-
信息论 (Information Theory): Introduction and information measures
Information Theory, 1948
- Shannon, Claude Elwood. “A mathematical theory of communication.” ACM SIGMOBILE mobile computing and communications review 5.1 (2001): 3-55.
Entropy (熵)
Information
- 考虑一个离散随机变量
X
X
X,当观测到它的一个具体值
x
x
x 时,我们能得到多少信息呢?信息量可以被理解为 “degree of surprise”,也就是说,一个不太可能发生的事件带来的信息量比经常发生的事件带来的信息量更多,一个必然会发生的事件则不会带来任何信息,因此,(1) 信息量
h
(
x
)
h(x)
h(x) 是
p
(
x
)
p(x)
p(x) 的减函数。同时,如果事件
x
,
y
x,y
x,y 相互独立 (
p
(
x
,
y
)
=
p
(
x
)
p
(
y
)
p(x,y)=p(x)p(y)
p(x,y)=p(x)p(y)),则同时观察到
x
,
y
x,y
x,y 带来的信息量为分别观察到
x
,
y
x,y
x,y 带来的信息量之和相同,也就是 (2)
h
(
x
,
y
)
=
h
(
x
)
+
h
(
y
)
h(x,y)=h(x)+h(y)
h(x,y)=h(x)+h(y). 由此可得信息量
h
(
x
)
h(x)
h(x) 的形式如下:
 其中,
h
(
x
)
≥
0
h(x)\geq0
h(x)≥0,对数函数的底数是任意的,当底数为 2 时,信息量的单位为 bits,当底数为
e
e
e 时,信息量的单位为 nats
其中,
h
(
x
)
≥
0
h(x)\geq0
h(x)≥0,对数函数的底数是任意的,当底数为 2 时,信息量的单位为 bits,当底数为
e
e
e 时,信息量的单位为 nats
Entropy
- 假设发射者向接收者传输离散随机变量的值,则传输过程中的平均信息量为
h
(
x
)
h(x)
h(x) 取期望的形式:
 其中,
H
[
x
]
H[x]
H[x] 即为随机变量
x
x
x 的熵。由于
lim
p
→
0
p
log
2
p
=
0
\lim_{p\rightarrow0}p\log_2 p=0
limp→0plog2p=0,因此当
p
(
x
)
=
0
p(x)=0
p(x)=0 时取
p
(
x
)
log
2
p
(
x
)
=
0
p(x)\log_2 p(x)=0
p(x)log2p(x)=0,不可能发生的事件不会带来任何信息量 (熵是关于
X
X
X 概率分布的凹函数,因此
H
[
x
]
H[x]
H[x] 也可以被记作
H
[
p
]
H[p]
H[p])
其中,
H
[
x
]
H[x]
H[x] 即为随机变量
x
x
x 的熵。由于
lim
p
→
0
p
log
2
p
=
0
\lim_{p\rightarrow0}p\log_2 p=0
limp→0plog2p=0,因此当
p
(
x
)
=
0
p(x)=0
p(x)=0 时取
p
(
x
)
log
2
p
(
x
)
=
0
p(x)\log_2 p(x)=0
p(x)log2p(x)=0,不可能发生的事件不会带来任何信息量 (熵是关于
X
X
X 概率分布的凹函数,因此
H
[
x
]
H[x]
H[x] 也可以被记作
H
[
p
]
H[p]
H[p]) - 一个随机变量的熵越大,意味着不确定性越大,那么也就是说,该随机变量包含的信息量越大,也表示平均意义上对随机变量的编码长度
Entropy in bits
- (1) 考虑一个离散随机变量 x ∈ X x\in\mathcal X x∈X 服从均匀分布,则传输 x x x 的值时,需要的编码长度为 log 2 ∣ X ∣ \log_2 |\mathcal X| log2∣X∣,也就是底数为 2 时 X X X 的熵
- (2) 再考虑如下例子。假设一个离散随机变量有 8 种状态
{
a
,
b
,
c
,
d
,
e
,
f
,
g
,
h
}
\{a, b, c, d, e, f, g, h\}
{a,b,c,d,e,f,g,h},它们的概率分别为
(
1
/
2
,
1
/
4
,
1
/
8
,
1
/
16
,
1
/
64
,
1
/
64
,
1
/
64
,
1
/
64
)
( 1/2 , 1/4 , 1/8 , 1/16 , 1/64 , 1/64 , 1/64 , 1/64 )
(1/2,1/4,1/8,1/16,1/64,1/64,1/64,1/64),如果要高效地对其进行传输,可以利用哈夫曼编码得到每种状态的最优编码
0
0
0,
10
10
10,
110
110
110,
1110
1110
1110,
111100
111100
111100,
111101
111101
111101,
111110
111110
111110,
111111
111111
111111,最优编码的平均编码长度为
