-
基于K8S构建Spark镜像-尚硅谷Java培训
一、构建Spark镜像
1、 上传Spark的压缩包到software,进行解压
[root@k8s101 ~]# cd /opt/software/ [root@k8s101 software]# tar -zxvf spark-3.0.0-bin-hadoop2.7.tgz
2、 修改spark配置文件
[k8s@k8s101 software]$ cd spark-3.0.0-bin-hadoop2.7 [k8s@k8s101 spark-3.0.0-bin-hadoop2.7]$ cd conf/ [k8s@k8s101 conf]$ mv spark-env.sh.template spark-env.sh [k8s@k8s101 conf]$ vim spark-env.sh HADOOP_CONF_DIR=/opt/module/hadoop-3.1.3/etc/hadoop export LD_LIBRARY_PATH=$HADOOP_HOME/lib/native
3、 创建阿里云仓库
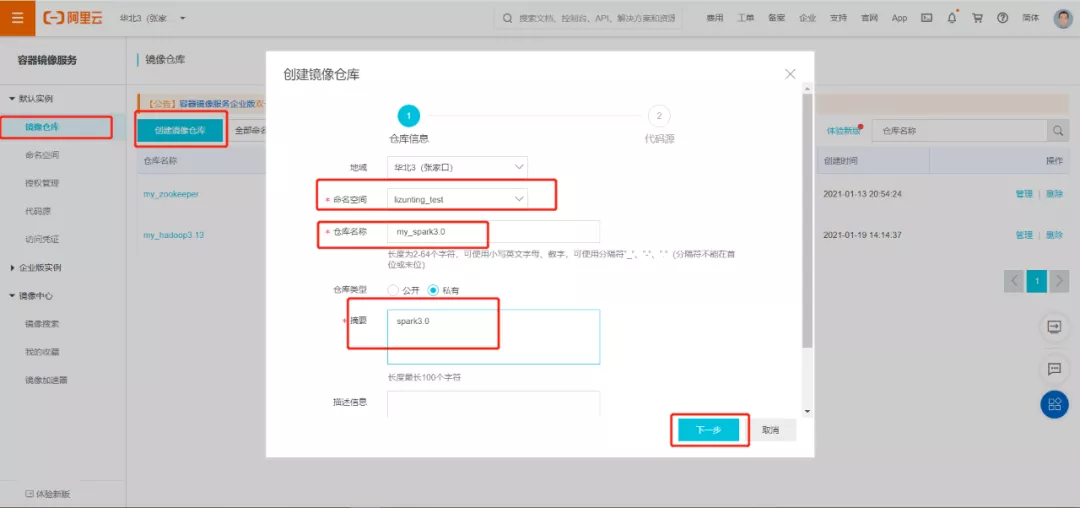
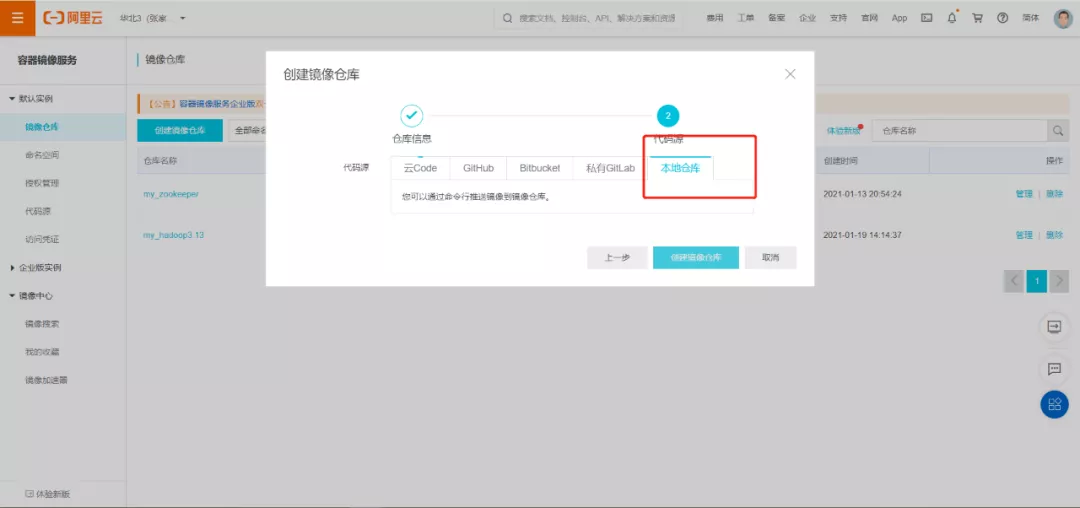

4、 根据官方提供的脚本构建镜像,仓库名就是当前阿里云创建的仓库名
[root@k8s101 spark-3.0.0-bin-hadoop2.7]# bin/docker-image-tool.sh -r registry.cn-zhangjiakou.aliyuncs.com/lizunting_test-t my_spark3.0 build
5、 查看docker镜像
[root@k8s101 spark-3.0.0-bin-hadoop2.7]# docker images

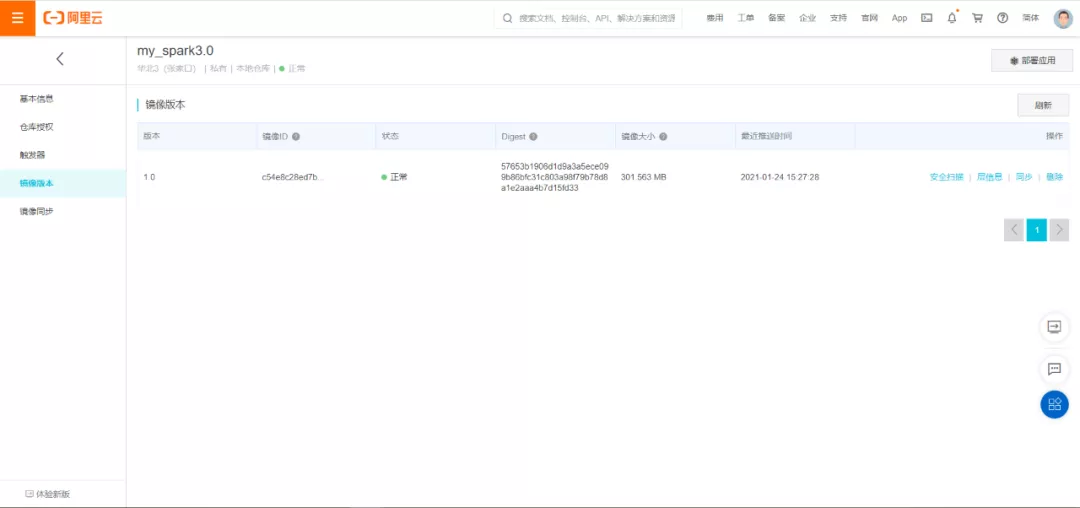
6、 将spark3镜像推送到阿里云上
[root@k8s101 spark-3.0.0-bin-hadoop2.7]# docker tagc54e8c28ed7b registry.cn-zhangjiakou.aliyuncs.com/lizunting_test/my_spark3.0:1.0 [root@k8s101 spark-3.0.0-bin-hadoop2.7]# docker pushregistry.cn-zhangjiakou.aliyuncs.com/lizunting_test/my_spark3.0:1.0
二、构建Spark pvc
创建spark pvc
[k8s@k8s101 ~]$ mkdir spark [k8s@k8s101 ~]$ cd spark/ [k8s@k8s101 spark]$ vim spark-pvc.yaml kind:PersistentVolumeClaim apiVersion:v1 metadata: name: spark-pvc annotations: volume.beta.kubernetes.io/storage-class:"managed-nfs-storage" spec: accessModes: - ReadWriteMany resources: requests: storage: 2G [k8s@k8s101 spark]$ kubectl create -f spark-pvc.yaml三、创建Spark需要的ConfigMap
