-
Chapter 6 提升
1 随机森林的特点
随机森林的决策树分别采样建立,相对独立。
ps:由弱分类器——>强分类器方法:样本加权、分类器加权。
样本加权:例如对于某个样本进行分类,会存在分类错误的样本,对此增大其权值。
分类器加权:对于误分类率低的弱分类器,我们在最终结果中给予更高的权重。
权值指的是预测值。
2 提升
2.1 提升
提升——提升是一个机器学习技术,可以用于回归和分类问题,它每一步产生一个弱预测模型(如决策树),并加权累加到总模型中。
梯度提升——如果每一步的弱预测模型生成都是依据损失函数的梯度方向,则称之为梯度提升。
提升的理论意义——如果一个问题存在弱分类器,则可以通过提升的方法得到强分类器。
2.2 梯度提升算法
梯度提升算法首先给定一个目标损失函数(我们自己根据实际问题给定的,与提升无关),它的定义域是所有可行的弱函数集合(基函数)。提升算法通过迭代选择一个负梯度方向上的基函数来逐渐逼近局部极小值。这种在函数域的梯度提升观点对机器学习的很多领域有深刻影响。
2.3 提升算法
给定输入向量x和输出变量y组成的若干训练样本(x1,y1),(x2,y2),……(xn,yn),目标是找到近似函数
 ,使得损失函数L(y,F(x))的损失值最小。
,使得损失函数L(y,F(x))的损失值最小。损失函数L(y,F(x))的典型定义为:
 或
或
假定最优函数为
 ,即:
,即:![F^{*}(\overrightarrow{x})=\underset{F}{arg min}E_{(x,y)}[L(y,F(\overrightarrow{x}))]](https://1000bd.com/contentImg/2022/07/31/104603657.gif)
假定F(x)是一族基函数
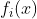 的加权和
的加权和
证明:中位数是绝对最小最优解。
给定样本x1,x2,……,xn,计算


求偏导:
 ,令其等于0。
,令其等于0。得到前k个样本数目与后n-k个样本数目相同,即
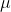 为中位数。
为中位数。提升算法推导:

梯度近似:

提升算法:

3 梯度提升决策树GBDT
3.1 定义


3.2 总结

4 目标函数
4.1 二阶导信息

4.2 目标函数的计算

4.3 目标函数的简化

5 Adaboost
5.1 Adaboost定义
设训练数据集

初始化训练数据的权值分布:
 ,
,5.2 Adaboost算法


 5.3 举例说明
5.3 举例说明m=1:
序号 1 2 3 4 5 6 7 8 9 x X 0 1 2 3 4 5 6 7 8 9 Y 1 1 1 -1 -1 -1 1 1 1 -1
权值分布为D1的训练数据上,阈值v取2.5时误差率最低,故基本分类器为

我们可以看到x=6、7、8时数据存在误差,所以误差率为0.3,即e1=0.3=3*0.1。
代入G1的系数:

∴

分类器
 在训练数据集上有3个误分类点。
在训练数据集上有3个误分类点。
计算权值

可以看到误差的点x=6、7、8的权值变大。为下个基本分类器所用,即m=2时。
m=2:
X 0 1 2 3 4 5 6 7 8 9 Y 1 1 1 -1 -1 -1 1 1 1 -1 w 0.0715 0.0715 0.0715 0.0715 0.0715 0.0715 0.1666 0.1666 0.1666 0.0715 权值分布为D2的训练数据上,阈值v取8.5时误差率最低,故基本分类器为

可以看到x=3、4、5存在误差,所以误差率为0.2143,即e2=0.2143=0.0715*3
代入G1的系数


分类器
 在训练数据集上有3个误分类点。
在训练数据集上有3个误分类点。 计算权值

可以看到x=3、4、5的权值变大。为下个基本分类器所用,即m=3时。
m=3依次类推……
5.4 权值和错误率的关键解释

-
相关阅读:
Recluster Table | RFC 解读
Jensen不等式(琴生不等式)
七月集训(21)
sqlalchemy模块介绍、单表操作、一对多表操作、多对多表操作、flask集成.
异形双柱体阵列纳米粒:球形纳米粒/圆盘形纳米粒子/盘状纳米粒子/棒状纳米粒子
golang roadrunner中文文档(一)基础介绍
python趣味编程-使用 Tkinter 进行 RPS 游戏
Tesla_V100加速卡详细参数
看了 4K 经典中视频,我才知道 30 多年前的艺术家有多牛
ICCV 2023 | 沉浸式体验3D室内设计装修,基于三维布局可控生成最新技术
- 原文地址:https://blog.csdn.net/qwertyuiop0208/article/details/126005370