息。
奇异值分解(Singular Value Decomposition,SVD)是一种流行的降维方法。
SVD 的核心思想很简单:给定一个矩阵 A,我们可以将其分解为 3 个相乘的矩阵:U、Σ 和
 。
。A = U Σ
(有点类似于相似对角化)
可以看到:
- 原始矩阵 A 是 term-document 矩阵(出现为 1,没有出现为0),其行数为词汇表大小 |V|,列数为文档总数 |D|。
- U 是新的 term 矩阵,行数为词汇表大小 |V|,列数为 m,由A的特征向量组成。其中,m 为矩阵 A 的秩,即 m=Rank(A)。
- Σ 是大小为 m×m 的奇异值矩阵,它是一个对角矩阵,里面的值是A的特征值。
- 是新的 document 矩阵,由A的特征向量组成,行数为 m,列数为文档总数 |D|。
显然,经过 SVD,我们得到的新的 term 矩阵要比之前的 A 矩阵维度更小,并且更密集。
3、LSA( 截断:潜在语义分析-Latent Semantic Analysis)
我们还可以在 SVD 的基础上更进一步,采用 截断(truncating)方法,也被称为 潜在语义分析 (Latent Semantic Analysis, LSA)。
- 将 U、Σ 和 截断为 k 个维度,从而生成原始矩阵的最佳 k 阶近似。
- 因此,截断后的
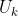 (或者
(或者 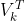 )是对应单词的一个新的低维表示。
)是对应单词的一个新的低维表示。 - 通常,k 的取值为 100-5000。
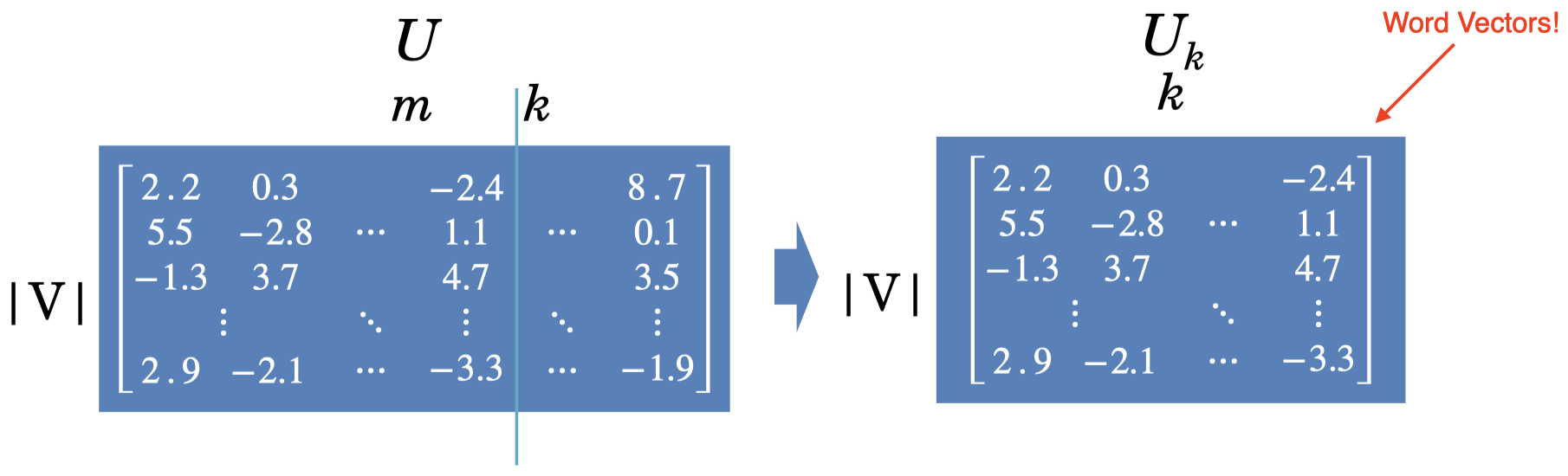
可以看到,矩阵
在矩阵 U 的基础上进一步压缩了,通常 k 取 100 或者 200 时已经足够很好地表示单词含义了。现在,矩阵 中的每一行都可以视为一个词向量。五、Word Embeddings(词嵌入)
1、词嵌入
- 在之前章节中,我们已经见过神经网络(前馈或循环)使用的 词嵌入 (word embeddings)。
- 但是这些模型是为其他任务设计的:
- 分类
- 语言模型
- 词嵌入只是这些模型的一部分。
2、用于嵌入的神经网络模型
- 理想模型:
- 无监督
我们希望该模型是无监督的,因为有监督模型需要标签信息,而标签信息需要依赖语言学专家进行手工标注。 - 高效
我们希望模型是高效的,因此,我们可以很容易地将其扩展到非常大的语料库上。 - 有用的表示
最重要的是,我们希望学习到的词嵌入能够用于各种下游任务中。
- 无监督
3、Word2vec(基于神经网络的语言模型)
- 关键思想:
- 目标单词的嵌入应与其 相邻单词 的嵌入 相似。
- 并且应当与不会出现在其附近的其他单词的嵌入 不相似。
- 在训练阶段,将向量点积用于向量 “比较”。