[k8s@k8s101 software]$ kubectl create configmap spark-conf-volume--from-file=/opt/software/spark-3.0.0-bin-hadoop2.7/conf/ [k8s@k8s101 software]$ kubectl create configmap hadoop-properties--from-file=/opt/module/hadoop-3.1.3/etc/hadoop/
四、创建Endpoint和Service
创建endpoint指向各节点,创建service暴露服务和端口,为了让pod能访问到外部hadoop集群
[k8s@k8s101 spark]$ vim node-endpoints.yaml apiVersion:v1 kind:Endpoints metadata: name: k8s101 namespace: default subsets: - addresses: - ip: 172.26.64.126 ports: - port: 8020 --- apiVersion:v1 kind:Endpoints metadata: name: k8s102 namespace: default subsets: - addresses: - ip: 172.26.64.124 ports: - port: 8020 --- apiVersion:v1 kind:Endpoints metadata: name: k8s103 namespace: default subsets: - addresses: - ip: 172.26.64.125 ports: - port: 8020 [k8s@k8s101 spark]$ kubectl create -f node-endpoints.yaml [k8s@k8s101 spark]$ vim node-service.yaml apiVersion:v1 kind:Service metadata: name: k8s101 spec: ports: - port: 8020 --- apiVersion:v1 kind:Service metadata: name: k8s102 spec: ports: - port: 8020 --- apiVersion:v1 kind:Service metadata: name: k8s103 spec: ports: -port: 8020 [k8s@k8s101 spark]$ kubectl create -f node-service.yaml五、创建Spark用户并赋予权限
[k8s@k8s101 ~]$ kubectl create serviceaccount spark [k8s@k8s101 ~]$ kubectl create clusterrolebinding spark-role --clusterrole=edit--serviceaccount=default:spark --namespace=default
六、测试例子
1、 查看master地址
[root@k8s101 spark-3.0.0-bin-hadoop2.7]# su k8s [k8s@k8s101 spark-3.0.0-bin-hadoop2.7]$ kubectl cluster-info

2、执行Spark任务提交命令
