-
Python 自动化教程(2) : Excel自动化:使用pandas库
人生苦短, 我用Python!
Excel自动化,是用Python程序创建、编辑、修改Excel文件,处理其中的数据,从而无人化、大批量处理excel文件数据。本篇讲解pandas库操作excel.
第二篇 Excel自动化:使用pandas库
一、首先用 PIP 安装 openpyxl、xlwings、pandas 库
打开命令行窗口,分别输入三行命令
- pip install openpyxl
- pip install xlwings
- pip install pandas
为快速下载,可以使用 阿里云 镜像 (pandas 库比较大)
- pip install openpyxl -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com
- pip install xlwings -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com
- pip install pandas -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com
由于pandas库将使用openpyxl 或 xlwings 库读写excel文件,因此openpyxl 或 xlwings必须最少安装一个。
二、pandas 简介
Pandas 是一个开放源码、BSD许可的python库,提供高性能、易于使用的数据结构和数据分析工具,广泛应用于办公、学术、金融、统计学等各个数据分析领域。
Pandas 可以从各种文件格式比如 Excel文件、CSV文件、JSON、数据库SQL等 导入数据或导出数据。
Pandas 名字衍生自术语 "panel data"(面板数据)。
Pandas库使用Numpy库提供高性能的矩阵运算, 安装Pandas库时,Numpy库将自动安装。三、pandas 的基本数据结构
Pandas 的主要数据结构是 Series类 (一维数据系列)与 DataFrame类(二维数据表)。
Series对象保存一组数据,类似于一维数组列表,例如: [1, 2, 3, 4].
DataFrame 对象是一个表格型的数据结构,有多个列、多个行,类似于Excel表格或数据库的表。
提取DataFrame的一列或一行将获得一个Series对象。类似于数据库,DataFrame有索引列,用于加快查找。
三、pandas 读取 / 保存 excel 文件
用PyCharm创建一个新项目,创建一个新的.py文件,在程序开头引入 pandas
import pandas as pdPS: 开发社区习惯于用 pd 作为 pandas 的别名
1、从excel文件读入数据表
- import pandas as pd
- # read DataFrame from excel
- df = pd.read_excel('202201报表.xlsx')
- print(type(df))
- print(df)
其中:excel文件 202201报表.xlsx 是这样的。py程序和excel文件可以在此下载
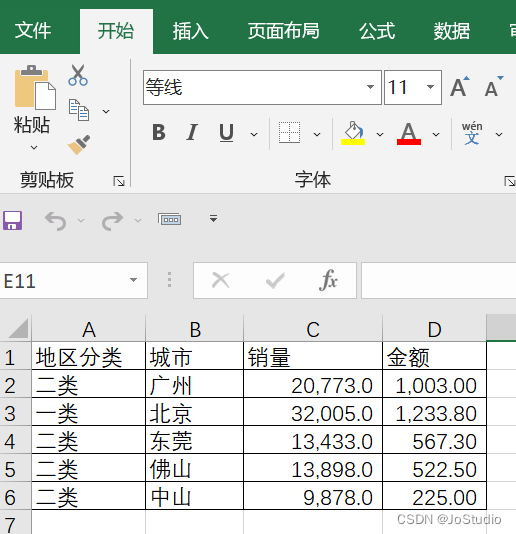
运行程序,结果如下:
- <class 'pandas.core.frame.DataFrame'>
- 地区分类 城市 销量 金额 单价
- 0 一类 广州 20773 1003.0 0.048284
- 1 一类 深圳 32005 1233.8 0.038550
- 2 二类 东莞 13433 567.3 0.042232
- 3 二类 佛山 13898 522.5 0.037595
- 4 二类 中山 9878 225.0 0.022778
说明:
(1) pd.read_excel(filename) 读取excel文件,返回值 df 是一个 DataFrame 对象。
如果excel文件中有多个worksheet, 则 pd.read_excel() 默认将读取第1个worksheet
(2) print(df) 显示 DataFrame 是一个表格,其中:第一列 [0, 1, 2, 3, 4] 是pandas自动加上的行号索引列
2、对于有多个worksheet的excel文件, 指定worksheet的名称, 读入数据表
- # 指定worksheet的名称,读入数据表
- df = pd.read_excel('202201报表.xlsx', sheet_name="客户")
- print(df)
说明: 从名为 "客户"的 worksheet 中读入数据表
3、将DataFrame保存到excel文件
- # 将DataFrame存入excel文件(注意:直接使用 to_excel() 将会丢弃原excel文件中的其他worksheet)