 正好等于随机变量的熵:
正好等于随机变量的熵:

- (3) noiseless coding theorem (Shannon, 1948) 指出,熵是传输随机变量需要的平均比特数的下界
Entropy in physics
熵的概念最早其实可以追溯到物理学中。在物理学中,熵就表示混乱程度。假设有 N N N 个相同物体被放在若干 bins 中,其中 i i i-th bin 中放 n i n_i ni 个物体,则分配方案的数量为
 熵被定义为
W
W
W 的对数形式再加上一个缩放因子的形式
熵被定义为
W
W
W 的对数形式再加上一个缩放因子的形式
 当
N
→
∞
N\rightarrow\infty
N→∞ 且
n
i
/
N
n_i/N
ni/N 固定时,使用 Stirling’s approximation 可以得到
当
N
→
∞
N\rightarrow\infty
N→∞ 且
n
i
/
N
n_i/N
ni/N 固定时,使用 Stirling’s approximation 可以得到
 将其代入
H
H
H 的表达式可得
将其代入
H
H
H 的表达式可得
H = 1 N ( N ln N − N − ∑ i ( n i ln n i − n i ) ) = 1 N ( N ln N − ∑ i n i ln n i ) = ∑ i ( n i N ) ln N − ∑ i ( n i N ) ln n iH=N1(NlnN−N−i∑(nilnni−ni))=N1(NlnN−i∑nilnni)=i∑(Nni)lnN−i∑(Nni)lnni因此,H = 1 N ( N ln N − N − ∑ i ( n i ln n i − n i ) ) = 1 N ( N ln N − ∑ i n i ln n i ) = ∑ i ( n i N ) ln N − ∑ i ( n i N ) ln n i

Properties
- (1) 概率分布越尖锐,熵越小;概率分布越平坦,熵越大。当
X
X
X 服从均匀分布时熵最大,
H
[
X
]
=
ln
∣
X
∣
H[X]=\ln|\mathcal X|
H[X]=ln∣X∣,其中
X
\mathcal X
X 为采样空间;当
X
X
X 只能取 1 个值时 (
p
i
=
1
,
p
j
≠
i
=
0
p_i=1,p_{j\neq i}=0
pi=1,pj=i=0) 熵最小,
H
[
X
]
=
0
H[X]=0
H[X]=0
0 ≤ H ( X ) ≤ ln ∣ X ∣ 0\leq H(X)\leq\ln|\mathcal X| 0≤H(X)≤ln∣X∣证明:下面求熵的最大值。求熵的最大值可以转化为求熵的负数的最小值,这就转化为了一个凸优化问题:
min ∑ i p ( x i ) ln p ( x i ) s . t . ∑ i p ( x i ) = 1 , 0 ≤ p ( x i ) ≤ 1 \min\sum_ip(x_i)\ln p(x_i)\\ s.t.\sum_ip(x_i)=1,0\leq p(x_i)\leq1 mini∑p(xi)lnp(xi)s.t.i∑p(xi)=1,0≤p(xi)≤1暂时忽略第 2 个约束条件,可以写出拉格朗日函数:
L ( p ( x i ) , λ ) = ∑ i p ( x i ) ln p ( x i ) + λ ( ∑ i p ( x i ) − 1 ) L(p(x_i),\lambda)=\sum_ip(x_i)\ln p(x_i)+\lambda(\sum_ip(x_i)-1) L(p(xi),λ)=i∑p(xi)lnp(xi)+λ(i∑p(xi)−1)令其偏导为 0:
∂ L ∂ p ( x i ) = 1 + ln p ( x i ) + λ = 0 ∂ L ∂ λ = ∑ i p ( x i ) − 1 = 0 \frac{\partial L}{\partial p(x_i)}=1+\ln p(x_i)+\lambda=0\\ \frac{\partial L}{\partial\lambda}=\sum_ip(x_i)-1=0 ∂p(xi)∂L=1+lnp(xi)+λ=0∂λ∂L=i∑p(xi)−1=0因此有
p ( x 1 ) = p ( x 2 ) = . . . = p ( x ∣ X ∣ ) = 1 ∣ X ∣ H [ X ] = ln ∣ X ∣ p(x_1)=p(x_2)=...=p(x_{|\mathcal X|})=\frac{1}{|\mathcal X|}\\ H[X]=\ln|\mathcal X| p(x1)=p(x2)=...=p(x∣X∣)=∣X∣1H[X]=ln∣X∣该解满足第 2 个约束条件 0 ≤ p ( x i ) ≤ 1 0\leq p(x_i)\leq1 0≤p(xi)≤1,是一个可行解

Differential entropy (微分熵)
- 熵的定义可以被推广到连续随机变量的情况。考虑将
X
\mathcal X
X 分为若干个宽为
Δ
\Delta
Δ 的 bins,对于
i
i
i-th bin,存在
x
i
x_i
xi 使得
 因此我们可以把
i
i
i-th bin 内的值都替换为
x
i
x_i
