-
第3周学习:ResNet+ResNeXt
本周工作
一、论文阅读与视频学习
(一)ResNet
1、论文Deep Residual Learning for Image Recognition,CVPR2016及视频ResNet网络讲解
ResNet全名Deep Residual Learning for Image Recognition,网络中有超深的网络结构(突破1000层),提出residual模块,使用Batch Normalization加速训练
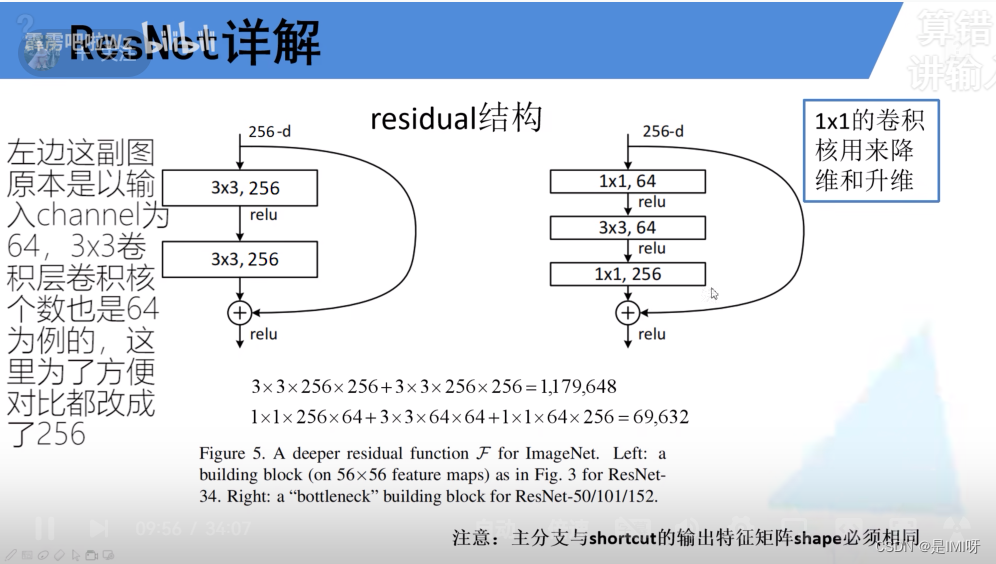
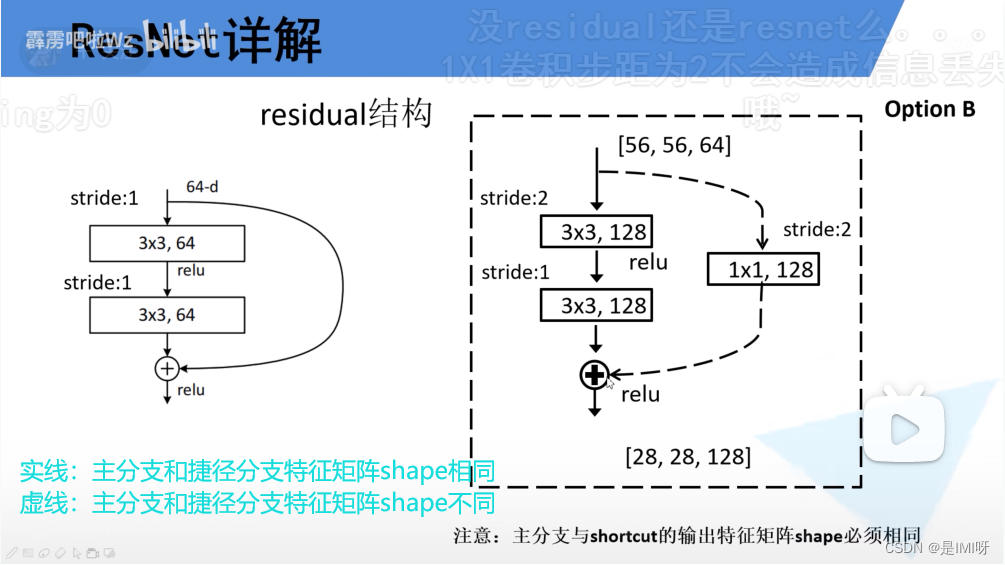
左侧适用于18/34层结构
Batch Normalization详解:
(1)训练时要将traning参数设置为True,验证时把这个参数设置为false。在 pytorch中可以通过创建模型的model.train()和model.eval()方法控制。
(2)batch size尽可能设置大点,设置小后表现可能很糟糕,设置的越大求的均值和方差约接近整个训练集的均值和方差。
(3)建议将bn层放在卷积层和激活层之间,且卷积层不要使用偏置bias。
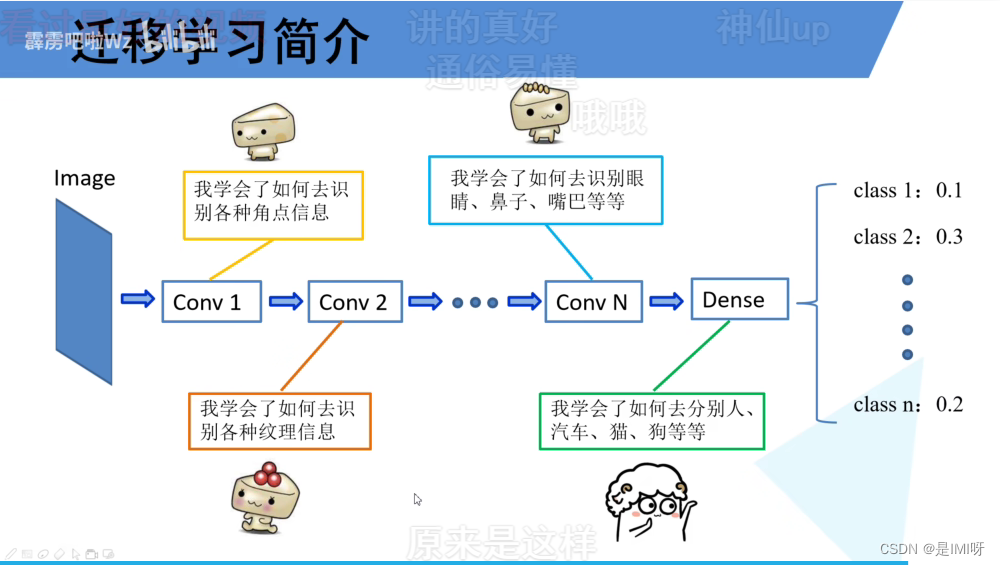
迁移学习(注意别人预处理的方式):
(1)能够快速训练出一个理想的结果
(2)当数据集较小时也能训练出理想的效果
常见的迁移学习方式:
(1)载入权重后训练所有参数
(2)载入权重后只训练最后几层参数
(3)载入权重后在原网络基础上在原网络基础上再添加一层全连接层,仅训练最后一个全连接层
2、视频Pytorch搭建ResNet网络
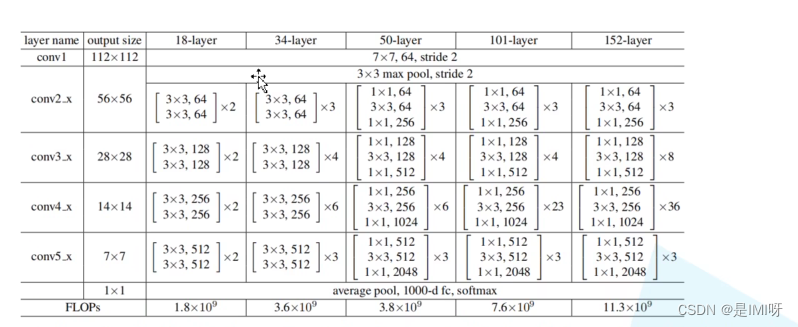
import torch.nn as nn import torch //18层/34层残差结构 自定义网络继承自类module class BasicBlock(nn.Module): expansion = 1//卷积核个数没变化 设为1 //in_channel输入特征矩阵的深度 out_channel输出特征矩阵的深度/主分支上卷积核的个数 stride步距1实线2虚线 downsample下采样参数/代表捷径中1*1的卷积层 def __init__(self, in_channel, out_channel, stride=1, downsample=None, **kwargs): super(BasicBlock, self).__init__() self.conv1 = nn.Conv2d(in_channels=in_channel, out_channels=out_channel, kernel_size=3, stride=stride, padding=1, bias=False) self.bn1 = nn.BatchNorm2d(out_channel) self.relu = nn.ReLU() self.conv2 = nn.Conv2d(in_channels=out_channel, out_channels=out_channel, kernel_size=3, stride=1, padding=1, bias=False) self.bn2 = nn.BatchNorm2d(out_channel) self.downsample = downsample def forward(self, x): //identity捷径分支的输出 identity = x //none->对应实线 if self.downsample is not None: identity = self.downsample(x) out = self.conv1(x) out = self.bn1(out) out = self.relu(out) out = self.conv2(out) out = self.bn2(out) out += identity out = self.relu(out) //残差结构的最终输出 return out //对应50/101/152层残差结构 class Bottleneck(nn.Module): """ 注意:原论文中,在虚线残差结构的主分支上,第一个1x1卷积层的步距是2,第二个3x3卷积层步距是1。 