- filename = '新报表.xlsx'
- df.to_excel(filename, sheet_name="商品销售", index=False)
说明:
(1) df.to_excel(filename, sheet_name) 将 DataFrame 对象的数据保存入 excel文件中。
index=False 表示不保存索引列
(2) 但是直接使用 to_excel() 有一个问题:如果存盘excel文件已经存在,则原excel文件中的其他worksheet将会被丢弃。所以, 直接使用 to_excel() 仅限于生成新excel文件,不适合于将数据存入已有excel文件.
4、将DataFrame保存到已有的excel文件
- import openpyxl
- import pandas as pd
- def save_to_exist_excel(df, filename, sheet_name, index=False,
- startrow=0, startcol=0, **kwargs):
- """
- 将DataFrame存入已有的excel文件
- :param df: DataFrame 对象
- :param filename: Excel 文件名
- :param sheet_name: 工作表名称(标题)
- :param index: (可选)索引列是否保存
- :param startrow: (可选)开始写入的行号, 第一行为0, 第二行为1, ...
- :param startcol: (可选)开始写入的列号, A列为0, B列为1 ...
- :param kwargs: (可选)其他参数
- :return: None
- """
- book = openpyxl.load_workbook(filename)
- writer = pd.ExcelWriter(filename, engine='openpyxl')
- writer.book = book
- writer.sheets = {}
- for ws in book.worksheets:
- writer.sheets[ws.title] = ws
- df.to_excel(writer, sheet_name=sheet_name, index=index,
- startcol=startcol, startrow=startrow, **kwargs)
- writer.save()
- # 读出数据
- filename = '202201报表.xlsx'
- df = pd.read_excel('202201报表.xlsx', sheet_name="商品销售")
- df.loc[1, '城市'] = "新城" # 修改单元格
- # 将DataFrame存入已存在的excel文件
- save_to_exist_excel(df, filename, sheet_name="商品销售")
说明:
(1) 将 DataFrame 对象的数据保存到已有的 excel文件稍微有点复杂。在此,提供一个函数 save_to_exist_excel(df, filename, sheet_name, index=False), 各参数说明见注释。
函数中使用了openpyxl库。
对于 .xlsx 文件读写, pandas 默认调用openpyxl库。
(2) 上面的例程显示了 save_to_exist_excel()的使用。
四、Pandas 的行、列的基本读写
1、df.columns 是一个 Series 对象,保存着每一列的名称
- # df. columns 是一个 Series 对象
- print(df.columns)
- # 显示每一列的名称
- for i in range(len(df.columns)):
- print(df.columns[i])
2、取得一列
- # 如果存在名为"城市"的列
- if '城市' in df.columns:
- column = df['城市'] # 取得名为"城市"的一列
- print(type(column)) # column 是一个 Series 对象
- print(column)
- print(column[0]) # 取得 columns 第1个数据(索引号从0开始)
- print(column.to_list()) # 将series转换为 list
运行结果:
- <class 'pandas.core.series.Series'>
- 0 深圳
- 1 东莞
- 2 广州
- 3 佛山
- Name: 城市, dtype: object
- 深圳
- ['深圳', '东莞', '广州', '佛山']
3、取得一行
- # 取得一行 (Series)
- if len(df) > 0:
- row = df.iloc[0] # 取得第一行(从0开始)
