-
CPM:A large-scale generative chinese pre-trained lanuage model
GitHub - yangjianxin1/CPM: Easy-to-use CPM for Chinese text generation(基于CPM的中文文本生成)Easy-to-use CPM for Chinese text generation(基于CPM的中文文本生成) - GitHub - yangjianxin1/CPM: Easy-to-use CPM for Chinese text generation(基于CPM的中文文本生成)
 https://github.com/yangjianxin1/CPM论文《CPM: A Large-scale Generative Chinese Pre-trained Language Model》_陈欢伯的博客-CSDN博客1. IntroductionGPT-3含有175B参数使用了570GB的数据进行训练。但大多数语料是基于英文(93%),并且GPT-3的参数没有分布,所以提出了CPM(Chinese Pretrained language Model):包含2.6B参数,使用100GB中文训练数据。CPM可以对接下游任务:对话、文章生成、完形填空、语言理解。随着参数规模的增加,CPM在一些数据集上表现更好,表示大模型在语言生成和理解上面更有效。文章的主要贡献发布了一个CPM:2.6B参数,100GB中文训练
https://github.com/yangjianxin1/CPM论文《CPM: A Large-scale Generative Chinese Pre-trained Language Model》_陈欢伯的博客-CSDN博客1. IntroductionGPT-3含有175B参数使用了570GB的数据进行训练。但大多数语料是基于英文(93%),并且GPT-3的参数没有分布,所以提出了CPM(Chinese Pretrained language Model):包含2.6B参数,使用100GB中文训练数据。CPM可以对接下游任务:对话、文章生成、完形填空、语言理解。随着参数规模的增加,CPM在一些数据集上表现更好,表示大模型在语言生成和理解上面更有效。文章的主要贡献发布了一个CPM:2.6B参数,100GB中文训练https://blog.csdn.net/mark_technology/article/details/118680728文章本身写的非常简单,至于模型结构这块,可以看一下放出来的代码,还挺好用的,我跑一个电商场景的推荐文章生成模型,效果也不错。在生成模型上还是很建议尝试一下CPM,整体采用transformer中的代码实现,比较简洁。

上面计算时间为使用单块NVIDIA V100 GPU训练的估计时间。
1.Approach
1.1 Chinese PLM(pretrained lanuage model)
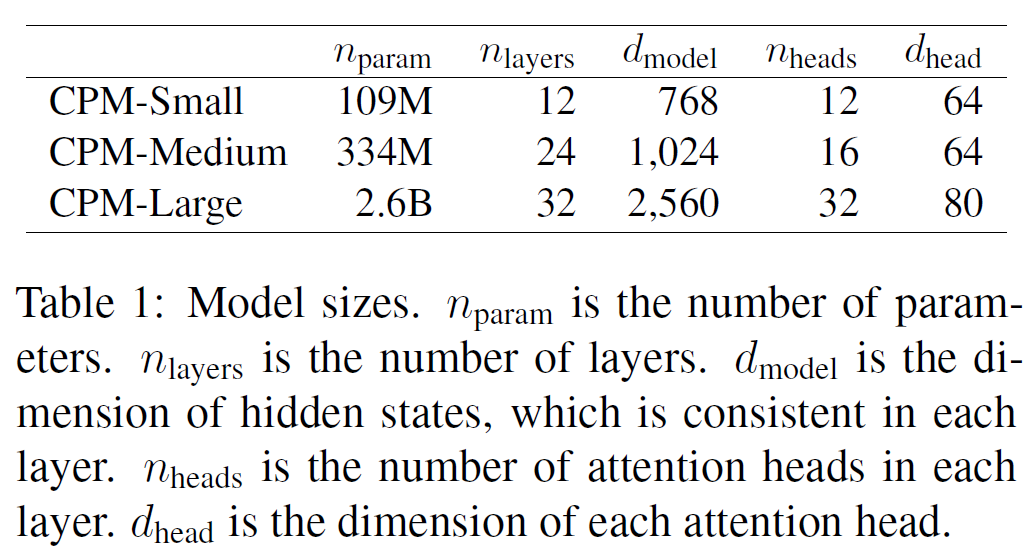
上面是CPM的模型参数版本,其中small版本至少我是可以在gtx1080ti上训练的,后面我会添加我的具体训练参数。
稍微过一下CPM的模型结构,其实就是gpt2的模型:
- transformer.wte.weight [30000, 768]
- transformer.wpe.weight [1024, 768]
- transformer.h.0.ln_1.weight [768]
- transformer.h.0.ln_1.bias [768]
- transformer.h.0.attn.bias [1, 1, 1024, 1024]
- transformer.h.0.attn.masked_bias []
- transformer.h.0.attn.c_attn.weight [768, 2304]
- transformer.h.0.attn.c_attn.bias [2304]
- transformer.h.0.attn.c_proj.weight [768, 768]
- transformer.h.0.attn.c_proj.bias [768]
- transformer.h.0.ln_2.weight [768]
- transformer.h.0.ln_2.bias [768]
- transformer.h.0.mlp.c_fc.weight [768, 3072]
- transformer.h.0.mlp.c_fc.bias [3072]
- transformer.h.0.mlp.c_proj.weight [3072, 768]
- transformer.h.0.mlp.c_proj.bias [768]
- transformer.h.1.ln_1.weight [768]
- transformer.h.1.ln_1.bias [768]
- transformer.h.1.attn.bias [1, 1, 1024, 1024]
- transformer.h.1.attn.masked_bias []
- transformer.h.1.attn.c_attn.weight [768, 2304]
- transformer.h.1.attn.c_attn.bias [2304]