bin/spark-submit \ --master k8s://https://k8s101:6443 \ --deploy-mode cluster \ --name spark-pi \ --class org.apache.spark.examples.SparkPi \ --confspark.kubernetes.authenticate.driver.serviceAccountName=spark \ --conf spark.executor.instances=2 \ --confspark.kubernetes.container.image=registry.cn-zhangjiakou.aliyuncs.com/lizunting_test/my_spark3.0:1.0\ --confspark.kubernetes.file.upload.path=hdfs://mycluster/tmp \ --confspark.kubernetes.driver.volumes.persistentVolumeClaim.data.options.claimName=spark-pvc\ --confspark.kubernetes.driver.volumes.persistentVolumeClaim.data.mount.path=/data/nfs/ \ /opt/software/spark-3.0.0-bin-hadoop2.7/examples/jars/spark-examples_2.12-3.0.0.jar3、 查看日志

[k8s@k8s101 spark-3.0.0-bin-hadoop2.7]$ kubectl logs spark-pi-ee19b477342871ff-driver
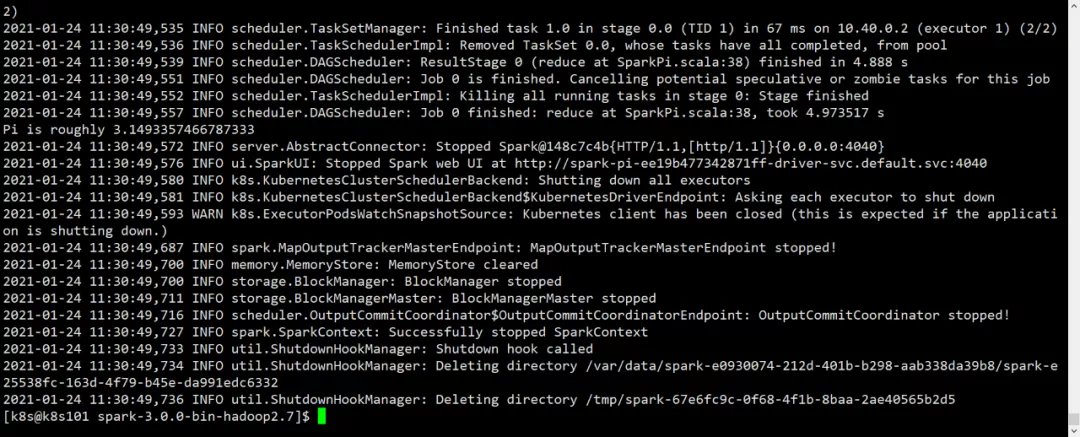
运行成功
七、测试Spark SQL任务
1、 上传测试的日志文件到/opt/software目录,然后使用hdfs命令上传hadoop路径
[root@k8s101 software]# hadoop dfs -mkdir -p /user/atguigu/ods/ [root@k8s101 software]# hadoop dfs -put *.log /user/atguigu/ods/
2、 进入到hive创建三个库dwd,dws,ads。然后见表,参见参考文件“用户注册模块.txt”。
3、 将hive.xml复制spark conf下,spark on hive模式。需要重新更新下spark-conf-volume
[k8s@k8s101 software]$ cp /opt/module/apache-hive-3.1.2-bin/conf/hive-site.xml/opt/software/spark-3.0.0-bin-hadoop2.7/conf/ [k8s@k8s101 software]$ kubectl delete configmap spark-conf-volume [k8s@k8s101 software]$ kubectl create configmap spark-conf-volume--from-file=/opt/software/spark-3.0.0-bin-hadoop2.7/conf/
4、 重新更新下endpoint和service需要对外开放9083 hive元数据服务端口。hive装在101上所以只更改101的配置
