-
Focal Loss讲解
1. 概述
论文:Focal Loss for Dense Object Detection
Focal Loss网上的争议比较大,有些人觉得Focal Loss有用,有些人觉得没有任何作用
在Yolov3中作者尝试使用Focal Loss,但是使用后作者发现它的mAP还降了2个点,所以作者也感到好奇。
原论文给出了Focal Loss的一组参数,第一行 r = 0 r=0 r=0表示不使用Focal Loss,AP为31.1 ,但是采用Focal Loss之后达到了34.0,相比于不使用Focal Loss提升了3个点,效果还是相当明显的。在论文作者提到
Focal Loss主要针对One-Stage目标检测的,对于one-stage模型都会面临class imblance这个问题,也就是正负样本不平衡问题。一张图像中能够匹配到目标的候选框(正样本)个数一般只有十几个或几十个,而没有匹配到的候选框(负样本)大概有10^4~10^5

通过上面的图可以看到,红色的框其实都没有匹配到目标,而黄色的是匹配的目标框的。所以在匹配正负样本的时候绝大部分是没有匹配到的,也就是归于负样本这个类,而正样本其实是非常少的。这里肯定会有疑问,为什么
two stage 网络就没听到类别不均衡问题。- 个人理解,two stage分两步走,在第一步中类别不均衡的情况,肯定也是存在的。但最终的结果是通过第二阶段的检测来确定我们目标的最终坐标以及它是否为目标。而通过我们第一个阶段比如说
Faster RCNN通过RPN之后我们最终提供给第二阶段网络的目标个数也就2000多个,RPN筛选除了相对质量比较好的目标框,目标框可能是正样本的概率变大了,而One-stage有上万、十几万个,对于two stage的第二阶段而言它也是存在正负样本不均衡的问题,但是相比于One stage已经好了很多,所以我们论文提出的Focal Loss主要是针对one stage网络的。 - 针对
one stage中这 1 0 4 10^4 104 1 0 5 10^5 105未匹配的目标候选框中大部分都是简单易分的负样本(对网络训练起不到任何作用,但由于数量太多会淹没掉少量但有助于训练的样本),所以直接选择所有样本训练网络的话,效果会很差 - 之前我们
one-stage网络也有筛选正负样本,就是hard negative mining,并不会使用所有负样本训练网络,而是去选择那些对损失影响比较大的去训练网络,这样确实也能达到一个比较好的效果。

上图表格中,作者也做了一系列比较。表格的前面列的数据采用的是hard negative mining方法,去采样我们的正负样本。但是如果直接使用本文提出的Focal Loss我们会发现,它的效果还是非常好的。相对于hard negative mining方法,AP提高了3个点。Focal Loss为什么效果会比较好,我们后面会介绍它的理论。
2. Focal Loss
论文中提到
Focal Loss是为了解决 one stage目标检测中前景和背景样本极度不平衡的情况,比如(1:1000). 对于二分类交叉熵损失,它的计算公式如下:

为了简化,我们定义 p t p_t pt:

则:
C E ( p , y ) = C E ( p t ) = − l o g ( p t ) CE(p,y)=CE(p_t)= -log(p_t) CE(p,y)=CE(pt)=−log(pt)平衡交叉熵
解决样本不平衡的常用方法是,引入权重因子 a a a, a a a在[0,1]区间。当y=1为正样本的时候为 a a a,当为负样本的时候为 1 − a 1-a 1−a,因此增加了 a a a因子的损失可以写成如下:
C E ( p t ) = a t l o g ( p t ) CE(p_t)=a_tlog(p_t) CE(pt)=atlog(pt)

图中作者做实验,在 a = 0.75 a=0.75 a=0.75的时候,效果最好。所以可以看出 a a a并不是正负样本的比例,因为正负样本的比率很小,可能是1:1000,而不是0.75Focal Loss 定义
a a a是平衡正负样本的权重,但它并不能区分哪些是容易的样本哪些是困难的样本。所以论文作者改进了损失函数,通过它可以降低容易样本的权重,因此我们能够聚焦于
hard negative样本(难分的负样本)的训练。作者引入了新的系数 ( 1 − P t ) r (1-P_t)^r (1−Pt)r ,Focal Loss的定义为:
F L ( p t ) = − ( 1 − p t ) r l o g ( p t ) FL(p_t)=-(1-p_t)^rlog(p_t) FL(pt)=−(1−pt)rlog(pt)
( 1 − p t ) r (1-p_t)^r (1−pt)r能够降低易分样本的损失贡献
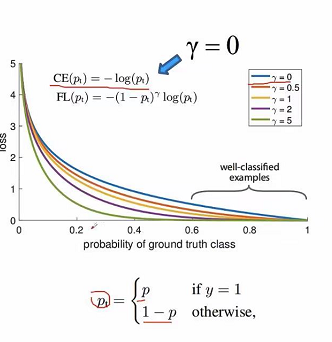
当 r = 0 r=0 r=0时,就变成我们最原始的 C E ( p t ) = − l o g ( p t ) CE(p_t)=-log(p_t) CE(pt)=−log(pt),对应的是图中蓝色的曲线,

图中的横坐标代表的是 p t p_t pt,如果正样本的话, p t = p p_t=p pt=p,我们希望p越大越好,p概率越大说明预测目标越准确。对于负样本的话,p越小越好,也就是1-p越大越好,因此可以看出无论正样本还是负样本我们希望 p t p_t pt越大越好。

我们可以看到到 p t p_t pt值在[0.6 1]区间,属于分类比较好的情况,对于分类比较好的其实就是很容易分类的样本,这些简单的样本其实我们没必要放很大的权重。从图中我们看到当 r > 0 r>0 r>0的时候,当 r = 1 , 2 , 5 r=1,2,5 r=1,2,5的时候,随着 p t p_t pt的增大,它下降的越来越快,当 r r r越大,易分样本的权重就越小。在实际应用中我们在
Focal Loss用 a a a来平衡样本,最终的Focal Loss如下:
F L ( p t ) = − a t ( 1 − p t ) r l o g ( p t ) FL(p_t)=-a_t(1-p_t)^rlog(p_t) FL(pt)=−at(1−pt)rlog(pt)
对 p t p_t pt展开后的Focal Loss形式如下:

使用Focal Loss之后我们会更专注于难学习的样本。对于简单的样本,Focal Loss会降低它的损失权重。
在使用Focal Loss的时候,训练集尽量标注正确,不要有错误,标注错误的话,肯定是难学习的样本,Focal Loss可能会针对标注错误的样本疯狂学习,导致模型效果越来越差。 - 个人理解,two stage分两步走,在第一步中类别不均衡的情况,肯定也是存在的。但最终的结果是通过第二阶段的检测来确定我们目标的最终坐标以及它是否为目标。而通过我们第一个阶段比如说
-
相关阅读:
python常见的输出格式总结
27、Flink 的SQL之SELECT (窗口函数)介绍及详细示例(3)
node.js学习笔记 09核心模块
鸿蒙 Harmony ArkTs开发教程三 流程控制
【SSM框架】MyBatis核心配置文件详解
go gin gorm连接postgres postgis输出geojson
Dubbo反序列化漏洞分析集合
JAVA核心类-String
玄机科技闪耀中国国际动漫节,携手百度共绘 AI 国漫新篇章
XPS表面及表面分析技术-科学指南针
- 原文地址:https://blog.csdn.net/weixin_38346042/article/details/126015654