-
Elasticsearch系列教程之核心概念及用法
Elasticsearch核心概念
ElasticSearch是面向文档型的数据库,一条数据在这里就是一个文档。比如:
{ "name" : "John", "sex" : "Male", "age" : 25, "birthDate": "1990/05/01", "about" : "I love to go rock climbing", "interests": [ "sports", "music" ] }在MySql中这样的数据存储容易想到建立一张User表,其中有一些字段,而在es中就是一个文档,文档会属于一个User类型,各种各样的类型存储于一个索引中。下表是关系型数据库和es的疏于对照表:
关系型数据库 ElasticSearch 数据库 索引 表 type (慢慢会被弃用) 行 document 列 field es中可以包含多个索引(数据库),每个索引中可以包含多个类型(表),每个类型下又包含多个文档(行),每个文档又包含多个字段(列)。
物理设计:
es在后台把每个索引划分成多个分片,每个分片可以在集群中的不同服务器中转移。
逻辑设计:
一个索引类型,包含多个文档,当我们索引一篇文档时,可以通过这样的顺序找到他: 索引-》类型-》文档id(该id实际是个字符串),通过这个组合我们就能索引到某个具体的文档。
文档
es是面向文档的,意味着索引和搜索数据的最小单位是文档,es中,文档有几个重要的属性:
-
自我包含,一篇文档同时包含字段和对应的值,也就是同时包含key:value
-
可以是层次性的,一个文档中包含自文档,复杂的逻辑实体就是这么来的
-
灵活的结构,文档不依赖预先定义的模式,我们知道关系型数据库中,要提前定义字段才能使用,在es中,对于字段是非常灵活的。有时候,我们可以忽略字段,或者动态的添加一个新的字段
尽管我们可以随意的添加或忽略某个字段,但是,每个字段的类型非常重要。因为es会保存字段和类型之间的映射以及其他的设置。这种映射具体到每个映射的每种类型,这也是为什么在es中,类型有时候也称为映射类型。
类型
类型是文档的逻辑容器,就像关系型数据库一样,表格是行的容器。类型中对于字段的定义称为映射,比如name映射为string类型.我们说文档是无模式的,他们不需要拥有映射中所定义的所有字段,当新增加一个字段时,es会自动的将新字段加入映射,但是这个字段不确定他是什么类型,所以最安全的方式是提前定义好所需要的映射。
索引
索引是映射类型的容器,es的索引是一个非常大的集合。索引寻出了映射类型的字段和其他设置。然后他们被存储到了各个分片上。
倒排索引
es使用的是一种称为倒排索引的结构,底层采用Lucene倒排索引,这种结构适用于快速的全文搜索,一个索引由文档中所有不重复的列表构成,对于每一个词,都有包含它的文档列表。例如:现在有两个文档,每个文档包含如下内容:

为了创建倒排索引,我们首先要将文档拆分成独立的词(或成为词条或tokens),然后创建一个包含所有不重复的词条的排序列表,然后列出每个词条出现在哪个文档:

IK分词器
-
下载链接(版本需和es一致):Release v7.17.4 · medcl/elasticsearch-analysis-ik · GitHub
-
解压放入到es对应的plugins下即可
-
重启观察ES,发现ik插件被加载了
IK分词器两种模式:
ik_smart 最粗粒度的拆分
ik_max_word 最细粒度的拆分
它们其实就是2中分词算法,其区别直接通过测试观察
ik_smart:

ik_max_word:

