-
关键数据结构 -- sk_buff
目录
unsigned char *head; unsigned char *end; unsigned char *data; ursigrned char *tail
union {...} h; union {…} nh; union {...} mac
unsigned int csum; unsigned char ip_summed
__u32 tc_index __u32 tc_verd __u32 tc_classid
分配内存: aloc_skb 和 dev_alloc_skb
释放内存: kfree_skb 和 dev_kfree_skb
数据预留及对齐:skb_reserve 、skb_put 、skb_push 以及 skb_pull
本文的内容全部来自《深入理解Linux网络技术内幕》, 代码片段源于version: linux-2.6.6,本着学习分享、加深印象的目的记录此文。如有侵权,联系删除。
struct sk_buff,一个封包就存储在这里。所有网络分层都会使用这个结构来储存其报头、有关用户数据的信息(有效载荷),以及用来协调其工作的其他内部信息。
这可能是 Linux 网络代码中最重要的数据结构,代表已接收或正要传输的数据的报头。此结构定义在<include/linux/skbuff.h>头文件中,由巨大的变量堆( heap )组成,试图满足所有人的所有需求。其字段可粗略划分为下列几种类型:布局( Layout ),通用( General ),功能专用( Feature - specific ),管理函数( Management functions )。
多个不同的网络分层( L2、L3、L4 )都会使用这个结构,而且当该结构从一个分层传到另一个分层时,其不同的字段会随之发生变化。L4在传给L3之前会附加一个报头,而L3在传给L2之前又会加上其自己的报头。附加报头比起把数据从一个分层拷贝到另一个分层更有效率。由于要在一个缓冲区开端新增空间 —— 也就是要改变指向该缓冲区的变量 —— 是一种复杂的运算,内核提供了 skb_reserve 函数来执行这一操作。所以,当缓冲区往下传经毎个分层时,每层的协议首先做的就是调用 skb_reserve 函数,为该协议的报头预留空间。
当缓冲区往上传经各个网络分层时,毎个源自于旧分层的报头就不再有用处。例如,L2报头只由处理L2协议的设备驱动程序使用,所以对L3而言并无用处。不过,并没有把L2的报头从缓冲区中删除,而是把指向有效载荷开端的指针向前移到L3报头的开端,这样做只需要很少的 CPU 周期。
- struct sk_buff
- {
- /* These two members must be first. */
- struct sk_buff *next;
- struct sk_buff *prev;
- struct sk_buff_head *list;
- struct sock *sk;
- struct timeval stamp;
- struct net_device *dev;
- struct net_device *real_dev;
- union
- {
- struct tcphdr *th;
- struct udphdr *uh;
- struct icmphdr *icmph;
- struct igmphdr *igmph;
- struct iphdr *ipiph;
- struct ipv6hdr *ipv6h;
- unsigned char *raw;
- } h;
- union
- {
- struct iphdr *iph;
- struct ipv6hdr *ipv6h;
- struct arphdr *arph;
- unsigned char *raw;
- } nh;
- union
- {
- struct ethhdr *ethernet;
- unsigned char *raw;
- } mac;
- struct dst_entry *dst;
- struct sec_path *sp;
- /*
- * This is the control buffer. It is free to use for every
- * layer. Please put your private variables there. If you
- * want to keep them across layers you have to do a skb_clone()
- * first. This is owned by whoever has the skb queued ATM.