- 在测试阶段,我们仍然采用余弦相似度进行比较。
-
Word2Vec 的框架是学习一个分类器,有以下 2 种算法:

两种算法的学习过程基本上是一样的,但是前提条件略有差别,二者之间互为逆过程。
- Skip-gram :给定目标单词,预测该单词周围的局部上下文单词。
- CBOW:给定目标单词周围的局部上下文单词,预测位于中心的目标单词。
- 局部上下文是指和目标单词距离 L 个位置以内的单词,在上图的例子中,L=2。
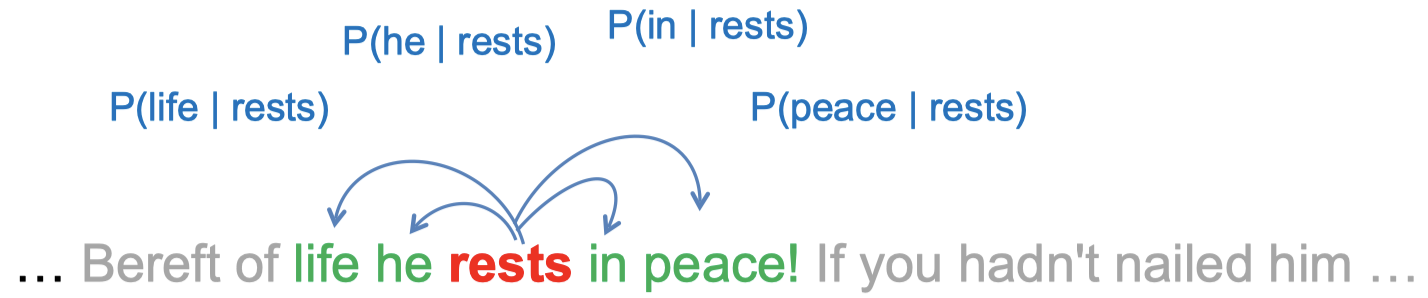
3.1 Skip-gram
(1) 模型
-
据给定的中心单词,生成相应的上下文单词。
-
全概率被定义为:

其中,
 是目标单词(中心单词),
是目标单词(中心单词), 是上下文单词,下标表示运行文本中的位置。
是上下文单词,下标表示运行文本中的位置。 -
使用一个 Logistic 回归模型来计算上面每一个乘积项(例如,
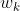 =he,
=he,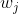 =rests):
=rests):
其中,
 和
和  分别表示单词 和 的词嵌入。
分别表示单词 和 的词嵌入。(2)模型的表示

