-
SOM网络1:原理讲解
SOM 介绍
SOM(Self Organizing Maps):自组织映射神经网络,是一种类似于kmeans``的聚类算法,用于寻找数据的聚类中心。它可以将相互关系复杂非线性的高纬数据,映射到具有简单几何结构及相互关系的低纬空间。(低纬映射能够反映高纬特征之间的拓扑结构)- 自组织映射(Self-organizing map, SOM)通过学习输入空间中的数据,生成一个
低维、离散的映射(Map),从某种程度上也可看成一种降维算法。 SOM是一种无监督的人工神经网络。不同于一般神经网络基于损失函数的反向传递来训练,它运用竞争学习(competitive learning)策略,依靠神经元之间互相竞争逐步优化网络。且使用近邻关系函数(neighborhood function)来维持输入空间的拓扑结构。- 由于基于
无监督学习,这意味着训练阶段不需要人工介入(即不需要样本标签),我们可以在不知道类别的情况下,对数据进行聚类;可以识别针对某问题具有内在关联的特征。 可以实现数据可视化;聚类;分类;特征抽取等任务
特点归纳
- 神经网络,竞争学习策略
- 无监督学习,不需要额外标签
- 非常适合高维数据的可视化,能够维持输入空间的拓扑结构
- 具有很高的泛化能力,它甚至能识别之前从没遇过的输入样本
网络结构
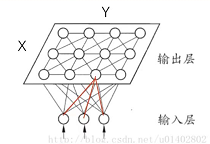
SOM的网络结构有
2层:输入层、输出层(也叫竞争层),。输入层:包含D个节点,节点数由输入特征的维度决定,跟输入特征维度相同。输出层:通常下将输出层的节点排列层X行Y列的矩阵形式,输出层有X x Y个节点。
网络的特点
- (1) 输出层的每个节点,通过
D条权边,与所有样本点D维特征向量相连。,输出层 i , j i,j i,j 位置的节点向量:
W i j = [ w i j 0 , w i j 0 , . . . w i j D ] W_{ij} = [w_{ij0},w_{ij0},...w_{ijD}] Wij=[wij0,wij0,...wijD]
换句话说:输出层 i , j i,j i,j 位置的节点可以用一个D维矢量 W i j W_{ij} Wij来表征` - (2)
经过训练后,输出层的各个节点之间,按照距离远近具有一定的关联,即离的越近,关联度越高,也可以表述为离的越近两个点,这个两个点的D维矢量的距离会越近。 - (3)
训练的目的:学习X x Y个D维权重 W W W,可以将所有的训练的样本(每个样本D维特征向量)映射到输出层的节点上。
高纬空间(输入)距离近的点,映射到输出层后距离也较近。比如两个样本点比较近都映射到 ( i , j ) (i,j) (i,j)上,或者映射到 ( i , j ) (i,j) (i,j)和 ( i , j + 1 ) (i,j+1) (i,j+1)上。
模型训练过程
- 1 准备训练数据datas:
N x DN为样本的数量,D为每个样本的特征向量维度
通常需要正则化:
d a t a s = d a t a s − m e a n ( d a t a s ) s t d ( d a t a s ) datas=\frac{datas-mean(datas)}{std(datas)} datas=std(datas)datas−mean(datas) - 2.确定参数 X , Y X,Y X,Y X = Y = 5 N X=Y=\sqrt{5\sqrt{N}} X=Y=5N , 向上取整
- 3.权重 W W W 初始化: W W W的维度为(X x Y x D)
- 4.迭代训练
1) 读取一个样本点 x x x : [D] # D维
2) 计算样本 x x x 分别与输出层的 X ∗ Y X*Y X∗Y个节点计算距离,找到距离最近的点 ( i , j ) (i,j) (i,j)作为激活点,设其权重 g g g为1
3) 对输出层其他节点,利用其与位置 ( i , j ) (i,j) (i,j)处的节点距离,计算他们的权重 g g g,与 ( i , j ) (i,j) (i,j)位置距离越近,则权重越大。 完成计算输出层的X*Y节点权重 g g g,特点是以 ( i , j ) (i,j) (i,j)处的权值最大,以其为中心越远越小
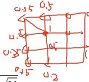