- */
- char cb[48];
- unsigned int len,
- data_len,
- mac_len,
- csum;
- unsigned char local_df,
- cloned,
- pkt_type,
- ip_summed;
- __u32 priority;
- unsigned short protocol,
- security;
- void (*destructor)(struct sk_buff *skb);
- #ifdef CONFIG_NETFILTER
- unsigned long nfmark;
- __u32 nfcache;
- struct nf_ct_info *nfct;
- #ifdef CONFIG_NETFILTER_DEBUG
- unsigned int nf_debug;
- #endif
- #ifdef CONFIG_BRIDGE_NETFILTER
- struct nf_bridge_info *nf_bridge;
- #endif
- #endif /* CONFIG_NETFILTER */
- #if defined(CONFIG_HIPPI)
- union
- {
- __u32 ifield;
- } private;
- #endif
- #ifdef CONFIG_NET_SCHED
- __u32 tc_index; /* traffic control index */
- #endif
- /* These elements must be at the end, see alloc_skb() for details. */
- unsigned int truesize;
- atomic_t users;
- unsigned char *head,
- *data,
- *tail,
- *end;
- };
布局字段
struct sk_buff_head *list
每个sk_buff 结构都包含一个指针,指向专一的sk_buff_head结构,这个指针名为list,sk_buff 有些字段只是为了方便搜寻以及组织数据结构本身。内核在一个双向链表中维护所有的 sk_buff 结构,通过毎个 sk_buff 结构中的 next 和 prev 字段实现联系。 next 字段指向前,而 prev 指向后。但是,这个表还有另一项必要需求:每个 sk_buff 结构必须能够迅速找出整个表的头。为了实现这项必要需求,在表的开端额外增加一个 sk_buff_head 结构作为一种哑元元素。
sk_buff_head 结构是:
- struct sk_buff_head {
- /* These two members must be first. */
- struct sk_buff *next;
- struct sk_buff *prev;
- __u32 qlen;
- spinlock_t lock;
- };
qlen 代表表中元素的数目。 lock 是用于防止对表的并发访问。sk_buff 和 sk_buff_head 的前两个元素是相同的:next 和 prev 指针。尽管sk_buff_head 与 sk_buff 相比实在太小,但还是允许两个结构共同存在于同一个表中。另外,同样的函数也可用于操作 sk_buff 和 sk_buff_head 二者,下图为sk_buff 和 sk_buff_head 的关系:

struct sock * sk
这是一个指针,指向拥有此缓沖区的套接字的 sock 数据结构。当数据在本地产生或者正由本地进程接收时,就需要这个指针,因为该数据以及套接字相关的信息会由L4( TCP 或 UDP )以及用户应用程序使用。当缓沖区只是被转发时(也就是说本地机器不是来源地也不是目的地),该指针就是 NULL 。
unsigned int len
这是指缓冲区中数据区块的大小。这个长度包括主要缓冲区(由 head 所指)的数据以及一些片断(fragment)的数据。当缓冲区从一个网络分层移往下一个网络分层时,其值就会变化,因为在协议栈中往上移动时报头会被丢弃,但是往下移动时报头就会添加进来。 len 也会把协议报头算在内。
unsigned int data_len
与 len 不同的是, data_len 只计算片段中的数据大小。
unsigned int mac_len
MAC 报头的大小。
atomic_t users
这是引用计数,或者使用这个 sk_buff 缓冲区的实例的数目。这个参数的主要用途是避免在某人依然使用此 sk_buff 结构时,把这个结构给释放掉。因此,此缓冲区的每个用户在必要时都要递增和递减此字段。此计数器只计算 sk_buff 数据结构的用户,此缓冲区所包含的实际数据由一个相似的字段(dataref)所包含。users 有时会直接用 atomic_inc 和 atomic_dec 函数递增和递减,但在大多数情况下,采用 skb_get 和 kfree_skb 进行处理。
unsigned int truesize
此字段代表此缓冲区总的大小,包括 sk_buff 结构本身。当此缓冲区得到所分配的len个字节的数据请求空间时,此字段的初始化由 alloc_skb 函数设置成 len + sizeof(sk_buff)。毎当 skb->len 的值增加时,此字段就会得到更新。
- struct sk_buff * alloc_skb (unsigned int size ,int gfp_mask)
- {
- ... ...
- skb->truesize = size + sizeof(struct sk_buff);
- ... ...