xi 从而将连续概率分布量化为离散概率分布,它的熵为
因此我们可以把
i
i
i-th bin 内的值都替换为
x
i
x_i
xi 从而将连续概率分布量化为离散概率分布,它的熵为
 其中,第 2 项
−
ln
Δ
-\ln\Delta
−lnΔ 在
Δ
→
0
\Delta\rightarrow0
Δ→0 时发散,这说明精准表示一个连续变量需要大量 bits
其中,第 2 项
−
ln
Δ
-\ln\Delta
−lnΔ 在
Δ
→
0
\Delta\rightarrow0
Δ→0 时发散,这说明精准表示一个连续变量需要大量 bits - 我们先忽略第 2 项
−
ln
Δ
-\ln\Delta
−lnΔ 并且考虑
Δ
→
0
\Delta\rightarrow0
Δ→0 的情况,此时有
 其中,等式右侧的项即为微分熵. 对于多元连续随机变量
x
\boldsymbol x
x (a vector),微分熵为
其中,等式右侧的项即为微分熵. 对于多元连续随机变量
x
\boldsymbol x
x (a vector),微分熵为

Maximum entropy configuration for a continuous variable - Gaussian Distribution
- 下面求微分熵的最大值。该问题是一个条件优化问题,
p
(
x
)
p(x)
p(x) 满足如下约束:
 可以用拉格朗日乘子法转化为无条件约束的优化问题:
可以用拉格朗日乘子法转化为无条件约束的优化问题:
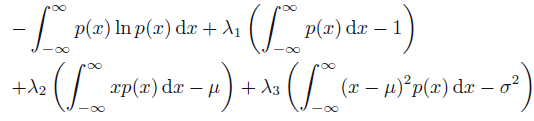
- 上式是一个有关概率分布
p
(
x
)
p(x)
p(x) 的泛函,将其整理一下可得
F [ p ( x ) ] = ∫ − ∞ ∞ [ − p ( x ) ln p ( x ) + λ 1 p ( x ) + λ 2 x p ( x ) + λ 3 ( x − μ ) 2 p ( x ) ] d x + ( − λ 1 − λ 2 μ − λ 3 σ 2 ) = ∫ − ∞ ∞ G ( p ( x ) , x ) d x + CF[p(x)]=∫−∞∞[−p(x)lnp(x)+λ1p(x)+λ2xp(x)+λ3(x−μ)2p(x)]dx+(−λ1−λ2μ−λ3σ2)=∫−∞∞G(p(x),x)dx+C由欧拉-拉格朗日方程可知,当 p ( x ) p(x) p(x) 使得 F [ p ( x ) ] F[p(x)] F[p(x)] 取极值时,对任意 x x x 有F [ p ( x ) ] = ∫ − ∞ ∞ [ − p ( x ) ln p ( x ) + λ 1 p ( x ) + λ 2 x p ( x ) + λ 3 ( x − μ ) 2 p ( x ) ] d x + ( − λ 1 − λ 2 μ − λ 3 σ 2 ) = ∫ − ∞ ∞ G ( p ( x ) , x ) d x + C
δ F δ p ( x ) = ∂ G ∂ p − d d x ( ∂ G ∂ p ′ ) = ∂ G ∂ p = − 1 − ln p ( x ) + λ 1 + λ 2 x + λ 3 ( x − μ ) 2 = 0δp(x)δF=∂p∂G−dxd(∂p′∂G)=∂p∂G=−1−lnp(x)+λ1+λ2x+λ3(x−μ)2=0因此,δ F δ p ( x ) = ∂ G ∂ p − d d x ( ∂ G ∂ p ′ ) = ∂ G ∂ p = − 1 − ln p ( x ) + λ 1 + λ 2 x + λ 3 ( x − μ ) 2 = 0
 将其带入 3 个约束式就可以得到拉格朗日乘子
λ
1
,
λ
2
,
λ
3
\lambda_1,\lambda_2,\lambda_3
λ1,λ2,λ3 的值 (过程比较复杂,可以参考 Exercise 1.34),最终可以得到
将其带入 3 个约束式就可以得到拉格朗日乘子
λ
1
,
λ
2
,
λ
3
\lambda_1,\lambda_2,\lambda_3
λ1,λ2,λ3 的值 (过程比较复杂,可以参考 Exercise 1.34),最终可以得到
 也就是说,正态分布可以使得微分熵最大 (在上述优化过程中,我们并没有约束
p
(
x
)
≥
0
p(x)\geq0
p(x)≥0,但由于求出来的
p
(
x
)
p(x)
p(x) 满足该约束,因此非负的约束项可以不加),将
p
(
x
)
p(x)
p(x) 代入微分熵的表达式可得
也就是说,正态分布可以使得微分熵最大 (在上述优化过程中,我们并没有约束
p
(
x
)
≥
0
p(x)\geq0
p(x)≥0,但由于求出来的
p
(
x
)
p(x)
p(x) 满足该约束,因此非负的约束项可以不加),将
p
(
x
)
p(x)
p(x) 代入微分熵的表达式可得