- print(type(row)) # row 是一个 Series 对象
- print(row)
- print(row['城市']) # 取得该行中 列名为"城市"的单元格的值
说明:.iloc[row_number] 是以行号取得一行
4、取得或写入一个单元格的值
- # 取得一个格子的值
- print(df.loc[1, '城市'])
- # 写入一个格子的值
- df.loc[1, '城市'] = "新城"
- print(df.loc[1, '地市'])
- # 取得 金额列的 最大、最小、平均值
- print(df['金额'].max(), df['金额'].min(), df['金额'].mean())
说明: .loc[index, column_name] 是以 行号索引、列名取得一个单元格
5、DataFrame有多少行、多少列
- print(len(df)) # len(df)取得行数
- print(len(df.columns)) # len(df.columns)取得列数
五、数据查询:取得 DataFrame的子集
DataFrame是一个数据集合。数据查询就是取得 DataFrame 的子集。
1、简单查询
- import pandas as pd
- # read DataFrame from excel
- df = pd.read_excel('202201报表.xlsx')
- # 取df的子集:取开头的两行
- print(df.head(2))
- # 取df的子集:取最后的3行
- print(df.tail(3))
- # 取df的子集:仅取两列
- df2 = df[['城市', '金额']]
- print(df2)
- # 查询:取df的子集,返回金额 > 600的所有行
- df3 = df[df['金额'] > 600]
- print(df3)
- # 查询:取df的子集:返回金额 > 600的所有行
- df5 = df.query('金额 > 600')
- print(df5)
说明:
(1) df.head(2) 返回最开始的 2行。 相当于数据库SQL语言中的:
select top 2 from df
类似的: df.tail(3) 返回最末尾的 3行
(2) df[['城市', '金额']] 表示只取'城市', '金额'两列, 相当于数据库SQL语言中的:
select 城市, 金额 from df
(3) df[df['金额'] > 600] 返回金额 > 600的所有行, 相当于数据库SQL语言中的:
select * from df where 金额 > 600
(4) 查询有两种形式:
第一种是 python 列表风格: df[df['金额'] > 600]
第二种是 数据库风格 : df.query('金额 > 600')
这两种是等价的。对于熟悉数据库SQL语言的人来说,第二种更熟悉一些
(5) 返回的df子集是 原df 的 复制品。修改子集不会影响原df.
2、复合查询
- # 复合查询:取df的子集:返回金额 > 600 且 销量 < 25000的所有行
- df4 = df[(df['金额'] > 600) & (df['销量'] < 25000)]
- print(df4)
- # 复合查询:取df的子集:返回金额 <= 600 或 销量 < 25000的所有行
- df4 = df[(df['金额'] <= 600) | (df['销量'] < 25000)]
- print(df4)
- # 复合查询:取df的子集:金额 > 600 且 销量 < 25000的所有行
- df6 = df.query('金额 <= 600 and 销量 < 25000')
- # 复合查询:取df的子集:金额 <= 600 或 销量 < 25000
- df6 = df.query('金额 <= 600 or 销量 < 25000')
- print(df6)
- # 取得 df6 的 城市列表
- print(df6['城市'].to_list())
说明:
(1) df[(df['金额'] > 600) & (df['销量'] < 25000)] 是一个两个条件的复合查询。 ‘&’ 是 and(且) 的意思。注意:每一个条件必须以括号 ()把它括起来,否则会出错。
同理, ‘|’ 是 or(或) 的意思, 每一个条件也必须以括号 ()把它括起来,否则会出错。
注意: 在这种形式的查询中, ‘&&’, ‘||’ , ‘and', 'or' 都是不能写的。
(2) df.query('金额 <= 600 and 销量 < 25000') 是SQL语言的查询形式,可以不写括号。与上面的等价。
df.query('金额 <= 600 or 销量 < 25000') 是 or 的关系。
3、排序
- # 对金额排序 (逆序: 从大到小)
- df7 = df.sort_values('金额', ascending=False)