输入层是目标单词
的 one-hot 向量,其维度为 1×|V|,所以其中只会有一个值被激活,即目标单词对应的位置索引(例如: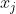 )。然后,经过目标单词嵌入矩阵
)。然后,经过目标单词嵌入矩阵 将其投影为一个 1×d 的嵌入向量。之后,我们将该嵌入向量和上下文单词嵌入矩阵
将其投影为一个 1×d 的嵌入向量。之后,我们将该嵌入向量和上下文单词嵌入矩阵 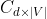 相乘,从而得到上下文单词
相乘,从而得到上下文单词 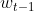 的一个 1×|V| 的概率向量,其中每个元素代表词汇表中相应位置的单词在这里出现的概率。我们可以对上下文单词进行相同的操作。然后,我们可以通过计算交叉熵来得到模型的损失。
的一个 1×|V| 的概率向量,其中每个元素代表词汇表中相应位置的单词在这里出现的概率。我们可以对上下文单词进行相同的操作。然后,我们可以通过计算交叉熵来得到模型的损失。(3)训练 Skip-gram 模型
- 训练目标是最大化 原始文本(raw text)的似然。
-
实践中非常缓慢,因为我们需要在整个词汇表 |V| 上进行 归一化(normalisation)。

当我们在给定目标单词的情况下,计算一个上下文单词的概率时,我们需要将词汇表中所有单词对应的词嵌入的点积进行累加,这个过程非常缓慢,因为在实践中,我们的词汇表可能包含 10,000 甚至 100,000 个单词,这样会使得词汇表的维度变得非常大。
- 因此,Skip-gram 模型的核心是将问题简化为二分类:相比直接进行 softmax 的相关计算,这里我们只是将真实上下文单词和非上下文单词,又称为 “负样本(negative samples)”,区分开来。
- 这些负样本单词是从词汇表 V 中随机抽取得到的。
因为词汇表通常非常大,所以从词汇表中随机抽样得到真实上下文单词的概率是非常低的。因此,我们可以假设随机抽样得到的单词都是负样本。
- 这些负样本单词是从词汇表 V 中随机抽取得到的。
(4)负采样
这里我们来看一个 负采样(Negative Sampling)的具体例子:

假设我们有以上例句,并且上下文窗口为目标单词前后各 2 个相邻单词。这里,我们的目标单词为 “apricot”,上下文单词为 “tablespoon”、“of”、“jam” 和 “a”。
正样本非常简单,就是由窗口中的目标单词和上下文单词构成的单词对。负样本的获取也非常简单,我们只是通过简单地将目标单词与从词汇表中随机抽取得到的单词进行配对,例如,这里我们进行 8 次随机抽样,从而得到 8 个负样本。这里我们的目标单词是 “apricot”,我们也可以对其他目标单词进行相同的操作。
之后,我们可以利用 logistic 函数分别计算正样本和负样本的概率:
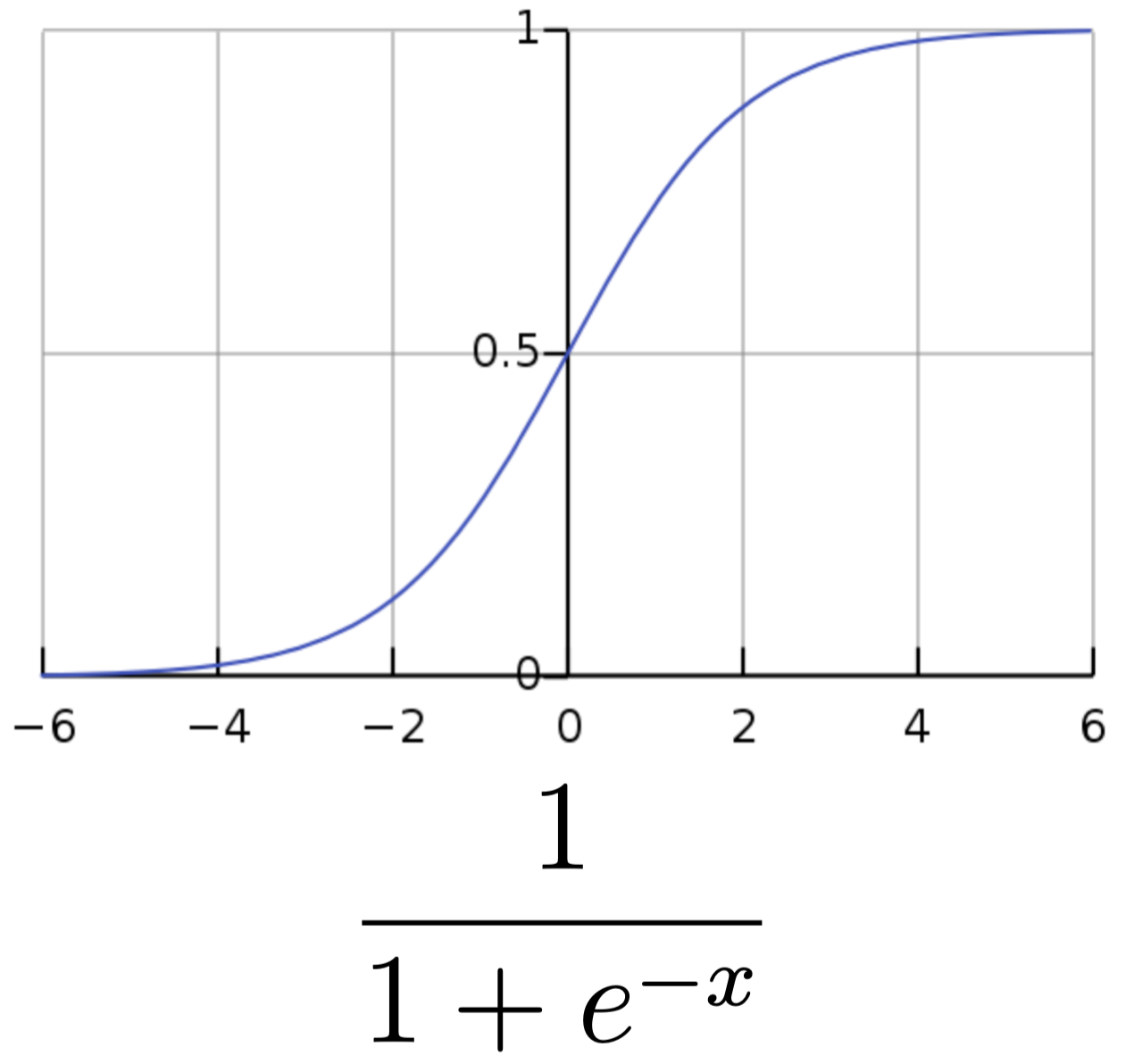
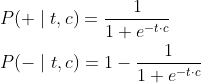
其中,t 和 c 表示目标单词和上下文单词(或者负样本)的词嵌入。
这里,我们将词嵌入 t 和 c 的点积 t⋅c 作为 logistic 函数的输入(即 x)。如果二者的点积 t⋅c 非常大(例如:“apricot” 和 “jam”),从上面的函数图像可以看到,我们得到的概率将非常接近 1,因为我们希望 最大化 目标单词和真实上下文单词之间的相似度。对于负样本,我们计算时用 1 减去 logistic 函数,目的是最小化 目标单词和非上下文单词之间的相似度。
(4)模型的损失函数
因此,我们可以通过简单地将正负样本的 log 概率相加来得到 Skip-gram 模型的总的损失函数:

但是,在实践中,相比仅仅采用一个负样本,我们通常会采用 k 个负样本:

(5)理想模型
- 无监督
- 原始的、无标签的语料库
正如前面所述,我们的模型无需标签,只要从给定的语料库按照窗口大小对其中出现的单词进行计数,并计算概率,进行学习即可。
- 原始的、无标签的语料库
- 高效
- 负采样(避免在整个词汇表上计算 softmax)
- 可以扩展到非常大的语料库上
还有一些在非常大的语料库上预训练的词向量,我们也可以直接下载使用。
3.2 CBOW(参考Week 6 Learning Representation: Word Embedding (symbolic →numeric)_金州饿霸的博客-CSDN博客)
4、GloVE(基于统计方法)
(1)基本思想
Glove是一个典型的基于统计的获取词向量的方法,基本思想是:用一个词语周边其他词语出现的次数(或者说两个词共同出现的次数)来表示每一个词语,此时每个词向量的维度等于词库容量,每一维存储着词库对应序号的词语出现在当前词语周围的次数,所有这些词向量组成的矩阵就是共现矩阵。
我们也可以换一个角度来理解共现矩阵,共现矩阵就是两个词同时出现的次数,共现矩阵的i行j列的数值表示词库中第i个词和第j个词同时出现的次数,同时共现矩阵是对角线为零的斜对称矩阵
大家可以通过下边这个例子来更直观的理解共生矩阵:
- (2)实现步骤
- 统计所有语料当中任意两个单词出现在同一个窗口中的频率,结果表现为共现矩阵 X
- 直接统计得到的共现矩阵 X,大小为 |V| x |V|(V=词库容量)
- 实践当中通常对原始统计矩阵施加 SVD(Singular Value Decomposition)来降低矩阵维度,同时降低矩阵的稀疏性
(3)优点
- 训练速度快
- 充分利用了全局的统计信息
(4)存在的问题
- 对于单一词语,只有少部分词与其同时出现,导致矩阵极其稀疏,因此需要对词频做额外处理来达到好的矩阵分解效果
- 矩阵非常大,维度太高
- 需要手动去掉停用词(如although, a,…),不然这些频繁出现的词也会影响矩阵分解的效果
5、 fastText(基于神经网络的语言模型)
fastText 设计之初是为了解决文本分类问题的,只不过在解决分类问题的同时 fastText 也能产生词向量,因此后来也被用来生成词向量。
fastText 和 word2vec 类似,也是通过训练一个神经网络,然后提取神经网络中的参数作为词语的词向量,只不过 fastText 训练网络的方法是对文本进行分类;此外 word2vec 的输入是多个词语的 noe-hot 编码,fastText的输入是多个单词及其n-gram特征;同时fastText为了解决类别过多导致的softmax函数计算量过大的问题,使用了层次softmax代替标准的softmax
fastText 和 word2vec 最主要的区别如下:- 输入增加了n-gram特征
- 使用 层次softmax做多分类
- 通过文本分类的方式来训练模型
六、评估词向量
1、内部评估(内部评估直接衡量单词之间的句法和语义关系)
- 最近的 上下文词向量(contextual word vectors)显示在神经网络上具有更好的效果。