H [ x ] = − ∫ p ( x ) ln p ( x ) d x = − ∫ p ( x ) ln { 1 2 π σ 2 } d x − ∫ p ( x ) { − ( x − μ ) 2 2 σ 2 } d x = − ln { 1 2 π σ 2 } + σ 2 2 σ 2 = 1 2 { 1 + ln ( 2 π σ 2 ) }H[x]=−∫p(x)lnp(x)dx=−∫p(x)ln{2πσ21}dx−∫p(x){−2σ2(x−μ)2}dx=−ln{2πσ21}+2σ2σ2=21{1+ln(2πσ2)}其中, σ 2 \sigma^2 σ2 越大,微分熵越大,并且 H [ x ] H[x] H[x] 可能取负值H [ x ] = − ∫ p ( x ) ln p ( x ) d x = − ∫ p ( x ) ln { 1 2 π σ 2 } d x − ∫ p ( x ) { − ( x − μ ) 2 2 σ 2 } d x = − ln { 1 2 π σ 2 } + σ 2 2 σ 2 = 1 2 { 1 + ln ( 2 π σ 2 ) }
Joint Entropy and Conditional Entropy (联合熵,条件熵)
Conditional Entropy
- 已知
x
x
x 的情况下观察到
y
y
y 的值带来的额外信息量为
−
ln
p
(
y
∣
x
)
-\ln p(y|x)
−lnp(y∣x). 假如我们从联合概率
p
(
x
,
y
)
p(x,y)
p(x,y) 中抽样
(
x
,
y
)
(x,y)
(x,y),则已知
x
x
x 时观察到
y
y
y 带来的平均额外信息量为
 上式即为给定
X
X
X 时
Y
Y
Y 的条件熵,并且有
H
[
Y
∣
X
]
≤
H
[
Y
]
H[Y|X]\leq H[Y]
H[Y∣X]≤H[Y]
上式即为给定
X
X
X 时
Y
Y
Y 的条件熵,并且有
H
[
Y
∣
X
]
≤
H
[
Y
]
H[Y|X]\leq H[Y]
H[Y∣X]≤H[Y] - 条件熵也可写为下式:
H [ Y ∣ X ] = − ∬ p ( y , x ) ln p ( y ∣ x ) d y d x = − ∫ p ( x ) ∫ p ( y ∣ x ) ln p ( y ∣ x ) d y d x = ∫ p ( x ) H [ Y ∣ x ] d xH[Y∣X]=−∬p(y,x)lnp(y∣x)dydx=−∫p(x)∫p(y∣x)lnp(y∣x)dydx=∫p(x)H[Y∣x]dxZero conditional entropy: 由上式可知,当 H [ Y ∣ X ] = 0 H[Y|X]=0 H[Y∣X]=0 时,对所有 x x x 都有 H [ Y ∣ x ] = 0 H[Y|x]=0 H[Y∣x]=0,也就是当 x x x 固定时, y y y 只能取某一个定值H [ Y | X ] = − ∬ p ( y , x ) ln p ( y | x ) d y d x = − ∫ p ( x ) ∫ p ( y | x ) ln p ( y | x ) d y d x = ∫ p ( x ) H [ Y | x ] d x
Joint Entropy
H [ x , y ] = − ∬ p ( x , y ) ln p ( x , y ) d y d x H[x,y]=-\iint p(x,y)\ln p(x,y)dydx H[x,y]=−∬p(x,y)lnp(x,y)dydx
- H [ x , x ] = H [ x ] H[x,x]=H[x] H[x,x]=H[x]
- H [ x , y ] = H [ y , x ] H[x,y]=H[y,x] H[x,y]=H[y,x]
Chain Rule
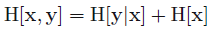
Relative entropy / KL divergence / KL distance (相对熵, KL 散度, KL 距离)
- 假如有一个未知的概率分布
p
(
x
)
p(x)
p(x),我们用另一个概率分布
q
(
x
)
q(x)
q(x) 来近似
p
(
x
)
p(x)
p(x). 如果我们在传输
x
x
x 的值时使用
q
(
x
)
q(x)
q(x) 构筑编码方式,则与实际使用
p
(
x
)
p(x)
p(x) 构筑编码方式相比,需要的平均额外信息量 (in nats) 为
 上式即为相对熵 / KL 散度 (KL divergence is a measure of the inefficiency of assuming that the distribution is
q
q
q when the true distribution is
p
p
p. e.g. if we knew the true distribution
p
p
p of the random variable, we could construct a code with average description length
H
(
p
)
H(p)
H(p). If, instead, we used the code for a distribution
q
q
q, we would need
H
(
p
)
+
K
L
(
p
∥
q
)
H(p) + KL(p\|q)
H(p)+KL(p∥q) bits on the average to describe the random variable. i.e.