- 4) 更新输出层所有节点的表征向量:
W = W + η ∗ g ∗ ( x − W ) W=W +\eta*g*(x-W) W=W+η∗g∗(x−W)
其中 η \eta η是学习率, x − W x-W x−W表示当前更新的输出层节点与输入样本x的距离,更新节点的表征向量的目的是让节点逼近输入向量 x x x
整个
SOM映射过程,相当于对输入的N个样本进行聚类映射,比如输入样本 x 1 x1 x1, x 2 x2 x2, x 3 x3 x3 映射为输出节点a, 样本 x 4 x4 x4, x 5 x5 x5, x 6 x6 x6映射为输出节点b,则可以用输出节点a来表征样本 x 1 x1 x1, x 2 x2 x2, x 3 x3 x3;用输出节点b来表征样本 x 4 x4 x4, x 5 x5 x5, x 6 x6 x6- 经过多轮迭代,完成了对输出节点表征向量
W
W
W的更新,这些节点的表征向量可以表征输入的样本x
(N x D)。相当于把输入样本,映射为(XxYxD)的表征向量 W = w 1 , 1 , w 1 , 2 , , , w x , y W=w_{1,1},w_{1,2} ,,, w_{x,y} W=w1,1,w1,2,,,wx,y
权重初始化 W:[X,Y,D]
权重初始化主要有
3种方法:- 1 随机初始化,然后标准化 W = W ∣ ∣ W ∣ ∣ W=\frac{W}{||W||} W=∣∣W∣∣W
- 2 从训练数据中随机挑选 X ∗ Y X*Y X∗Y个,来初始化权重
- 3 对训练数据进行
PCA,取特征值最大的两个特征向量M:D x 2 作为基向量进行映射。
距离计算方式
采用欧式距离计算 ,公式如下:
d i s = ∣ ∣ x − y ∣ ∣ dis =|| x-y || dis=∣∣x−y∣∣计算输出节点的权重g
假设激活点坐标为 ( c X , c y ) (c_X,c_y) (cX,cy) ,其他位置 i , j i,j i,j处的权重g计算主要有两种方法:
高斯法
g ( i , j ) = e − ( c x − i ) 2 2 σ 2 e − ( c y − j ) 2 2 σ 2 g(i,j)= e^{-\frac{(c_x-i)^2}{2\sigma^2}}e^{-\frac{(c_y-j)^2}{2\sigma^2}} g(i,j)=e−2σ2(cx−i)2e−2σ2(cy−j)2
可以看出到 ( i , j ) (i,j) (i,j)为激活点 ( c X , c y ) (c_X,c_y) (cX,cy),计算得到的g=1。权重呈现高斯分布。其中高斯法中的 σ \sigma σ值也会随着迭代步数变化而变化,更新方式跟学习率方式一样,参见后面学习率的更新硬阈值法

这种方法比较直接,以 ( c X , c y ) (c_X,c_y) (cX,cy)为中心一定范围内的g为1,其他为0,;一般都是选择高斯方法
学习率更新
η = η 0 1 + t m a x s t e p / 2 \eta=\frac{\eta_0}{1+\frac{t}{max_{step}/2}} η=1+maxstep/2tη0
其中 t t t表示当前的迭代
step, m a x s t e p max_{step} maxstep网络训练总的迭代次数,学习率 η \eta η随着迭代次数的增加,会越来越小。 - 自组织映射(Self-organizing map, SOM)通过学习输入空间中的数据,生成一个
-
相关阅读:
共模电感选择请收好谷景电感教你的小方法
Linux使用Docker完整安装Superset3,同时解决please use superset_config.py to override it报错
拼多多店铺如何快速装修?
【C++STL基础入门】list基本使用
C++ STL中的 map 容器
护眼灯值不值得买?护眼灯买哪种好
Oracle技术分享 oracle 回收站recyclebin相关
安装facebook/wdt备忘
docker容器健康状态健康脚本
[附源码]Python计算机毕业设计Django社区疫情防控信息管理系统
- 原文地址:https://blog.csdn.net/weixin_38346042/article/details/126097351