可以看出 ik_max_word 比 ik_smart 划分的词条更多,这就是它们为什么叫做最细粒度和最粗粒度。
自定义词典:
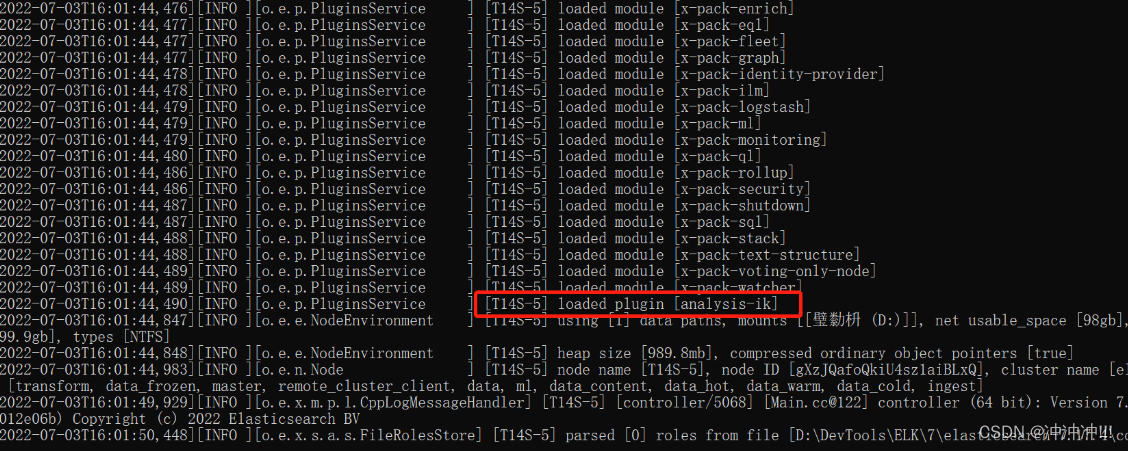
问题:如何把 金毛狮王 拆分成“金毛”、 “狮王”、 “金毛狮王” 三个词条?
默认2种模式都会拆分成 “金”、 “毛”、 “狮王” 三个词条。不符合我们的要求
根据默认拆分的结果,发现我们需要增加“金毛”和“金毛狮王”2个词条并删除“金”和“毛”2个词条。
这里就可以用自定义字典来实现:
打开 plugins\ik\config\IKAnalyzer.cfg

可以看到有2个配置 ext_dict 和 ext_stopwords。分别是扩展和停用字典
左边为my_ext.dic, 右边为my_stop.dic:

重新启动es后,发现分词结果变了:

Elasticsearch REST API
RESTful风格
一种软件架构风格,而不是标准,只是提供了一组设计原则和约束条件;它主要用于客户端和服务器交互类的软件;基于这个风格设计的软件可以更简洁,更有层次,更易于实现缓存等机制
基本命令说明

创建一个文档
PUT方式:
PUT /索引名/~类型名~/文档id { 请求体 }
示例:
PUT /cd/emp/1 { "name" : "李四", "age" : 25, "about" : "我喜欢摇滚乐", "interests": [ "运动", "音乐" ] }
POST方式:
方式一:不指定文档ID,会自动生成文档ID
POST /cd3/_doc { "name" : "王五", "age" : 2, "about" : "我喜欢摇滚乐", "interests": [ "运动", "音乐" ] }
方式二:指定文档ID,和PUT类似
POST /cd3/_doc/2 { "name" : "王五", "age" : 2, "about" : "我喜欢摇滚乐", "interests": [ "运动", "音乐" ] }
Elasticsearch文档字段的数据类型
-
字符串类型:
text、keyword text:支持分词,全文检索,支持模糊、精确查询,不支持聚合,排序操作;text类型的最大支持的字符长度无限制,适合大字段存储; keyword:不进行分词,直接索引、支持模糊、支持精确匹配,支持聚合、排序操作。keyword类型的最大支持的长度为——32766个UTF-8类型的字符,可以通过设置ignore_above指定自持字符长度,超过给定长度后的数据将不被索引,无法通过term精确匹配检索返回结果。
-
数值型 long、Integer、short、byte、double、float、half float、scaled float
-
日期类型 date
-
布尔类型 boolean
-
二进制类型 binary
-
等等…
创建一个索引并指定字段类型
PUT /cd2 { "mappings": { "properties": { "name": { "type": "text" }, "age": { "type": "integer" }, "birthday": { "type": "date" } } } }
获取索引的字段类型列表:

如果文档字段没有被指定类型,那么ElasticSearch就会默认配置字段类型
PUT /cd3/_doc/1 { "name" : "李四", "age" : 25, "about" : "我喜欢摇滚乐", "interests": [ "运动", "音乐" ] }