- print(df7)
说明: sort_values(列名) 对数据行进行排序, ascending 缺省是 True, 由小到大排序。
以上程序相当于SQL语言中的: select * from df order by 金额 desc
如果要以两个以上的进行排序,则写为: df.sort_values([‘地区分类’,’金额']) , 意思是先按 地区分类排序,如相同,再按 金额排序. 相当于SQL语言中的:
select * from df order by 地区分类, 金额
4, 写在一起:一个较完整的查询
- # 取地区分类为二类的前两名的城市、金额
- df8 = df.query('地区分类 == "二类"').sort_values('金额', ascending=False).head(2)[['地区分类', '城市', '金额']]
- print(df8)
说明:以上程序 既有查询,也有排序、取部分行、取部分字段。相当于SQL语言中的:
select top 2 地区分类, 城市, 金额 from df where 地区分类="二类"
5, 分组统计
- import pandas as pd
- import numpy as np
- # read DataFrame from excel
- df = pd.read_excel('202201报表.xlsx')
- # 分类统计
- df8 = df.groupby("地区分类").agg({"城市": np.size, "金额": np.sum})
- print(df8)
说明:
(1) .groupby('地区分类') 是按照 地区分类 列进行分组, 类似于与SQL语言中的GROUP BY
(2) .agg() 是对分组进行统计
agg() 的参数是一个 dictionary, key是列名, value是numpy库中的统计函数名. np.size 是统计个数(相当于SQL语言中的 count), np.sum是统计加总值(相当于SQL语言中的 sum)
(3) 上面的程序,相当于 SQL语句:
select 地区分类, count(城市), sum(金额) from df group by 地区分类
六、DataFrame 列计算
1、按列赋值,或从其他列计算产生新的列
- import pandas as pd
- # 读取数据表
- df = pd.read_excel('202201报表.xlsx')
- # 增加一列,设为统一值:'未定义'
- df['价值档次'] = '未定义'
- # 增加一列,取值:从其他列计算产生
- df['单价'] = df['金额'] * 10000 / df['销量']
- print(df)
说明:
(1) df['价值档次'] = '未定义', 对'价值档次'列统一赋值为‘未定义’。
因为原df中没有'价值档次'列, 则该列自动增加。 如果该列已有,则更新值。
(2) df['单价'] = df['金额'] * 10000 / df['销量'] # 单价=金额*10000/销量
因为原df中没有'单价'列, 则’单价‘列自动增加.
2、增加一个分类列
- # 增加一列:价值档次 默认值为 低价值
- df['价值档次'] = '低价值'
- # 当 单价 >= 300, 价值档次 为 中价值
- df.loc[df['单价'] >= 300, '价值档次'] = '中价值'
- # 当 单价 >= 400, 价值档次 为 高价值
- df.loc[df['单价'] >= 400, '价值档次'] = '高价值'
- print(df)
说明:分类列的值由其他列按条件多次计算产生
3、更改列名称
- # 将列名 单价 更改为 平均金额
- df.rename(columns={'单价': '平均金额'}, inplace=True)
说明:可以一次更改多个列名,例如:columns={'单价': '平均金额', '城市': '地方'}
inplace=True的意思是就地,即:更改原df的值。之前说过,DataFrame的操作结果默认是产生一个新的DataFrame,复制原DataFrame的值,不修改原df的值。 当指定inplace=True时,则修改原df的值。
4、按列排序
- # 按 平均金额列 就地排序(逆序),更改原df的值
- df.sort_values('平均金额', ascending=False, inplace=True)
说明:
(1) sort_values(列名) 是按列排序, 如果要求按两列以上排序,则写为一个list, 例如:
sort_values(['地区分类', '平均金额‘])
(2) inplace=True的意思是‘就地’,即:更改原df的值。
七、两个DataFrame的合并
1、 纵向合并
- import pandas as pd
- # 读取表1