[k8s@k8s101 software]$ cd ~ [k8s@k8s101 ~]$ cd spark/ [k8s@k8s101 spark]$ kubectl delete -f node-endpoints.yaml -f node-service.yaml [k8s@k8s101 spark]$ vim node-endpoints.yaml apiVersion:v1 kind:Endpoints metadata: name: k8s101 namespace: default subsets: - addresses: - ip: 172.26.64.126 ports: - port: 8020 name: rpc - port: 9866 name: dnport - port: 9083 name: hivemetastore [k8s@k8s101 spark]$ vim node-service.yaml apiVersion:v1 kind:Service metadata: name: k8s101 spec: ports: - port: 8020 name: rpc - port: 9866 name: dnport - port: 9083 name: hivemetastore [k8s@k8s101 spark]$ kubectlcreate -f node-endpoints.yaml -f node-service.yaml5、 然后将编写完的代码打成jar包,上传进行测试打成jar包的时候,需要将集群的hive-site.xml,hdfs-site.xml,core-site.xml放到resources源码包下,不然会识别不到hive。
[k8s@k8s101 software]$ cd spark-3.0.0-bin-hadoop2.7 执行以下命令 bin/spark-submit \ --master k8s://https://k8s101:6443 \ --deploy-mode cluster \ --name spark-pi \ --class com.atguigu.member.controller.DwdMemberController \ --conf spark.kubernetes.authenticate.driver.serviceAccountName=spark\ --conf spark.executor.instances=3 \ --confspark.kubernetes.container.image=registry.cn-zhangjiakou.aliyuncs.com/lizunting_test/my_spark3.0:1.0\ --confspark.kubernetes.file.upload.path=hdfs://mycluster/tmp \ --confspark.kubernetes.driver.volumes.persistentVolumeClaim.data.options.claimName=spark-pvc\ --confspark.kubernetes.driver.volumes.persistentVolumeClaim.data.mount.path=/data/nfs/ \ /opt/software/com_atguigu_warehouse-1.0-SNAPSHOT-jar-with-dependencies.jar
6、 任务跑完之后,查看pod
[k8s@k8s101 software]$ kubectl get pods

7、 可以看到pod状态已完成,根据pod名称使用log命令可以查看对应日志,如果报错,日志里有错误信息.