但在pytorch官方实现过程中是第一个1x1卷积层的步距是1,第二个3x3卷积层步距是2, 这么做的好处是能够在top1上提升大概0.5%的准确率。 可参考Resnet v1.5 https://ngc.nvidia.com/catalog/model-scripts/nvidia:resnet_50_v1_5_for_pytorch """ //第三层卷积核个数是第一/二层卷积核个数的4倍 expansion = 4 def __init__(self, in_channel, out_channel, stride=1, downsample=None, groups=1, width_per_group=64): super(Bottleneck, self).__init__() width = int(out_channel * (width_per_group / 64.)) * groups self.conv1 = nn.Conv2d(in_channels=in_channel, out_channels=width, kernel_size=1, stride=1, bias=False) # squeeze channels self.bn1 = nn.BatchNorm2d(width) # ----------------------------------------- self.conv2 = nn.Conv2d(in_channels=width, out_channels=width, groups=groups, kernel_size=3, stride=stride, bias=False, padding=1) self.bn2 = nn.BatchNorm2d(width) # ----------------------------------------- self.conv3 = nn.Conv2d(in_channels=width, out_channels=out_channel*self.expansion, kernel_size=1, stride=1, bias=False) # unsqueeze channels self.bn3 = nn.BatchNorm2d(out_channel*self.expansion) self.relu = nn.ReLU(inplace=True) self.downsample = downsample //正向传播过程 def forward(self, x): identity = x if self.downsample is not None: identity = self.downsample(x) out = self.conv1(x) out = self.bn1(out) out = self.relu(out) out = self.conv2(out) out = self.bn2(out) out = self.relu(out) out = self.conv3(out) out = self.bn3(out) out += identity out = self.relu(out) return out class ResNet(nn.Module): //block->basicblock/bottleneck def __init__(self, block, blocks_num, num_classes=1000, include_top=True, groups=1, width_per_group=64): super(ResNet, self).__init__() self.include_top = include_top self.in_channel = 64 self.groups = groups self.width_per_group = width_per_group self.conv1 = nn.Conv2d(3, self.in_channel, kernel_size=7, stride=2, padding=3, bias=False) self.bn1 = nn.BatchNorm2d(self.in_channel) self.relu = nn.ReLU(inplace=True) self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1) //layer1对应conv2.x一系列结构 self.layer1 = self._make_layer(block, 64, blocks_num[0]) self.layer2 = self._make_layer(block, 128, blocks_num[1], stride=2) self.layer3 = self._make_layer(block, 256, blocks_num[2], stride=2) self.layer4 = self._make_layer(block, 512, blocks_num[3], stride=2) if self.include_top: //自适应平均池化下采样 self.avgpool = nn.AdaptiveAvgPool2d((1, 1)) # output size = (1, 1) self.fc = nn.Linear(512 * block.expansion, num_classes) for m in self.modules(): if isinstance(m, nn.Conv2d): nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu') def _make_layer(self, block, channel, block_num, stride=1): downsample = None if stride != 1 or self.in_channel != channel * block.expansion: downsample = nn.Sequential( nn.Conv2d(self.in_channel, channel * block.expansion, kernel_size=1, stride=stride, bias=False), nn.BatchNorm2d(channel * block.expansion)) layers = [] layers.append(block(self.in_channel, channel, downsample=downsample, stride=stride, groups=self.groups, width_per_group=self.width_per_group)) self.in_channel = channel * block.expansion for _ in range(1, block_num): layers.append(block(self.in_channel, channel, groups=self.groups, width_per_group=self.width_per_group)) //用于搭建神经网络的模块被按照被传入构造器的顺序添加到nn.Sequential()容器中 return nn.Sequential(*layers) def forward(self, x): x = self.conv1(x) x = self.bn1(x) x = self.relu(x) x = self.maxpool(x) x = self.layer1(x) x = self.layer2(x) x = self.layer3(x) x = self.layer4(x) if self.include_top: x = self.avgpool(x) x = torch.flatten(x, 1) x = self.fc(x) return x def resnet34(num_classes=1000, include_top=True): # https://download.pytorch.org/models/resnet34-333f7ec4.pth return ResNet(BasicBlock, [3, 4, 6, 3], num_classes=num_classes, include_top=include_top) def resnet50(num_classes=1000, include_top=True): # https://download.pytorch.org/models/resnet50-19c8e357.pth return ResNet(Bottleneck, [3, 4, 6, 3], num_classes=num_classes, include_top=include_top) def