- }
unsigned char *head; unsigned char *end; unsigned char *data; ursigrned char *tail
这些字段代表缓冲区的边界以及其其中的数据。当每一分层为其工作而而准备缓神区时,可能会为一个报头或更多的数据分配配更多的空间。 head 和 end 指向已分配缓冲区空间的开端和尾端,而 data 和tail则指向实际数据的开端和尾端。参见下图所示。
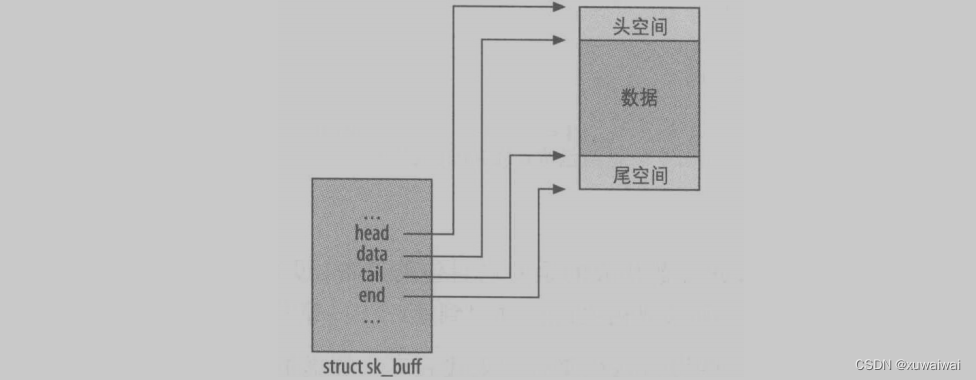
然后,该分层可以把 head 和 data之间的空隙填上一个协议报头,或者以新数据填入tail和 end 之间的空隙。图中右边的缓冲区在底端包含一个附加报头。
void (* destructor )(...)
此函数指针可以被初始化为一个函数,当此锾冲区被删除时,可完成某些工作。当此缓冲区不属于一个套接字时,destructor 通常不会被初始化。当此缓冲区属于一个套接字时,通常设成sock_rfree 或 sock_wfree (分别由 skb_set_owner_r 和skb_set_owner_w 初始化函数设置)。这两个 sock_XXXX 函数可用于更新套按字队列中所持有的内存。
通用字段
接下来讨论的 sk_buff 主要字段,而这些字段都与特定内核功能能无关:
struct timeval stamp
通常只对一个已接收的封包才有意义。这是一个时间戳,用于表示封包何时被接收,或者有时用于表示封包预定传传输的时间。此字段由 netif_rxx 函数用net_timestamp 设置,而该函数在接收毎个封包之后由设备驱动程序调用。
struct net_device *dev
此字段描述个网络设备,由dev 所代表的设备的角色,依赖于存储在该缓冲区内的封包是即将传输的还是刚被接收的而定。当接收到一个封包时,设备驱动程序会用代表此接收接口的数据结构的指针更新此字段;当传输一个封包时,此参数代表的是发送封包的设备。
struct net_device *input_dev
这是已被接收的封包所源自的设备。当封包是由本地产生时,其为 NULL 指针。就 Ethernet 设备而言,此字段在 eth_type_trans 中初始化。此字段主要由流量控制(Traffic Control)使用。
struct net_device *real_dev
此字段只对虚拟设备有意义,代表的是与虚拟设备所关联的真实设备。例如,Bonding 和 VLAN 接口使用该字段,用以记下真实设备的输人流量是从什么地方接收而得的。
union {...} h; union {…} nh; union {...} mac
这些是指向 TCP/IP 协议栈的协议报头的指针: h 针对L4,nh 针对L3,而 mac 针对L2。每个字段都指向一个由各种结构组成的联合( union ),每个协议的结构都由内核中该层来解释。例如,h 是一个联合,内核所解释的毎个L4协议的报头在 h 中都有一个字段。每个联合都有一个名为 raw 的成员用于初始化。而后续所有的访问都是通过协议指定的成员。
struct dst_enty dst
这个结构由路由子系统使用。
char cb[40]
这是一个“控制缓沖区( control buffer )”,或者说是私有信息的存储空间,为毎一层内部使用起维护的作用。该字段在 sk_buff 结构内静态分配(目前的大小是40个字节),而且容量足以容纳每个层所需的私有数据。在每一层的代码中都是通过宏进行访问的,这样使代码更具有可读性。例如, TCP 使用这个空间来存储一个 tcp_skb_cb 数据结构,该数据结构定义在 include/net/tcp.h 中:
- struct tcp_skb_cb {
- ... ... ...
- __u32 seq; /* Starting sequence number */
- __u32 end_seq; /* SEQ + FIN + SYN + datalen */
- __u32 when; /* used to compute rtt's */
- __u8 flags; /* TCP header flags. */
- ... ... ...