[k8s@k8s101 software]$ kubectl logs spark-pi-ee19b477342871ff-driver
8、 日志里并没有出错,再查看hive里是否有数据。随便抽张表
[k8s@k8s101 software]$ hive hive(default)> use dwd; hive(dwd)> select *from dwd_base_ad;

八、测试Spark Streaming任务
1、 启动kafka,创建测试topic
[root@k8s101 spark-3.0.0-bin-hadoop2.7]# cd /opt/module/kafka_2.11-2.4.0/ [k8s@k8s101 kafka_2.11-2.4.0]$ bin/kafka-topics.sh --zookeeper k8s101:2181/kafka_2.4--create --replication-factor 2 --partitions 10 --topic register_topic
2、 同样需要开放kafka9092端口,修改对应endpoint和servicec开发端口
[k8s@k8s101 ~]$ cd spark/ [k8s@k8s101 spark]$ kubectl delete -f node-endpoints.yaml -f node-service.yaml [k8s@k8s101 spark]$ vim node-endpoints.yaml apiVersion:v1 kind:Endpoints metadata: name: k8s101 namespace: default subsets: - addresses: - ip: 172.26.64.126 ports: - port: 8020 name: rpc - port: 9866 name: dnport - port: 9083 name: hivemetastore - port: 9092 name: kafka --- apiVersion:v1 kind:Endpoints metadata: name: k8s102 namespace: default subsets: - addresses: - ip: 172.26.64.124 ports: -port: 8020 name: rpc - port: 9866 name: dnport - port: 9092 name: kafka --- apiVersion:v1 kind:Endpoints metadata: name: k8s103 namespace: default subsets: - addresses: - ip: 172.26.64.125 ports: -port: 8020 name: rpc - port: 9866 name: dnport - port: 9092 name: kafka [k8s@k8s101 spark]$ vim node-service.yaml apiVersion:v1 kind:Service metadata: name: k8s101 spec: ports: - port: 8020 name: rpc - port: 9866 name: dnport - port: 9083 name: hivemetastore - port: 9092 name: kafka --- apiVersion:v1 kind:Service metadata: name: k8s102 spec: ports: - port: 8020 name: rpc - port: 9866 name: dnport - port: 9092 name: kafka --- apiVersion:v1 kind:Service metadata: name: k8s103 spec: ports: - port: 8020 name: rpc - port: 9866 name: dnport - port: 9092 name: kafka [k8s@k8s101 spark]$ kubectl create -f node-endpoints.yaml -f node-service.yaml3、 使用准备好的数据和代码往对应topic灌测试数据,参考数据文件以及数据发送代码register.log,registerProducer.scala
4、 kafka有了数据之后,可以测试spark streaming任务了。
package com.atguigu.qzpoint.streaming import java.lang import java.sql.ResultSet import com.atguigu.qzpoint.util.{DataSourceUtil, QueryCallback, SqlProxy} import org.apache.kafka.clients.consumer.ConsumerRecord import org.apache.kafka.common.TopicPartition import org.apache.kafka.common.serialization.StringDeserializer import org.apache.spark.SparkConf import org.apache.spark.streaming.dstream.InputDStream import org.apache.spark.streaming.kafka010._ import org.apache.spark.streaming.{Seconds, StreamingContext} import scala.collection.mutable object RegisterStreaming2 { private val groupid ="register_group_test" def main(args: Array[String]): Unit = { val conf = newSparkConf().setAppName(this.getClass.getSimpleName) .set("spark.streaming.kafka.maxRatePerPartition","300") val ssc = new StreamingContext(conf,Seconds(3)) val sparkContext = ssc.sparkContext sparkContext.hadoopConfiguration.set("fs.defaultFS","hdfs://nameservice1") sparkContext.hadoopConfiguration.set("dfs.nameservices","nameservice1") val topics =Array("register_topic") val kafkaMap: Map[String, Object] =Map[String, Object]( "bootstrap.servers" ->"k8s101:9092,k8s102:9092,k8s103:9092", "key.deserializer" ->classOf[StringDeserializer], "value.deserializer"-> classOf[StringDeserializer], "group.id" -> groupid, "auto.offset.reset" ->"earliest", "enable.auto.commit"-> (false: lang.Boolean) ) val