resnet101(num_classes=1000, include_top=True): # https://download.pytorch.org/models/resnet101-5d3b4d8f.pth return ResNet(Bottleneck, [3, 4, 23, 3], num_classes=num_classes, include_top=include_top) def resnext50_32x4d(num_classes=1000, include_top=True): # https://download.pytorch.org/models/resnext50_32x4d-7cdf4587.pth groups = 32 width_per_group = 4 return ResNet(Bottleneck, [3, 4, 6, 3], num_classes=num_classes, include_top=include_top, groups=groups, width_per_group=width_per_group) def resnext101_32x8d(num_classes=1000, include_top=True): # https://download.pytorch.org/models/resnext101_32x8d-8ba56ff5.pth groups = 32 width_per_group = 8 return ResNet(Bottleneck, [3, 4, 23, 3], num_classes=num_classes, include_top=include_top, groups=groups, width_per_group=width_per_group)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
(二)ResNeXt
1、论文Aggregated Residual Transformations for Deep Neural Networks, CVPR 2017及视频ResNeXt网络讲解
ResNetXt更新了block

组卷积
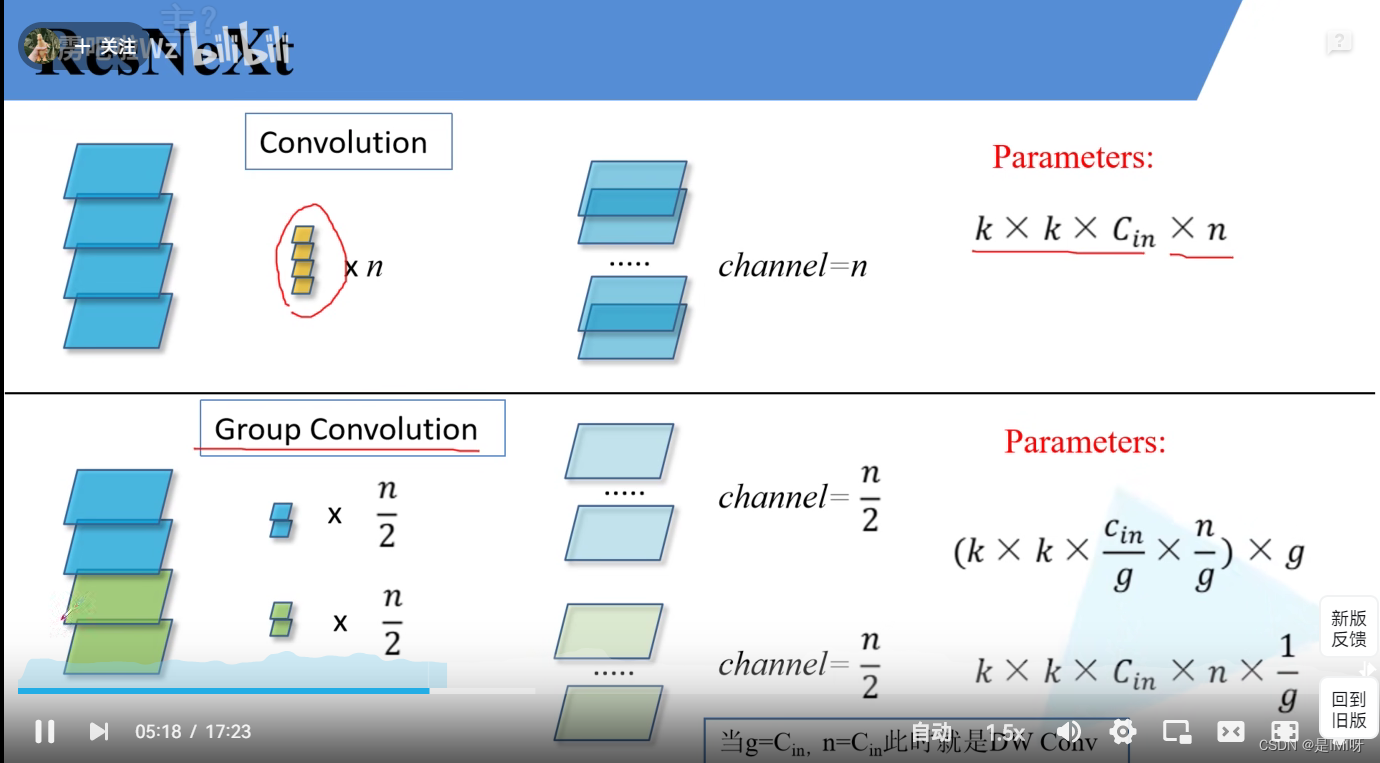
2、视频Pytorch搭建ResNeXt网络
提出ResNeXt的主要原因在于,传统提高模型的准确率方式都是加深或加宽网络,但是随着超参数数量的增加,网络设计的难度和计算开销也会增加。因此 ResNeXt 结构可以在不增加参数复杂度的前提下提高准确率,同时得益于子模块的拓扑结构,可以减少超参数的数量。
二、代码作业
AI研习社“猫狗大战”
LeNet框架:
在学习了LeNet网络进行猫狗大战博客的基础上,尝试搭建LeNet网络进行分类。Step 1:下载数据集
# 这个是训练集,猫狗各取了2000个 ! wget https://gaopursuit.oss-cn-beijing.aliyuncs.com/2021/files/train.zip ! unzip train.zip # 这个是测试集 ! wget https://gaopursuit.oss-cn-beijing.aliyuncs.com/202007/dogs_cats_test.zip ! unzip dogs_cats_test.zip import numpy as np import matplotlib.pyplot as plt import torch import torch.nn as nn import torchvision from torchvision import models,transforms,datasets import torch.nn.functional as F from PIL import Image import torch.optim as optim import json, random import os # 判断是否存在GPU设备 device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") print('Using gpu: %s ' % torch.cuda.is_available()) # 训练图片和测试图片的路径 train_path = './train/' test_path = './test/'- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
Step 2:处理数据集