- }
以下是 TCP 代码用于访问该结构的宏。该宏由一些简单的指针组成:
#define TCP_SKB_CB(__skb) ((struct tcp_skb_cb *)&((__skb)->cb[0]))以下是 TCP 子系统在段的收条中填写此结构的实例:
- int tcp_v4_rcv(struct sk_buff *skb)
- {
- struct tcphdr *th;
- ... ... ...
- th = skb->h.th;
- TCP_SKB_CB(skb)->seq = ntohl(th->seq);
- TCP_SKB_CB(skb)->end_seq = (TCP_SKB_CB(skb)->seq + th->syn + th->fin +
- skb->len - th->doff * 4);
- TCP_SKB_CB(skb)->ack_seq = ntohl(th->ack_seq);
- TCP_SKB_CB(skb)->when = 0;
- TCP_SKB_CB(skb)->flags = skb->nh.iph->tos;
- TCP_SKB_CB(skb)->sacked = 0;
- ... ... ...
- }
unsigned int csum; unsigned char ip_summed
这些代表校验和( checksum )以及相关联的状态标识。
unsigned char cloned
当一个 boolean 标识置位时,表示该结构是另一个 sk_buff 缓冲区的克隆。
unsigned char pkt_type
此字段会根据帧的L2目的地址进行类型划分。可能的取值列于 include/linux/if_packet.h 中。对 Ethernet 设备而言,此参数由函数 eth_type_trans 进行初始化。
__u32 priority
此字段表示正被传输或转发的封包 QoS ( Quality of Service ,服务质量)等级。如果该封包由本地产生,套接字层会定义优先级的值。相反的,如果此封包正被转发,则函数 rt_tos2priority(由 ip_forward 函数调用) 会根据 IP 报头本身的 ToS ( Type of Service ,服务类型)字段的值而定义此字段的值。
unsigned short protocol
从L2层的设备驱动程序的角度来看,就是用在下一个较高层的协议。典型的协议有 IP 、IPv6以及 ARP;完整的列表可以在 include/linux/if_ether.h 中找到。由于毎种协议都有自己的函数处理例程用来处理输入的封包,因此,驱动程序使用这个字段通知其上层该使用哪个处理例程。每个驱动程序会调用 netif_rx 用来启动上面的网络分层的处理例程,所以,在该函数被调用前 protocol 字段必须初始化。
unsigned short security
这是封包的安全级。最初引人这个字段是为了 IPsec ,但是现在已不再使用了。
功能专用字段
Linux 内核是模块化的,允许你选择要包含什么及要省略什么。因此,只有当内核编译为支持特定功能,如防火墙( Netfilter )或 QoS ,某些字段才会包含在 sk_buff 数据结构中。
unsigned long nfmark
__u32 nfcache
__u32 nfctinfo
struct nf_conntrack *nfct
unsigned int nfdebug
struct nf_bridge_info *nf_bridge这些参数由 Netfilter(防火墙代码)使用,更明确地讲就是指由内核选项“ Device Drivers -> Networking support -> Networking options -> Network packet filtering ”及其两个子选项“ Network packet filtering debugging ”“ Bridged IP/ARP packets filtering ”所用。
union {...} private
这个联合由 HIPPI ( High Performance Parallel Interface ,高性能并行接口)使用。相关联的内核选项为“ Device Drvers -> Networking support -> Network device support -> HIPPI driver support ”。