通过get _cat/ 可以查看Elasticsearch的当前的很多信息
GET _cat/indices 查看索引信息(indices是index的复数) GET _cat/aliases 显示别名,过滤器,路由信息 GET _cat/allocation 显示每个节点分片数量、占用空间 GET _cat/count 显示索引文档的数量 GET _cat/fielddata 查看字段分配情况 GET _cat/health 查看集群健康状况 GET _cat/master 显示master节点信息 GET _cat/nodeattrs 显示node节点属性 GET _cat/nodes 显示node节点信息 GET _cat/pending_tasks 显示正在等待的任务 GET _cat/plugins 显示节点上的插件 GET _cat/recovery 显示正在进行和先前完成的索引碎片恢复的视图
通过get _cluster/ 和 _nodes可以查看很多集群、节点相关的信息
查看集群健康状态接口 (_cluster/health) 查看集群状况接口 ( _cluster/state) 查看集群统计信息接口 ( _cluster/stats) 查看集群挂起的任务接口( _cluster/pending_tasks) 集群重新路由操作( _cluster/reroute) 更新集群设置( _cluster/settings) 节点状态( _nodes/stats) 节点信息( _nodes) 节点的热线程( _nodes/hot_threads) 关闭节点( _nodes/master/_shutdown)
修改文档
PUT方式 - 直接覆盖:版本+1,如果漏了某个字段没写,那么此字段会消失。
PUT /cd3/_doc/3 { "name" : "王五2",, "age" : 2, "about" : "我喜欢摇滚乐", "interests": [ "运动", "音乐" ] }
POST方式 - By字段更新,版本不会+1,不会丢失字段,路径后面要加上 _update。
POST /cd3/doc/3/update { "doc": { "name": "王五3" } }
删除
删除指定文档:
DELETE /cd3/_doc/3
删除索引:
DELETE test1
Elasticsearch 查询操作
简单查询
GET /cd/emp/_search
GET /cd/emp/_search?q=name:金毛狮王
hits:可以得到索引和文档的信息;查询的结果总数;查询的具体文档,可以遍历;分数:判断哪个更符合结果
复杂查询
-
query 查询
-
_source 展示的字段
-
sort 排序
-
from/size 分页
-
highlight 高亮
GET cd/emp/search { "query": { "match": { "name": "金毛狮王" } }, "highlight": { "pre_tags": "
", "post_tags": "
", "fields": { "name": {} } } , "source": ["age","name"] , "sort": [ { "age": { "order": "desc" } } ] , "from": 0 , "size": 10 }多条件查询
-
must 相当于 and
-
should 相当于 or
-
must_not 相当于 not ( ... and ... )
-
filter 过滤
GET cd/emp/_search { "query": { "bool": { "must": [ { "match": { "name": "金毛狮王" } }, { "match": { "age": 13 } } ] } } }
GET cd/emp/_search { "query": { "bool": { "should": [ { "match": { "name": "金毛狮王" } }, { "match": { "age": 13 } } ], "filter": [ { "range": { "age": { "gte": 0, "lte": 10 } } } ]
}
} }
match 会使用分词器解析
匹配数组字段可以空格隔开
精确查询
match:会使用分词器解析,对要查询的词进行分词,然后将只要包含一个分词的文档都查出来 term:不采用分词器解析,将包含完整的要查询的单词的文档查出来
term 直接通过 倒排索引 指定词条查询 适合查询 number、date、keyword ,不适合text
字段类型text和keyword text:支持分词,text字段单词会分词后存储 keyword:不进行分词,keyword字段单词不分词存储
定义类型:
PUT cd4 { "mappings": { "properties": { "name": { "type": "text" }, "desc": { "type": "keyword" } } } }
PUT /cd4/_doc/1 { "name": "张三", "desc": "张三爱打球" }
PUT /cd4/_doc/2 { "name": "张三三", "desc": "张三三爱打球" }
按照keyword类型精准匹配:
GET cd4/_search { "query": { "term": { "desc": "张三爱打球" } } }
按照name匹配:
GET /cd4/_search { "query": { "match": { "name": "张三" } } }
多个值精确匹配:
GET /cd4/_search { "query": { "bool": { "should": [ { "term": { "desc": "张三爱打球" } }, { "term": { "desc": "张三三爱打球" } } ] } } }
参考文档:
狂神说Java - Elasticsearch教程
-
-
相关阅读:
京准、ntp校时服务器(GPS北斗卫星校时器)技术方案
多频电磁法概述 - 1. 简介
滑动窗口:找到字符串中所有字母异位词
基于SSM的医院在线挂号预约系统的设计与实现
【Mycat2实战】五、Mycat实现分库分表【实践篇】
推荐一款企业级开源低代码工具,解放双手如此简单
Linux下redis安装教程
[libevent:构建高性能事件驱动应用的利器]
二十四、输入输出设备模型(串口/键盘/磁盘/打印机/总线/中断控制器/DMA和GPU)
深入学习和理解Django模板层:构建动态页面
- 原文地址:https://blog.csdn.net/aHardDreamer/article/details/126086790