def get_data(file_path): file_lst = os.listdir(file_path) #获得所有文件名称 xxxx.jpg data_lst = [] for i in range(len(file_lst)): clas = file_lst[i][:3] #cat和dog在文件名的开头 img_path = os.path.join(file_path,file_lst[i])#将文件名与路径合并得到完整路径,以备读取 if clas == 'cat': data_lst.append((img_path, 0)) else: data_lst.append((img_path, 1)) return data_lst class catdog_set(torch.utils.data.Dataset): def __init__(self, path, transform): super(catdog_set).__init__() self.data_lst = get_data(path)#调用刚才的函数获得数据列表 self.trans = torchvision.transforms.Compose(transform) def __len__(self): return len(self.data_lst) def __getitem__(self,index): (img,cls) = self.data_lst[index] image = self.trans(Image.open(img)) label = torch.tensor(cls,dtype=torch.float32) return image,label # 将输入图像缩放为 128*128,每一个 batch 中图像数量为128 # 训练时,每一个 epoch 随机打乱图像的顺序,以实现样本多样化 train_loader = torch.utils.data.DataLoader( catdog_set(train_path, [transforms.Resize((128,128)),transforms.ToTensor()]), batch_size=128, shuffle=True)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
Step 3:搭建LeNet网络
3*128*128->conv1(16*124*124)->maxpool(16*62*62)->conv2d(32*58*58)->maxpool(32*29*29)
LeNet学习博客class LeNet(nn.Module): def __init__(self): super(LeNet, self).__init__() self.conv1 = nn.Conv2d(3, 16, 5) # C1 self.pool1 = nn.MaxPool2d(2, 2) # S2 self.conv2 = nn.Conv2d(16, 32, 5) # C3 self.pool2 = nn.MaxPool2d(2, 2) # S4 self.fc1 = nn.Linear(32*29*29, 120) # C5(用全连接代替) self.fc2 = nn.Linear(120, 84) # F6 self.fc3 = nn.Linear(84, 2) # F7 结果分2类 def forward(self, x): x = F.relu(self.conv1(x)) # input(3, 32, 32) output(16, 28, 28) x = self.pool1(x) # output(16, 14, 14) x = F.relu(self.conv2(x)) # output(32, 10, 10) x = self.pool2(x) # output(32, 5, 5) x = x.view(-1, 32*29*29) # output(32*5*5) 展平 x = F.relu(self.fc1(x)) # output(120) x = F.relu(self.fc2(x)) # output(84) x = self.fc3(x) # output(10) return x- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
