-
Python 教程之如何在 Python 中处理大型数据集CSV、Pickle、Parquet、Feather 和 HDF5 的比较
时隔这么久, Kaggle 终于推出了新的表格数据竞赛,一开始大家都很兴奋。直到他们没有。当 Kagglers 发现数据集有 50 GB 大时,社区开始讨论如何处理如此大的数据集.
CSV 文件格式需要很长时间来写入和读取大型数据集,并且除非明确告知,否则不会记住数据类型。
除了通过减少数据类型来减少所需的磁盘空间之外,问题在于在工作会话之间以哪种格式保存修改后的数据集。CSV 文件格式需要很长时间来写入和读取大型数据集,并且除非明确告知,否则不会记住列的数据类型。本文探讨了处理大型数据集的 CSV 文件格式的四种替代方案:Pickle、Feather、Parquet 和 HDF5。此外,我们将研究这些带有压缩的文件格式。
基准设置
为了进行基准测试,我们将创建一个虚构的数据集。这个虚构的数据集包含每种数据类型的一列,但以下例外:具有数据类型的列在此示例float16中categorical被省略,因为 parquet 不支持float16而 HDF5format = "table"不支持categorical。为了减少可比性的时序噪声,这个虚构的数据集包含 10,000,000 行,并且如 [8] 中所建议的几乎 1GB 大。
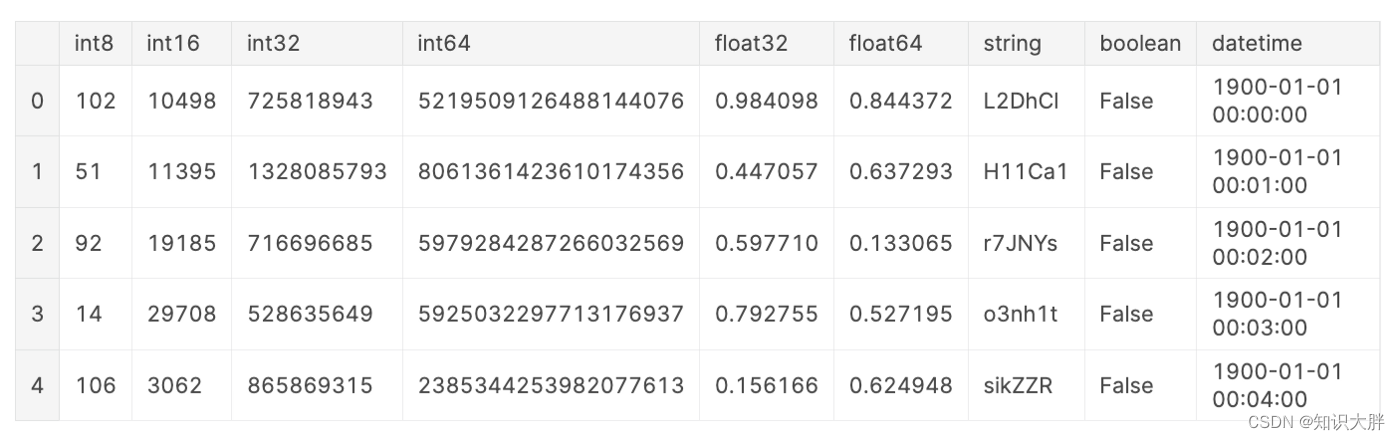
数据的特性会影响读取和写入时间,例如数据类型、DataFrame 的宽度(列数)与长度(行数)。但是,这超出了本文的范围。为了进一步阅读,我推荐以下资源:文件格
-
相关阅读:
Springboot整合Redisson解决超卖问题【分布式锁】
千挂科技与东风柳汽达成前装量产合作,2024年交付自动驾驶牵引车
C/C++教程 从入门到精通《第十一章》——初识MFC
Docker使用总结
. NET Core Razor动态菜单实现
【我的OpenGL学习进阶之旅】当你运行OpenGL程序的时候,程序并不绘制任何内容,并且白屏和黑屏的时候怎么排查?
Rust中的 into和from如何使用?
Ladybug 全景相机, 360°球形成像,带来全方位的视觉体验
【OS】操作系统课程笔记 第四章 中断和处理机调度
企业年报API的应用:从金融投资到市场研究
- 原文地址:https://blog.csdn.net/iCloudEnd/article/details/126089914