__u32 tc_index
__u32 tc_verd
__u32 tc_classid
这些参数由流量控制功能使用,更明确地讲就是指由内核选项“ Device Drivers -> Networking support -> Networking options -> QoS and/or fair queueing ”及其子选项“ Packet classifier API ”使用。struct sec_path * sp
由 IPsec 协议组使用,以记录转换信息。
管理函数
内核通常提供许多很短、很简单的函数,用以操作 sk_buff 元素或元素列表。
首先,我们来看用于分配和释放缓冲区的函数,然后是用于在帧头部或尾部预留空间的操作指针(即 skb -> data )函数。在文件 include/linux/skbuff.h 和 net/core/skbuff.c 文件中,几乎所有函数都有两个版本,名称类似 do_something 和 __do_something 。通常来讲,第一个是包裹函数,增加了额外的合理性检査或者在调用第二个函数前后加入上锁机制。内部所用的__do_something 形式通常不会被直接调用(除非满足特定条件,例如,上锁条件或命名)。
分配内存: aloc_skb 和 dev_alloc_skb
定义在 net/core/skbuf.c 中的 allo _skb 是分配缓冲区的主要函数。数据缓冲区和报头( sk_buff数据结构)是两种不同的实例,也就是说,建立一个缓沖区会涉及到两次内存分配(一个是分配缓沖区,而另一个是分配 sk_buff 结构)。
alloc_skb 通过调用 kmem_cachealloc 函数,从一个缓存中取得一个 sk_buff 数据结构,然后调用 kmalloc (如果有缓存可用也会使用)以取得一个数据缓冲区。其代码如下(略为简化):- skb = kmem_cache_alloc(skbuff_head_cache, gfp_mask &~_GFP_DMA);
- size = SKB_DATA_ALIGN(size);
- data = kmalloc(size + sizeof(struct skb_shared_info), gfp_mask);
调用 kmalloc 之前, size 参数被 SKB_DATA_ALIGN 宏进行调整以强制对齐。返回之前,此函数会对结构中的一些参数做初始化,产生的最后结果如图所示。
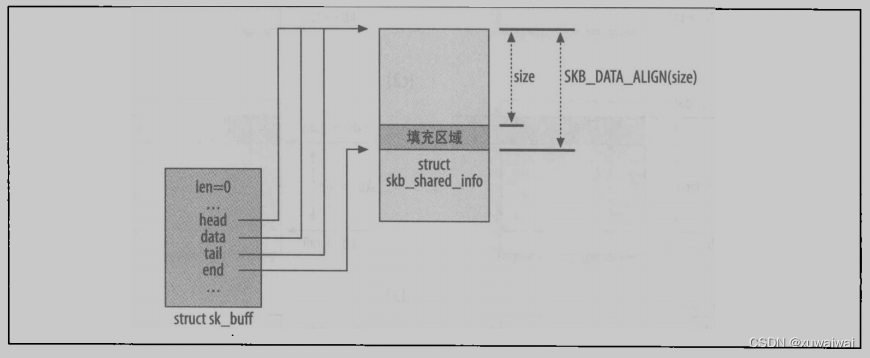
在图右侧内存区块的底端,你可以发现引人了填充区域( padding area )以强制对齐。 skb_shared_info 块主要用于处理一些 IP 片段。dev_alloc_skb 是由设备驱动程序使用的缓冲区分配函数,而且应该是在中断模式中执行。此函数只是一个包裹 alloc_skb 的函数,为了优化的原因在申请的大小之上再加16个字节。而且因为此函数是由中断事件处理函数调用的,所以会要求原子操作( GFP_ATOMIC ):
- static inline struct sk_buff *dev_alloc_skb(unsiged int length)
- {
- return __dev_alloc_skb(length, GFP_ATOMIC);
- }
- static inline struct sk_buff *__dev_alloc_skb(unsigned int length, int gfp_mask)
- {
- struct sk_buff *skb = alloc_skb(length + 16, gfp_mask );
- if (1ikely(skb))
- skb_reserve(skb, 16);
- return skb;
- }
当没有体系结构说明( architecture - specific )定义时,__dev_alloc_skb 的定义就是默认的。
释放内存: kfree_skb 和 dev_kfree_skb
这两个函数会释放一个缓冲区,使其返回缓冲池(缓存)。dev_kfree_skb是一个宏,直接调用kfree_skb。