例如:根据单词 “dog” 出现的地方,我们会得到不同的词向量。从句子 1 得到的单词 “dog” 的词嵌入和从句子 2 得到的单词 “dog” 的词嵌入可能差别很大,因为二者的上下文不同。BERT 在捕获这种上下文词向量上做得非常好。
- ELMO 和 BERT
-
similarity 相关性度量
使用向量空间中的余弦相似度测试单词对的兼容性。
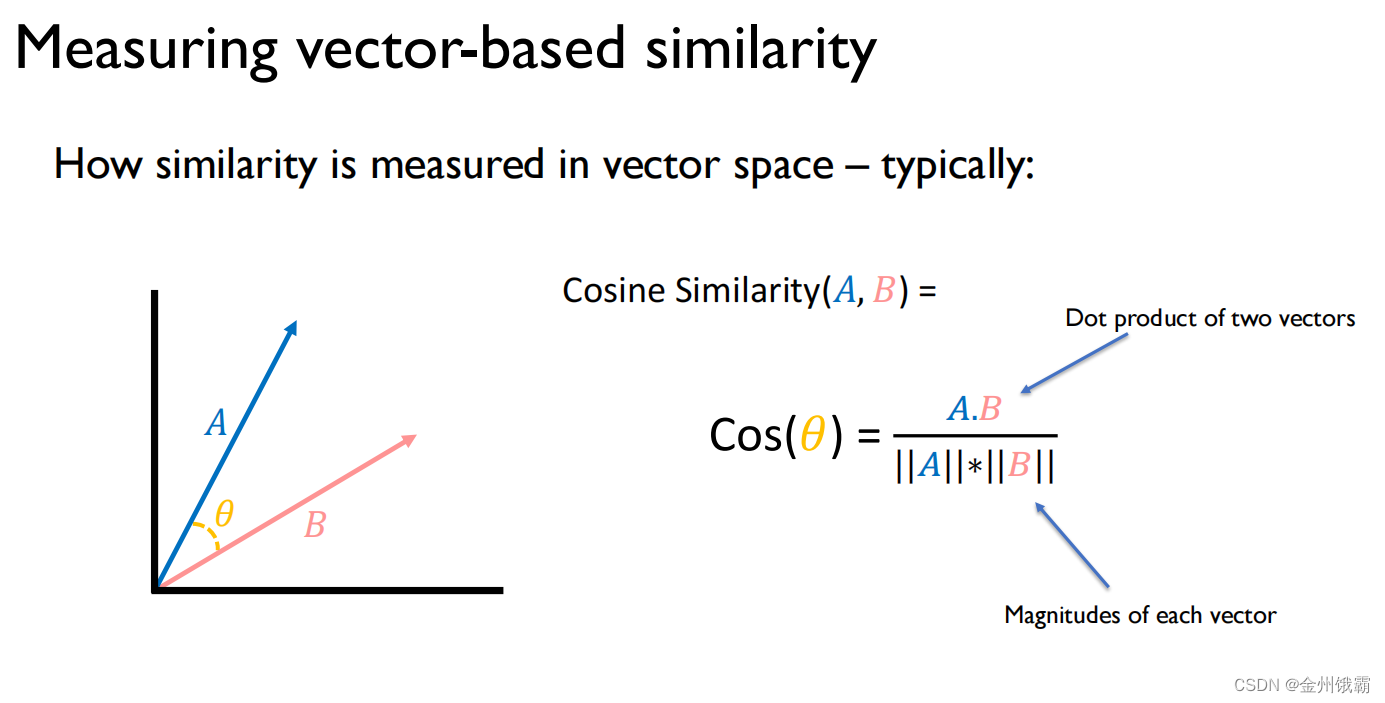
我们可以计算得到的词向量之间的余弦相似度,然后将其和人类评分的结果进行对比,例如:计算 Pearson 相关度。如果我们的计算的余弦相似度和人类评分二者的 Pearson 相关系数很高,则说明我们的词嵌入至少和人类从直觉上对单词相似度的判断接近。
- word analogy 类比推理
假设给了一对单词 (a , b) 和一个单独的单词c,task会找到一个单词d,使得c与d之间的关系相似于a与b之间的关系,举个简单的例子:(中国,北京)和 日本,应该找到的单词应该是东京,因为北京是中国的首都,而东京也是日本的首都。 在给定word embedding的前提下,task一般是通过在词向量空间寻找离(b-a+c)最近的词向量来找到d。
2、外部评估
- 对于词向量,最佳评估方式是基于其他下游任务中的表现进行评估。
- 使用词袋嵌入作为分类器中的特征表示。
- 大部分深度学习模型中的第一层是对输入文本进行嵌入表示;相比随机初始化所有权重系数,我们可以仅对部分参数进行随机初始化,而对于词嵌入层的初始权重,我们可以使用预训练的词向量作为嵌入的初始化,因为这样我们可以在少量数据上训练出相对准确的词嵌入。
七、Contextualized Word Embeddings(上下文词嵌入)
1、ELMo(语言模型的嵌入-Embeddings from Language Models)
(1) 优点
- 学习单词的复杂特征,包括语法、语义
- 学习在不同上下文下的一词多义
- ELMo 的各层参数实际上就是为各种有监督的下游任务准备的,因此ELMo 可以被认为是一种迁移学习(transfer learning)
- 通过这样的迁移策略,那些对词义消歧有需求的任务就更容易通过训练给第二隐层一个很大的权重,而对词性、句法有明显需求的任务则可能对第一隐层的参数学习到比较大的值(实验结论)
缺点
- lstm是串行机制,训练时间长,从这一点来看ELMo 注定成为不了大哥,
- 相比于Transformer,lstm提取特征的能力还是不够的
- ELMo 的两个RNN网络是分别计算的,导致计算时上下文的信息不会相互通信,进而导致ELMo 得到的词向量有一定的局限性
- 输出的结果只是讲两个RNN网络得到的结果拼接在一起,上下文信息并不会相互影响
(2) 模型
- Bidirectional language models(BLM)
首先给定N个单词的序列, (t1,t2,...,tN)
1)前向语言模型,已知前k-1个单词 (t1,t2,...,tk−1) ,预测第k个单词 tk 的概率:

2)后向语言模型,已知下文 (tk+1,tk+2,...,tN) ,预测第k个单词 tk :

双向语言模型(biLM)即将前向和后向语言模型联合起来,并最大化前后向语言模型的联合似然函数:

其中,公式中有两个LSTM 单元, θx 为输入的初始词向量参数, θs 为输出的softmax层参数(即,在LSTM的每一个步长输出的隐藏层h,再作为softmax的输入)。
- char-level(CNN) 初始词向量
在第一点中输入的初始词向量通过 char-level(CNN)获得(即,对单词内的字符通过CNN卷积操作得到词向量),如下图:

- ELMo
ELMo为多个双向语言模型biLM的多层表示
对于某一个单词tk,一个L层的双向语言模型biLM由2L+1个向量表示:

xkLM 为char-level初始词向量,前后向 hk,jLM 分别为前后向lstm的输出,ELMo将多层的biLM的输出R整合成一个向量:

再将 Rk 向量正则化后,输入softmax层,作为学到的一组权重

结构如下图所示

(3) ELMo词向量在NLP任务中的使用
- ELMOttask和初始词向量 xk (char-level词向量)直接拼接

- ELMOttask 和隐藏层输出 hk直接拼接

2、BERT(Bidirectional Encoder Representation from Transforme)
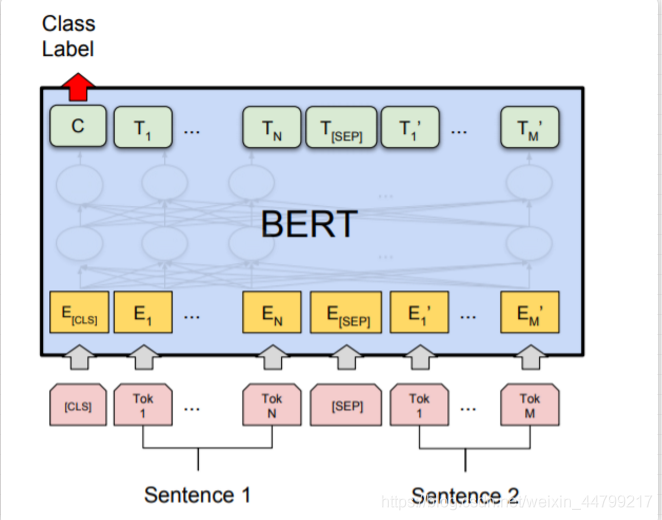
BERT 来自 Google 的论文Pre-training of Deep Bidirectional Transformers for Language Understanding,BERT 是“Bidirectional Encoder Representations from Transformers”的首字母缩写,整体是一个自编码语言模型(Autoencoder LM),并且其设计了两个任务来预训练该模型。
- 第一个任务是采用 MaskLM 的方式来训练语言模型,通俗地说就是在输入一句话的时候,随机地选一些要预测的词,然后用一个特殊的符号[MASK]来代替它们,之后让模型根据所给的标签去学习这些地方该填的词。
- 第二个任务在双向语言模型的基础上额外增加了一个句子级别的连续性预测任务,即预测输入 BERT 的两段文本是否为连续的文本,引入这个任务可以更好地让模型学到连续的文本片段之间的关系。
BERT 相较于原来的 RNN、LSTM 可以做到并发执行,同时提取词在句子中的关系特征,并且能在多个不同层次提取关系特征,进而更全面反映句子语义。相较于 word2vec,其又能根据句子上下文获取词义,从而避免歧义出现。同时缺点也是显而易见的,模型参数太多,而且模型太大,少量数据训练时,容易过拟合。
- 需要手工构建
-
相关阅读:
k8s之pod流量分析
深入理解指针(三)
python如何快速的判断一个key在json的第几层呢,并修改其value值
Java并发编程系列34:CountDownLatch使用
C++:函数符(一)
matplotlib绘制动态正弦曲线
群推王|如何引爆您的推特流量
图像分割 人脸分割CVPR2023笔记
分治:循环比赛
错误记录:从把项目从Tomcat8.5.37转到Tomcat10.1.7
- 原文地址:https://blog.csdn.net/wangjian530/article/details/126130480