# 网络放到GPU上 net = LeNet().to(device) criterion = nn.CrossEntropyLoss() optimizer = optim.Adam(net.parameters(), lr=0.001)- 1
- 2
- 3
- 4
Step 4:重复多次训练
for epoch in range(30): # 重复多轮训练 for i, (inputs, labels) in enumerate(train_loader): inputs = inputs.to(device) labels = labels.to(device) # 优化器梯度归零 optimizer.zero_grad() # 正向传播 + 反向传播 + 优化 outputs = net(inputs) loss = criterion(outputs, labels.long()) loss.backward() optimizer.step() print('Epoch: %d loss: %.6f' %(epoch + 1, loss.item())) print('Finished Training')- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
Epoch: 1 loss: 0.704636
Epoch: 2 loss: 0.654936
Epoch: 3 loss: 0.577431
Epoch: 4 loss: 0.540570
Epoch: 5 loss: 0.487358
Epoch: 6 loss: 0.352520
Epoch: 7 loss: 0.345092
Epoch: 8 loss: 0.325232
Epoch: 9 loss: 0.067634
Epoch: 10 loss: 0.031828
Epoch: 11 loss: 0.036147
Epoch: 12 loss: 0.012576
Epoch: 13 loss: 0.010833
Epoch: 14 loss: 0.004121
Epoch: 15 loss: 0.001717
Epoch: 16 loss: 0.001304
Epoch: 17 loss: 0.000462
Epoch: 18 loss: 0.000133
Epoch: 19 loss: 0.000179
Epoch: 20 loss: 0.000141
Epoch: 21 loss: 0.000439
Epoch: 22 loss: 0.000666
Epoch: 23 loss: 0.000298
Epoch: 24 loss: 0.000086
Epoch: 25 loss: 0.000156
Epoch: 26 loss: 0.000069
Epoch: 27 loss: 0.000371
Epoch: 28 loss: 0.000186
Epoch: 29 loss: 0.000025
Epoch: 30 loss: 0.000098
Finished TrainingStep 5:输出分类结果

resfile = open('res0.csv', 'w') for i in range(0,2000): img_PIL = Image.open('./test/'+str(i)+'.jpg') img_tensor = transforms.Compose([transforms.Resize((128,128)),transforms.ToTensor()])(img_PIL) img_tensor = img_tensor.reshape(-1, img_tensor.shape[0], img_tensor.shape[1], img_tensor.shape[2]) img_tensor = img_tensor.to(device) out = net(img_tensor).cpu().detach().numpy() if out[0, 0] < out[0, 1]: resfile.write(str(i)+','+str(1)+'\n') else: resfile.write(str(i)+','+str(0)+'\n') resfile.close()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
ResNet18:
Change 1:将图片resize为[224,224]