- static inline void kfree_skb(struct sk_buff *skb)
- {
- if (atomic_read(&skb->users) == 1 || atomic_dec_and_test(&skb->users))
- __kfree_skb(skb);
- }
- #define dev_kfree_skb(a) kfree_skb(a)
只有当 skb->users 计数器为1时(该缓冲区已无任何用户时),这个基本函数才会释放一个缓冲区。否则,就只是递减该计数器。所以,如果一个缓沖区有三位用户,则只有第三次调用 dev_kfree_skb 或 kfree_skb 时オ会释放内存。
数据预留及对齐:skb_reserve 、skb_put 、skb_push 以及 skb_pull

skb_reserve 会在缓冲区的头部预留一些空间(头空间),通常允许插人一个报头,或者强迫数据对齐某个边界。此函数会移动标记有效载荷开端指针 data 和尾端指针 tail。调用 skb_reserve (skb, n)之后的结果。缓沖区分配之后,通常马上就会调用此函数,此时 data 和 tail 的值仍然相同。
如果你看过几种 Ethernet 驱动程序之一的接收函数,会发现,它们把任何数据存储在刚分配到的缓冲区之前,都会使用下列命令:skb_reserve ( skb ,2); /*把 IP 对齐在16学节地址边界上*/
由于知道要把一个带有14个字节头的 Ethernet 帧拷贝到缓冲区中,参数2会使缓冲区的头移动2个字节。这样 IP 报头就可以从缓冲区开始按照16字节边界对齐,并紧接在Ethernet 报头之后,如图所示。

skb_reserve 函数没有真正把任何东西移人数据缓冲区内,只是更两个指针而已。这个函数在刚分配好缓冲区后使用。
- static inline void skb_reserve(struct sk_buff *skb, unsigned int len)
- {
- skb->data += len;
- skb->tail += len;
- }
skb_push 会把一个数据块添加到缓冲区的开端,而 skb_put 会把一个数据块添加到缓沖区的尾端。像 skb_reserve 一样,这些函数并没有真的把数据添加到缓冲区,只是简单地移动指向其头或尾的指针。新的数据应该由其他函数明确地拷贝进来。 skb_pull 是通过 head 指针向前移,把一个数据块从缓冲区的头部删除。
skb_shared_info 结构和 skb_shinfo 函数
在分配缓冲区时在数据缓冲区尾端有个名为 skb_shared_info 的数据结构,用以保持此数据区块的附加信息。此数据结构紧接在标记数据尾端的 end 指针之后。此数据结构的定义如下:
- /* This data is invariant across clones and lives at
- * the end of the header data, ie. at skb->end.
- */
- struct skb_shared_info {
- atomic_t dataref;
- unsigned int nr_frags;
- unsigned short tso_size;
- unsigned short tso_segs;
- struct sk_buff *frag_list;
- skb_frag_t frags[MAX_SKB_FRAGS];
- };
sk_buff 结构中没有指向 skb_shared_info 数据结构的字段。为了访问该结构,函数必须使用返回 end 指针的 skb_shinfo 宏:
#define skb_shinfo(SKB) ((struct skb_shared_info *)((SKB)->end))例如,显示出该宏如何用于增加私有块的一个字段: skb_shinfo(skb)->nr_frags++;
缓冲区的克隆和拷贝
skb_clone 函数
当同一个缓冲区需要由不同消费者个别处理时,那些消费者可能需要修改 sk_buff 描述符的内容(指向协议报头的 h 和 nh 指针),但内核不需要完全拷贝 sk_buff 结构和相关联的数据缓冲区。相反,为了提高效率,内核可以克隆( clone )原始值,也就是只拷贝 sk_buff 结构,然后使用引用计数,以免过早释放共享的数据块。缓冲区的克隆由 skb_clone 函数实现。