上式即为相对熵 / KL 散度 (KL divergence is a measure of the inefficiency of assuming that the distribution is
q
q
q when the true distribution is
p
p
p. e.g. if we knew the true distribution
p
p
p of the random variable, we could construct a code with average description length
H
(
p
)
H(p)
H(p). If, instead, we used the code for a distribution
q
q
q, we would need
H
(
p
)
+
K
L
(
p
∥
q
)
H(p) + KL(p\|q)
H(p)+KL(p∥q) bits on the average to describe the random variable. i.e.
H ( q ) = H ( p ) + K L ( p ∥ q ) H(q)=H(p)+KL(p\|q) H(q)=H(p)+KL(p∥q)),它可以用来度量两个概率分布之间的距离 (两个概率分布的采样空间必须相同)。注意到,KL 散度是非对称量,即 K L ( p ∥ q ) ≠ K L ( q ∥ p ) KL(p\|q)\neq KL(q\|p) KL(p∥q)=KL(q∥p) - 注意到, 0 log 0 0 = 0 , 0 log 0 q = 0 , p log p 0 = ∞ 0\log\frac{0}{0}=0,0\log\frac{0}{q}=0,p\log\frac{p}{0}=\infty 0log00=0,0logq0=0,plog0p=∞,因此如果存在 x ∈ X x\in\mathcal X x∈X 使得 p ( x ) > 0 p(x)>0 p(x)>0 但 q ( x ) = 0 q(x)=0 q(x)=0, 则 K L ( p ∥ q ) = ∞ KL(p\|q)=\infty KL(p∥q)=∞
Gibbs’s inequality
K L ( p ∥ q ) ≥ 0 with equality if and only if p ( x ) = q ( x ) for all x
with equality if and KL(p∥q)≥0only if p(x)=q(x) for all xK L ( p ‖ q ) ≥ 0 with equality if and only if p ( x ) = q ( x ) for all x Proof
- Jensen’s inequality:凸函数:
 其中,
0
≤
λ
≤
1
0\leq\lambda\leq1
0≤λ≤1
其中,
0
≤
λ
≤
1
0\leq\lambda\leq1
0≤λ≤1
 由数学归纳法可知,凸函数
f
(
x
)
f(x)
f(x) 满足
由数学归纳法可知,凸函数
f
(
x
)
f(x)
f(x) 满足
 其中,
λ
i
≥
0
\lambda_i\geq0
λi≥0,
∑
i
λ
i
=
1
\sum_i\lambda_i=1
∑iλi=1. 上式即为 Jensen’s inequality,证明如下:
其中,
λ
i
≥
0
\lambda_i\geq0
λi≥0,
∑
i
λ
i
=
1
\sum_i\lambda_i=1
∑iλi=1. 上式即为 Jensen’s inequality,证明如下:
f ( ∑ m = 1 M + 1 λ m x m ) = f ( λ M + 1 x M + 1 + ( 1 − λ M + 1 ) ∑ m = 1 M λ m 1 − λ M + 1 x m ) ≤ λ M + 1 f ( x M + 1 ) + ( 1 − λ M + 1 ) f ( ∑ m = 1 M λ m 1 − λ M + 1 x m ) ≤ λ M + 1 f ( x M + 1 ) + ( 1 − λ M + 1 ) ∑ m = 1 M λ m 1 − λ M + 1 f ( x m ) ≤ ∑ m = 1 M + 1 λ m f ( x m )f(m=1∑M+1λmxm)=f(λM+1xM+1+(1−λM+1)m=1∑M1−λM+1λmxm)≤λM+1f(xM+1)+(1−λM+1)f(m=1∑M1−λM+1λmxm)≤λM+1f(xM+1)+(1−λM+1)m=1∑M1−λM+1λmf(xm)≤m=1∑M+1λmf(xm)如果将 λ i \lambda_i λi 视为离散随机变量 z z z 的概率分布,即 λ i = p ( z = z i ) \lambda_i=p(z=z_i) λi=p(z=zi), x i = ξ ( z i ) x_i=\xi(z_i) xi=ξ(zi),则 Jensen 不等式可以写为f ( ∑ m = 1 M + 1 λ m x m ) = f ( λ M + 1 x M + 1 + ( 1 − λ M + 1 ) ∑ m = 1 M λ m 1 − λ M + 1 x m ) ≤ λ M + 1 f ( x M + 1 ) + ( 1 − λ M + 1 ) f ( ∑ m = 1 M λ m 1 − λ M + 1 x m ) ≤ λ M + 1 f ( x M + 1 ) + ( 1 − λ M + 1 ) ∑ m = 1 M λ m 1 − λ M + 1 f ( x m ) ≤ ∑ m = 1 M + 1 λ m f ( x m )