- transformer.h.1.attn.c_proj.weight [768, 768]
- transformer.h.1.attn.c_proj.bias [768]
- transformer.h.1.ln_2.weight [768]
- transformer.h.1.ln_2.bias [768]
- transformer.h.1.mlp.c_fc.weight [768, 3072]
- transformer.h.1.mlp.c_fc.bias [3072]
- transformer.h.1.mlp.c_proj.weight [3072, 768]
- transformer.h.1.mlp.c_proj.bias [768]
- transformer.h.2.ln_1.weight [768]
- transformer.h.2.ln_1.bias [768]
- transformer.h.2.attn.bias [1, 1, 1024, 1024]
- transformer.h.2.attn.masked_bias []
- transformer.h.2.attn.c_attn.weight [768, 2304]
- transformer.h.2.attn.c_attn.bias [2304]
- transformer.h.2.attn.c_proj.weight [768, 768]
- transformer.h.2.attn.c_proj.bias [768]
- transformer.h.2.ln_2.weight [768]
- transformer.h.2.ln_2.bias [768]
- transformer.h.2.mlp.c_fc.weight [768, 3072]
- transformer.h.2.mlp.c_fc.bias [3072]
- transformer.h.2.mlp.c_proj.weight [3072, 768]
- transformer.h.2.mlp.c_proj.bias [768]
- transformer.h.3.ln_1.weight [768]
- transformer.h.3.ln_1.bias [768]
- transformer.h.3.attn.bias [1, 1, 1024, 1024]
- transformer.h.3.attn.masked_bias []
- transformer.h.3.attn.c_attn.weight [768, 2304]
- transformer.h.3.attn.c_attn.bias [2304]
- transformer.h.3.attn.c_proj.weight [768, 768]
- transformer.h.3.attn.c_proj.bias [768]
- transformer.h.3.ln_2.weight [768]
- transformer.h.3.ln_2.bias [768]
- transformer.h.3.mlp.c_fc.weight [768, 3072]
- transformer.h.3.mlp.c_fc.bias [3072]
- transformer.h.3.mlp.c_proj.weight [3072, 768]
- transformer.h.3.mlp.c_proj.bias [768]
- transformer.h.4.ln_1.weight [768]
- transformer.h.4.ln_1.bias [768]
- transformer.h.4.attn.bias [1, 1, 1024, 1024]
- transformer.h.4.attn.masked_bias []
- transformer.h.4.attn.c_attn.weight [768, 2304]
- transformer.h.4.attn.c_attn.bias [2304]
- transformer.h.4.attn.c_proj.weight [768, 768]
- transformer.h.4.attn.c_proj.bias [768]
- transformer.h.4.ln_2.weight [768]
- transformer.h.4.ln_2.bias [768]
- transformer.h.4.mlp.c_fc.weight [768, 3072]
- transformer.h.4.mlp.c_fc.bias [3072]
- transformer.h.4.mlp.c_proj.weight [3072, 768]
- transformer.h.4.mlp.c_proj.bias [768]
- transformer.h.5.ln_1.weight [768]
- transformer.h.5.ln_1.bias [768]
- transformer.h.5.attn.bias [1, 1, 1024, 1024]
- transformer.h.5.attn.masked_bias []
- transformer.h.5.attn.c_attn.weight [768, 2304]
- transformer.h.5.attn.c_attn.bias [2304]