- df1 = pd.read_excel('202201报表.xlsx')
- # 读取表2
- df2 = pd.read_excel('202202报表.xlsx')
- # print(df2)
- # 将 df1, df2 合并(纵向合并、df2的行排在df1后)为df3
- df3 = pd.concat([df1, df2])
- print(df3)
说明:
(1) pd.concat([df1, df2]) 是将 df2的行排在df1后, 每一行内容不变,即:纵向合并
2、横向合并
- # 读取表1
- df1 = pd.read_excel('202201报表.xlsx')
- # 从worksheet '客户' 中 读取表
- df4 = pd.read_excel('202201报表.xlsx', sheet_name='客户')
- # 将 df1, df2 横向合并, 关联字段是 城市, 体会:how="outer", how="inner" 有何区别
- df5 = pd.merge(df1, df4, on='城市', how="inner")
- print(df5)
- # 将 df1, df2 横向合并, 关联字段是 城市, 体会:how="outer", how="inner" 有何区别
- df5 = pd.merge(df1, df4, on='城市', how="outer")
- print(df5)
说明:
(1) df5 = pd.merge(df1, df4, on='城市', how="inner"
将 df1, df2 横向合并, 关联字段是 城市。 相当于 SQL语句:
select df1.*, df4.* from df1, df2 where df1.城市=df4.城市
(2) how 参数表达关联的方式。
how="inner" 时, 如果有一个城市在 df1 中存在,在df4中不存在,则该行将删去。
how="outer" 时, 如果有一个城市在 df1 中存在,在df4中不存在,则该行将保留。
八、从其他文件或数据格式中导入、导出数据
Pandas的数据导入、导出能力是很强的。
Pandas 支持从 excel文件、csv文件、json文件、数据库SQL查询等导入数据, 提供名为 read_xxx()的一系列函数, 这些函数的返回值均是一个DataFrame对象:
pd.read_excel(filename) # 读取 excel文件
pd.read_csv(filename) # 读取 .csv 文件
pd.read_json(filename) # 读取 json 文件
pd.read_html(html_text) # 读取 html 文本
pd.read_sql(sql, db_connection) # 在数据库连接中执行SQL,读取数据DataFrame 支持将数据导出为 excel文件、csv文件、json、dict、数据库等,DataFrame对象有名为 to_xxx()的一系列方法:
df.to_excel(filename) # 导出 excel文件
df.to_csv(filename) # 导出 .csv 文件
df.to_json(filename) # 导出 json 文件
df.to_html() # 导出 html 文本
df.to_sql(name, db_connection) # 导出到数据库,写入数据
df.to_dict() # 导出 dictionary 对象同时, DataFrame类支持以 list, dict 等数据直接创建。
Pandas 的导入、导出功能为数据的生成、转换、保存提供了方便。
1、.csv 文件导入、导出
.csv 文件是逗号分割的文本文件。
- import pandas as pd
- # 从 excel 文件读取DataFrame
- df = pd.read_excel('202201报表.xlsx')
- print(df)
- # DataFrame存盘为 .csv 文件, index=False表示不存索引列
- df.to_csv('202201.csv', index=False)
- # 从 .csv 文件读取DataFrame
- df = pd.read_csv('202201.csv')
- print(df)
说明: 调用 df.to_csv() 是, 参数index=False表示不保存索引列。
用文本编辑器打开 202201.csv 文件,结果如下:
- 地区分类,城市,销量,金额
- 一类,广州,20773,1003.0
- 一类,新城,32005,1233.8
- 二类,东莞,13433,567.3
- 二类,佛山,13898,522.5
- 二类,中山,9878,225.0
2、html 文本的导入、导出
- import pandas as pd
- # 从 excel 文件读取DataFrame