f ( E z [ ξ ( z ) ] ) ≤ E z [ f ( ξ ( z ) ) ] f(\mathbb E_z[\xi(z)])\leq\mathbb E_z[f(\xi(z))] f(Ez[ξ(z)])≤Ez[f(ξ(z))]其中, f f f 为凸函数, ξ \xi ξ 为任意函数。如果 f f f 为严格凸函数,则当且仅当 “ ξ ( z ) \xi(z) ξ(z) is constant with probability one or a l m o s t almost almost s u r e l y surely surely” 时等号成立 ( a l m o s t almost almost s u r e l y surely surely 表明可能存在例外,但例外发生的概率为 0),此时有 ξ ( z ) = ξ 0 \xi(z)=\xi_0 ξ(z)=ξ0 (on the range of z z z almost everywhere),因此 E z [ ξ ( z ) ] = ξ 0 \mathbb E_z[\xi(z)]=\xi_0 Ez[ξ(z)]=ξ0,Jensen 不等式的左右均为 f ( ξ 0 ) f(\xi_0) f(ξ0)
 并且 Jensen 不等式也可以推广到连续随机变量
并且 Jensen 不等式也可以推广到连续随机变量
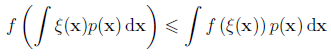
- 由于
−
ln
x
-\ln x
−lnx 为凸函数,将 Jensen 不等式代入 KL 散度公式可知
K L ( p ∥ q ) = − ∫ p ( x ) ln { q ( x ) p ( x ) } d x ⩾ − ln ∫ p ( x ) q ( x ) p ( x ) d x ≥ 0 \mathrm{KL}(p \| q)=-\int p(\mathrm{x}) \ln \left\{\frac{q(\mathrm{x})}{p(\mathrm{x})}\right\} \mathrm{dx} \geqslant-\ln \int p(\mathrm x)\frac{q(\mathrm{x})}{p(\mathrm x)} \mathrm{d} \mathrm{x}\geq0 KL(p∥q)=−∫p(x)ln{p(x)q(x)}dx⩾−ln∫p(x)p(x)q(x)dx≥0其中最后 − ln ∫ p ( x ) q ( x ) p ( x ) d x ≥ 0 -\ln \int p(\mathrm x)\frac{q(\mathrm{x})}{p(\mathrm x)} \mathrm{d} \mathrm{x}\geq0 −ln∫p(x)p(x)q(x)dx≥0 是因为 − ln ∫ p ( x ) q ( x ) p ( x ) d x -\ln \int p(\mathrm x)\frac{q(\mathrm{x})}{p(\mathrm x)} \mathrm{d} \mathrm{x} −ln∫p(x)p(x)q(x)dx 中,如果 p ( x ) = 0 p(x)=0 p(x)=0 则 p ( x ) q ( x ) p ( x ) = 0 p(x)\frac{q(x)}{p(x)}=0 p(x)p(x)q(x)=0,因此最后得出的 ∫ p ( x ) q ( x ) p ( x ) d x \int p(\mathrm x)\frac{q(\mathrm{x})}{p(\mathrm x)} \mathrm{d} \mathrm{x} ∫p(x)p(x)q(x)dx 可能少掉某些 q ( x ) q(x) q(x) 项,使得最终的和小于 1. 由于 − ln x -\ln x −lnx 为严格凸函数,因此当且仅当 p ( x ) = q ( x ) p(x) = q(x) p(x)=q(x) almost everywhere 时 K L ( p ∥ q ) = 0 \mathrm{KL}(p \| q)=0 KL(p∥q)=0
KL divergence for density estimation
- 假设我们想要建模的数据服从一个未知分布
p
(
x
)
p(x)
p(x),我们用一个参数化的分布
q
(
x
∣
θ
)
q(x|\theta)
q(x∣θ) 去近似
p
(
x
)
p(x)
p(x),此时就通过最小化
K
L
(
p
∥
q
)
KL(p\|q)
KL(p∥q) 来优化参数
θ
\theta
θ. 但我们并不知道
p
(
x
)
p(x)
p(x) 的具体值,只能从中采样,因此期望项需要用蒙特卡洛法来近似,也就是从
p
(
x
)
p(x)
p(x) 中采样出
N
N
N 个样本点来近似地计算 KL 散度:
K L ( p ∥ q ) ≃ 1 N ∑ n = 1 N { − ln q ( x n ∣ θ ) + ln p ( x n ) } \mathrm{KL}(p \| q) \simeq \frac{1}{N}\sum_{n=1}^{N}\left\{-\ln q\left(\mathrm{x}_{n} \mid \boldsymbol{\theta}\right)+\ln p\left(\mathrm{x}_{n}\right)\right\} KL(p∥q)≃N1n=1∑N{−lnq(xn∣θ)+lnp(xn)}第 2 项为定值可以忽略,因此最小化 KL 散度等价于最大化对数似然
Cross entropy loss
- 在 ML 的分类问题中,样本
i
i
i 的标签
t
i
t_i
ti 可以被表示为 one-hot vector,该向量可以被看作是一个离散概率分布
p
i
(
z
)
p_i(z)
pi(z). 模型经过 softmax 的预测结果也可以被看作一个离散概率分布
q
i
(
z
∣
θ
)
q_i(z|\theta)
qi(z∣θ),我们想要让
p
i
(
z
)
p_i(z)
pi(z) 和
q
i
(
z
∣
θ
)
q_i(z|\theta)
qi(z∣θ) 之间的 KL 散度尽量小:
min θ K L ( p i ( z ) ∥ q i ( z ∣ θ ) ) = min θ E z ∼ p i ( z ) [ ln p i ( z ) q i ( z ∣ θ ) ] = min θ − E z ∼ p i ( z ) [ ln q i ( z ∣ θ ) ]θminKL(pi(z)∥qi(z∣θ))=θminEz∼pi(z)[lnqi(z∣θ)pi(z)]=θmin−Ez∼pi(z)[lnqi(z∣θ)]又因为 p i ( z ) p_i(z) pi(z) 只在标签处概率值为 1 (i.e. p i ( z ) = 1 p_i(z)=1 pi(z)=1, if z = t i z=t_i z=ti else 0),因此有min θ K L ( p i ( z ) ‖ q i ( z | θ ) ) = min θ E z ∼ p i ( z ) [ ln p i ( z ) q i ( z | θ ) ] = min θ − E z ∼ p i ( z ) [ ln q i ( z | θ ) ]
min θ K L ( p i ( z ) ∥ q i ( z ∣ θ ) ) = min θ − ln q i ( t i ∣ θ )θminKL(pi(z)∥qi(z∣θ))=θmin−lnqi(ti∣θ)样本 i i i 的损失函数为min θ K L ( p i ( z ) ‖ q i ( z | θ ) ) = min θ − ln q i ( t i | θ )
L i = − ln q i ( t i ∣ θ ) L_i=-\ln {q_i(t_i|\theta)} Li=−lnqi(ti∣θ)上式即为交叉熵损失
Mutual information (互信息)
- 现在考虑随机变量
x
x
x,
y
y
y,如果它们相互独立,则有
p
(
x
,
y
)
=
p
(
x
)
p
(
y
)
p(x,y)=p(x)p(y)
p(x,y)=p(x)p(y),因此可以用如下的 KL 散度来衡量随机变量
x
x
x,
y
y
y 的独立程度:
 上式即为随机变量
x
x
x,
y
y
y 的互信息,可以看到,独立程度越低,互信息越大 (a measure of the amount of information one random variable contains about another)
上式即为随机变量
x
x
x,
y
y
y 的互信息,可以看到,独立程度越低,互信息越大 (a measure of the amount of information one random variable contains about another)
Properties
-
I
[
x
,
y
]
≥
0
I[x,y]\geq0
I[x,y]≥0;当且仅当
x
,
y
x,y
x,y 独立时有
I [ x , y ] = 0 I[x,y]=0 I[x,y]=0 - I [ x , y ] = I [ y , x ] I[x,y]=I[y,x] I[x,y]=I[y,x]
- I [ x , x ] = K L ( p ( x ) ∥ p ( x ) 2 ) = ∫ x p ( x ) ln 1 p ( x ) d x = H [ x ] I[x,x]=KL(p(x)\|p(x)^2)=\int_xp(x)\ln\frac{1}{p(x)}dx=H[x] I[x,x]=KL(p(x)∥p(x)2)=∫xp(x)lnp(x)1dx=H[x]. Entropy then becomes the self-information of a random variable.
Mutual Information and Entropy
- Mutual Information is the reduction in the uncertainty of one random variable due to the knowledge of the other.