stream:InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream( ssc,LocationStrategies.PreferConsistent, ConsumerStrategies.Subscribe[String,String](topics, kafkaMap)) val resultDStream =stream.filter(item => item.value().split("\t").length == 3). mapPartitions(partitions => { partitions.map(item => { val line = item.value() val arr =line.split("\t") val app_name = arr(1) match { case "1" =>"PC" case "2" =>"APP" case _ =>"Other" } (app_name, 1) }) }) resultDStream.reduceByKeyAndWindow((x: Int, y: Int) => x + y,Seconds(60), Seconds(6)).print() ssc.start() ssc.awaitTermination() } }5、 将代码打成jar包上传到集群进行测试。
[k8s@k8s101 software]$ cdspark-3.0.0-bin-hadoop2.7 bin/spark-submit\ --master k8s://https://k8s101:6443 \ --deploy-mode cluster \ --name spark-pi \ --classcom.atguigu.qzpoint.streaming.RegisterStreaming2\ --confspark.kubernetes.authenticate.driver.serviceAccountName=spark \ --conf spark.executor.instances=3 \ --conf spark.kubernetes.container.image=registry.cn-zhangjiakou.aliyuncs.com/lizunting_test/my_spark3.0:1.0\ --confspark.kubernetes.file.upload.path=hdfs://mycluster/tmp \ --confspark.kubernetes.driver.volumes.persistentVolumeClaim.data.options.claimName=spark-pvc\ --conf spark.kubernetes.driver.volumes.persistentVolumeClaim.data.mount.path=/data/nfs/ \ /opt/software/com_atguigu_sparkstreaming-1.0-SNAPSHOT-jar-with-dependencies.jar6、 运行成功查看pod,有2个executor的pod pending,使用describe可查看详情,显示cpu资源不足,所以没起来,不影响处理。

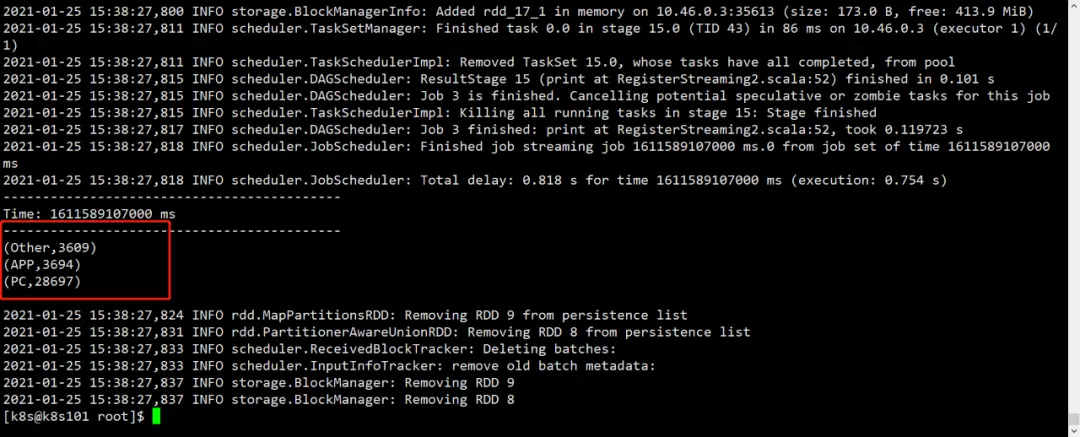
7、 查看日志看输出结果。-f参数 一直监控日志
[k8s@k8s101 root]$ kubectl logs -f spark-pi-a27e40773a316496-driver
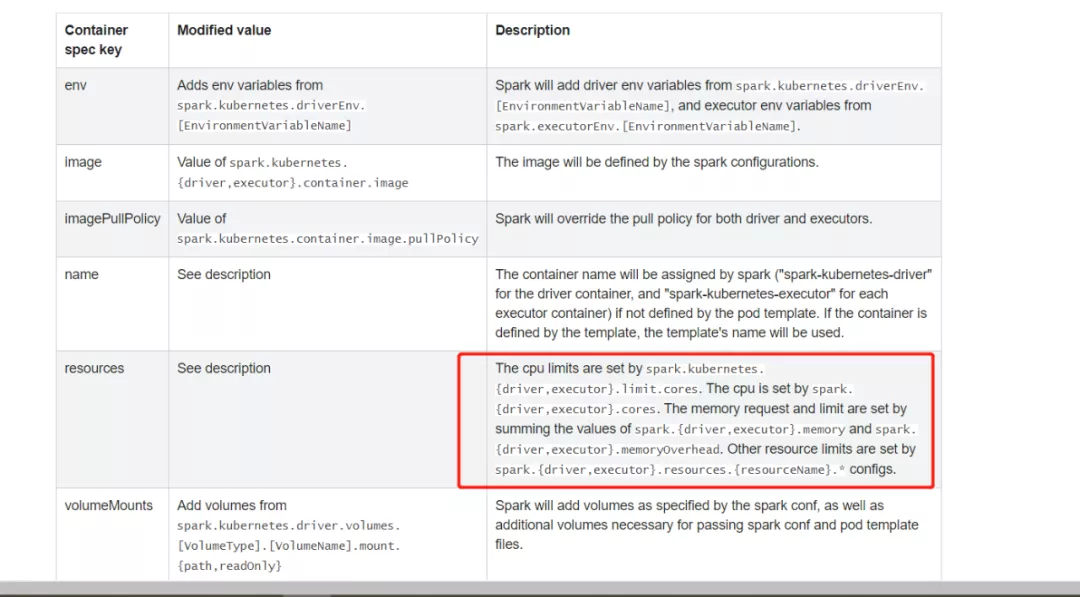
具体资源参数控制可参考官网:
http://spark.apache.org/docs/latest/running-on-kubernetes.html#configuration