使用克隆的情况的一个例子就是,当一个输入封包需要传递给多个接收者时,如协议处理例程和一个或多个网络分流器。
sk_buff 的克隆没有链接到任何表( list ),而且也没有引用套接字的拥有者。 skb->cloned 字段在克隆的和原有的缓冲区内都置为1。而只有克隆的 skb->users 置为1,使得第一次尝试删除就能成功,但是,对包含数据的缓冲区的引用数目( dataref )则会递增(因为从现在起,又有一个 sk_buff 数据结构指向该区)。下图所示是克隆缓冲区的一个实例。
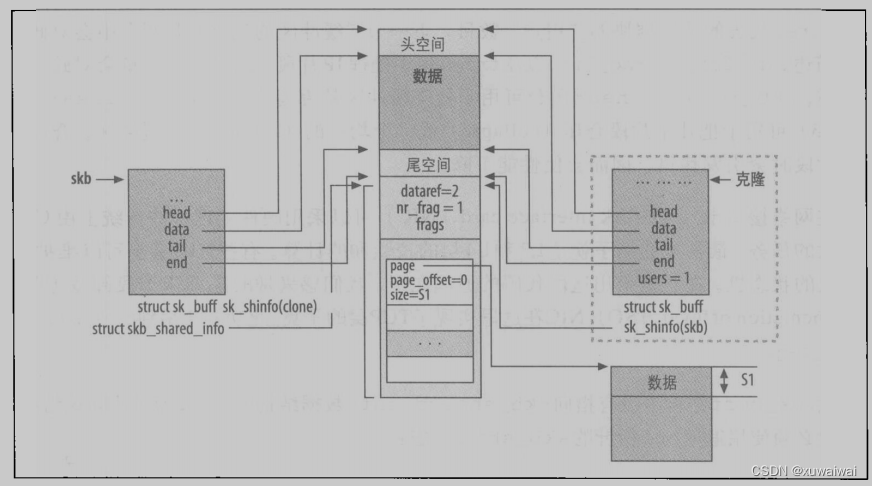
skb_clone 函数可用于检査一个 skb 缓冲区的克隆状态,上图所示为片段缓冲区的一个实例,也就是说,这个缓冲区内有一些数据是存储在一些以 frags 数组链接起来的数据片段。skb_share_check 函数可用于检査引用计数 skb->users ,并且当 users 字段说明该缓冲区是共享时可以克隆该缓冲区。
当一个缓冲区被克隆时,数据区块的内容不能修改。这意味着访问该数据的代码不需要上锁机制。然而,当函数不仅需要修改 sk_buff 结构的内容,而且也需要修改数据时,就必须连数据区块一起克隆。在这种情况下,程序员有两种选择:
1、当他知道他只需修改介于 skb->start 和 skb->end 的区域的数据内容时,可以使用 pskb_copy 只克隆该区域;
2、当他认为他可能必须连片段数据区块的内容也跟着修改时,就必须使用 skb_copy。
pskb_copy 和 skb_copy 的结果如图所示。skb_shared_info 数据结构也可以括一个 sk_buff 结构列表(链接到一个 frag_list字段)。 pskb_copy 和 skb_copy 处理该列表的方式和frags数组的处理方式相同。

列表管理函数
这些函数会操作 sk_buff 元素列表,列表也称为队列( queue )。函数的完整列表参见
和<net/core/skbuff.c> 。一些最常用的函数如下 skb_queue_head_init
用一个元素为空的队列对 sk_buff_head 。skb_queue_head , skb_queue_tail
把一个缓冲区分别添加到队列的头或尾。skb_dequeue , skb_dequeue_tail
把一个元素分别从队列的头或尾去掉。第二个函数可能应该称为 skb_dequeue_head ,
才能与其他队列函数之名相称。skb_queue_purge
把队列变为空队列。skb_queue_walk
依次循环运行队列里中的毎个元素。这类函数都必须以原子方式执行;也就是说,它们必须为此队列抓住 sk_buff_head 结构所提供的回转锁。否则,可能会被向队列添加元素或从队列中删除元素等异步事件所中断,如到期的定时器所调用的函数,将导致竟争的情况( race condition )。
因此,毎个函数按照以下方式实现:
- static inline function_name(parameter_list)
- {
- unsigned long flags ;
- spin_lock_irqsave(...);
- __function_name(parameter_list)
- spin_unlock_irqrestore(...);
- }
此函数内有一个包裹函数会取得回转锁,然后调用一个以两个下划线符号开头命名的函数,接着再放开该锁。
-
相关阅读:
LeetCode - 79 单词搜索
acwing算法基础之基础算法--前缀和算法
【毕业设计】基于stm32的WiFi监控小车 - 物联网 单片机 嵌入式
NAS折腾记录(一)基础概念介绍
【云原生之k8s】k8s资源限制以及探针检查
数据分析的基本要求:学习数据分析需要掌握哪些能力
数据结构学习笔记——图的遍历(深度优先搜索和广度优先搜索)
win环境安装Node.js的多种方式
Node.js如何处理多个请求?
SQL Server多实例之间触发器同步数据
- 原文地址:https://blog.csdn.net/xuwaiwai/article/details/126101260