- transformer.h.5.attn.c_proj.weight [768, 768]
- transformer.h.5.attn.c_proj.bias [768]
- transformer.h.5.ln_2.weight [768]
- transformer.h.5.ln_2.bias [768]
- transformer.h.5.mlp.c_fc.weight [768, 3072]
- transformer.h.5.mlp.c_fc.bias [3072]
- transformer.h.5.mlp.c_proj.weight [3072, 768]
- transformer.h.5.mlp.c_proj.bias [768]
- transformer.h.6.ln_1.weight [768]
- transformer.h.6.ln_1.bias [768]
- transformer.h.6.attn.bias [1, 1, 1024, 1024]
- transformer.h.6.attn.masked_bias []
- transformer.h.6.attn.c_attn.weight [768, 2304]
- transformer.h.6.attn.c_attn.bias [2304]
- transformer.h.6.attn.c_proj.weight [768, 768]
- transformer.h.6.attn.c_proj.bias [768]
- transformer.h.6.ln_2.weight [768]
- transformer.h.6.ln_2.bias [768]
- transformer.h.6.mlp.c_fc.weight [768, 3072]
- transformer.h.6.mlp.c_fc.bias [3072]
- transformer.h.6.mlp.c_proj.weight [3072, 768]
- transformer.h.6.mlp.c_proj.bias [768]
- transformer.h.7.ln_1.weight [768]
- transformer.h.7.ln_1.bias [768]
- transformer.h.7.attn.bias [1, 1, 1024, 1024]
- transformer.h.7.attn.masked_bias []
- transformer.h.7.attn.c_attn.weight [768, 2304]
- transformer.h.7.attn.c_attn.bias [2304]
- transformer.h.7.attn.c_proj.weight [768, 768]
- transformer.h.7.attn.c_proj.bias [768]
- transformer.h.7.ln_2.weight [768]
- transformer.h.7.ln_2.bias [768]
- transformer.h.7.mlp.c_fc.weight [768, 3072]
- transformer.h.7.mlp.c_fc.bias [3072]
- transformer.h.7.mlp.c_proj.weight [3072, 768]
- transformer.h.7.mlp.c_proj.bias [768]
- transformer.h.8.ln_1.weight [768]
- transformer.h.8.ln_1.bias [768]
- transformer.h.8.attn.bias [1, 1, 1024, 1024]
- transformer.h.8.attn.masked_bias []
- transformer.h.8.attn.c_attn.weight [768, 2304]
- transformer.h.8.attn.c_attn.bias [2304]
- transformer.h.8.attn.c_proj.weight [768, 768]
- transformer.h.8.attn.c_proj.bias [768]
- transformer.h.8.ln_2.weight [768]
- transformer.h.8.ln_2.bias [768]
- transformer.h.8.mlp.c_fc.weight [768, 3072]
- transformer.h.8.mlp.c_fc.bias [3072]
- transformer.h.8.mlp.c_proj.weight [3072, 768]
- transformer.h.8.mlp.c_proj.bias [768]
- transformer.h.9.ln_1.weight [768]
- transformer.h.9.ln_1.bias [768]
- transformer.h.9.attn.bias [1, 1, 1024, 1024]
- transformer.h.9.attn.masked_bias []
- transformer.h.9.attn.c_attn.weight [768, 2304]
- transformer.h.9.attn.c_attn.bias [2304]
