-
YOLOX改进之一:添加CBAM、SE、ECA注意力机制
前 言:之前发布系列已经有对2020年发布的YOLOv5进行改进,不少朋友咨询YOLOX改进方法,本系列就重点对YOLOX如何改进进行详细介绍,基本跟YOLOv5一致,有细微差异。此后的系列文章,将重点对YOLOX的如何改进进行详细的介绍,目的是为了给那些搞科研的同学需要创新点或者搞工程项目的朋友需要达到更好的效果提供自己的微薄帮助和参考。
需要更多程序资料以及答疑欢迎大家关注——微信公众号:人工智能AI算法工程师
解决问题:本文以加入CBAM双通道注意力机制为例,可以让网络更加关注待检测目标,提高检测效果,解决复杂环境背景下容易错漏检的情况。
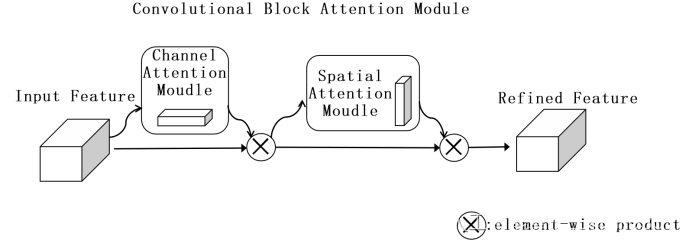
添加方法:
第一步:确定添加的位置,作为即插即用的注意力模块,可以添加到YOLOX网络中的任何地方。本文以添加进卷积Conv模块中为例。
第二步:darknet.py构建CBAM模块。
- class SE(nn.Module):
- def __init__(self, channel, ratio=16):
- super(SE, self).__init__()
- self.avg_pool = nn.AdaptiveAvgPool2d(1)
- self.fc = nn.Sequential(
- nn.Linear(channel, channel // ratio, bias=False),
- nn.ReLU(inplace=True),
- nn.Linear(channel // ratio, channel, bias=False),
- nn.Sigmoid()
- )
- def forward(self, x):
- b, c, _, _ = x.size()
- y = self.avg_pool(x).view(b, c)
- y = self.fc(y).view(b, c, 1, 1)
- return x * y
- class ECA(nn.Module):
- def __init__(self, channel, b=1, gamma=2):
- super(ECA, self).__init__()
- kernel_size = int(abs((math.log(channel, 2) + b) / gamma))
- kernel_size = kernel_size if kernel_size % 2 else kernel_size + 1
- self.avg_pool = nn.AdaptiveAvgPool2d(1)
- self.conv = nn.Conv1d(1, 1, kernel_size=kernel_size, padding=(kernel_size - 1) // 2, bias=False)
- self.sigmoid = nn.Sigmoid()
- def forward(self, x):
- y = self.avg_pool(x)
- y = self.conv(y.squeeze(-1).transpose(-1, -2)).transpose(-1, -2).unsqueeze(-1)
- y = self.sigmoid(y)
- return x * y.expand_as(x)
- class ChannelAttention(nn.Module):
- def __init__(self, in_planes, ratio=8):
- super(ChannelAttention, self).__init__()
- self.avg_pool = nn.AdaptiveAvgPool2d(1)
- self.max_pool = nn.AdaptiveMaxPool2d(1)
- # 利用1x1卷积代替全连接
- self.fc1 = nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False)
- self.relu1 = nn.ReLU()
- self.fc2 = nn.Conv2d(in_planes // ratio, in_planes, 1, bias=False)
- self.sigmoid = nn.Sigmoid()
- def forward(self, x):
- avg_out = self.fc2(self.relu1(self.fc1(self.avg_pool(x))))
- max_out = self.fc2(self.relu1(self.fc1(self.max_pool(x))))
- out = avg_out + max_out
- return self.sigmoid(out)
- class SpatialAttention(nn.Module):
- def __init__(self, kernel_size=7):
- super(SpatialAttention, self).__init__()
- assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
- padding = 3 if kernel_size == 7 else 1
- self.conv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
- self.sigmoid = nn.Sigmoid()
- def forward(self, x):
- avg_out = torch.mean(x, dim=1, keepdim=True)
- max_out, _ = torch.max(x, dim=1, keepdim=True)
- x = torch.cat([avg_out, max_out], dim=1)
- x = self.conv1(x)
- return self.sigmoid(x)
- # CBAM注意力机制
- class CBAM(nn.Module):
- def __init__(self, channel, ratio=8, kernel_size=7):
- super(CBAM, self).__init__()
- self.channelattention = ChannelAttention(channel, ratio=ratio)
- self.spatialattention = SpatialAttention(kernel_size=kernel_size)
- def forward(self, x):
- x = x*self.channelattention(x)
- x = x*self.spatialattention(x)
- return x
第三步:yolo_pafpn.py中注册我们进行修改的CBAM模块
- self.cbam_1 = CBAM(int(in_channels[2] * width)) # 对应dark5输出的1024维度通道
- self.cbam_2 = CBAM(int(in_channels[1] * width)) # 对应dark4输出的512维度通道
- self.cbam_3 = CBAM(int(in_channels[0] * width)) # 对应dark3输出的256维度通道
- def forward(self, input):
- """
- Args:
- inputs: input images.
- Returns:
- Tuple[Tensor]: FPN feature.
- """
- # backbone
- out_features = self.backbone(input)
- features = [out_features[f] for f in self.in_features]
- [x2, x1, x0] = features
- # 3、直接对输入的特征图使用注意力机制
- x0 = self.cbam_1(x0)
- x1 = self.cbam_2(x1)
- x2 = self.cbam_3(x2)
结 果:本人在多个数据集上做了大量实验,针对不同的数据集效果不同,同一个数据集的不同添加位置方法也是有差异,需要大家进行实验。有效果有提升的情况占大多数。
需要更多程序资料以及答疑欢迎大家关注——微信公众号:人工智能AI算法工程师
PS:CBAM等多种注意力机制,不仅仅是可以添加进YOLOX,也可以添加进任何其他的深度学习网络,不管是分类还是检测还是分割,主要是计算机视觉领域,都可能会有不同程度的提升效果。
最后,希望能互粉一下,做个朋友,一起学习交流。
-
相关阅读:
结构体和联合体
jvm参数配置
elasticsearch快速应用于SpringBoot
【暑期每日一题】洛谷 P7798 [COCI2015-2016#6] PUTOVANJE
爬虫实例——从mindat上爬取矿石图片
Matlab论文插图绘制模板第117期—气泡云图
PAM从入门到精通(五)
百趣生物受邀参加代谢组学及脂质组学质谱技术研讨会
TensorFlow实战教程(二十八)-Keras实现BiLSTM微博情感分类和LDA主题挖掘分析
VMware 与 SmartX 超融合 I/O 路径对比与性能影响解析
- 原文地址:https://blog.csdn.net/m0_70388905/article/details/126002838