 I
[
X
,
Y
]
=
H
[
X
]
+
H
[
Y
]
−
H
[
X
,
Y
]
I[X,Y]=H[X]+H[Y]-H[X,Y]
I[X,Y]=H[X]+H[Y]−H[X,Y]
I
[
X
,
Y
]
=
H
[
X
]
+
H
[
Y
]
−
H
[
X
,
Y
]
I[X,Y]=H[X]+H[Y]-H[X,Y]
I[X,Y]=H[X]+H[Y]−H[X,Y] Proof sketch: e.g. To prove
I
[
X
,
Y
]
=
H
[
X
]
+
H
[
Y
]
−
H
[
X
,
Y
]
I[X,Y]=H[X]+H[Y]-H[X,Y]
I[X,Y]=H[X]+H[Y]−H[X,Y]
Proof sketch: e.g. To prove
I
[
X
,
Y
]
=
H
[
X
]
+
H
[
Y
]
−
H
[
X
,
Y
]
I[X,Y]=H[X]+H[Y]-H[X,Y]
I[X,Y]=H[X]+H[Y]−H[X,Y]
- (1)
log p ( X , Y ) p ( X ) p ( Y ) = − log p ( X ) − log p ( Y ) + log p ( X , Y ) \log \frac{p(X, Y)}{p(X) p(Y)}=-\log p(X)-\log p(Y)+\log p(X, Y) logp(X)p(Y)p(X,Y)=−logp(X)−logp(Y)+logp(X,Y) - (2) Take expectation E E E at both sides.
- (1)
- For two random variables
X
,
Y
X,Y
X,Y, if
X
X
X and
Y
Y
Y are independent, then
H [ X , Y ] = H [ X ] + H [ Y ] H[X,Y]=H[X]+H[Y] H[X,Y]=H[X]+H[Y]
Chain rules for entropy, relative entropy, and mutual information
Chain Rule for Entropy
- The entropy of a collection of random variables is the sum of the conditional entropies.

- If
X
1
,
.
.
.
,
X
n
X_1, ... , X_n
X1,...,Xn are independent,

- If
X
1
,
.
.
.
,
X
n
X_1, ... , X_n
X1,...,Xn are independent,
Proof
- (1) Fact p ( x 1 , . . . , x n ) = p ( x 1 ) p ( x 2 ∣ x 1 ) . . . p ( x n ∣ x 1 , . . . , x n − 1 ) p(x_1,...,x_n)=p(x_1)p(x_2|x_1)...p(x_n|x_1,...,x_{n-1}) p(x1,...,xn)=p(x1)p(x2∣x1)...p(xn∣x1,...,xn−1)
- (2) Take log ( ) \log() log() at each side
- (3) Take expectation E E E at both sides: E ( X 1 + X 2 ) = E ( X 1 ) + E ( X 2 ) E(X_1+X_2)=E(X_1)+E(X_2) E(X1+X2)=E(X1)+E(X2)
Conditional mutual information
- We now define the conditional mutual information as the reduction in the uncertainty of X X X due to knowledge of Y Y Y when Z Z Z is given.

- I ( X ; Y ∣ Z ) ≥ 0 I(X;Y|Z)≥ 0 I(X;Y∣Z)≥0 with equality if and only if X X X and Y Y Y are conditionally independent given Z Z Z
Chain rule for information
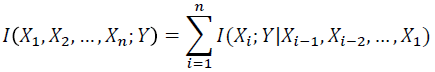
Conditional Relative Entropy

Chain rule for relative entropy
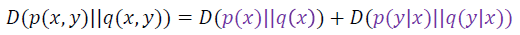
- Proof:

Information inequality (信息不等式)
Independence Bound on Entropy

- Proof: By chain rule for entropies,

References
- 上海交通大学程帆老师信息论课程
- Bishop, Christopher M., and Nasser M. Nasrabadi. Pattern recognition and machine learning. Vol. 4. No. 4. New York: springer, 2006.
- 【PRML】【模式识别和机器学习】【从零开始的公式推导】1.6 信息论
- Solution Manual For PRML
- More PRML Errata
-
相关阅读:
【SpringCloud】Gateway网关、SpringCloud Config配置中心、消息总线BUS以及Spring Cloud Stream
Kamiya丨Kamiya艾美捷小鼠高敏CRP ELISA说明书
Java NIO 文件通道 FileChannel 用法
《HCIP-openEuler实验指导手册》4.1Mysql数据库安装与配置
arm开发板
视频剪辑高手的秘诀:如何从视频中提取封面,提高视频点击率
山东菏泽家乡网页代码 html静态网页设计制作 dw静态网页成品模板素材网页 web前端网页设计与制作 div静态网页设计
赛后补题L - Non-Prime Factors
一次服务器被入侵的处理过程分享
Annaconda环境下ChromeDriver配置及爬虫编写
- 原文地址:https://blog.csdn.net/weixin_42437114/article/details/119023610