Change 2:网络结构替换为ResNet18class Resblk(nn.Module): def __init__(self,ch_in,ch_out,stride1,stride2) -> None: super(Resblk,self).__init__() self.blk = nn.Sequential( nn.Conv2d(ch_in,ch_out,kernel_size=3,stride=stride1,padding=1), nn.BatchNorm2d(ch_out), nn.ReLU(), nn.Conv2d(ch_out,ch_out,kernel_size=3,stride=stride2,padding=1), nn.BatchNorm2d(ch_out) ) self.extra = nn.Sequential() #输入输出通道数不同的话 if ch_in != ch_out: self.extra = nn.Sequential( nn.Conv2d(ch_in,ch_out,kernel_size=1,stride=2,padding=0), nn.BatchNorm2d(ch_out) ) def forward(self,x): out = F.relu(self.blk(x)+self.extra(x)) return out class ResNet18(nn.Module): def __init__(self) -> None: super(ResNet18,self).__init__() self.preconv = nn.Sequential( nn.Conv2d(3,64,kernel_size=7,stride=2,padding=3), nn.MaxPool2d(kernel_size=3,stride=2,padding=1) ) self.conv1 = nn.Sequential( nn.Conv2d(64,128,kernel_size=1,stride=2,padding=0), ) self.conv2 = nn.Sequential( nn.Conv2d(128,256,kernel_size=1,stride=2,padding=0), ) self.conv3 = nn.Sequential( nn.Conv2d(256,512,kernel_size=1,stride=2,padding=0), ) #由于残差块中 是通过控制stride来降维度的, #因此我在设置Resblk时将stride作为参数输入, #参数意义: 输入通道,输出通道,残差块中第一层卷积步长,残差块中第二层卷积的步长 self.blk1 = Resblk(64,64,1,1) self.blk2 = Resblk(64,64,1,1) self.blk3 = Resblk(64,128,2,1) self.blk4 = Resblk(128,128,1,1) self.blk5 = Resblk(128,256,2,1) self.blk6 = Resblk(256,256,1,1) self.blk7 = Resblk(256,512,2,1) self.blk8 = Resblk(512,512,1,1) #池化操作 self.avgpool = nn.AdaptiveAvgPool2d(output_size=(1, 1)) #全连接层 self.fc = nn.Linear(512,2) #2类 def forward(self,x): #输入 224*224*3 输出 64*56*56 #7*7 conv + maxpool x = self.preconv(x) #第一个残差块 #输入 224*224*3 输出 64*56*56 x = self.blk1(x) #第二个残差块 #输入 64*56*56 输出 64*56*56 x = self.blk2(x) #第三个残差块 + 1*1 subsample #输入 64*56*56 输出 128*28*28 x = self.conv1(x) + self.blk3(x) #第四个残差块 #输入 128*28*28 输出 128*28*28 x = self.blk4(x) #第五个残差块 + 1*1 subsample #输入 128*28*28 输出 256*14*14 x = self.conv2(x) + self.blk5(x) #第六个残差块 #输入 