九、Spark UI
1、 spark任务运行在容器内部,这个时候直接访问4040端口是访问不到的,需要对外进行转发暴露。根据pod名称使用命令,
spark-pi-1f85e07747273183-driver为pod名称[k8s@k8s101 root]$ kubectl port-forward --address 0.0.0.0 spark-pi-1f85e07747273183-driver4040:4040
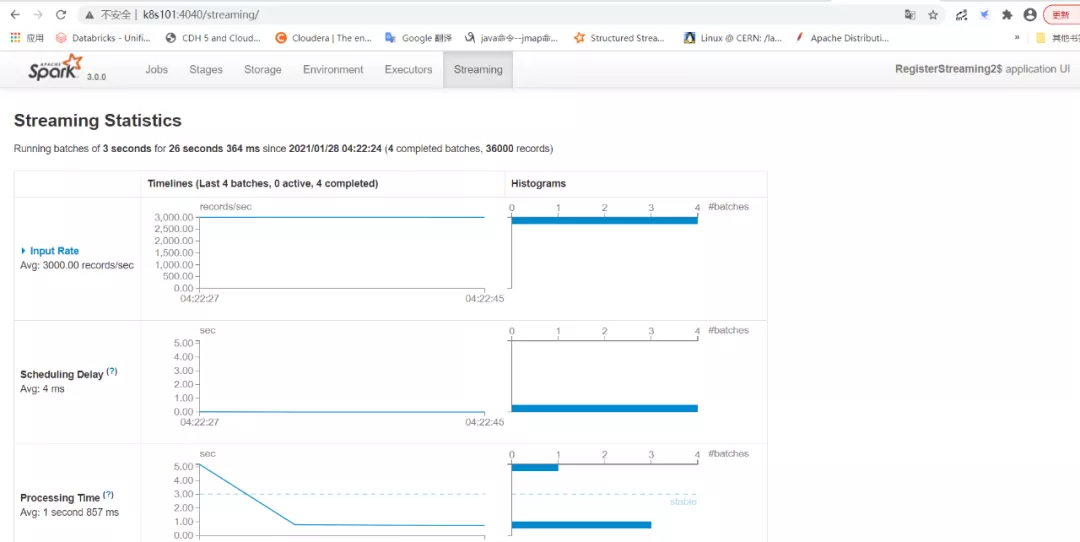
2、 转发命令完成后,使用浏览器访问,就可以访问到UI界面了
3、 如果想杀死对应任务,使用命令。defalut是pod所在namespace
[k8s@k8s101 spark-3.0.0-bin-hadoop2.7]$ bin/spark-submit --killdefault:spark-pi-1f85e07747273183-driver --master k8s://https://k8s101:6443
十、历史服务器
1、 修改spark.default.conf配置文件
[k8s@k8s101 ~]$ cd /opt/software/spark-3.0.0-bin-hadoop2.7/conf [k8s@k8s101 conf]$ mv spark-defaults.conf.template spark-defaults.conf [k8s@k8s101 conf]$ vim spark-defaults.conf spark.eventLog.enabledtrue spark.eventLog.dirhdfs://mycluster/sparklogs spark.history.fs.logDirectory hdfs://mycluster/sparklogs
2、 创建目录
[root@k8s101 conf]# hadoop dfs -mkdir /sparklogs
3、 启动spark历史服务
[root@k8s101 spark-3.0.0-bin-hadoop2.7]# sbin/start-history-server.sh

4、 浏览器访问18080端口

5、 重新更新spark-conf-volume cobfigmap
[k8s@k8s101 spark-3.0.0-bin-hadoop2.7]$ kubectl delete configmap spark-conf-volume [k8s@k8s101 spark-3.0.0-bin-hadoop2.7]$ kubectl create configmap spark-conf-volume--from-file=/opt/software/spark-3.0.0-bin-hadoop2.7/conf/
6、 测试,再次跑spark on k8s的任务,查看页面,可以看到历史任务
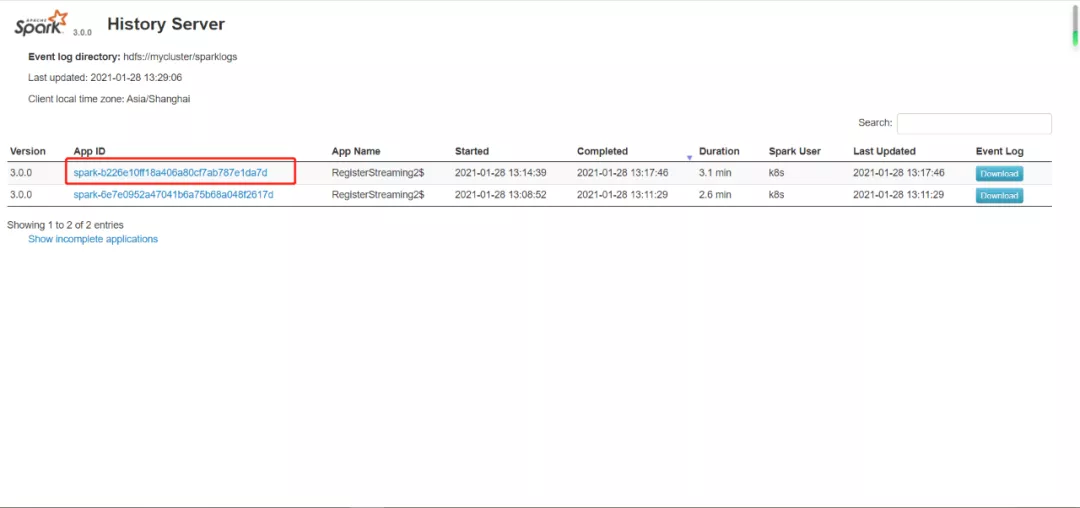
7、 点击查看详情

-
相关阅读:
3.程序控制
Codeforces Round 895 (Div. 3) C题QAQ原理秒杀
jQuery表单属性过滤器:过滤<input>标签、<select>标签
【系统稳定性】1.1 诊断日志分布体系(一,日志矩阵)
SOC设计:关于时钟门控的细节
ROS vscode开发,故障解决
经典动画库 animate.css 的应用
SQL刷题查漏补缺5
C# 异步编程,有时候我们需要拿到异步任务计算体完成计算的数据,请使用task.AsyncState去获取。
前端大文件上传如何实现(文件切片)
- 原文地址:https://blog.csdn.net/zjjcchina/article/details/126036228
