-
广告行业中那些趣事系列56:超实用的多模态学习模型VILT源码实践
导读:本文是“数据拾光者”专栏的第五十六篇文章,这个系列将介绍在广告行业中自然语言处理和推荐系统实践。本篇主要介绍了多模态学习模型VILT几个实用的源码实践,对于希望将VILT模型应用到业务实践的小伙伴可能有帮助。
欢迎转载,转载请注明出处以及链接,更多关于自然语言处理、推荐系统优质内容请关注如下频道。
知乎专栏:数据拾光者
公众号:数据拾光者

摘要:本篇主要介绍了多模态学习模型VILT几个实用的源码实践,包括使用VILT预训练模型获取pretrain embedding、微调VILT、VILT模型预估Inference、VILT掩码模型、使用VILT根据图片找到语义匹配的文本和使用VILT根据两张图片和一条文本判断是否匹配。对于希望将VILT模型应用到业务实践的小伙伴可能有帮助。
下面主要按照如下思维导图进行学习分享:

01
背景介绍
之前在《广告行业中那些趣事系列54:从理论到实践学习当前超火的多模态学习模型》中介绍了当前主流的几种多模态学习模型,包括VisualBERT、Unicoder-VL、VL-BERT和VILT。学习前沿技术最重要的目的是落地到实际工作中,本篇主要基于开源的transformers库来介绍VILT几种实用的应用场景,这也是我们使用真正意义上的多模态学习模型的早期尝试。我们现阶段对于多模态学习的目标是使用多模态模型获取广告标题和素材图片对应的pretrain embedding,然后作为特征通过concat方式拼接到传统特征之后,最后添加到DNN网络的CTR模型中。
02
VILT几个实用的源码实践
VILT源码实践主要参考的是transformers库中关于VILT的相关教程,github地址如下:
https://github.com/NielsRogge/Transformers-Tutorials/tree/master/ViLT
2.1 使用VILT预训练模型获取pretrain embedding
如果你想把VILT模型作为特征抽取器用于提取特征,也就是输入一张图片和文本,输出对应的embedding,那么通过下面的代码即可完成你的需求:

图1 使用VILT预训练模型获取pretrain embedding
这里需要注意两点,第一点是预训练模型的选择。预训练模型可以直接通过"dandelin/vilt-b32-mlm"地址即可选择对应的预训练模型,这种方法会在代码调用时通过网络下载模型,优点是简单方便,缺点是可能需要比较久的时间,一般的预训练模型可能几百M。还有一种方式是提前去transformers的model hub里下载到本地,然后使用本地的预训练模型即可,model hub地址如下:
https://huggingface.co/models
下面是transformers的model hub界面,支持各种各样的预训练模型:

图2 transformers的model hub界面
第二点是processor不仅支持输入一张图像和一条文本,而且还可以输入图片列表和文本列表,得到批量的图像-文本对pretrain embedding。这里需要注意如果输入的文本列表和图像列表,要求列表的长度是一样的。同时如果文本列表中各文本长度是不同的,需要在processor中添加padding和truncation配置(padding=True , truncation=True)。
2.2 微调VILT:使用VQA数据微调VILT
上面是直接使用官方提供的预训练模型来获取pretrain embedding,如果你想用业务相关的数据来微调VILT模型则可以查看这个教程,下面以VQA数据微调VILT模型为例展示,教程代码地址如下:
https://github.com/NielsRogge/Transformers-Tutorials/blob/master/ViLT/Fine_tuning_ViLT_for_VQA.ipynb
VQA任务就是根据一张图片来提问,希望模型能正确回答对应的问题。比如下面有一张图片,图片里有两只猫,问题Question是“How many cats are there?”,希望模型给出的答案Answer是“two”,下面是VQA任务数据示例:

图3 VQA任务数据示例
Fine_tuning_ViLT_for_VQA教程中比较重要的几个部分:
第一块是构造VQADataset:

图4 构造VQADataset
第二块是模型定义:

图5 模型定义
第三块是模型训练:

图6 模型训练
2.3 VILT模型预估Inference:使用VILT看图回答问题
上面使用VQA数据微调了VILT预训练模型,下面是使用微调好的VILT模型来进行线上预估,教程代码地址如下:
https://github.com/NielsRogge/Transformers-Tutorials/blob/master/ViLT/Inference_with_ViLT_(visual_question_answering).ipynb
比较重要的是vilt-b32-finetuned-vqa模型导入和结果预估代码如下:
图7 vilt-b32-finetuned-vqa模型导入和结果预估代码
2.4 VILT掩码模型:根据图片和掩码文本预测被掩码的文本
如果你想用VILT掩码模型来完成根据图片对文本进行完形填空的任务,比如提供一张图片,掩码文本为“a bunch of [MASK] laying on a [MASK].”,希望模型能预测出被掩码的文本,也就是得到“a bunch of cats laying on a couch.”,下面是VILT掩码模型数据示例:

图8 VILT掩码模型数据示例
2.5 使用VILT根据图片找到语义匹配的文本
如果想使用VILT模型找到和图像语义一致的文本,比如提供一张图片和文本列表texts,需要找到文本列表中和图片语义最匹配的文本,下面是VILT根据图片找到语义匹配的文本数据示例:

图9 VILT根据图片找到语义匹配的文本数据示例
比较重要的是定义processor和模型源码如下:
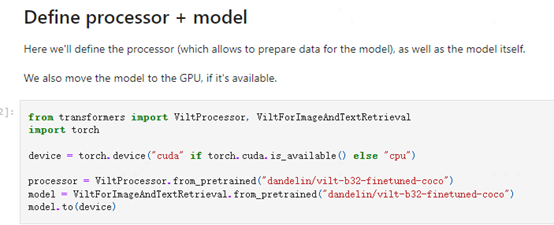
图10 定义processor和模型
2.6 使用VILT根据两张图片和一条文本判断是否匹配
如果想使用VILT模型判断两张图片和一条文本的语义是否匹配,比如准备两张图片,对应的文本内容是text,如果图片和文本内容匹配则模型输出True,否则输出False,下面是VILT根据两张图片和一条文本判断是否匹配数据示例:

图11 VILT根据两张图片和一条文本判断是否匹配数据示例
03
总结和反思
本篇主要介绍了多模态学习模型VILT几个实用的源码实践,包括使用VILT预训练模型获取pretrain embedding、微调VILT、VILT模型预估Inference、VILT掩码模型、使用VILT根据图片找到语义匹配的文本和使用VILT根据两张图片和一条文本判断是否匹配。对于希望将VILT模型应用到业务实践的小伙伴可能有帮助。
最新最全的文章请关注我的微信公众号或者知乎专栏:数据拾光者。
码字不易,欢迎小伙伴们点赞和分享。
-
相关阅读:
leetcode_2652倍数求和
Linux防火墙常用操作及端口开放
Java配置41-搭建Kafka服务器
OPT101光照传感器 光强度传感器模块 单片光电二极管
找准边界,吃定安全 | 串联边界设备协同,便捷运营思维让安全更有效
AI大模型探索之路-基础篇5:GLM-4解锁国产大模型的全能智慧与创新应用
TSINGSEE青犀睡岗离岗检测算法——确保加油站安全运营
Jmeter之BeanShell详解和夸线程调用
Zookeeper学习二集群搭建
基于python的大数据反电信诈骗管理系统设计与实现
- 原文地址:https://blog.csdn.net/abc50319/article/details/126093166