256*14*14 输出 256*14*14 x = self.blk6(x) #第七个残差块 #输入 256*14*14 输出 512*7*7 x = self.conv3(x) + self.blk7(x) #第八个残差块 #输入 512*7*7 输出 512*7*7 x = self.blk8(x) #平均池化 512*7*7-> 512*1*1 x = self.avgpool(x) #Flatten 打平操作 后面俩维合并成一维 x = x.view(x.size(0),-1) #[512,1] #全连接层 512,1 -> 1,1000 x = self.fc(x) return x- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93

三、思考题
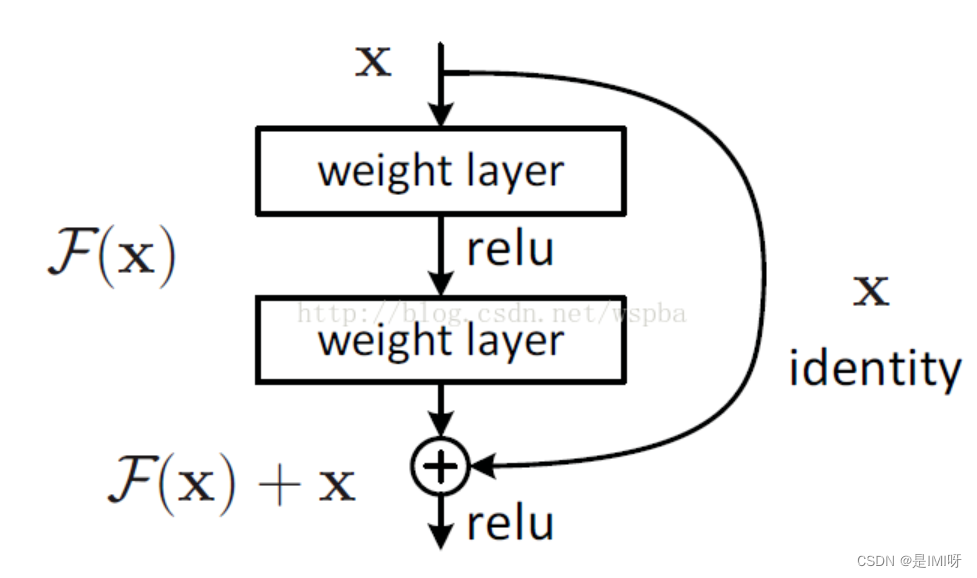
1、Residual learning
神经网络叠的越深,学习出的效果不一定越好。因为当模型层数增加到某种程度,模型的效果将会不升反降,即发生了退化情况。退化原因可能是梯度爆炸或梯度消失现象,具体来说,反向传播结果的数值大小不止取决于求导的式子,很大程度上也取决于输入的模值。当计算图每次输入的模值都大于1,那么经过很多层回传,梯度将不可避免地呈几何倍数增长直到Nan,这就是梯度爆炸现象。如果我们每个阶段输入的模恒小于1,那么梯度也将不可避免地呈几何倍数下降直到0,这就是梯度消失现象。值得一提的是,由于人为的参数设置,梯度更倾向于消失而不是爆炸。
如果深层网络后面的层都是是恒等映射,那么模型就可以转化为一个浅层网络。那现在的问题就是如何得到恒等映射了。事实上,已有的神经网络很难拟合潜在的恒等映射函数H(x) = x。但如果把网络设计为H(x) = F(x) + x,即直接把恒等映射作为网络的一部分。就可以把问题转化为学习一个残差函数F(x) = H(x) - x.只要F(x)=0,就构成了一个恒等映射H(x) = x。 而且,拟合残差至少比拟合恒等映射容易得多。
2、Batch Normailization 的原理
Batch normalization 的 batch 是批数据, 把数据分成小批小批进行 stochastic gradient descent. 而且在每批数据进行前向传递 forward propagation 的时候, 对每一层都进行 normalization 的处理。
归一化的好处是:
(1)神经网络学习过程本质就是为了学习数据分布,一旦训练数据与预测数据分布不同,那么网络的泛化能力也大大降低。
(2)若训练过程中每批batch的数据分布也各不相同,那么网络每次迭代学习过程就会出现较大波动,使之更难趋于收敛,降低训练收敛速度。对于深层网络,网络前几层的微小变化都会被网络累积放大,则训练数据分布变化问题就会被放大,更加影响训练速度。一旦每批训练数据的分布各不相同(batch梯度下降),那么网络就要在每次迭代都去学习适应不同的分布,这样会大大降低网络的训练速度。3、为什么分组卷积可以提升准确率?即然分组卷积可以提升准确率,同时还能降低计算量,分数数量尽量多不行吗?
(1)高效训练。因为卷积被分成了多个路径,每个路径都可由不同的 GPU 分开处理,所以模型可以并行方式在多个 GPU 上进行训练。相比于在单个 GPU 上完成所有任务,这样的在多个 GPU 上的模型并行化能让网络在每个步骤处理更多图像。
(2)模型会更高效。模型参数会随过滤器分组数的增大而减少,完整的标准 2D 卷积有 h x w x Din x Dout 个参数。具有 2 个过滤器分组的分组卷积有 (h x w x Din/2 x Dout/2) x 2 个参数,参数数量减少了一半。分组数k越多,卷积操作的总参数量和总计算量就越少(减少k倍)。然而分组卷积有一个致命的缺点就是不同分组的通道间减少了信息流通,即输出的feature maps只考虑了输入特征的部分信息。解决方法是在分组卷积之后进行信息融合操作。
-
相关阅读:
信号驱动io
uniapp 开发App 网络异常如何处理
动静态库(生成和使用)
zynq平台蓝牙协议栈移植
ShiroFilter
跨设备操作
git 远程名称 远程分支 介绍
OpenCV的绘图函数,实力绘画篮球场
mysql14
数据转换工具DBT介绍及实操
- 原文地址:https://blog.csdn.net/weixin_45351699/article/details/125977566