- df = pd.read_excel('202201报表.xlsx')
- print(df)
- # DataFrame导出为html文本,index=False表示不存索引列
- html = df.to_html(index=False)
- print(html)
- # 从 html 文本读取
- # read_html(html) 的返回值是一个DataFrame列表
- # html 可以是一个网页URL
- df_list = pd.read_html(html)
- if len(df_list) > 0:
- df = df_list[0] # 取得第1个DataFrame
- print(df)
说明: read_html(url) 可以方便地从网页读取其中的表格, 返回值是一个DataFrame列表。但是,如果网页html书写不规范,则会抛出错误: lxml.etree.XMLSyntaxError
DataFrame导出的html文本,结果如下:
- <table border="1" class="dataframe">
- <thead>
- <tr style="text-align: right;">
- <th>地区分类th>
- <th>城市th>
- <th>销量th>
- <th>金额th>
- tr>
- thead>
- <tbody>
- <tr>
- <td>一类td>
- <td>广州td>
- <td>20773td>
- <td>1003.0td>
- tr>
- <tr>
- <td>一类td>
- <td>新城td>
- <td>32005td>
- <td>1233.8td>
- tr>
- <tr>
- <td>二类td>
- <td>东莞td>
- <td>13433td>
- <td>567.3td>
- tr>
- <tr>
- <td>二类td>
- <td>佛山td>
- <td>13898td>
- <td>522.5td>
- tr>
- <tr>
- <td>二类td>
- <td>中山td>
- <td>9878td>
- <td>225.0td>
- tr>
- tbody>
- table>
3、从 excel 文件导入、导出 (指定单元格位置)
上文 讲了 read_excel(), to_excel() 的基本用法。
但是,仍然有一个问题, 之前读取的excel表格都是从工作表的 A1单元格开始的, 如果表格不是从A1格开始,比如, 202201报表.xlsx文件中的 '库存‘工作表数据开始于B6格, 则导入、导出数据不对。 如何处理呢?
3.1 从 excel 文件导入, 指定工作表,指定表格开始的行和需要的列
- import pandas as pd
- # 从 excel 文件读取DataFrame, 指定工作表为 "库存"
- # 参数 skiprows=range(0,5) 表示跳过 0-4行共5行(第一行为0, range函数中5不包含)
- # 参数 usecols 表示使用哪几行作为列(第一列为0), [1, 2, 3] 表示 B, C, D 列
- df = pd.read_excel('202201报表.xlsx', sheet_name="库存",
- skiprows=range(0, 5), usecols=[1, 2, 3])
- print(df)
运行结果:从B6格开始正确读出表格 ( B, C, D 三列)
- 城市 库存数量 金额
- 0 广州 3233897 289.8
- 1 深圳 4287005 367.5
- 2 东莞 1532353 212.0
- 3 佛山 1232232 199.0
3.2 写入 excel 文件, 指定工作表,指定表格开始的行号和列号
将DataFrame写入 excel文件中,如果不是从 A1格开始写入,需在 to_excel()函数中使用 startcol, startrow 参数。 使用上文提供的 save_to_exist_excel() 函数, 如下
- import pandas as pd
- import openpyxl
- def save_to_exist_excel(df, filename, sheet_name, index=False,
- startrow=0, startcol=0, **kwargs):
- """
- 将DataFrame存入已有的excel文件
- :param df: DataFrame 对象
- :param filename: Excel 文件名
- :param sheet_name: 工作表名称(标题)
- :param index: (可选)索引列是否保存
- :param startrow: (可选)开始写入的行号, 第一行为0, 第二行为1, ...
- :param startcol: (可选)开始写入的列号, A列为0, B列为1 ...