- transformer.h.9.attn.c_proj.weight [768, 768]
- transformer.h.9.attn.c_proj.bias [768]
- transformer.h.9.ln_2.weight [768]
- transformer.h.9.ln_2.bias [768]
- transformer.h.9.mlp.c_fc.weight [768, 3072]
- transformer.h.9.mlp.c_fc.bias [3072]
- transformer.h.9.mlp.c_proj.weight [3072, 768]
- transformer.h.9.mlp.c_proj.bias [768]
- transformer.h.10.ln_1.weight [768]
- transformer.h.10.ln_1.bias [768]
- transformer.h.10.attn.bias [1, 1, 1024, 1024]
- transformer.h.10.attn.masked_bias []
- transformer.h.10.attn.c_attn.weight [768, 2304]
- transformer.h.10.attn.c_attn.bias [2304]
- transformer.h.10.attn.c_proj.weight [768, 768]
- transformer.h.10.attn.c_proj.bias [768]
- transformer.h.10.ln_2.weight [768]
- transformer.h.10.ln_2.bias [768]
- transformer.h.10.mlp.c_fc.weight [768, 3072]
- transformer.h.10.mlp.c_fc.bias [3072]
- transformer.h.10.mlp.c_proj.weight [3072, 768]
- transformer.h.10.mlp.c_proj.bias [768]
- transformer.h.11.ln_1.weight [768]
- transformer.h.11.ln_1.bias [768]
- transformer.h.11.attn.bias [1, 1, 1024, 1024]
- transformer.h.11.attn.masked_bias []
- transformer.h.11.attn.c_attn.weight [768, 2304]
- transformer.h.11.attn.c_attn.bias [2304]
- transformer.h.11.attn.c_proj.weight [768, 768]
- transformer.h.11.attn.c_proj.bias [768]
- transformer.h.11.ln_2.weight [768]
- transformer.h.11.ln_2.bias [768]
- transformer.h.11.mlp.c_fc.weight [768, 3072]
- transformer.h.11.mlp.c_fc.bias [3072]
- transformer.h.11.mlp.c_proj.weight [3072, 768]
- transformer.h.11.mlp.c_proj.bias [768]
- transformer.ln_f.weight [768]
- transformer.ln_f.bias [768]
- lm_head.weight [30000, 768]
1.2 data processing
CPM的词汇表有3w个。丰富的中文训练数据,中文数据其实比较好搞,直接网上爬就可以,git上作为提供了一个作文预训练的模型,在这个预训练模型上finetune效果也不错,我的训练数据大概有7-8w的标题-文本对数据。

1.3 pr-training details
lr=1.5x10-4,batch_size=3072,max_len:1024(训练时,输入数据的最大长度),steps=2000(前500轮warmup),optimizer=adam,64*v100训了2周。
2x1080ti:cpm-small版本,max_len:200,lr=0.00015,batch_size:16,steps:100,adamw。
transformer=4.6.0
2.后面是cpm在一些任务上的实验。
-
相关阅读:
神经网络常用的训练方式,神经网络训练过程详解
神经网络的主要内容特点,神经网络的种类和特点
【Python】安装autopep8包,并在PyCharm中进行配置,以PEP8规范排版代码
Mac 取消系统更新的红点——强迫症晚期患者
mybatics 连接池-Druid
老子云平台会员专业又有性价比!
Verilog 之 wire与reg 类型的变量
LeetCode 刷题 [C++] 第73题.矩阵置零
亚马逊秋季促销指南——如何更好的利用促销?
基于JavaWeb的大学社团管理系统的设计与实现
- 原文地址:https://blog.csdn.net/u012193416/article/details/126040727