- :param kwargs: (可选)其他参数
- :return: None
- """
- book = openpyxl.load_workbook(filename)
- writer = pd.ExcelWriter(filename, engine='openpyxl')
- writer.book = book
- writer.sheets = {}
- for ws in book.worksheets:
- writer.sheets[ws.title] = ws
- df.to_excel(writer, sheet_name=sheet_name, index=index,
- startcol=startcol, startrow=startrow, **kwargs)
- writer.save()
- # 从 excel 文件读取DataFrame, 指定工作表为 "库存"
- # 参数 skiprows=range(0,5) 表示跳过 0-4行共5行(第一行为0, range函数中5不包含)
- # 参数 usecols 表示使用哪几行作为列(第一列为0), [1, 2, 3] 表示 B, C, D 列
- df = pd.read_excel('202201报表.xlsx', sheet_name="库存",
- skiprows=range(0, 5), usecols=[1, 2, 3])
- df.loc[1, '城市'] = "新城" # 修改一个单元格的值,以体现变化
- print(df)
- # 写入Excel文件, startrow=5 表示从第6行开始(第1行为0), startcol=1表示从第2列开始(第1行为0)
- save_to_exist_excel(df, '202201报表.xlsx', sheet_name="库存", startrow=5, startcol=1)
4、DataFrame 与 dictionary 的相互转换
- import pandas as pd
- # 从 dictionary 创建DataFrame
- dict1 = {
- "Name": ["Peter", "Sam", "Mary"],
- "Age": [22, 35, 58],
- "Sex": ["male", "male", "female"],
- }
- df = pd.DataFrame(dict1)
- print(df)
- # 将 DataFrame 转化为 dictionary
- d = dict(df.to_dict("series"))
- dd = {}
- for key in d:
- dd[key] = list(d[key])
- print(dd)
5、DataFrame 与 list 的相互转换
- # 从 list 创建DataFrame
- list1 = [
- ['Name', 'Age', 'Sex'],
- ["Peter", 22, "male"],
- ["Sam", 35, "male"],
- ["Mary", 58, "female"],
- ]
- df = pd.DataFrame(list1[1:], columns=list1[0])
- print(df)
- # 将 DataFrame 转化为 list
- print(df.to_dict("split"))
- # 从 list 创建DataFrame
- list2 = [
- {'Name': 'Peter', 'Age': 22, 'Sex': 'male'},
- {'Name': 'Sam', 'Age': 35, 'Sex': 'male'},
- {'Name': 'Mary', 'Age': 58, 'Sex': 'female'}
- ]
- df = pd.DataFrame(list2)
- # 将 DataFrame 转化为 list
- print(df.to_dict(orient="records"))
- # orient='records' : list like [{column -> value}, … , {column -> value}]
6, DataFrame 与 json 文本的 相互转换
- # 从 json 文本中 创建DataFrame
- json = '[{"Name":"Peter","Age":22,"Sex":"male"},{"Name":"Mary","Age":58,"Sex":"female"}]'
- df = pd.read_json(json)
- # 将 DataFrame 转化为 json 文本
- json = df.to_json(orient="records")
本篇小结:
本篇讲解了 pandas 库的基本用法。相关py程序和excel文件可以在此下载。练习作业:
... ...
-
相关阅读:
Hadoop分布式文件系统-HDFS
Docker-安装部署全过程
5 秒生成高质量文章,Llama 3-Chinese-Chat Demo 一键启动!
linux下golang环境配置问题记录
Linux | 文件描述符理解 | 系统级别的文件操作讲解 | 一切皆文件的由来 | 重定向dup2函数讲解
基于FPGA的图像缩小算法实现,包括tb测试文件和MATLAB辅助验证
用Python让字符串整齐排列:左对齐、右对齐还是居中对齐?
docker和Helm Chart的基本命令和操作
代码随想录算法训练营第五十天| LeetCode1035.不相交的线、53. 最大子序和、392.判断子序列、115.不同的子序列
LeetCode:字符串的前缀分数和
- 原文地址:https://blog.csdn.net/c80486/article/details/126080134
